本文主要是介绍低光图像增强论文GLADNet: Low-Light Enhancement Network with Global Awareness阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8373911
项目地址:https://github.com/weichen582/GLADNet
作者:北大
来源:IEEE2018
abstract
在这篇文章中,我们讨论了微光增强的问题。我们的核心思想是先计算出弱光输入的全局光照估计,然后在估计的指导下调整光照,并通过与原始输入的级联来补充细节。考虑到这一点,我们提出了一个全局照明和细节保护网络(GLADNet)。输入图像被重新缩放到一定的大小,然后放入编解码网络中生成全局照明先验知识。基于全局先验和原始输入图像,采用卷积网络进行细节重建。为了训练GLADNet,我们使用一个由raw图像生成的合成数据集。大量的实验表明,在不同条件下拍摄的真实微光图像上,我们的方法优于其他比较方法。
I. INTRODUCTION
balabala
本文提出了一种全局光照感知和细节保持网络(GLADNet)。该网络的体系结构可分为两个步骤。为了得到全局光照预测,首先将图像下采样到一定的大小,然后通过编解码网络,我们称之为全局光照估计步骤。编解码器的瓶颈层有一个覆盖整个图像的接收场。第二步是细节重建步骤,这有助于补充在重新缩放过程中丢失的细节。为了训练这样一个网络,我们从不同条件下捕获的原始图像合成训练数据集,并使用L1范数作为损失函数。GLADNet的效果是在真实图像上进行评估并与其他的sota方法进行了比较。大量的实验证明了我们的方法优于其他比较方法。
II. PROPOSED METHOD
该网络的结构包括两个步骤。一种用于全局光照估计,另一种用于细节重建。
如图1所示,在全局照明估计步骤中,输入被下采样到固定大小。然后,特征映射通过编解码网络传递。在瓶颈层,估计全局光照。在缩小到原始尺寸后,得到整个图像的照明预测。在全局光照估计步骤之后是细节重建步骤。三个卷积层参考全局级光照预测调整输入图像的光照,同时填充下采样和上采样过程中丢失的细节。

A. Global illumination estimation
全局光照估计步骤包括三个子步骤:将输入图像缩放到一定的分辨率,通过编解码网络进行全局光照预测,然后将其重新缩放到原始分辨率。
首先,通过最近邻插值将输入下采样到一定尺寸的W0×H0。接着是带有ReLU的卷积层。然后,特征映射通过一系列级联的采样块。根据w0和H0精心设计下采样块的数目,使编解码网络瓶颈层的接收场能够覆盖整个图像。因此,该网络对整个照明分布具有全局意识。这种设计还可以减少所需的存储空间,提高网络的效率。通过一系列对称上采样块,得到了用于光照预测的W0×h0特征图。通过另一个上采样块,将特征映射重新缩放为原始输入的大小。
从下采样块到相应的镜像上采样块引入跳跃连接。下采样块的输出被传递到上采样块的特征映射并与之相加。这迫使网络学习残差,而不是预测实际像素值。
下采样块由一个具有步长2的卷积层和一个ReLU组成。在上采样块中,resize-convolutional layers [9]被用来代替正常的反卷积层。与常规的反卷积层不同,resize-convolutional layers 避免了棋盘格纹的伪影,并且对输入图像的大小没有限制。resize-convolutional layers 由一个最近邻插值操作、一个具有步长2的卷积层和一个ReLU组成。
B. Details reconstruction
第一步是从全局角度生成光照估计。但是,由于重新缩放过程而丢失了详细信息。为了解决这个问题,我们提出了一个详细的重建过程。
原始输入被认为比编解码器网络的输出包含更多的细节,因此可以为细节恢复提供信息。最后一步的图像特征和光照信息都可以通过下一步的图像拼接来实现。连接层后面是三个带ReLUs的卷积层。它将输入的图像信息与估计的全局光照信息相结合,最终生成具有更好细节的增强效果。
C. Loss function
训练过程是通过最小化恢复图像F(X,Θ)和对应的地面真实图像Y之间的损失来实现的。我们这里用L1范数。L2范数可以更好地去除增强结果中的噪声和振铃效应[10]。损失函数可以写成:
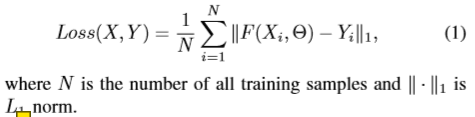
另外,红、绿、蓝通道在损失函数中有各自的权重:(0.29891,0.58661,0.11448),这与RGB图像到灰度图像的转换权重相同。这有助于保持颜色平衡并提高网络的健壮性。
III. EXPERIMENTS
A. Dataset generation
我们使用合成对作为训练数据。与[8][11]在8位RGB图像上合成对不同,我们在原始图像上合成对。在8位RGB图像上计算可能会导致只有256个值的信息丢失。在原始图像上,所有的调整都是在一个步骤中对原始数据执行的,从而获得更精确的结果。
我们从RAISE[12]收集了780个原始图像,700个用于生成用于训练的对,80个用于验证。Adobe Photoshop Lightroom为原始图像提供了一系列参数来进行调整。包括曝光、振动和对比度。我们通过将曝光参数E设置为[-5,0],振动参数V设置为[-100,0],对比度参数C设置为[-100,0],来合成微光图像。为了防止颜色偏差,我们在训练数据集中加入700个灰度图像对,并将其转换为彩色图像对。为了使增强前后的黑白区域保持一致,我们增加了五对黑和五对白的训练对。最后,将所有图像调整为400×600并转换为便携式网络图形格式。
B. Network training
GLADNet的卷积核大小设置为3×3。w0和H0都设置为96。编解码结构有五个下采样块和五个相应的上采样块。该设计使得编解码网络中的瓶颈层的尺寸为3×3,使接收场能够覆盖整个图像。
我们使用[13]提出的初始化方法初始化权重。Adam作为优化器,mini-batch为8。我们从1e−3的学习率开始,每100batch后乘以0.96。这个模型被训练了50个epoch。
C. Subjective evaluation
尽管GLADNet是根据合成数据训练的,但我们在真实曝光不足的图像上评估其性能。我们将GLADNet与几种最先进的方法进行了比较,其中包括带颜色恢复的多尺度Retinex(MSRCR)[3]、基于dehazing的方法(DeHz)[6]、基于照度估计的方法(LIME)[4]和同时反射和光照估计(SRIE)[5]。这里我们展示几个主观结果。关于增强图像质量和运行时分析的定量结果可以在我们的项目网站1中找到。
图2显示了测试数据集中的三组视觉比较。我们可以看到,MSRCR可以完全照亮图像,但结果有点苍白。LIME的效果在视觉上是令人愉快的,但明亮的区域被过度增强,细节丢失。例如,在“房子”和“中国花园”中,树木后面的天空区域过度暴露。DeHZ的结果在边缘有伪影,这降低了增强结果的视觉美感。另一方面,SRIE对微光图像的亮度改善不够,细节看不清。在“中国花园”里,展馆上方的瓷砖仍然看不见。

与其他方法相比,我们的方法产生了更生动自然的结果。由于GLADNet对输入具有全局感知能力,可以同时调整整个图像,因此可以避免在较亮区域过度曝光和在较暗区域曝光不足。此外,增强后的细节仍然保持不变,这得益于细节重建步骤。
D. Applications on Computer Vision
GLADNet的主要应用之一是帮助提高其他计算机视觉任务的性能,例如目标检测和识别。由于大多数视觉识别模型都是基于高质量的数据,低能见度、雾度和低照度等恶劣条件会大大降低这些算法的性能。
为了说明我们的方法对提高目标识别性能的有效性,我们在Google Cloud Vision API2上测试了几幅真实的微光图像及其相应的增强效果,该软件可以通过机器学习模型来理解图像的内容,并将其分为上千个类别。
图3示出成对结果之一。原始图像来自MEF数据集。由于光照不足,google cloud vision只能将图像标记为“天空”、“云”和“尖顶”。增强后的前景埃菲尔铁塔被成功地检测到,并用绿盒进行了精确标记,说明了该方法的有效性。

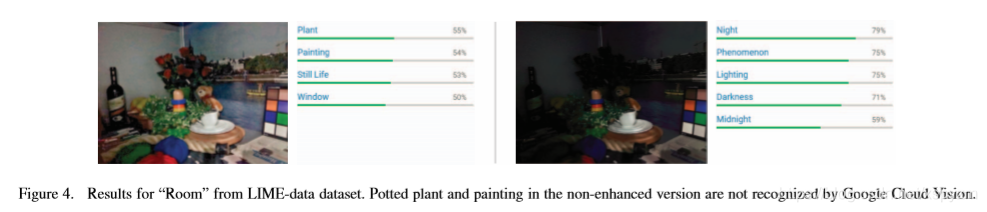
另一个例子来自LIME数据集。在增强之前,标签被固定在“夜晚”和“现象”上。盆栽、绘画和其他物品太暗,无法被发现。如图4所示,GLADNet帮助google cloud vision api识别图片中的对象。
IV. CONCLUSIONS
本文提出了一种全局光照感知和细节保持网络。该架构包括两个步骤。首先,编解码器网络从全局角度获得固定大小的照明预测。然后,卷积网络利用光照预测和原始输入重建细节。结果表明,我们的方法优于其他最先进的方法。
这篇关于低光图像增强论文GLADNet: Low-Light Enhancement Network with Global Awareness阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






