本文主要是介绍Ubuntu20.04与Nvidia显卡:配置Pytorch深度学习环境(Pytorch1.4.0+CUDA10.0+cuDNN7.4) + 远程Jupyter服务 + 配置Pycharm远程连接,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0️⃣ `gcc`降级
- 1️⃣ 配置`Pytorch`深度学习环境与`Nvidia`显卡
- 1️⃣.1️⃣ 配置`Anaconda`
- 1️⃣.1️⃣.1️⃣下载`Anaconda`
- 1️⃣.1️⃣.2️⃣ `conda`换源
- 1️⃣.1️⃣.3️⃣ `conda`创建新环境
- 1️⃣.2️⃣ `Ubuntu20.04`安装`Nvidia`显卡驱动
- 1️⃣.2️⃣.1️⃣ 禁用`nouveau`
- 1️⃣.2️⃣.2️⃣ 控制面板中安装`Nvidia`驱动
- 1️⃣.3️⃣ 配置`CUDA`
- 1️⃣.4️⃣ 配置`cuDNN`
- 1️⃣.5️⃣ 安装`Pytorch`
- 2️⃣ 配置远程`Jupyter Notebook`服务
- 2️⃣.1️⃣ `Ubuntu`服务器设置
- 2️⃣.2️⃣ 本地连接远程服务器
- 2️⃣.3️⃣ `Jupyter Notebook `更换`kernel`
- 3️⃣ `Pycharm Pro`连接服务器运行程序
- 3️⃣.1️⃣ 建立新的`Python Interpreter`
- 3️⃣.2️⃣ 配置`Deployment`
- 3️⃣.3️⃣ 注意事项
- 3️⃣.4️⃣ 环境与包管理
0️⃣ gcc降级
-
因为
Ubuntu20.04自带的gcc版本为9(或者不自带gcc),而CUDA10不支持gcc-9,因此要手动安装gcc-7,命令如下:.sudo apt-get install gcc-7 g++-7 -
设置优先使用
gcc7sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 9 sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-7 9 -
查看当前优先使用的版本:
sudo update-alternatives --display g++
1️⃣ 配置
Pytorch深度学习环境与Nvidia显卡
1️⃣.1️⃣ 配置Anaconda
1️⃣.1️⃣.1️⃣下载Anaconda
-
推荐在清华源进行下载,我选择的是最新的Anaconda3-2020.11-Linux-x86_64.sh,注意版本。
-
复制相应的链接,然后输入下面命令:
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2020.11-Linux-x86_64.sh -
下载完成后,输入:
sh Anaconda3-2020.11-Linux-x86_64.sh -
一直按回车直到下方界面,提示安装路径,这里选择默认路径,直接回车即可,但是到是否将
Anaconda3加入环境变量那里,一定要记得输入yes(我这里就是忘记输入,因为默认是No),否则安装完后,还要重新配置:
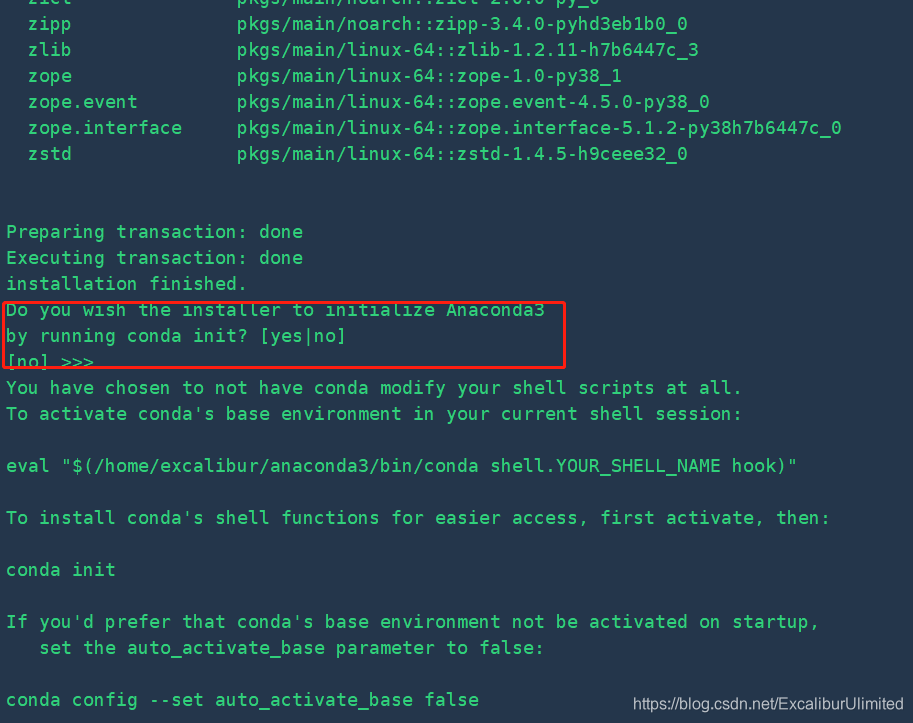
-
(否则就就要编辑
~/.bashrc文件:)sudo vim ~/.bahsrc在最后加入下面的一段:
export PATH=“/home/excalibur/anaconda3/bin:$PATH”其中
excalibur根据自己的用户名修改。 -
接下来验证是否安装成功:
source ~/.bashrc python
1️⃣.1️⃣.2️⃣ conda换源
vim ~/.condarc
-
在文件中加入
channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/- defaultsshow_channel_urls: true
1️⃣.1️⃣.3️⃣ conda创建新环境
-
最好使用
conda创建一个新环境,在新环境中安装各种依赖库和使用代码。因此使用如下命令新建一个名称为“torch”的环境:conda create --name torch python=3.8 -
可以使用
source activate torch来激活环境,可以使用source deactivate来退出环境,让我们source activate torch,此后安装pytorch均在此环境中。
1️⃣.2️⃣ Ubuntu20.04安装Nvidia显卡驱动
1️⃣.2️⃣.1️⃣ 禁用nouveau
为了避免sudo apt-get install nvidia-*安装方式造成登录界面循环,安装nvidia显卡驱动首先需要禁用nouveau,不然会碰到冲突的问题,导致无法安装nvidia显卡驱动。虽然说nouveau貌似默认被禁用了,但是实战表明,只有通过手动禁用才能解决后续的一系列的问题。
-
编辑文件
blacklist.conf:sudo gedit /etc/modprobe.d/blacklist.conf -
在文件最后部分插入以下两行内容:
blacklist nouveau options nouveau modeset=0 -
更新系统:
sudo update-initramfs -u -
重启
sudo reboot -
可以运行下列命令:
lsmod | grep nouveau -
应该是没有输出的,虽然在禁用之前也是没有输出的。
1️⃣.2️⃣.2️⃣ 控制面板中安装Nvidia驱动
-
在“设置”-“关于”中能够显示英伟达的显卡型号:

-
在“软件与更新”-“附加驱动”(
Additional Drivers)中,也能获取显卡驱动: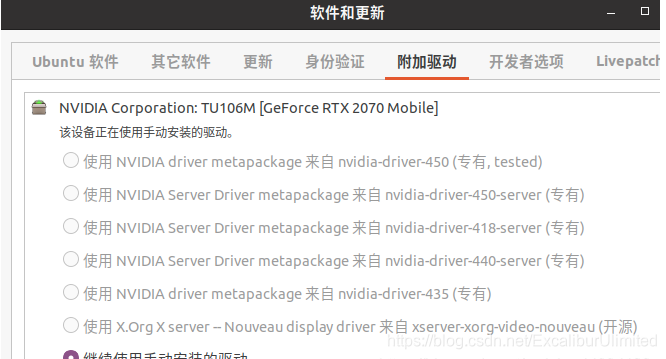
-
选择合适的驱动,
apply然后restart即可。 -
在终端中输入:
nvidia-smi
-
可以看出支持低于11.1的任意
CUDA版本。
1️⃣.3️⃣ 配置CUDA
- 因为后期使用
tensorflow-gpu 2.0.0,所以使用CUDA10.0版本。在英伟达官网中寻找10.0的包,选择18.04的即可(虽然我们的系统是20.04)。

- 最左侧的
runfile格式最为方便,复制下载链接,在终端中输入:
wget https://developer.nvidia.com/compute/cuda/10.0/Prod/local_installers/cuda_10.0.130_410.48_linux
-
连续回车看完协议,然后输入
accept,接下来会有一系列提示,提示是否安装显卡驱动那里选no。(Graphics Driver)其他的均为yes。默认的东西直接回车。
-
安装完毕后,配置环境变量:
vim ~/.bashrc -
加入以下内容:
# add cuda export PATH=/usr/local/cuda-10.0/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64:$LD_LIBRARY_PATH -
在终端输入:
source ~/.bashrc -
刷新一下环境变量。然后检查
CUDA是否安装成功:nvcc -V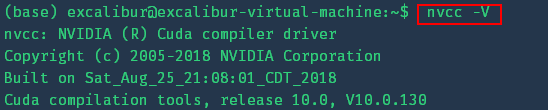
-
出现信息即安装成功;
-
然后再编译测试:
cd ~/NVIDIA_CUDA-10.0_Samples/0_Simple/vectorAdd make sudo ./vectorAdd
-
提示测试通过。
1️⃣.4️⃣ 配置cuDNN
- 进入cuDNN网址,这里选择了
7.4.1版本,这里需要注册登陆。

-
下载对应linux版本的cuDNN Library for Linux (x86_64)
-
在下载目录运行:
tar -zxf cudnn-10.0-linux-x64-v7.4.1.5.tgz cd cuda sudo cp lib64/* /usr/local/cuda/lib64/ sudo cp include/* /usr/local/cuda/include/
1️⃣.5️⃣ 安装Pytorch
-
激活之前创建的
torch环境:source activate torch -
安装:
conda install pytorch torchvision cudatoolkit=10.0 -
由于更换了
conda源,因此下载会很快。正是因为换源了,所以命令末尾没有-c pytorch。 -
在终端:
python -
>>> import torch >>> >>> import torchvision >>> >>> torch.cuda.is_available() True -
显示
True,证明pytorch成功识别CUDA。
2️⃣ 配置远程Jupyter Notebook服务
介绍如何在自己本地浏览器使用jupyter notebook连接远程服务器。
2️⃣.1️⃣ Ubuntu服务器设置
-
首先要在
Ubuntu服务器上的base环境下安装Jupyter Notebook:pip install jupyter -
生成
Jupyter Notebook配置文件:jupyter notebook --generate-config -
配置
Jupyter Notebook密码:jupyter notebook password -
配置
jupyter_notebook_config.py文件:vim ~/.jupyter/jupyter_notebook_config.py -
在最后一行后加入如下配置信息(
vim编辑器按A键进行编辑):c.NotebookApp.allow_remote_access = True c.NotebookApp.open_browser = False c.NotebookApp.ip = '*' c.NotebookApp.allow_root = True c.NotebookApp.port = 8888 #端口可以更改 -
添加完成后按
ESC,:wq退出并保存,Ubuntu服务器上的配置就完成了。
2️⃣.2️⃣ 本地连接远程服务器
-
首先在
Ubuntu服务器上启动Jupyter Notebook,这会保证服务一直开着,即使SSH断开连接:nohup jupyter notebook --no-browser --port=8889 --ip=127.0.0.1 & -
然后在本地转发端口,用
win+R打开cmd, 进入终端,输入:ssh -N -f -L localhost:8888:localhost:8889 -p 22 remote_user@remote_host # 填写服务器用户名和IP -
按照提示输入服务器密码即可,在本地浏览器网址栏输入http://127.0.0.1:8888,然后就可以看到
jupyter-notebook登录界面了。输入设置好的密码即可。
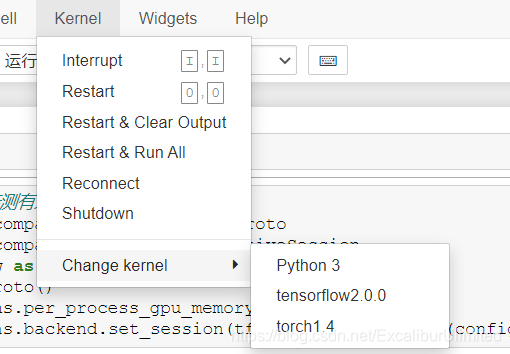
2️⃣.3️⃣ Jupyter Notebook更换kernel
-
首先我们在
anaconda3的base环境里,激活我们要用到的环境:conda activate 环境名 -
然后安装
ipykernel:conda install nb_conda_kernels -
最后将环境写入
Jupyter notebook中的kernel里:python -m ipykernel install --user --name 环境名 --display-name "显示的名称" -
完成。
3️⃣ Pycharm Pro连接服务器运行程序
- 只有
Pycharm Pro版本才具有此功能。
首先打开项目文件如下:

3️⃣.1️⃣ 建立新的Python Interpreter
File—>Settings—>Python Interpreter,然后Add建立新的解释器:
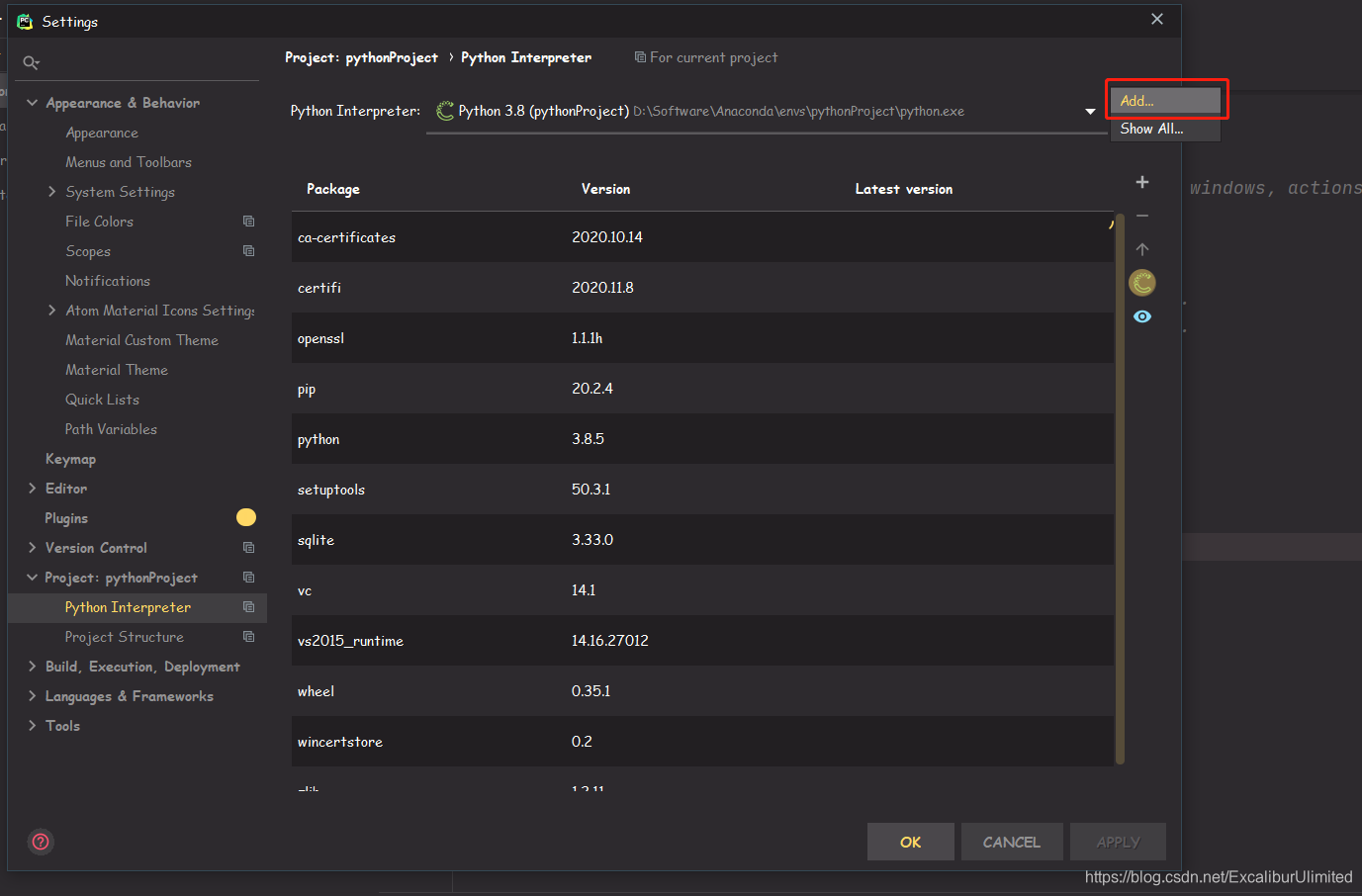
-
点击
SSH Interpreter,建立新服务器连接,填入服务器IP和用户名: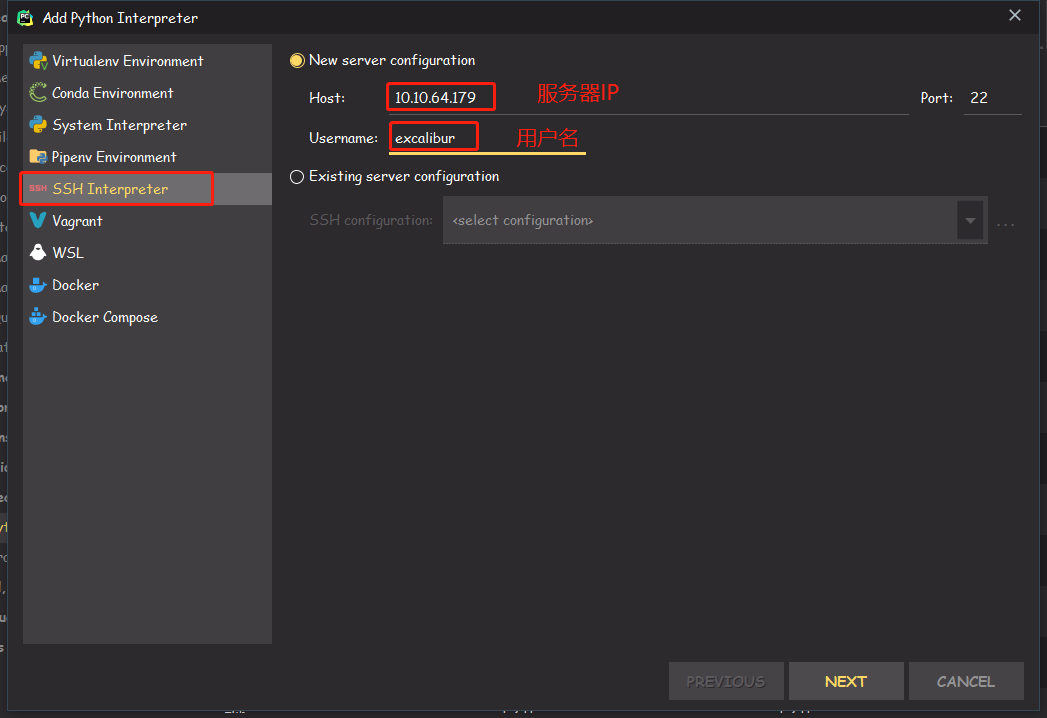
-
然后填入密码:
111111,下一步:
-
这里
Interpreter的默认路径:/usr/bin/python3,链接的是基础的Anaconda3自带的Python3环境,如果想使用建立的Pytorch1.4.0环境,则需要使用这个路径:/home/excalibur/anaconda3/envs/torch/bin/python,这个/torch/是我自己命名的,如果以后新建其他环境使用,整个路径只需要改变这个字段即可。然后勾上使用sudo命令,然后还要修改一下本地代码部署到服务器的文件地址,为了养成良好的使用习惯,建议使用类似这样的地址:/pycharm_project/xxx后面的xxx就是你想要放的文件夹,最后Finish,按照提示输入sudo密码:111111,然后Apply,接着OK。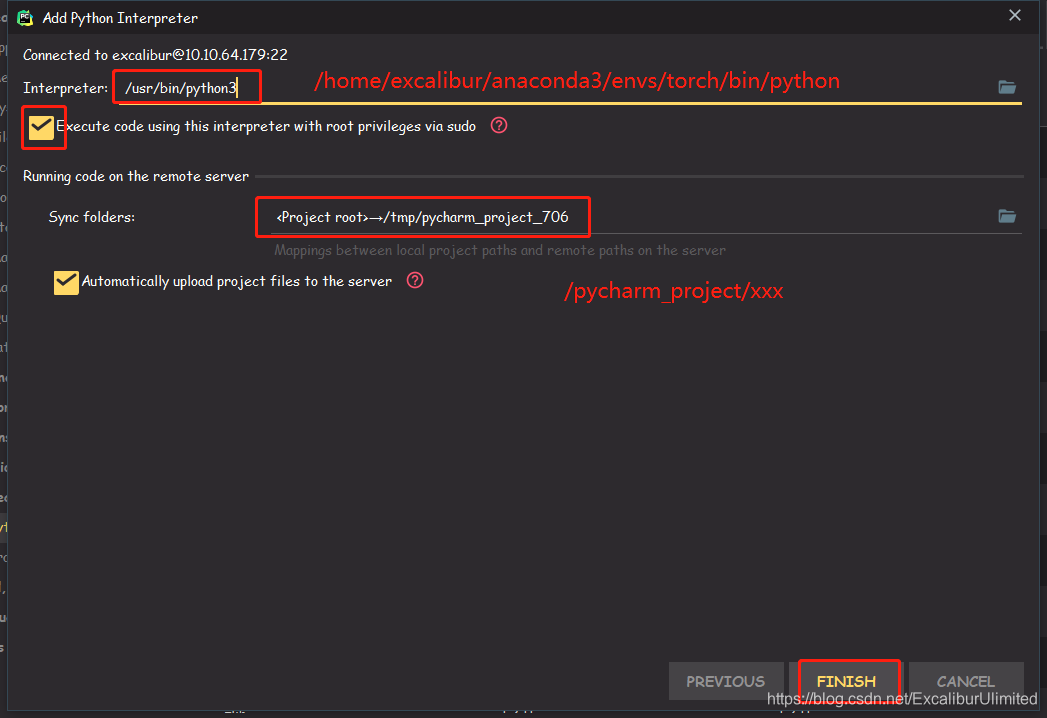
-
此时可能会提示上传文件失败,permission denied,不用管。

3️⃣.2️⃣ 配置Deployment
-
Tools—>Deployment—>Configuration...
-
点一下
AUTODETECT,这一步至关重要,然后再点Mappings,主要看一下刚刚配置的Deployment Path是否正确,然后OK即可。
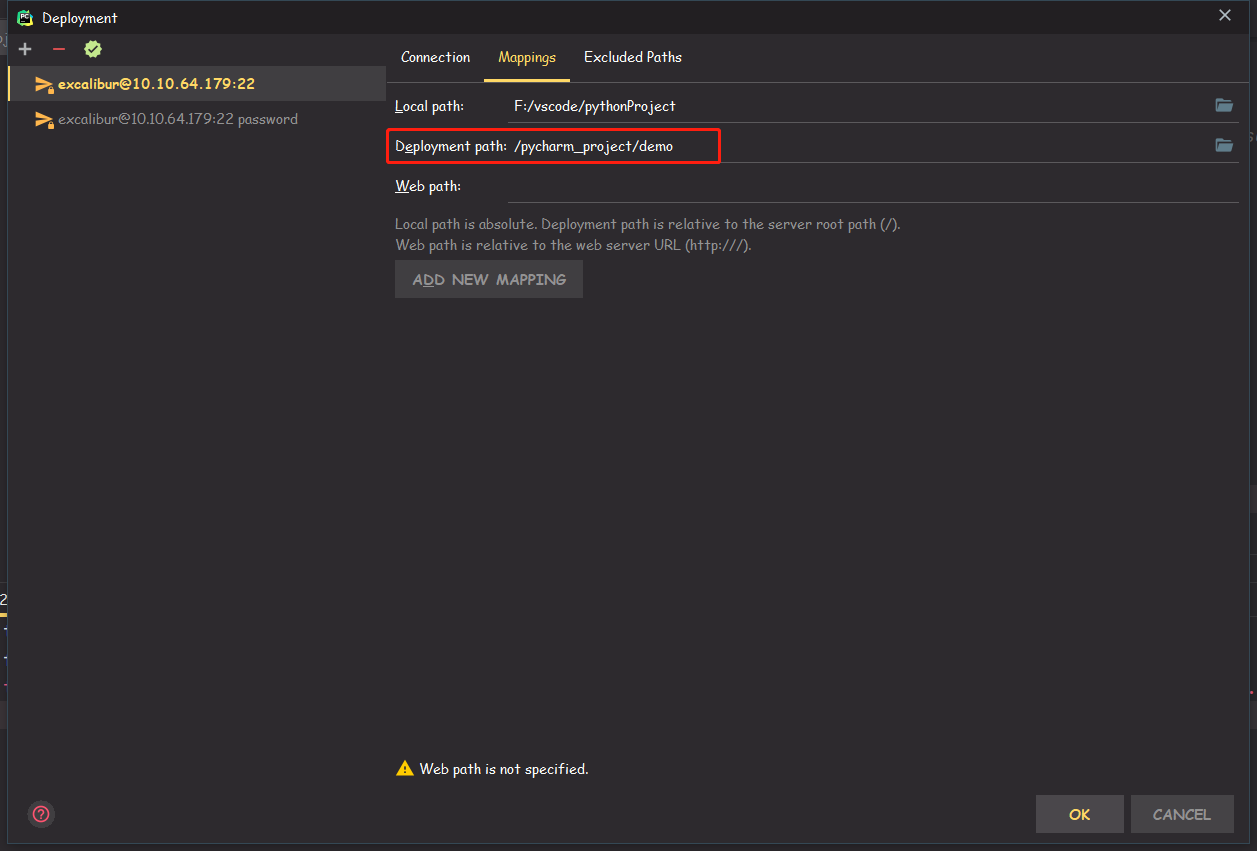
-
将鼠标放置在整个文件夹目录上,然后
Tools—>Deployment—>Upload to ...,就会把整个程序文件上传到你之前指定的目录那里。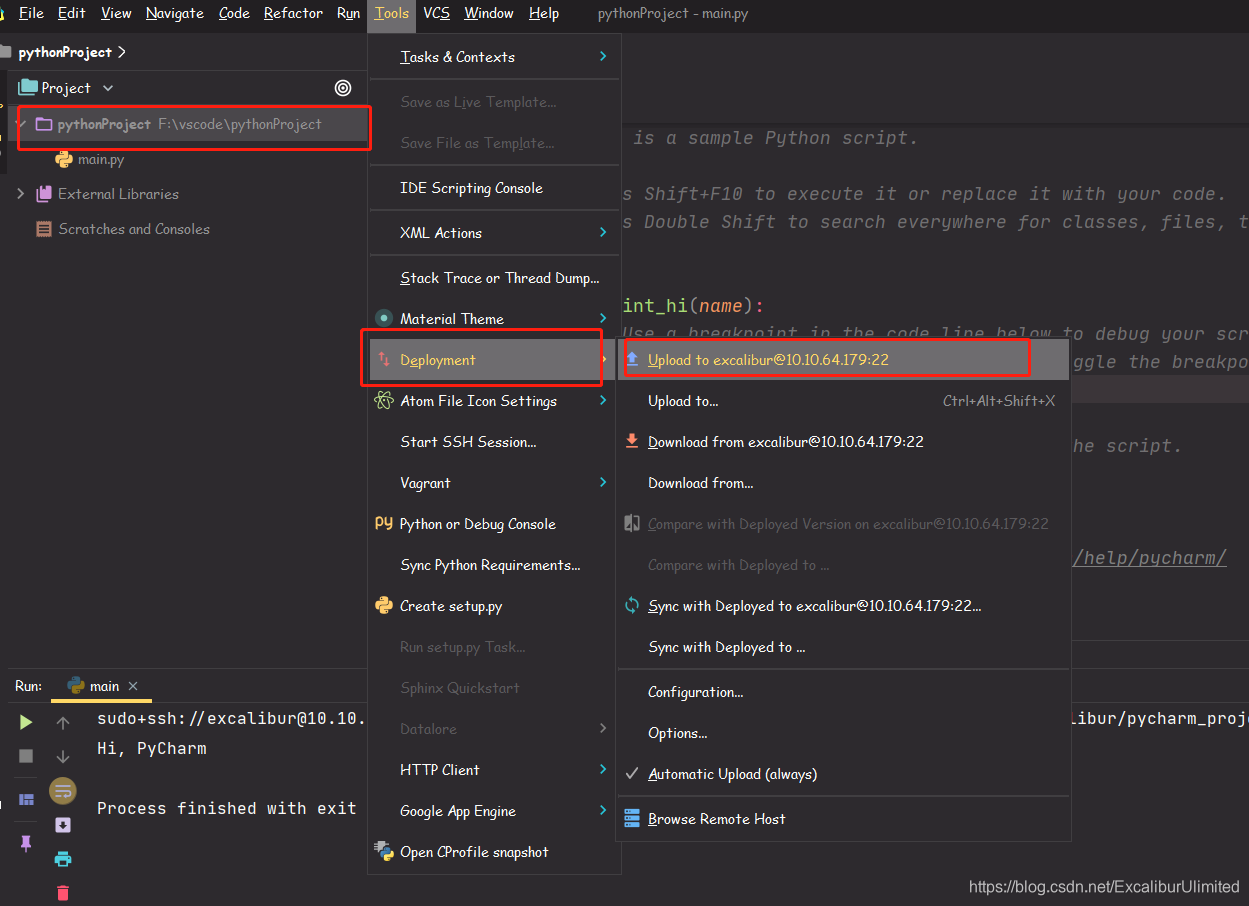
-
等待上传完成。

-
然后
Edit Configuration。
-
确保
Python Interpreter是刚才设置的解释器。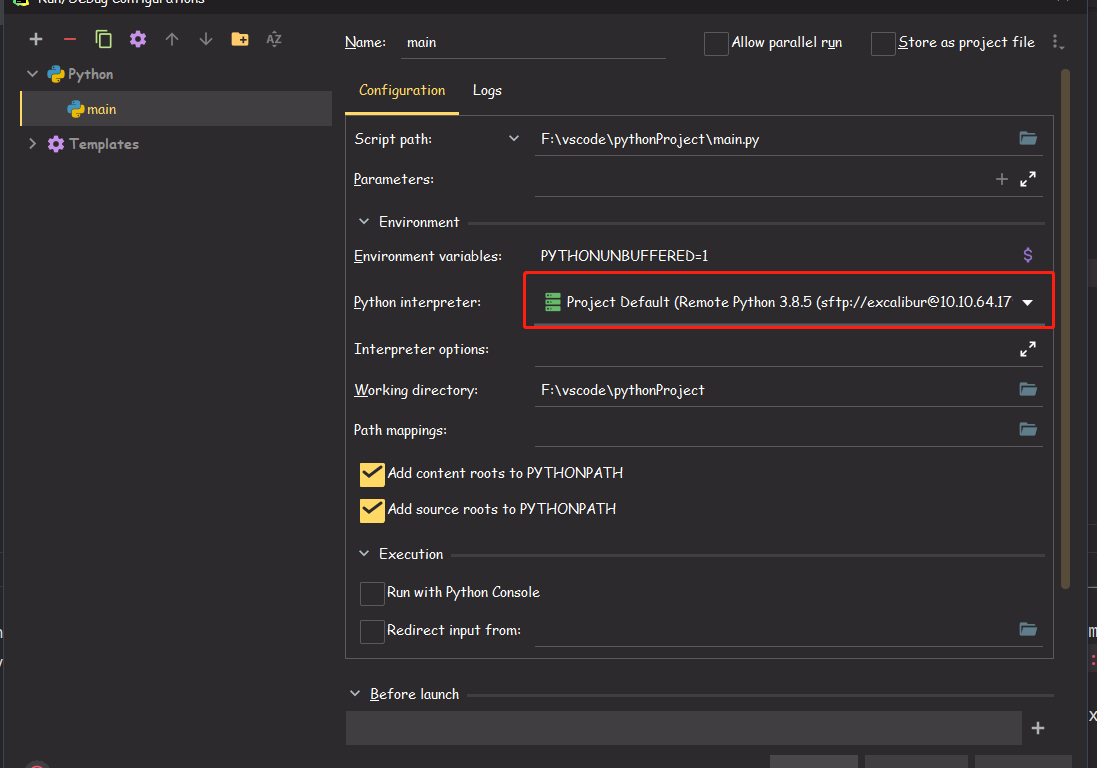
-
直接点击绿色三角运行,或者右击文件
run运行即可,结果为:
3️⃣.3️⃣ 注意事项
- 每次修改程序后,记得保存。然后像之前那样上传到服务器保持一致,否则运行的还是没有修改之前的存在服务器的版本。当程序运行会生成数据文件时,也要记得在
Deployment里面Download到本地,Overwrite本地的文件。
3️⃣.4️⃣ 环境与包管理
-
当现有的环境中缺包时,先连接到服务器,工具有(
Xshell,FinalShell,MobaXterm)等。然后切换到那个环境,如切换到torch环境:conda activate torch-
相应的,命令行前面的前缀会变成环境名称。
-

-
接着安装想要安装的包,如想要
matplotlib,直接: -
pip install matplotlib -
退出环境使用:
-
conda deactivate torch
-
-
当需要新的环境时,如需要建立名为
tensorflow2.0.0,Python版本为3.8的环境,直接:-
conda create --name tensorflow2.0.0 python=3.8
-
至此,本文完结!✨✨✨
这篇关于Ubuntu20.04与Nvidia显卡:配置Pytorch深度学习环境(Pytorch1.4.0+CUDA10.0+cuDNN7.4) + 远程Jupyter服务 + 配置Pycharm远程连接的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






