本文主要是介绍与 PCIe 相比,CXL为何低延迟高带宽?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 1. Latency
- PCIE 生产者消费则模型
- 结论
- Flit 包
- PCIE/CXL.io
- CXL.cace & .mem
- 总结
- 2. BandWidth
- 常见开销
- CXL.IO Link efficiency
- PCIe Link efficiency
- CXL.IO bandwidth
- CXL.mem/.cache bandwidth
- 参考
前言
CXL 规范里没有具体描述与PCIe 相比低延时高带宽的原因,一开始我也很不理解,不过慢慢就有点轮廓了,做一个总结,尽量讲通俗一点,欢迎指正。
1. Latency
PCIE 生产者消费则模型
在开始之前,首先提一嘴 PCIE 的生产者消费者模型,因为在使用 PCIE 设备的时候,主机与设备通信,比如网卡收发数据、显卡接受数据等,进行具体的业务数据传输时,为了维护数据的准确性,必须是使用生产者消费者模型的。
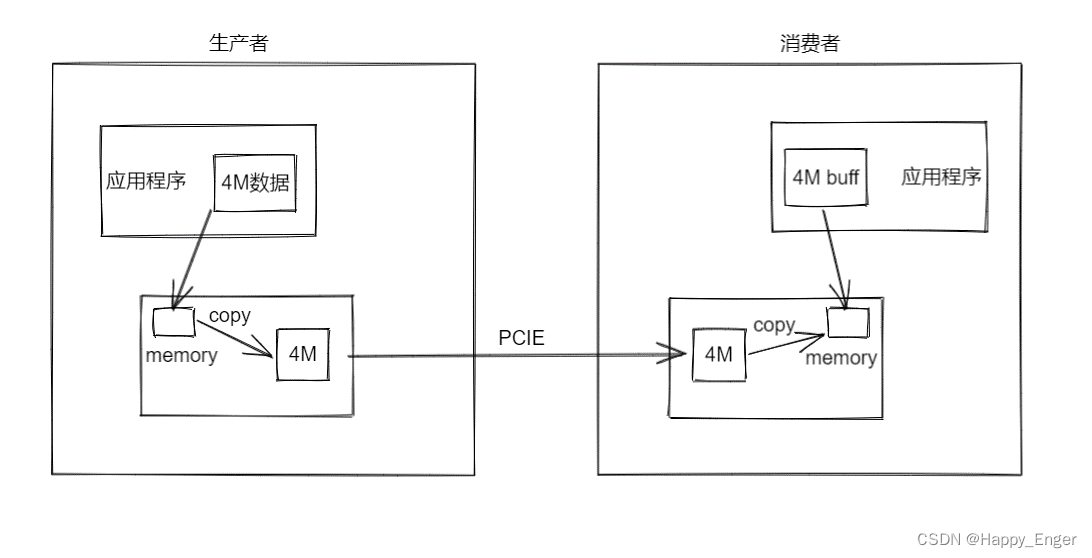
如上图,右侧为主机,左侧为设备,如果主机想要获取设备某段内存的地址,除非特殊设计,将设备内存映射到BAR 空间,主机侧可直接地址访问,否则,必须是设备将要读取的内存区域的数据 copy 到 DMA 传输内存缓冲区中,然后启动 DMA 传输,通过PCIE 控制器传输数据到主机侧相应的 DMA 缓冲区,并通过中断或者 flag 通知主机,传输完成;主机收到完成信号后,会开始操作,将DMA 缓冲区的数据拷贝到应用程序缓冲区,进行下一步数据处理。
哪怕是主机读设备一个字节,也是上面这个流程,延迟的分布不仅在 PCIE 协议层,而且主要分布在最少两次的内存拷贝中。
所以,我要将延迟分两部分介绍,一部分是控制器到控制器的延迟,一部分是站在应用程序的角度,读写对端内存的延迟.
结论
后面内容太杂,所以先说结论,以免越看越乱。CXL 低延迟的实现根据上面两部分分类,一类是控制器到控制器的延迟,主要是因为采用 FLIT 模式的包,增加了少数据量的带宽,简化了硬件设计,取消了PCIE的ordering rule, access right check、DLLP等,换句话说,CXL 控制器与PCIe 控制器设计上就降低了很多 latency。第二类,站在应用层角度上看,延迟主要是因为 CXL 协议可以维护缓存一致性,所以减少了内存 copy 的操作,从而降低了整体延迟。
Flit 包
在讲 Flit 包之前,我们可以先看一下 PCIe 传输层协议包的格式,如下图
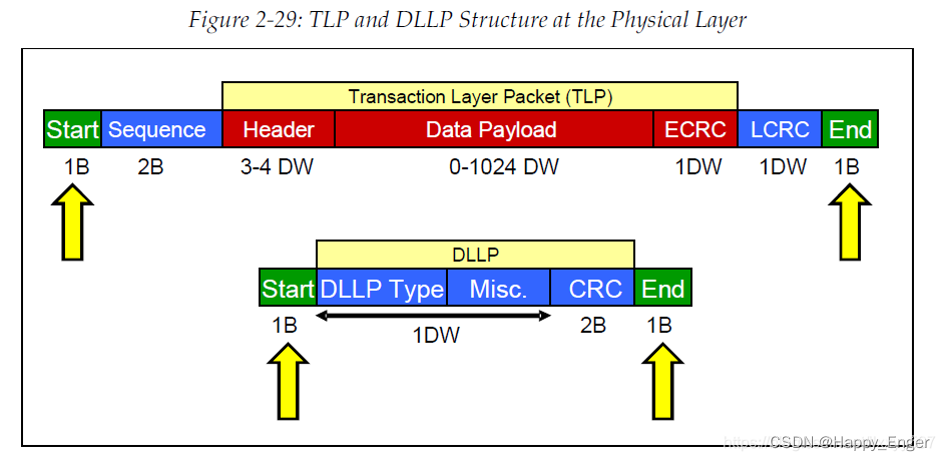
其中,红色部分为 TLP 包格式,分为 3 -4 DW 的头,0 - 1024 DW 变长的数据负载以及最后 1DW 的CRC. 其他字节为数据链路层以及物理层额外添加的开销。
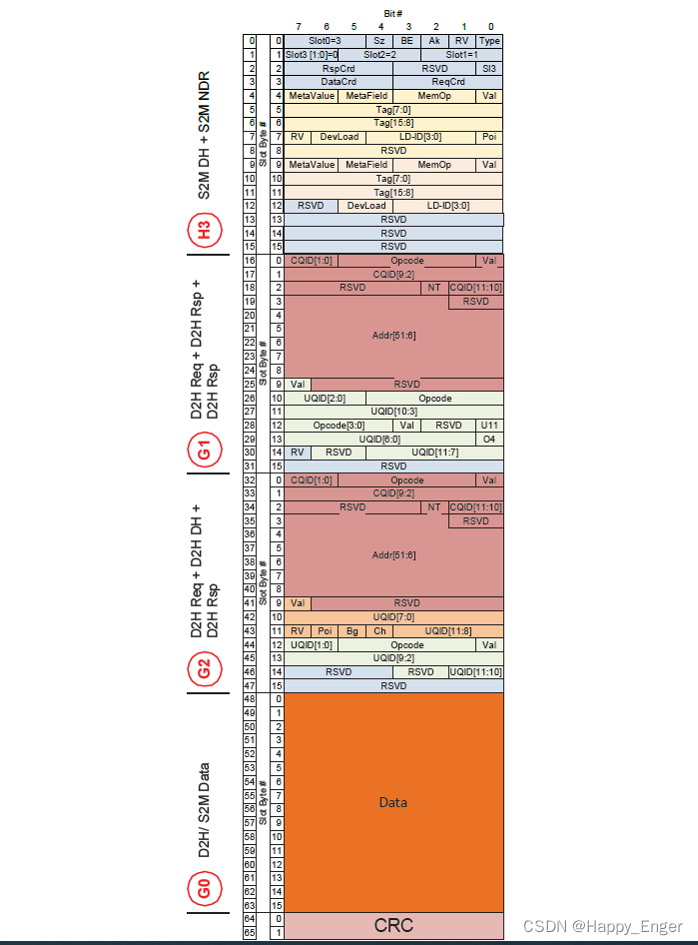
不同于 TLP, CXL 采用 Flit 模式发送数据,CXL.cache / mem flie 大小固定 528bit, 有2字节的CRC以及 4 slots 的16字节块。
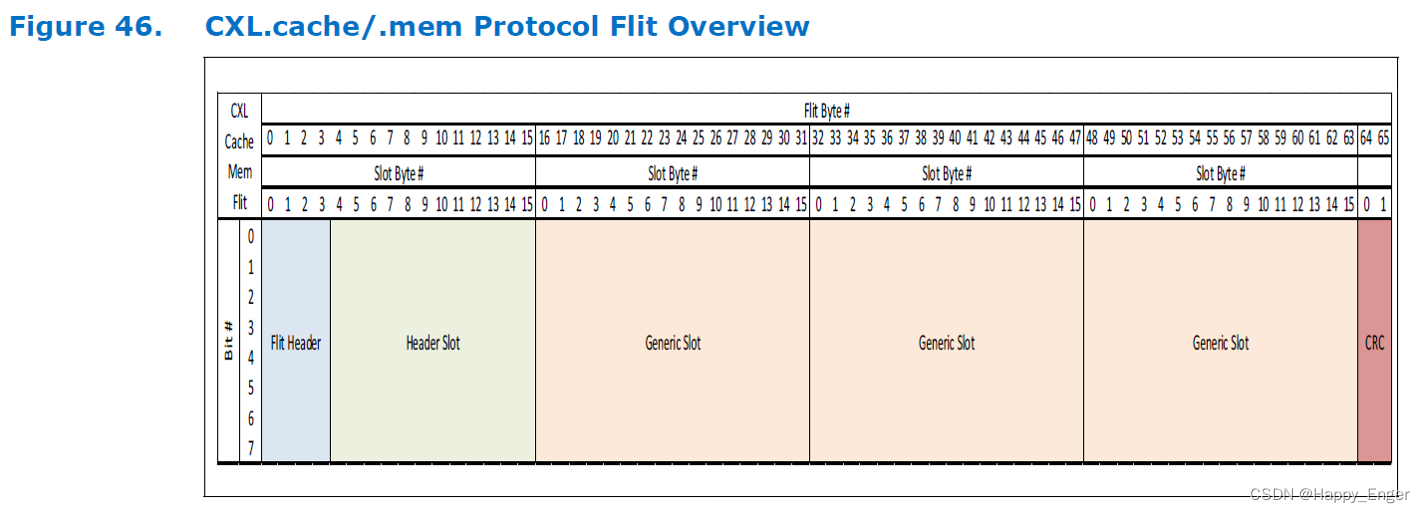
其中:
A “Header” Slot is defined as one that carries a “Header” of link-layer specific information
A “Generic” Slot can carry one or more request/response messages or a single 16B data chunk.
The flit can be composed of a Header Slot and 3 Generic Slots or four 16B Data Chunks.
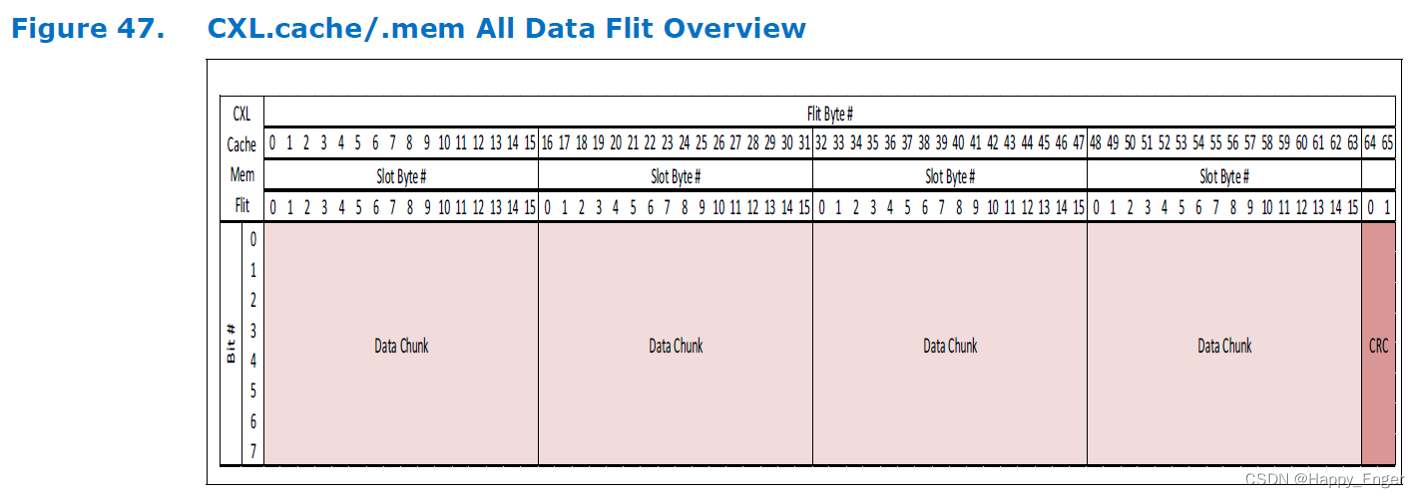
总结一下,就是 CXL Flit 就是固定的 4块 16 字节的区域外加一个2字节CRC. 这 4 块区域每块都可以放请求响应包,也可以放数据块,头只能放在 slot0 中。
举个例子如下,设备到主机的 flit 包, 最上面 slot0 有头,也有响应包,其他的有请求包也有响应包,最后一个slot 放的16字节数据,然后最后2字节CRC.
使用 Flit 优点如下:
- 其携带的额外信息很多,优势就在于当你出现高速数据传输的时,携带数据的能力越强,速率越高,数据量越大,这种flit模式下的低延迟高速率的优势就会越明显;
- PCIe 6.0 引入了 FLIT 模式,其中数据包以固定大小的流量控制单元组织,而不是过去几代 PCIe 中的可变大小。引入 FLIT 模式的最初原因是纠错需要使用固定大小的数据包;
- FLIT 模式还简化了控制器级别的数据管理,从而提高了带宽效率、降低了延迟并缩小了控制器占用空间。对于固定大小的数据包,不再需要在物理层对数据包进行成帧,这为每个数据包节省了 4 字节;
- FLIT 编码还消除了以前 PCIe 规范中的 128B/130B 编码和 DLLP(数据链路层数据包)开销,从而显著提高了效率,尤其是对于较小的数据包。
PCIE/CXL.io
首先借鉴一下其他公司的 PPT , PCIe 设备访问主机内存的数据流如下:
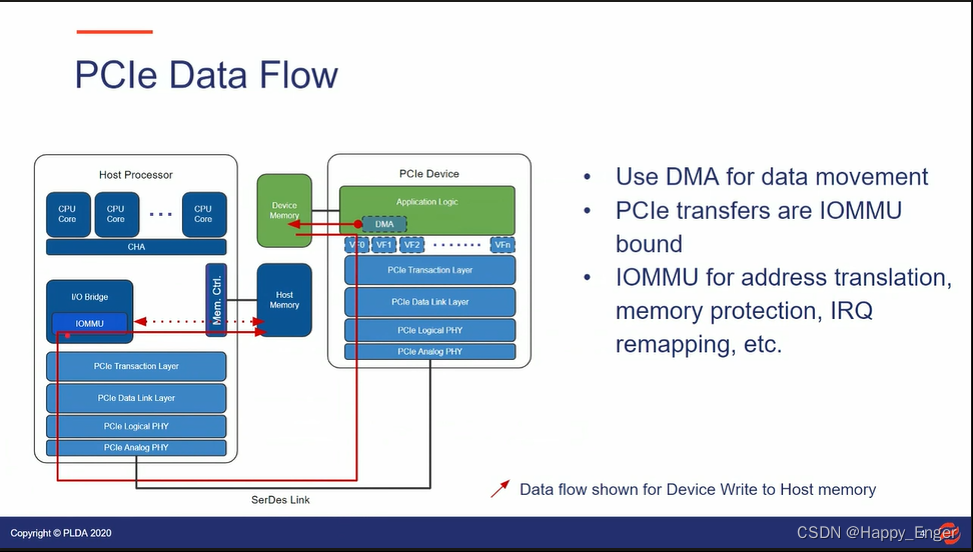
PCIe 设备访问主机内存有两种情况,一种是直接内存访问,流向如上图;还有一种是站在应用程序的角度,需要内存拷贝至少两次,如前面的生产者消费者模型。他们都用不到缓存,但会都用到 IOMMU.
PCIe Latency Breakdown 如下:
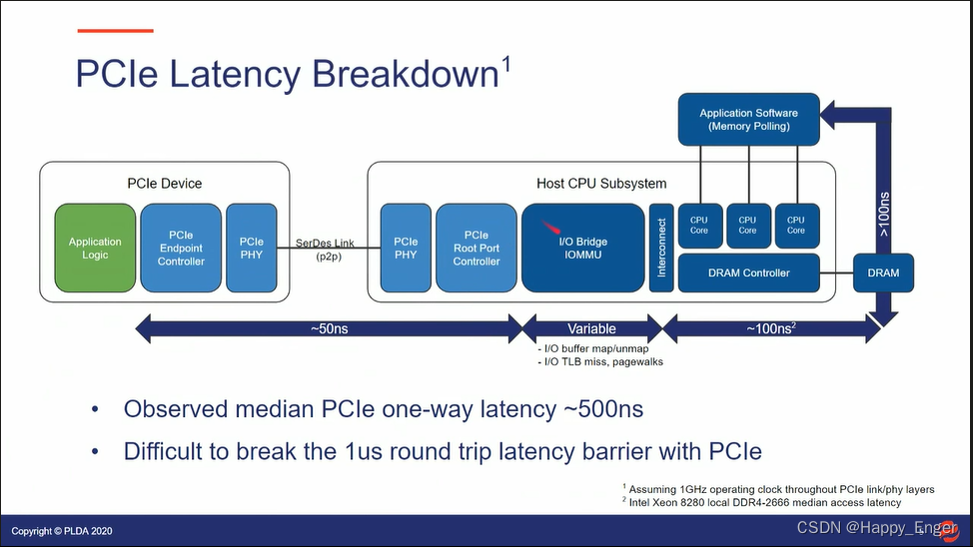
PCIe 控制器到控制器为 50ns, IOMMU 根据不同的环境时间是变化的,内存控制器读写内存需要 100ns. 整体一路大概 500ns, 来回很难打破 1us. 这是站在应用层角度,有了第二次拷贝,这个 latency 算进去。实际延时应该会更长。
如下为 CXLIO 设备到主机内存的数据流向:
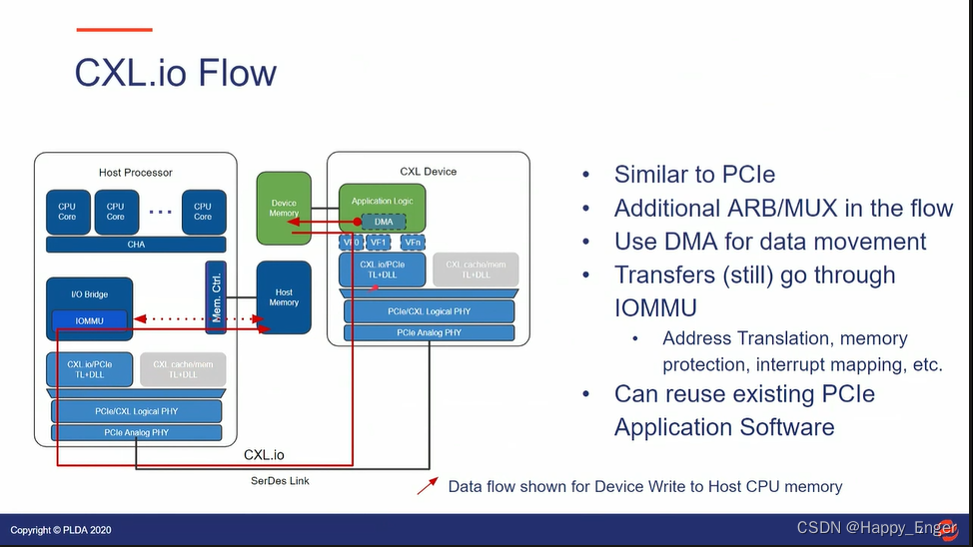
与 PCIe 基本相似,不同的是,CXL 控制器与 PCIe控制器还是有点差异的,多了一个 ARB/MUX 动态多路复用器件。软件层面,可以与 PCIe 复用。
CXL.io 的性能如下:

IO 的吞吐量比 PCIe 还要差 6%, 因为CXL.io 协议就是封装了PCIe 的TLP, 在前面加了2字节 Protocol ID 以及后面增加了 2字节的 reserved bytes。增加了的 ARB/MUX 器件也会消耗 2 - 4 ns。
如下图, CXL Flit 包的在 X8 的分布,每条 Lane 发送一个字节, 第一部分的橙色部分为封装的 PCIe 的包,黄色部分为添加的 2 字节 Protocol ID, 最后有 2字节的 reserved bytes:
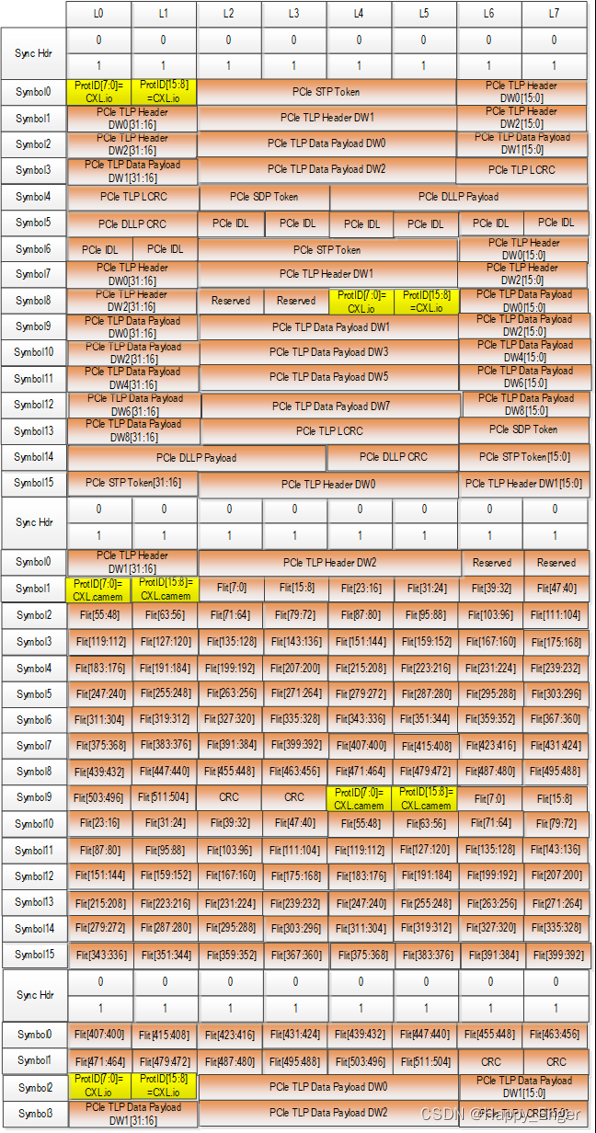
CXL.cace & .mem
下图为 CXL.cache 设备访问主机内存的数据流向:
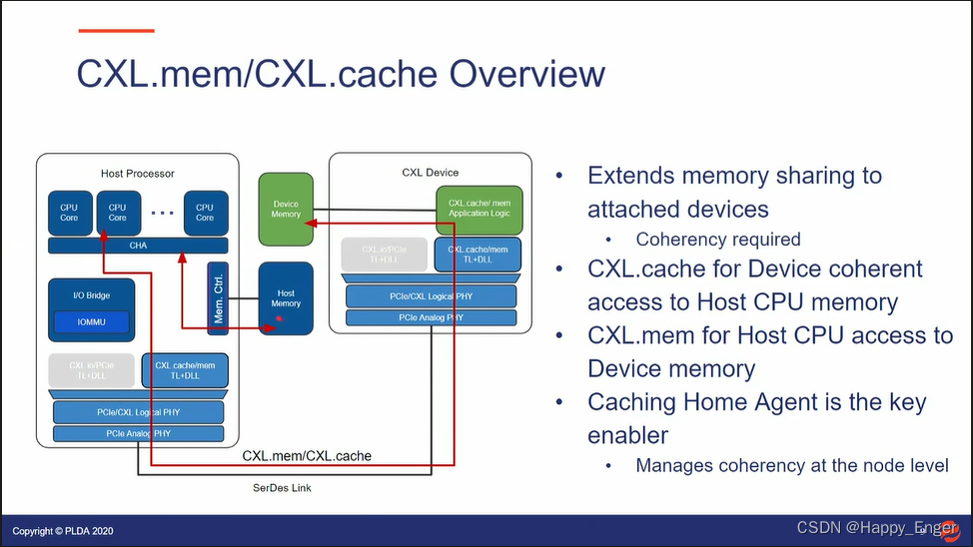
.cache 协议可以让设备像访问本地内存一样访问主机内存,设备CPU与主机 CPU 可以共同访问同一个地址的数据,缓存一致性由主机侧的 Cache Home Agent 来维护。根据 MESI 协议,看情况是否去访问实际内存。
.mem 则相反方向,让主机使用缓存访问设备内存,就像访问本地 DDR 内存一样。
下图为 .cache 与 .mem 的好处:

- 主机和设备相互访问对方内存,可以直接使用内存语义, load/store,不用再使用生产者消费者模型,使用中断或者 flag 通知对方,也不用多次拷贝了;
- 设备侧可以同样使用主机页表,那样,主机进程和设备就可以访问同一块虚拟地址空间了;
下图为 CXL microarchitecture with CXL.$Mem measured latency.
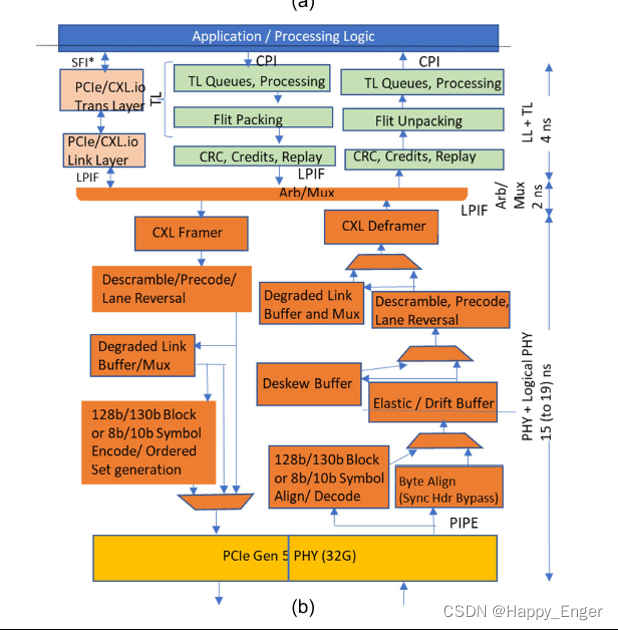
intel 控制器比标准PCIe PHY 做了如下延迟优化:
- bypassing the 128-/130-byte encoding
- bypassing the logic and serializing flops needed to support
- bypassing the deskew buffer if the lane to lane skew is less than half the internal PHY logical clock period
- adopting a predictive policy of processing entries from the elastic buffer (versus waiting for the clock domain synchronization handshake for every entry)
最终, PHY 到 PHY 之间有一个 15 - 19 ns 的延迟,其中4ns 的差异是由参考时钟决定的,depending on whether a common reference clock or independent reference clocks are deployed. 与前面 PCIe 的50 ns 对比,是有时间节省的,不过实际情况,根据不同的IP, 可能会有更大的差距。
这里需要注意的一点是,最底层的模拟 PHY,PCIe 与 CXL 使用的是同一个,这个意味着对于RC与EP的模拟phy 到模拟 phy,相同的数据量,时间是一样的。
More Latency Savings with CXL.mem /.cache

及其他:
- The link layer and transaction layer paths have a low latency since they are natively flit based.
This eliminates the higher latency in the PCIe/ CXL.io path due to the support for variable packet size, ordering rules, access rights checks, etc. saving latency due to simplified controller design. - Break out of the PCIe ordering model
Latency saving through out-of-order transfers, write completions - ARB/MUX:
CXL.Cache/Mem protocol muxing at the PHY level (versus higher level of the stack) helps deliver a low latency path for CXL.$Mem traffic. - Coherence Bias
Latency savings with optimized snoop traffic in Device Bias mode
其他的介绍开销的地方,前两个由于使用 FLIT 模式传输,PCIe 协议包耗时的逻辑取消了;第 3 点是硬件期间 ARB/MUX 为协议选择低延迟路径,还是硬件控制器IP 加速了;最后一条是 CXL 协议的功能,设备偏置,有利于加速设备访问主机内存。
下图为 CXL.cache/mem 延迟分布
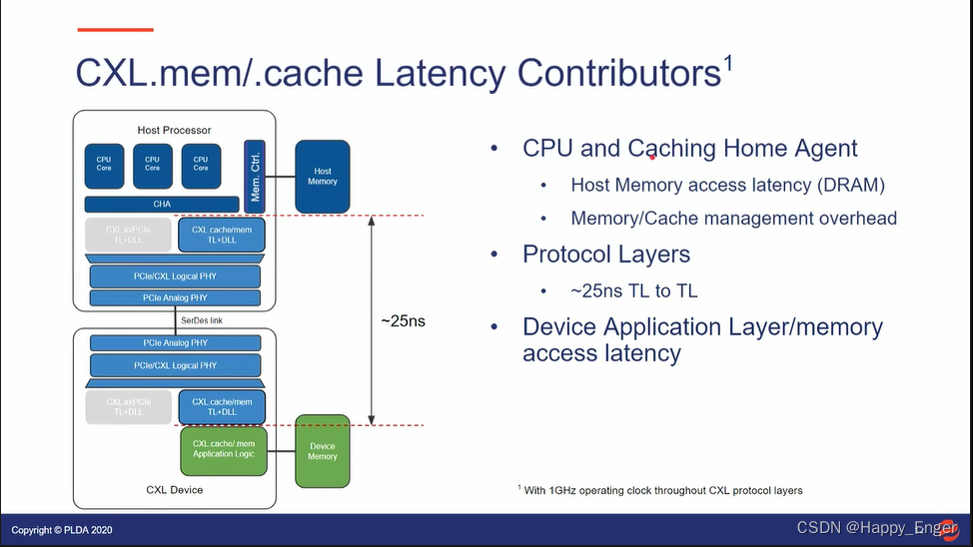
CPU 访问内存以及 Cache 一致性操作;CXL 协议层消耗 25 ns; 设备侧应用层延迟以及内存访问延迟;
下图是一个 Type2 设备读主机内存的时间估计:

请求响应包一个来回共 25 + 25 = 50ns, 主机访问内存消耗 100ns 左右,整体 150ns 左右,外加设备侧应用消耗;
下图为写:
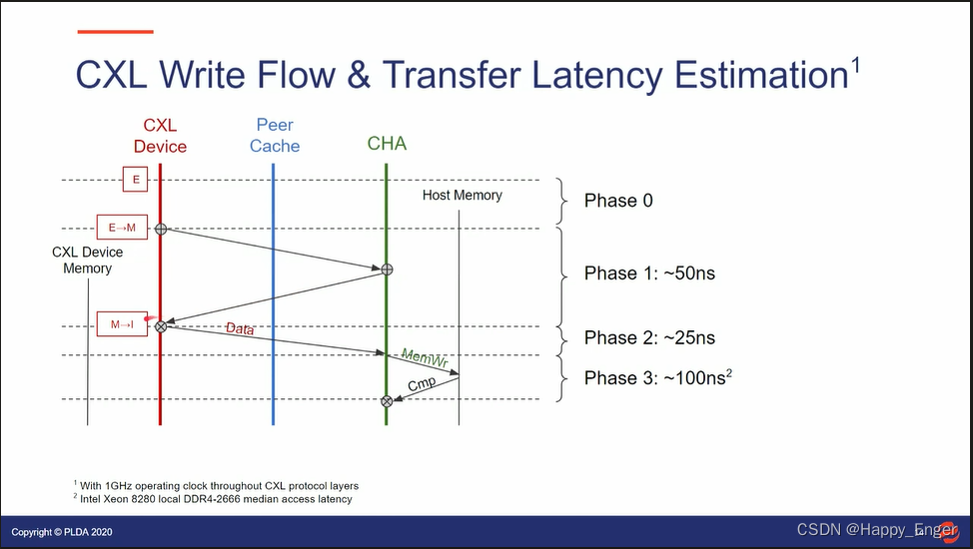
请求与响应一个来回,写操作再携带数据发送一遍,25 + 25 + 25 = 75 ns, 主机侧写内存消耗 100ns 左右,总计 175ns左右。
其他影响延迟的因素:

多处理器环境,以及 snoop 的响应的缓存一致性管理增加延迟,IOMMU 中的虚拟地址到物理地址的转换等也会有影响,不过这是 PCIe 与 CXL 共同面临的问题。
如下是 RAMBUS 公司设计的 CXL Controller IP

控制器与上层接口也使用了 Intel 低延迟的 CPI 接口,控制器也使用了其他技术减少延迟。
总结
由上总结,CXL 比 PCIe 延迟低的原因如下:
- 与PCIe相比,CXL Flit 模式简化控制器设计,控制器其他硬件设计降低延迟, 最少 50 ns-> 25ns;
- Flit 模式增加了少数据量的带宽;
- CXL 协议包降低了数据处理逻辑,取消了排序规则以及DLLP等,节省开销;
- CXL 协议功能取消了内存拷贝,节省开销等;
2. BandWidth
这里的带宽是指每秒传输的有效数据,有效数据即读写的数据。前提,X16 Gen5 在速率 32 GT/s 下原始带宽每个方向 64 GB/s = 32 GT / s * 16 / 8bit。
常见开销
在 68-byte flit 模式下,三种常见开销:
-
128/130 = 0.9846 represents the sync HDR overhead (which can be reclaimed when sync HDR bypass is supported)
这里不是 128/130 编码, 是 Flit 每条Lane上的 2bit的 Sync Header,01代表128bit前插入 Order set block, 10 表示该 block 为 data block
支持 Sync HDR bypass 的时候此开销可以取消 -
374/375 = 0.9973 represents the bandwidth loss due to SKP ordered sets for common clock (higher for other mode)
SKP : 最多 375 字符插入 SKP 方式,达到补偿时钟偏差的目的, PCIe 与 CXL 都有的开销 -
64/68 = 0.9412 representing the flit overhead (2 bytes each for protocol ID and flit CRC).
CXL Flit 模式特有的,前面 2字节 Protocol ID, 后面 2 字节 CRC
FLit 包格式如下图,CRC 画错了,PROTID 与 CRC 之间应该是 4 个 slot 共 64字节:
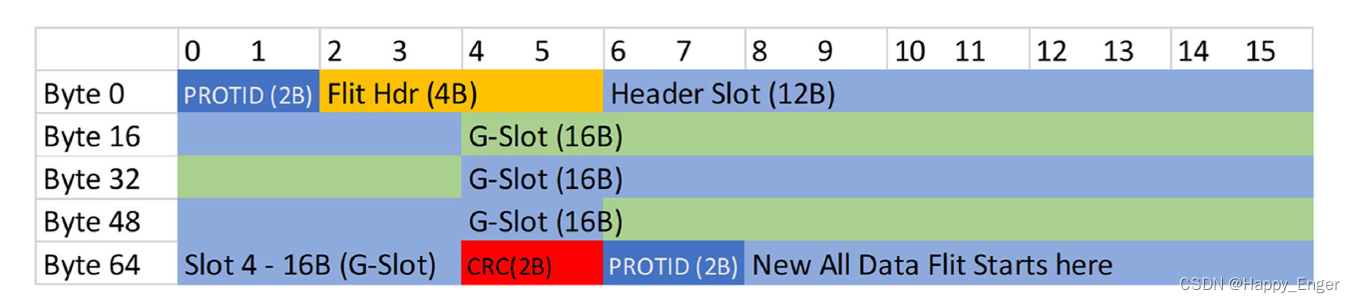
下图也是 68B Flit 包:

由上知链路效率:
使用 HDR Flit 包: 0.9846 * 0.9973 * 0.9412 = 0.9242
关闭 HDR Flit 包: 0.9973 * 0.9412 = 0.9387
CXL.IO Link efficiency
68-byte flit 模式下, 假设DLLP 包损耗 2%, .IO 链路层效率为:
使用 Sync HDR : 0.9242 * (1 - 0.02) = 0.9055
关闭 Sync HDR : 0.9387 * (1 - 0.02) = 0.9199
PCIe Link efficiency
PCIe 不适用 flit 模式,所以第三个开销没有,另外两个开销: 0.9846 * 0.9973 = 0.9819,此外还有 2%的 DLLP 开销,所以总开销为:
0.982 * (1 - 0.02) = 0.9624.
与 CXL.io 相比,PCIe 链路层效率还上升了 6%,主要在 Protocol ID 与 CRC 上。
CXL.IO bandwidth
计算带宽一般是 100% 读,100%写,50%读50%写三种情况,这里就不一一分析了。只分析个简单的 100% 读。
设 D 为数据负载,单位 DW 双字, 1 DW = 4 字节。
IO 里面封装的 TLP 包, TLP 包头是 3-DW for completions and 4-DW for requests (read/write).
An additional overhead of 2-DWs for framing and CRC is incurred per TLP with 68-byte flit (FT_CRC = 2),这里可能是计算的 CXL3.0 256B Flit 的开销。
带宽计算方式如下:
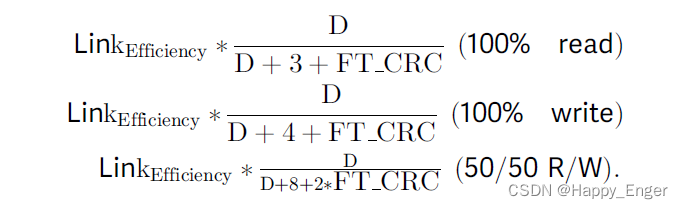
所以 1R0W 的结果为: 0.9199 /6 * 64GB /s = 9.812GB /s, 其他同理。
CXL.IO Bandwidth 结果如下:
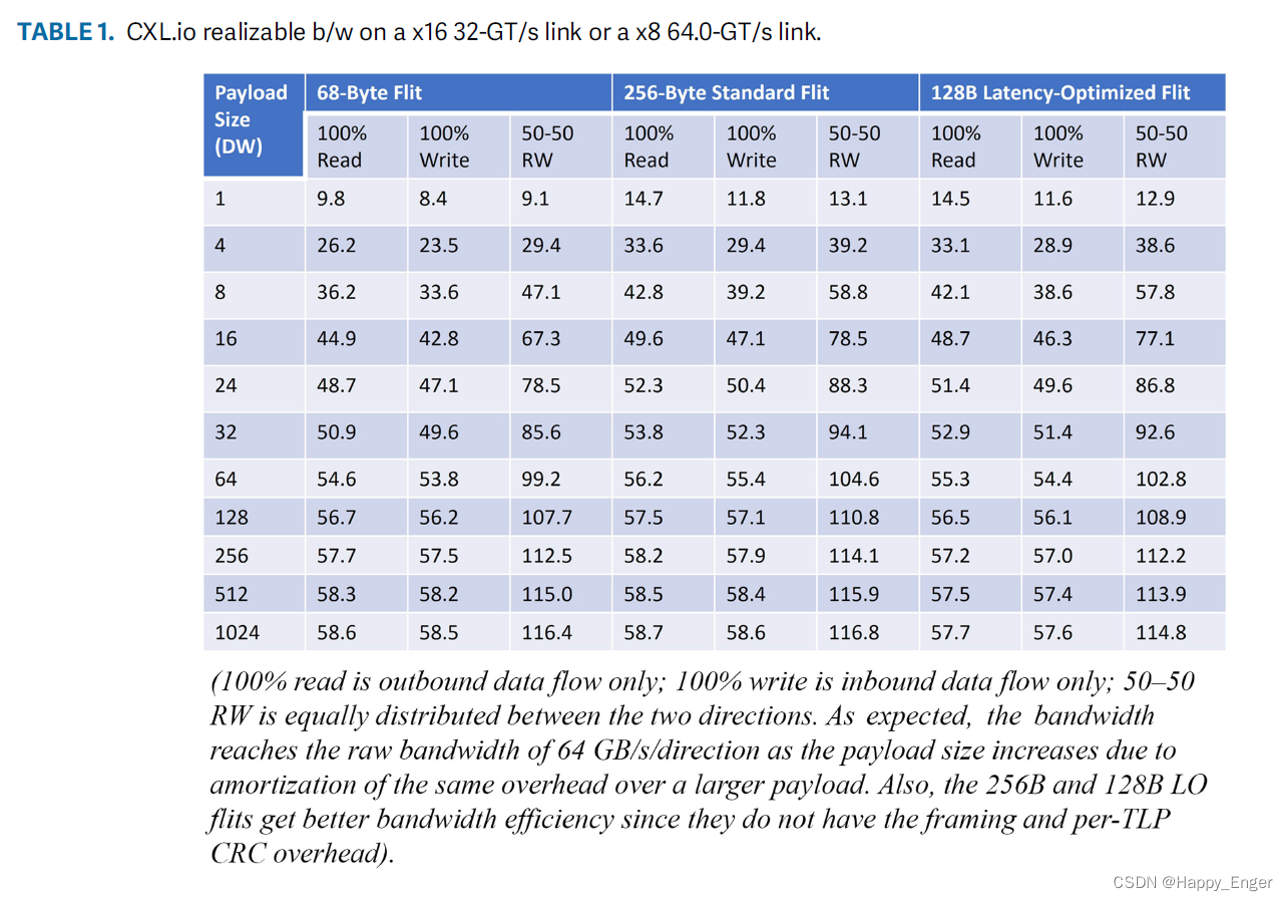
PCIe 与 CXL.IO 差不多,从结果看,少量数据效率低,大量数据效率高,所以,对于大数据量来说, CXL 与 PCIe 相比提高不大,不过对于小数据量的读写访问,比如 8个字节来说,优势则巨大。
CXL.mem/.cache bandwidth
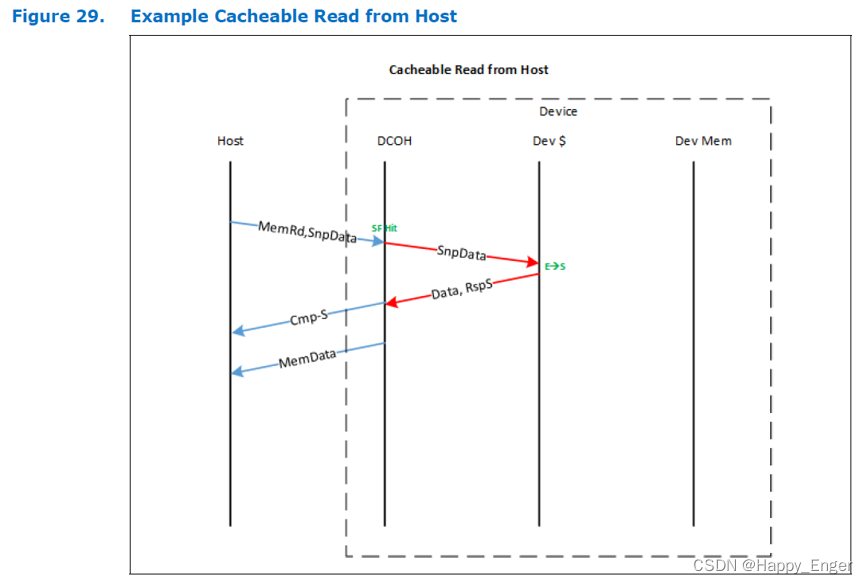
主机读 Type 2 设备内存流程如下图:
主机读 Type 3 设备内存流程如下图:
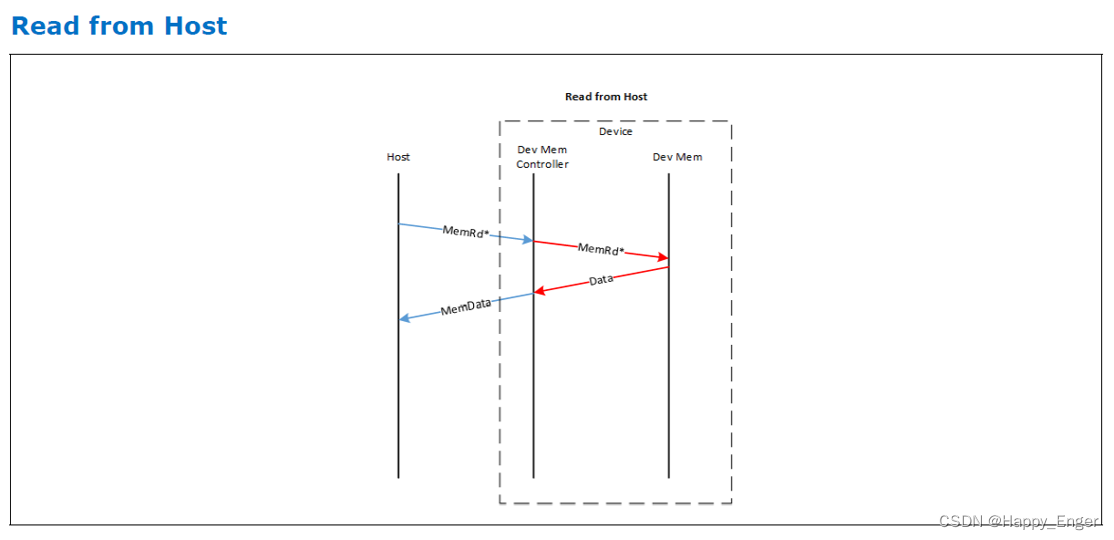
主机读设备,都是发送一个读请求,只不过对于 Type2 设备,会附加缓存状态信息Snoop SnpData, Type2 设备会返回 S2M DRS + NDR, Type3 设备会只返回 S2M DRS,这是 Type2 与 Type3 的重要区别,此条信息值一万。
S2M DRS 是响应数据包,NDR 是无数据响应,用来指示主机缓存状态的,此外都要外加一个缓存行大小的数据 64 字节。
同样,以 1R0W 为例计算带宽,x reads, y writes, 以 slot 为单位,有效数据占 4 slot.
在看下图 S2M DRS + S2M NDR Flit 包
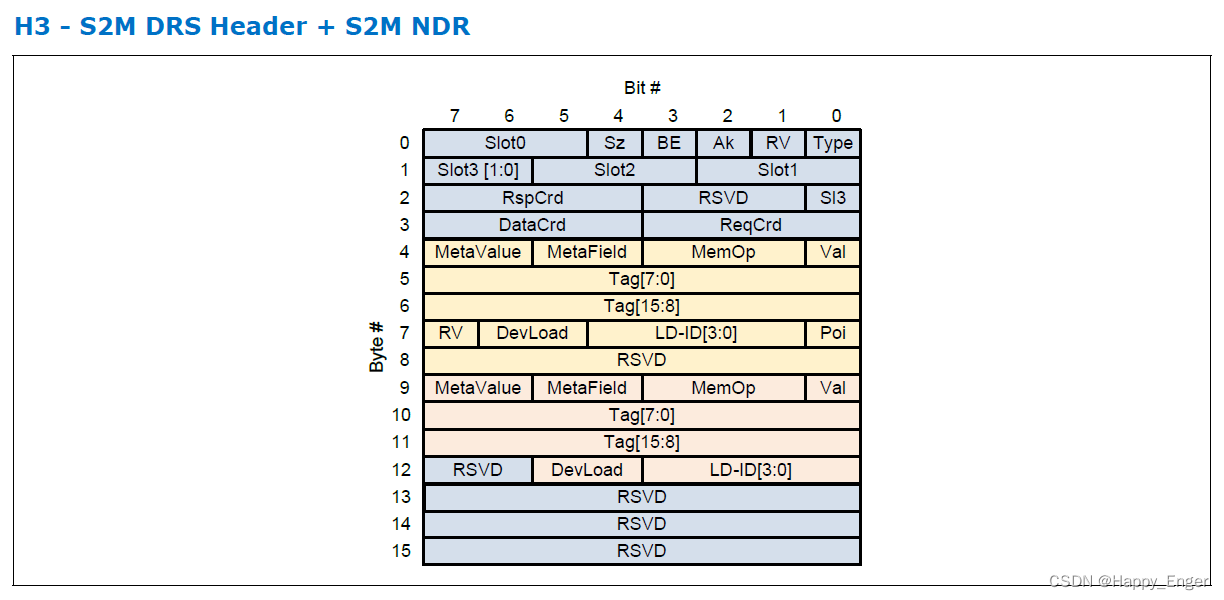
0 - 3 字节为头,4 - 8 字节为 S2M DRS, 9 - 12 字节为 S2M NDR.
所以对于 Type3 来说,S2M DRS 占半个 Slot.
由上可计算得到 S2M 使用的最大 slots 为 (x + y) / 2 + 4x, 有效数据占 4x
则最终 bandwidth 为 LinkEfficiency * 4x / ((x + y) / 2 + 4x) = 0.9387 * 4 / (1/2 + 4) = 0.8344, 0.8344 * 64GB/s = 53.4 GB / s
其他 cache 与 mem bandwidth 计算公式如下图:

结果如下:
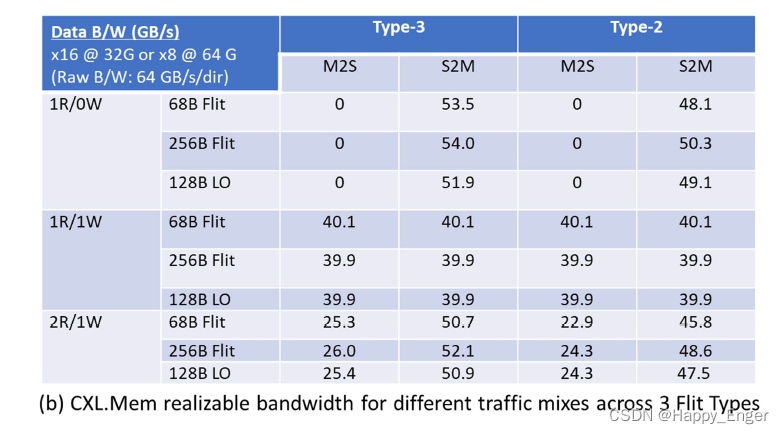
因为PCIe 的有效数据负载是可变的,所以 1DW - 1024 DW 效率随着负载的增多在不断增大,CXL 读写操作的字节长度是 64 字节,读128字节的数据就是发送两个 S2M DRS 包,所以一个方向的带宽是不变的。
打完收工!
参考
- 《Compute Express Link (CXL) Specification Revision 3.0》
- 《An Introduction to the Compute Express LinkTM (CXLTM) Interconnect》
- 《Compute Express Link (CXL): Enabling Heterogeneous Data-Centric Computing With Heterogeneous Memory Hierarchy》
- RAMBUS Company PPT
这篇关于与 PCIe 相比,CXL为何低延迟高带宽?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






