本文主要是介绍UNETR:用于三维医学图像分割的Transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接:https://arxiv.org/abs/2103.10504
代码链接: https://monai.io/research/unetr
机构:Vanderbilt University, NVIDIA
最近琢磨不出来怎么把3d体数据和文本在cnn中融合,因为确实存在在2d里面用的transformer用在3d里面会爆炸这回事,所以干脆去找个经典3d transformer+cnn的好了。要是有知道朋友也可以一起讨论一下。因为是两年前的文章,所以这篇博文主要集中写方法了。
*妈耶,没想到真的部分解决我的疑问了,好的洛阳铲,爱来自中国
摘要
近十年来,具有收缩和扩展路径的全卷积神经网络(fcnn)在大多数医学图像分割应用中表现出突出的特点。在fcnn中,编码器通过学习全局和局部特征以及上下文表示来发挥不可或缺的作用,这些特征和上下文表示可用于解码器的语义输出预测。尽管取得了成功,但fcnn中卷积层的局部性限制了学习远程空间依赖关系的能力。受自然语言处理(NLP)在远程序列学习中最近成功的启发,我们将体积(3D)医学图像分割任务重新制定为序列到序列的预测问题。我们引入了一种新的架构,称为UNEt-TRansformer(UNETR),它利用Transformer作为编码器来学习输入体积的序列表示并有效捕获全局多尺度信息,同时也遵循编码器和解码器的成功“u形”网络设计。Transformer 编码器通过不同分辨率的跳过连接直接连接到解码器,以计算最终的语义分割输出。我们已经在用于多器官分割的多图谱标记颅顶(BTCV)数据集和用于脑肿瘤和脾脏分割任务的医学分割十项全能(MSD)数据集上验证了我们的方法的性能。我们的基准测试在BTCV排行榜上展示了新的最先进的性能。
背景
fcnn不能有效捕捉全局信息,transformer难以有效捕捉局部信息
我们将3D分割任务重新制定为一维seq to seq 的预测问题,并使用Transformer作为编码器从嵌入的输入补丁中学习上下文信息。从Transformer编码器中提取的表示通过多个分辨率的跳过连接与基于cnn的解码器合并,以预测分割输出。在解码器中我们使用cnn,这是因为Transformer虽然具有学习全局信息的强大能力,但却无法正确捕获局部信息。
贡献
1. 提出了一种新的基于变压器的体积医学图像分割模型。
2. 为此,我们提出了一种新的架构,其中(1)Transformer编码器直接利用嵌入式3D体来有效捕获远程依赖关系;(2)skip-connected decoder结合提取的不同分辨率的表示并预测分割输出
3. 我们在两个公共数据集:BTCV[26]和MSD[38]上验证了我们提出的模型在不同体积分割任务中的有效性。UNETR在BTCV数据集的排行榜上实现了新的最先进的性能,并且在MSD数据集上优于竞争方法。
相关工作
基于cnn的分割网络
暂略
Vision Transformers
暂略
方法
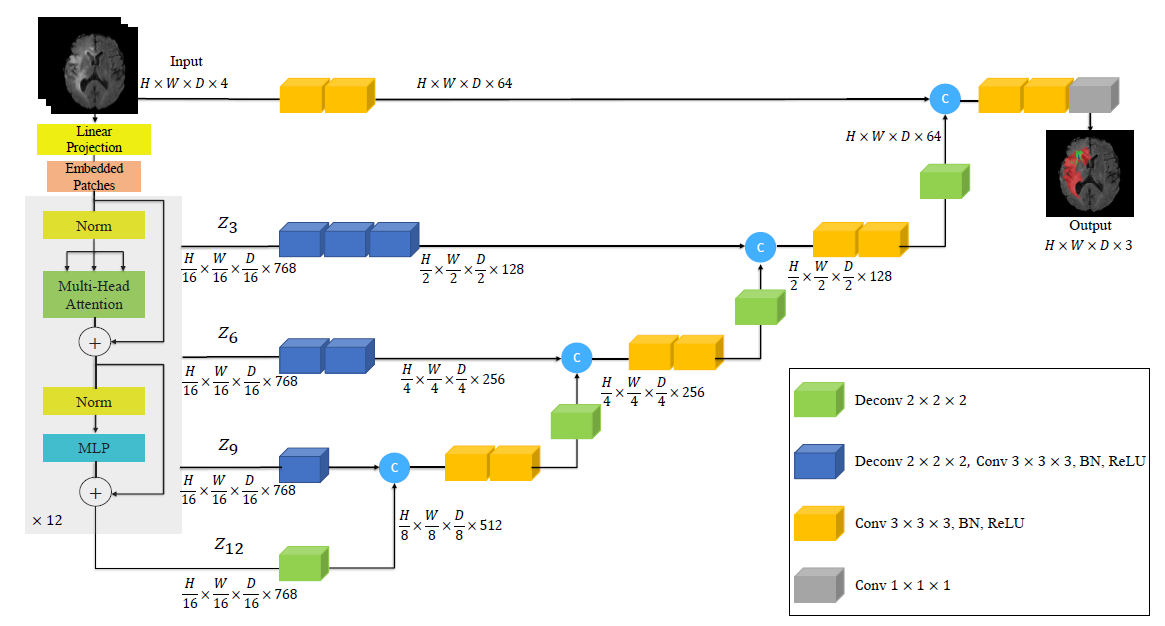
UNETR架构概述。3D输入体数据(例如,MRI图像的C=4通道)被划分为一系列均匀且不重叠的patch,并使用线性层投影到嵌入空间中。该序列与位置嵌入一起添加,并用作变压器模型的输入。提取变压器中不同层的编码表示,并通过跳过连接与解码器合并,以预测最终的分割。给出了补丁分辨率P =16和嵌入尺寸ek =768时的输出大小。
网络结构
我们在上图中概述了所提出的模型。UNETR采用由一堆Transformer组成的收缩-扩展(contracting-expanding)模式作为编码器,编码器通过跳过连接连接到解码器。与NLP中常用的一样,Transformer在输入嵌入的一维序列上运行。
我本人就是在3D作为跟文本一样维度的序列输入tansformer之后会存在长宽高压到一个维度上导致做交叉注意力的时候内存会爆掉,看看本文怎么解决的↓
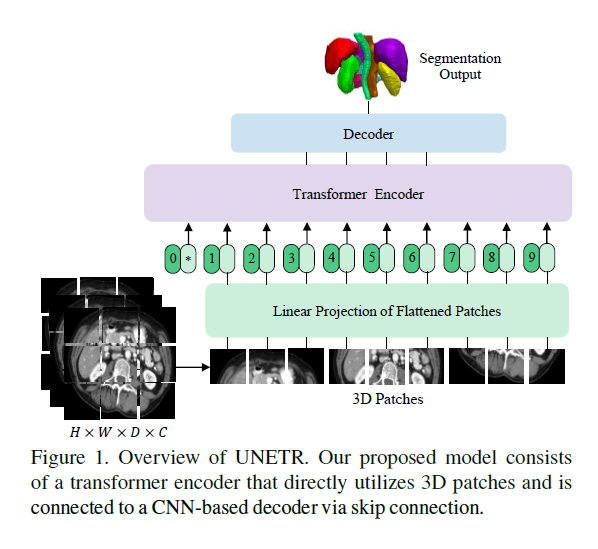
1)img 输入:x∈R HxWxDxC,其中H,W是长宽,D是深度,C是channel
2)然后把它拍平成 xv∈R Nx(P^3 x C) 式中P^3表示每个patch的分辨率,N =(H*W*D)/P^3为序列长度。
3) 随后,我们使用线性层将贴片投影到K维嵌入空间中,该嵌入空间在整个Transformer层中保持恒定。
4) 为了保留提取的patch的空间信息,我们添加了一维可学习的位置嵌入 Epos ∈ R NxK 到投影的 patch embedding Epos ∈ R (P^3 x C)xK,根据公式↓
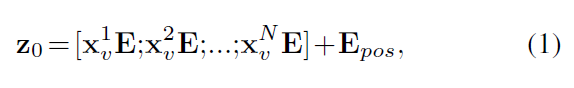
请注意,可学习的[class]令牌没有添加到嵌入序列中,因为我们的变压器主干是为语义分割而设计的。
5)在嵌入层后,我们利用由多头自注意(MSA)和多层感知器(MLP)子层组成的Transformer块堆,根据算式
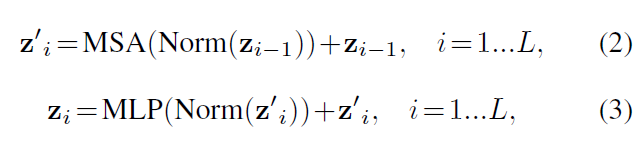
其中Norm()表示层归一化[1],MLP由两个具有GELU激活函数的线性层组成,i为中间块标识符,L为变压器层数。
MSA子层
由n个并行self-attention层(SA)组成。具体来说,SA块是一个参数化函数,它学习查询(q)与序列Z∈R N*K 中相应的键(k)和值(v)表示之间的映射
通过测量z中两个元素及其键值对之间的相似性来计算注意权重(A)
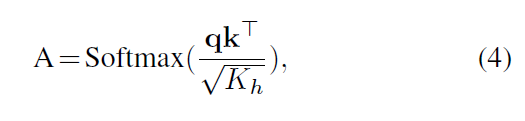
其中Kh = K=n是一个比例因子,用于将参数的数量保持在一个常数上,其中键K的值不同。
6) 使用计算的注意力权重,序列z中值v的SA输出计算为

这里,v表示输入序列和中的值 Kh = K/n是一个比例因子(scaling factor.)
此外,MSA的输出被定义为

其中Wmsa ∈ R n.Kh x K表示多头可训练参数权重。
7) 受类似于U-Net[36]的架构的启发,其中编码器的多个分辨率的特征与解码器合并。我们从transformer提取了大小为 (HxWxD)/P^3 x K 的序列表示zi(i∈{3,6,9,12}),并把他们变形成一个 H/P x W/P xD/P x K的tensor
我们定义中的表示在嵌入空间中被重塑为特征大小为K的Transformer 的输出(即变压器的嵌入大小)。此外,如图2所示,在每个分辨率下,我们利用连续3x3x3的卷积层,然后是规范化层,将嵌入空间中的重塑张量投影到输入空间中。
8)在我们encoder的bottleneck(即变压器最后一层的输出)中,我们将反卷积层应用于变换后的特征映射,将其分辨率提高2倍。
9) 然后,我们将调整大小的特征图与先前变压器输出(例如z9)的特征图连接起来,并将它们馈送到连续的3x3x3的卷积层中,并使用反卷积层对输出进行上采样。这个过程在所有其他后续层中重复,直到原始输入分辨率,其中最终输出被送入带有softmax激活函数的1x1x1卷积层,以生成体素语义预测。
损失函数
soft dice loss
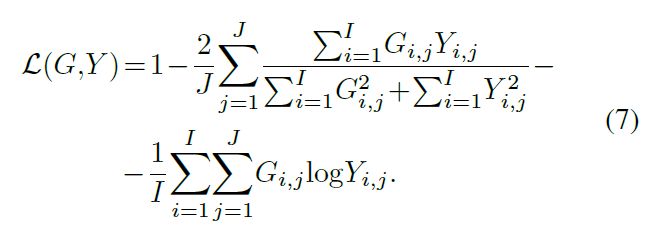
实验
数据集
BTCV (CT):多器官分割
MSD (MRI/CT):脑肿瘤分割
实现细节
框架:pytorch 和 monai(monai听说作为医学深度学习的框架还挺方便的,也是基于pytorch的,有机会学学)
硬件:NVIDIADGX-1服务器
所有模型都以6个批大小进行训练,使用AdamW优化器[31],初始学习率为0.0001,迭代20000次。
Transformer 模型 :VIT-B16,L=12层,嵌入尺寸k =768
结果
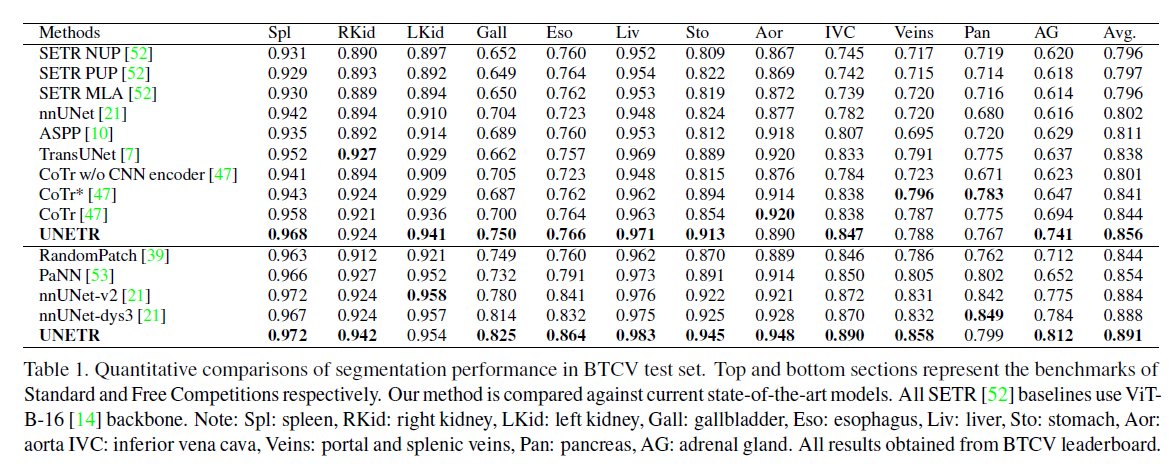
BTCV
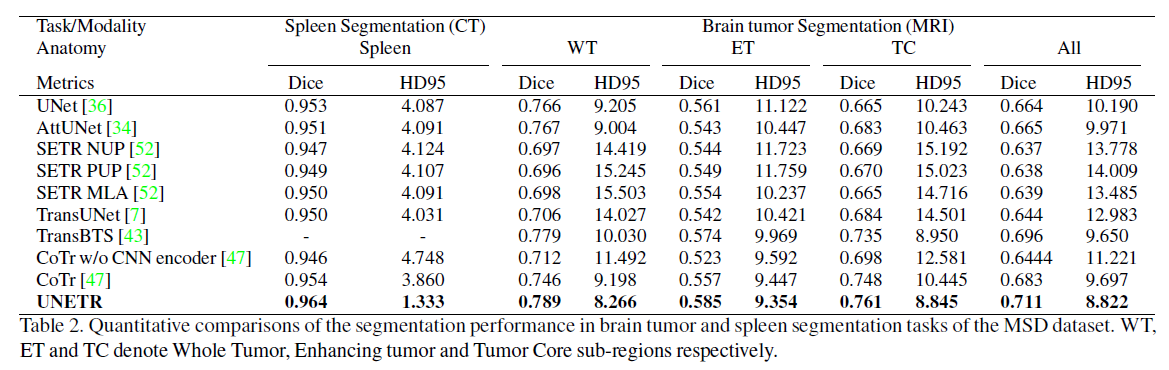
MSD
评估指标
Dice(Dice score)
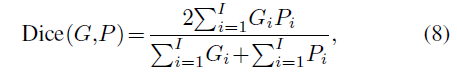
HD (Hausdorff Distance)
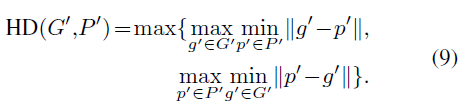
总结
本文介绍了一种新的基于Transformer的结构,称为UNETR,通过将该任务重新表述为一维序列到序列预测问题,用于体医学图像的语义分割。我们建议使用转换器编码器来增加模型学习远程依赖关系和在多个尺度上有效捕获全局上下文表示的能力。我们验证了UNETR在CT和MRI模式下不同体积分割任务中的有效性。UNETR在BTCV排行榜上的多器官分割的标准和自由竞赛中都取得了新的最先进的表现,并且在MSD数据集上优于脑肿瘤和脾脏分割的竞争方法。最后,UNETR已显示出有效学习医学图像中所表示的关键解剖关系的潜力。该方法为医学图像分析中一类新的基于变压器的分割模型奠定了基础。
这篇关于UNETR:用于三维医学图像分割的Transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






