本文主要是介绍大语言模型(LLMs)在 Amazon SageMaker 上的动手实践(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本期文章,我们将通过三个动手实验从浅到深地解读和演示大语言模型(LLMs),如何结合 Amazon SageMaker 的模型部署、模型编译优化、模型分布式训练等。
实验一:使用 Amazon SageMaker 构建基于开源 GPT-J 模型的对话机器人应用
开发者可以使用 Amazon SageMaker 构建一个交互式的人机对话应用 DEMO,尝试基于开源 GPT-J 模型的 Text Generation 技术。Amazon SageMaker 是亚马逊云科技公有云中的一项托管服务。作为一个云机器学习平台,可以让开发者在云中创建、训练和部署 ML 模型以此来对大语言模型有更深刻的认知。
这一动手实验仅仅使用 20 行左右的代码,即可将开源的 GPT-J 模型部署到 Amazon SageMaker 的终端节点(Endpoint),实现基于大语言模型的简单交互式人机对话。完成该实验的代码编写和模型部署预计需要 20 分钟。
什么是 GPT-J:
GPT-J 是一种生成式预训练(GPT)大语言模型,就其架构而言,它可与 GPT-3 等流行的私有大语言模型相媲美。它由大约 60 亿个参数和 28 个层组成,包括一个前馈模块和一个自注意力模块。为 GPT-J 提供推理所需的内存要低得多——在 FP16 中,模型权重占用不到 13 GB,这意味着可以在单个 16GB GPU 上轻松进行推理。
1. 创建 SageMaker Notebook 实例
在亚马逊云科技控制台(console.aws.amazon.com)上,输入 “Amazon SageMaker” 并点击进入,然后在左侧导航菜单中找到 “Notebook instances”,点击右上角的 “Create notebook instance” 开始创建。如下图所示:
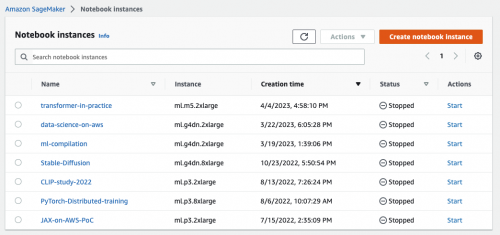
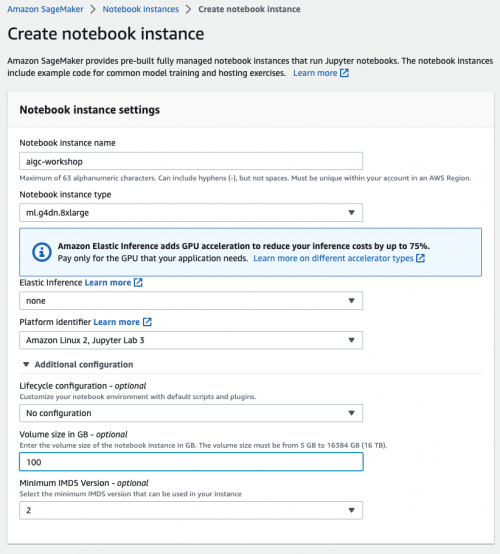
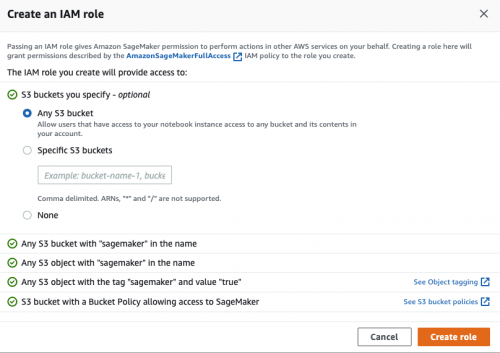
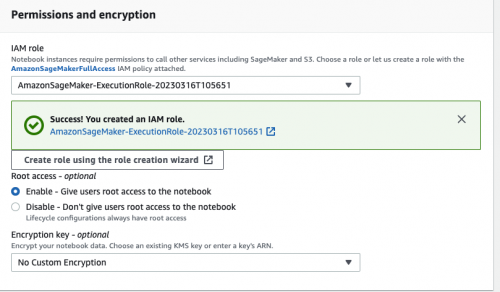
在创建 Notebook instances 的过程中,需要指定在 Amazon SageMaker 中运行代码的角色(role)。由于需要访问 Amazon S3 等资源(存放模型训练需要的数据、模型构件等),因此必须设置合适的角色(role)使其具有访问相关 Amazon S3 的权限。如下图所示:
提交后等待几分钟,可以看到状态变成 “InService”,即表示该实例已经成功创建。如下图所示:

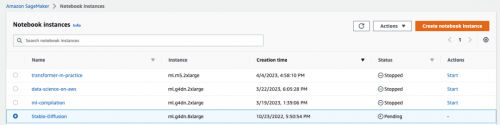
如果之前已经创建过(并且没有 delete),可以直接点击 ”Start” 重新启动实例。如下图所示:
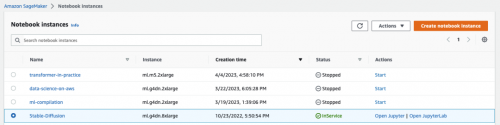
当状态从 “Pending” 变成 “InService”, 即表示该实例已经成功启动。如下图所示:
2. 进入 Open Jupyter/JupyterLab 环境
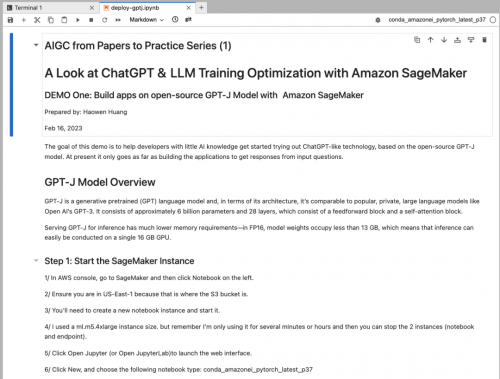
如下图,点击 Open Jupyter 或者 Open JupyterLab 环境。我个人更喜欢 Open JupyterLab,因此本文中会主要以 Open JupyterLab 来做讲解和演示:
![]()
点击 “Terminal”,以打开一个终端:
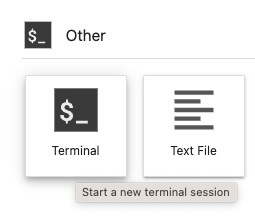
在打开的终端中输入以下命令:
$ pwd
$ cd SageMaker
$ git clone https://github.com/hanyun2019/aigc.git
输出如下:
这时你会看到左侧菜单栏增加了 “aigc” 目录:
该目录下的文件如下图所示:
双击 “deploy-gptj.ipynb” 打开这个文件,即可开始逐步完成实验一:
3. 使用 Amazon SageMaker 构建基于开源 GPT-J 模型的对话机器人应用
以下逐行解释实验一的主要代码。
首先,需要安装 SageMaker 的相关 SDK:
!pip install -U sagemaker
然后 import 实验需要的 HuggingFace API 和 SageMaker 的 API 包:
from sagemaker.huggingface import HuggingFaceModel
import sagemaker
定义创建终端节点的 IAM 角色权限:
# IAM role with permissions to create endpoint
role = sagemaker.get_execution_role()
定义 GPT-J 模型构件所在的 S3 桶:
# public S3 URI to gpt-j artifact
model_uri="s3://huggingface-sagemaker-models/transformers/4.12.3/pytorch/1.9.1/gpt-j/model.tar.gz"
调用 HuggingFace API 来创建模型相关参数,包括:模型构件文件名、transformers 的版本号、PyTorch 的版本号、Python 的版本号、角色名等:
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=model_uri,
transformers_version='4.12.3',
pytorch_version='1.9.1',
py_version='py38',
role=role,
)
以上设置完毕后,即可部署模型到 Amazon SageMaker 的终端节点了。可以在这里设置一些终端节点的参数,比如节点实例数量、节点类型等:
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1, # number of instances
instance_type='ml.g4dn.xlarge' #'ml.p3.2xlarge' # ec2 instance type
)
运行以上 “huggingface_model.deploy” 代码后,会在 Amazon SageMaker 控制台的 “EndPoints” 看到有实例正在创建(Creating)中,如下图所示:

当看到实例创建完成(InService),即可开始进行推理,即开始和聊天机器人对话了!

如下图所示,我们询问的是中国香港地区的最高建筑、最贵物业等信息。你可以自己定义问题,从中获得和大模型(GPT-J)聊天机器人对话的乐趣!
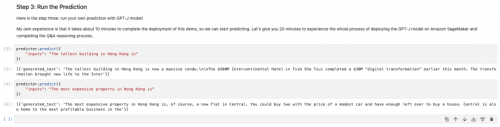
特别提醒:完成该实验后,记得删除终端节点,以避免不必要的终端节点收费。如下图所示:

这篇关于大语言模型(LLMs)在 Amazon SageMaker 上的动手实践(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







