本文主要是介绍【Keras学习笔记】10:IMDb电影评价数据集文本分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
读取数据
import keras
from keras import layers
import numpy as np
from matplotlib import pyplot as plt
import pandas as pd
%matplotlib inline
Using TensorFlow backend.
data = keras.datasets.imdb
# 最多提取10000个单词,多的不要
(x_train, y_train), (x_test, y_test) = data.load_data(num_words=10000)
Downloading data from https://s3.amazonaws.com/text-datasets/imdb.npz
17465344/17464789 [==============================] - 761s 44us/step
x_train.shape, y_train.shape, x_test.shape, y_test.shape
((25000,), (25000,), (25000,), (25000,))
数据集已经为每个单词做好数字编码了,所以得到的每个样本都是一个整数形式的向量:
# 看一下第一个样本的前10个单词的数字编码
x_train[0][:10]
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65]
# 标签y是非0即1的,表示负面和正面评价
y_train
array([1, 0, 0, ..., 0, 1, 0], dtype=int64)
不妨恢复一条样本看一下原始形式是什么样子的。
# 这个得到的是一个字典,里面是{单词:数字序号,单词:数字序号,...}
word_index = data.get_word_index()
Downloading data from https://s3.amazonaws.com/text-datasets/imdb_word_index.json
1646592/1641221 [==============================] - 100s 61us/step
现在要根据数字序号去得到单词,所以把这个字典的k-v反转一下。这里用生成器来将其反转,再转换成字典。
index_word = dict((value, key) for key, value in word_index.items())
用生成器将第一个样本转换成单词序列,注意这个数据集的word=>index映射时是从0开始编码的,但前面得到的word_index里保留了0,1,2三个编码,也就是所有编码加了3,,这里将其减掉。另外,有些词在word_index里找不到,不妨在找不到时候就给个?标识。
" ".join(index_word.get(index-3,'?') for index in x_train[0])
"? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ? father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for ? and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also ? to the two little boy's that played the ? of norman and paul they were just brilliant children are often left out of the ? list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
样本有的很短,有的很长,看一下前10个样本的长度:
[len(seq) for seq in x_train[:10]]
[218, 189, 141, 550, 147, 43, 123, 562, 233, 130]
但一定不会超过读取数据集时定义的最大长度10000:
max(max(seq) for seq in x_train)
9999
文本的向量化
因为有10000个单词,可以使用长度为10000的向量,然后将每个词对应一个索引,如果一个词在一条样本中出现了,就将相应位置设置成1(或者+1),这就是次袋模型。
如果设置成1(而不是+1),那么这个向量是有很多为1的分量,其余位置都是0,在学习视频里老师叫它k-hot编码(没查到有这种叫法,估计又是自己扯的),了解一下就好。
def k_hot(seqs, dim=10000):"""数字编码转k-hot编码"""res = np.zeros((len(seqs), dim))for i, seq in enumerate(seqs):res[i, seq] = 1return res
x_tr = k_hot(x_train)
x_tr.shape
(25000, 10000)
x_ts = k_hot(x_test)
x_ts.shape
(25000, 10000)
建立模型和训练
model = keras.Sequential()
model.add(layers.Dense(32, input_dim=10000, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 32) 320032
_________________________________________________________________
dense_5 (Dense) (None, 32) 1056
_________________________________________________________________
dense_6 (Dense) (None, 1) 33
=================================================================
Total params: 321,121
Trainable params: 321,121
Non-trainable params: 0
_________________________________________________________________
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['acc']
)
history = model.fit(x_tr, y_train, epochs=15, batch_size=256, validation_data=(x_ts, y_test), verbose=0)
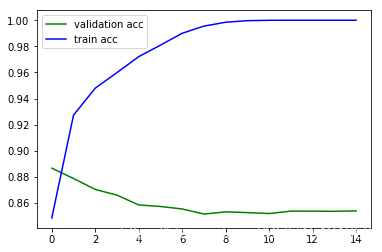
plt.plot(history.epoch, history.history.get('val_acc'), c='g', label='validation acc')
plt.plot(history.epoch, history.history.get('acc'), c='b', label='train acc')
plt.legend()
<matplotlib.legend.Legend at 0x1890b908>
plt.plot(history.epoch, history.history.get('val_loss'), c='g', label='validation loss')
plt.plot(history.epoch, history.history.get('loss'), c='b', label='train loss')
plt.legend()
<matplotlib.legend.Legend at 0x189b79e8>
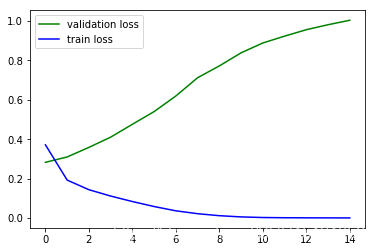
可以看到发生了严重的过拟合,下面尝试引入Dropout和正则化项,同时减小网络的规模。
模型优化
from keras import regularizers
model = keras.Sequential()
model.add(layers.Dense(8, input_dim=10000, activation='relu', kernel_regularizer=regularizers.l2(0.005)))
model.add(layers.Dropout(rate=0.4)) # keeep_prob=0.6
model.add(layers.Dense(8, activation='relu', kernel_regularizer=regularizers.l2(0.005)))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_13 (Dense) (None, 8) 80008
_________________________________________________________________
dropout_3 (Dropout) (None, 8) 0
_________________________________________________________________
dense_14 (Dense) (None, 8) 72
_________________________________________________________________
dense_15 (Dense) (None, 1) 9
=================================================================
Total params: 80,089
Trainable params: 80,089
Non-trainable params: 0
_________________________________________________________________
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['acc']
)
history = model.fit(x_tr, y_train, epochs=15, batch_size=256, validation_data=(x_ts, y_test), verbose=0)
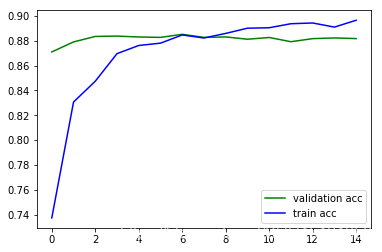
plt.plot(history.epoch, history.history.get('val_acc'), c='g', label='validation acc')
plt.plot(history.epoch, history.history.get('acc'), c='b', label='train acc')
plt.legend()
<matplotlib.legend.Legend at 0x1b2a4f28>
plt.plot(history.epoch, history.history.get('val_loss'), c='g', label='validation loss')
plt.plot(history.epoch, history.history.get('loss'), c='b', label='train loss')
plt.legend()
<matplotlib.legend.Legend at 0x1b319208>
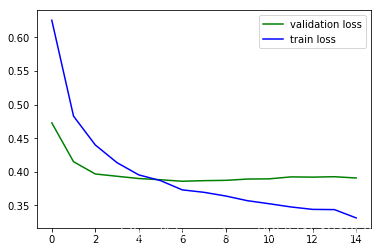
好了很多。
这篇关于【Keras学习笔记】10:IMDb电影评价数据集文本分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




