本文主要是介绍EI论文故障识别程序:DBN深度置信/信念网络的故障识别Matlab程序,数据由Excel导入,直接运行!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
适用平台:Matlab2021b版及以上
本程序参考中文EI期刊《基于变分模态分解和改进灰狼算法优化深度置信网络的自动转换开关故障识别》中的深度置信网络(Deep Belief Network,DBN)部分进行故障识别,程序注释清晰,干货满满,下面对文章和程序做简要介绍。
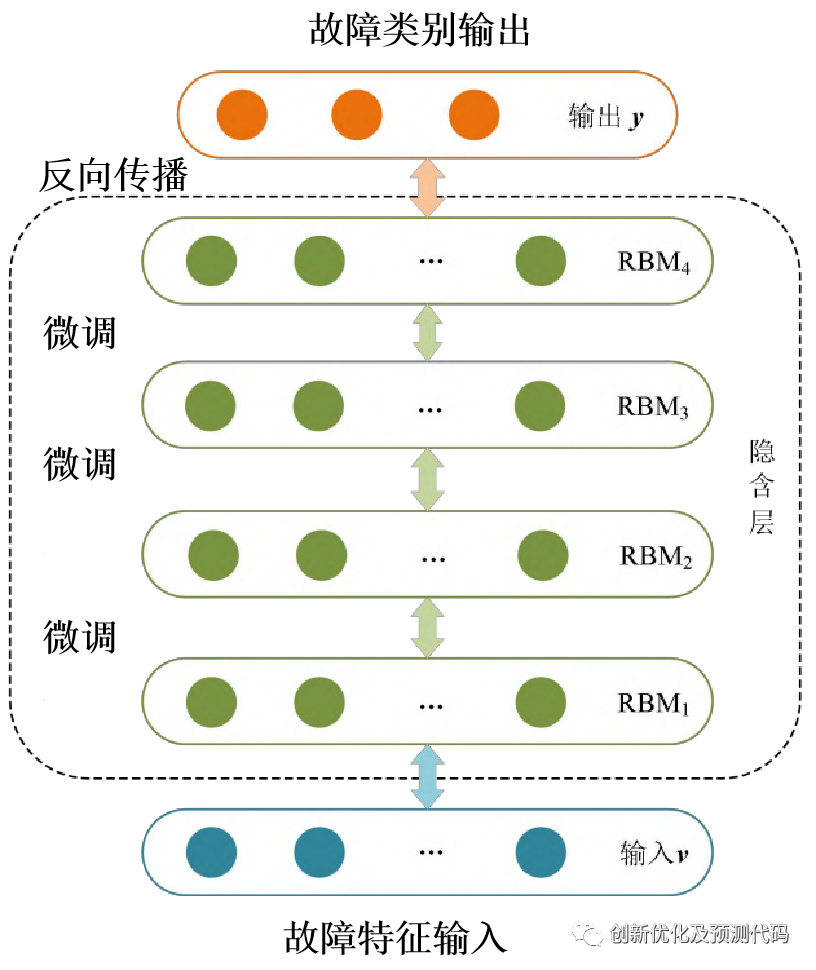
这篇文献使用深度置信网络(DBN)来进行自动转换开关故障识别。DBN的训练过程分为预训练和反向微调两个阶段。预训练阶段中,通过RBMs的逐层预训练,数据从底层输入并逐层传递。每个RBM包含一个视觉层和一个隐藏层,并通过权重连接。在反向微调阶段,采用梯度下降算法对DBN进行有监督的训练,减小每层的预测误差。在RBMs中,使用对比度发散算法近似获得模型的无偏生成概率。通过合适的设置学习率和动量系数,优化DBN算法的网络结构参数,最终实现DBN在自动转换开关故障识别中的应用。
DBN结合电力系统故障识别的创新点主要体现在其对复杂、非线性系统进行建模和特征提取方面。以下是DBN在电力系统故障识别方面的创新点的详细介绍:
分层学习结构:DBN采用了分层学习的结构,包含输入层、隐含层(多个)和输出层。每一层的节点都与下一层的节点相连接,形成一个前馈的结构。这种结构使得DBN能够逐层学习数据的抽象表示,有助于捕捉电力系统数据中的复杂特征和模式。
非监督学习和有监督学习相结合:DBN的训练过程包含两个阶段:首先是无监督的贪婪逐层预训练,然后是有监督的调整网络参数。通过无监督学习,DBN可以从数据中提取高层次的特征表示,然后通过有监督学习来调整这些特征表示以完成具体任务,如故障识别。
适应性特征提取:DBN通过多层次的特征提取,能够适应复杂的电力系统数据模式。这些特征对于故障识别任务而言更具有表征能力,使得系统可以更好地区分正常运行和故障状态。
对抗性训练和鲁棒性:DBN在训练中引入对抗性训练的思想,通过使网络在面对不同情况时更具鲁棒性。这对于电力系统,面对可能的噪声和干扰,以及未知的故障模式,都具有重要的意义。
大数据处理能力:DBN在处理大规模数据方面表现出色,而电力系统通常会产生大量的实时数据。DBN的能力使其能够有效地处理这些数据,并从中提取对于故障识别有关键意义的信息。
潜在变量的建模:DBN通过潜在变量的建模,能够更好地理解电力系统中的隐含关系。这些潜在变量可以捕获系统中的复杂动态和非线性关系,从而提高故障识别的准确性。
总结:DBN在电力系统故障识别中的创新点主要体现在其深度学习结构、分层特征提取、对抗性训练等方面,使其能够更好地应对电力系统数据的复杂性和多变性。
适用于各种数据分类场景,如滚动轴承故障、变压器油气故障、电力系统输电线路故障、绝缘子、配网、电能质量扰动,等领域的识别、诊断和分类。
以下是程序的输出:
测试集的混淆矩阵:(右下角为最终准确率,精确率是混淆矩阵的最下面一行,召回率是混淆矩阵的最右边一列)

精确率:是指在所有被模型预测为正类别的样本中,有多少是真正的正类别。
召回率:是指在所有实际正类别的样本中,有多少被模型正确地预测为正类别。
训练集的实际故障类别和模型识别的故障类别:

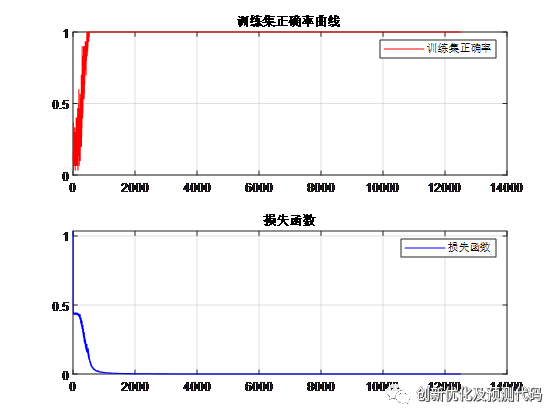
模型的训练曲线:
数据格式:一行为一个故障波形样本,最后一列为该样本所属的故障类别。

DBN建模部分代码:
%% 建立DBN
dbn.sizes = [10 5]; % DBN各层神经元个数 第二层10 第三层5
opts.numepochs = 300; % RBM 训练时 迭代次数
opts.batchsize = 30; % 每批次使用30个样本进行训练
opts.momentum = 0; % 学习率的动量
opts.alpha = 0.01; % 学习率因子
dbn = dbnsetup(dbn, p_train, opts); % 建立DBN模型
dbn = dbntrain(dbn, p_train, opts); % 训练DBN模型%% DBN移植到深层NN
nn = dbnunfoldtonn(dbn, 8); % 反向微调(8代表有8种输出)
nn.activation_function = 'sigm'; % 激活函数%% 反向调整DBN
opts.numepochs = 500; % 反向微调次数
opts.alpha = 0.001; % 学习率因子
opts.batchsize = 30; % 反向微调每次样本数
opts.output = 'softmax'; % 激活函数
nn = nntrain(nn, p_train, t_train, opts);% 训练%% 预测
T_sim1 = nnpredict(nn, p_train);
T_sim2 = nnpredict(nn, p_test);%% 完整代码:https://mbd.pub/o/bread/ZZeTlpZw部分图片来源于网络,侵权联系删除!
欢迎感兴趣的小伙伴关注我们的公众号,或点击上方链接获得完整版代码哦~,关注小编会继续推送更有质量的学习资料、文章程序代码~

这篇关于EI论文故障识别程序:DBN深度置信/信念网络的故障识别Matlab程序,数据由Excel导入,直接运行!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




