本文主要是介绍CANN5.0黑科技解密 | 别眨眼!缩小隧道,让你的AI模型“身轻如燕”!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着深度学习的发展,推理模型巨大的参数量和计算量,需要耗费越来越多的硬件资源,也给模型在移动端的部署带来了新的挑战。
能不能像哆啦A梦一样,变出一条缩小隧道,不管再大的模型,塞进去后就能变小变轻,在寸土寸金的AI硬件资源上身轻如燕…
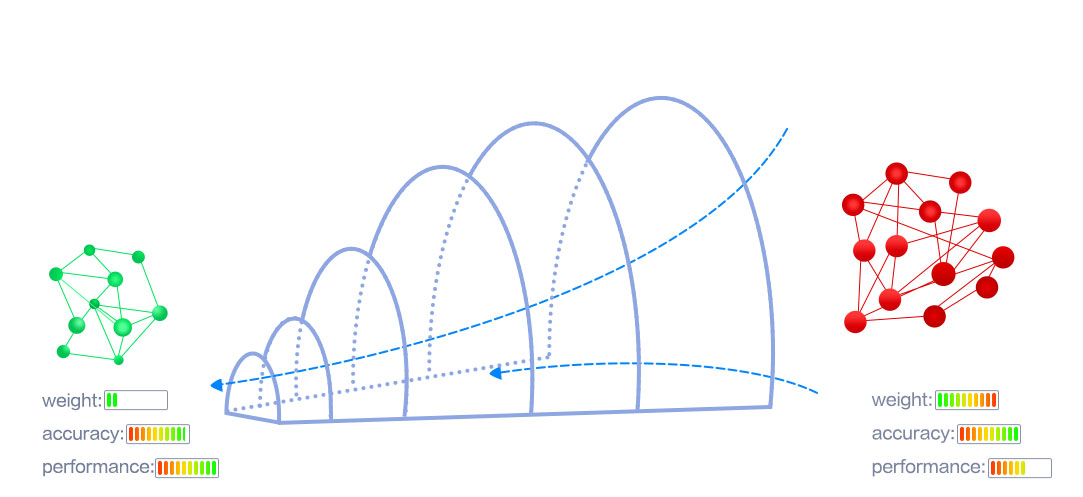
答案是:当然可以!
通常来说,想要构建深度学习领域的模型缩小隧道,加速模型推理部署,一般需要借助量化、剪枝、低秩分解、知识蒸馏等模型压缩技术,降低模型参数量、计算量。
但是,模型压缩通常不是无损压缩,是牺牲一定精度为代价来获取计算性能的提升。而作为衡量AI推理应用成效的双重标准,精度和性能同等重要,模型压缩算法的落地自然也需要同时兼顾精度损失和性能提升的均衡。
AMCT:模型缩小隧道
昇腾异构计算架构CANN,作为连接AI框架和AI硬件的桥梁,提升昇腾AI计算效率的关键平台,通过AMCT模型压缩工具(Ascend Model Compression Toolkit),构筑了一条现实版的模型缩小隧道。
AMCT是一个python工具包,有效适配Caffe/TensorFlow/ 昇思MindSpore/PyTorch/ONNX等主流深度学习框架,提供包含量化、张量分解、通道稀疏在内的多种模型压缩功能。在保证模型精度前提下,可有效降低模型的存储空间和计算量,提升模型推理性能。
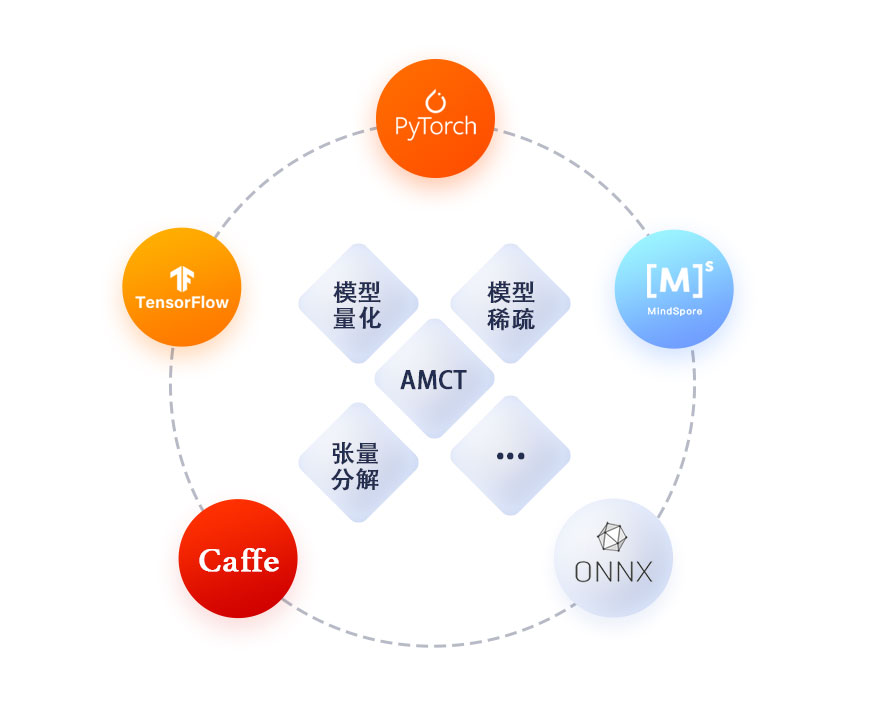
相比于其他同类平台,AMCT支持的模型压缩特性更加完备,通过多种压缩算法以及硬件亲和模型优化最大化用户模型部署推理性能;AMCT支持的训练框架也更加丰富,适配不同领域不同用户人群开发使用;除此之外,AMCT还致力于通过自动调优、自动补齐等高阶特性来提升工具的易用性,让用户可以付出极低代价就可以获取尽可能大的收益。
量化:低比特压缩,减少数据bit位宽
顾名思义,模型量化是一种将浮点计算转成低比特定点计算的技术(例如32bit的浮点模型转换为8bit的定点模型),可有效降低模型的存储开销和计算复杂度,从而提升模型推理性能。
常见的量化算法有二值化、对数量化和线性量化。
二值化量化,
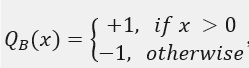
由于模型压缩太过激进,对于模型性能提升较大但是相应的精度损失也较大,适用范围较小;
对数量化,
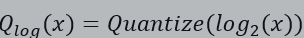
由于依赖专用的硬件计算单元且性能提升有限,也未能获得大规模应用;
AMCT采用线性量化方式,
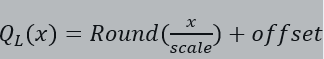
支持8bit、4bit位宽量化。一般而言,网络做8bit量化的精度风险小,可通过训练后量化的方式实现;对于4bit量化的精度损失风险较大,当前AMCT仅支持通过量化感知训练的方式实现。
训练后量化(Post-Training Quantization, 简称PTQ),是指将训练后模型中的权重由浮点数量化到低比特整数,并通过少量校准数据基于推理过程进行校准量化。对于8bit量化,一般网络通过训练后量化即可达到较低的量化精度损失。
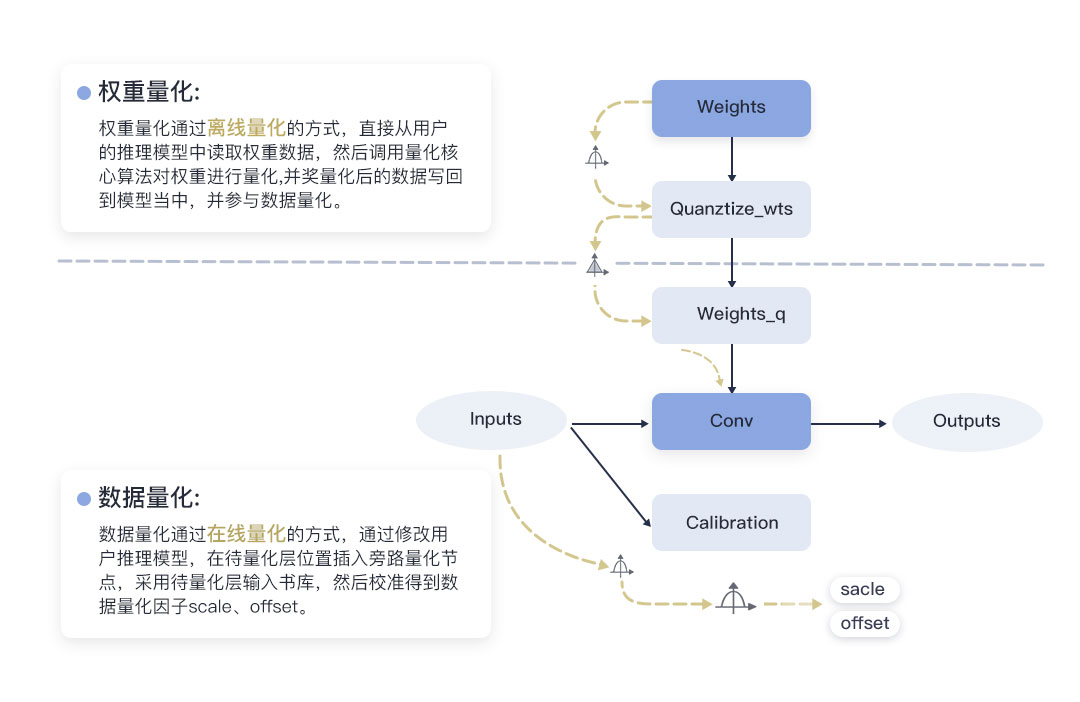
量化感知训练(Quantization-Aware Training, 简称QAT),是指借助用户完整训练数据集,在重训练过程中引入量化操作,在训练前向计算中对数据和权重进行伪量化(量化反量化),引入量化误差损失,从而在训练过程中提高模型对量化效应的适应能力,提高最终的量化模型精度。对于4bit以及更低bit位宽的量化,一般需要通过量化感知训练来降低量化精度损失。

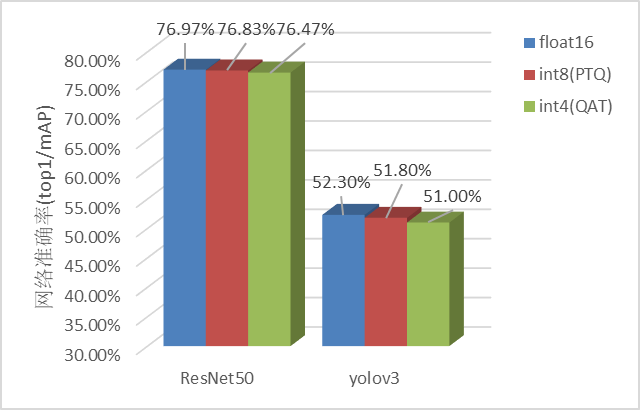
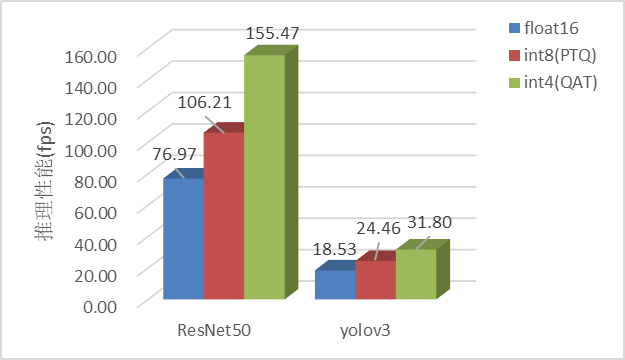
我们在昇腾AI处理器上分别测试了ResNet-50和YOLOV3网络在8bit PTQ和4bit QAT下的性能及精度表现。
精度方面,可以看到不同网络对量化的敏感度不同,在经典CV网络,8bit量化量化精度损失可保持在1%以内,4bit量化量化精度损失可保持2%以内。
性能方面,不同模型由于其模型结构及网络规格的差异,量化所获取的性能提升也各不相同,其中ResNet-50 INT8相较于FP16,INT4相较于INT8而言平均约有40%左右的性能提升;YOLOV3则都在30%左右。
使用方面,开发者调用AMCT提供的API即可轻松完成模型量化。AMCT默认会对整网所有可量化算子(主要为卷积类和矩阵乘类算子)进行量化,开发者也可自行指定具体量化哪些层、每一层的量化bit位宽。如果量化后精度损失大于预期,可以通过跳过一些关键层的量化来恢复精度。例如,我们通常认为网络的首尾层对网络的业务精度影响较大,则需要优先进行量化回退。
3 稀疏:权重剪枝,缩减模型参数量
许多实验证明,神经网络模型都是过参数化的(over-parameterized),许多参数都是冗余的,恰当剔除这些相对“不重要”的参数对模型最终的结果几乎没有影响。
模型稀疏就是对模型的参数进行删减,从而降低模型的存储和计算开销。而模型稀疏按照稀疏颗粒度,从最小的element-wise到channel-wise甚至更大,稀疏颗粒度从小到大,对模型的精度影响越大,但是相应能够获取到的性能收益也越大。
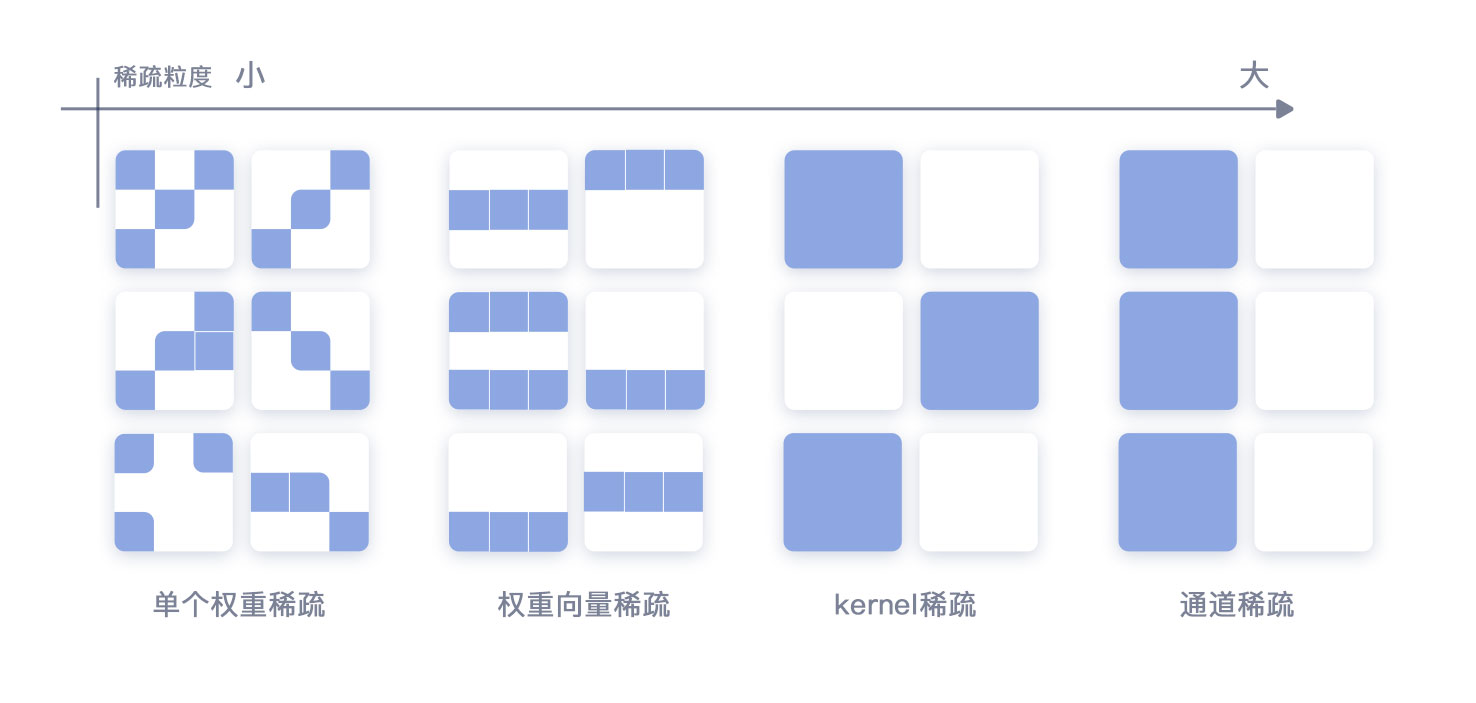
以上稀疏颗粒度示意图,从左到右颗粒度依次增加。但是对于单个权重、权重向量、单个卷积核kernel的稀疏都需要硬件特殊适配才能够拿到对应的性能或者存储收益。
而通道稀疏(filter-level sparsity)由于裁剪了输出数据通道,等价于缩小了模型的规格,不需要特定的硬件支持就可以拿到对应的性能收益,是一个比较理想的选择。但是如前所述,通道稀疏的颗粒度较大,对于网络的精度风险也较大,一般需要进行Fine-tune。
AMCT目前主要支持基于重训练的通道稀疏模型压缩特性。
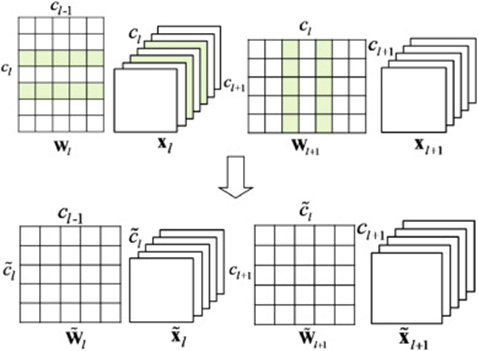
通道稀疏主要是通过裁剪网络通道数,在保持网络功能的前提下缩减模型参数量。通道稀疏的实现通常包括两个步骤:首先是通道选择,需要选择合适的通道组合以保留丰富的信息;然后是重建,需要使用选择的通道对下一层的输出进行重建。
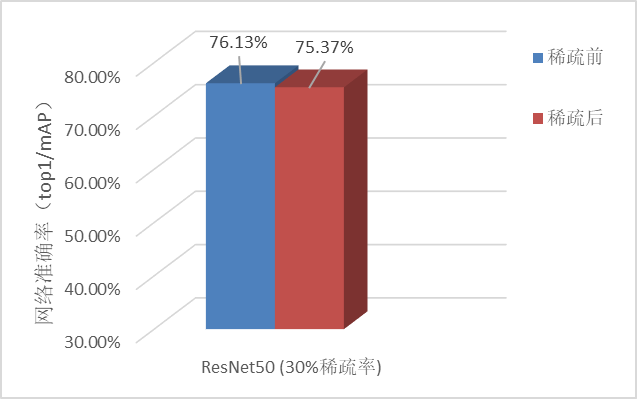
在昇腾AI处理器上分别测试了ResNet-50网络进行30%稀疏的精度和性能表现。
精度方面,可以看到不同网络对通道稀疏的敏感度不同,ResNet50做30%比例的通道稀疏后精度损失仍能保持在1%以内。
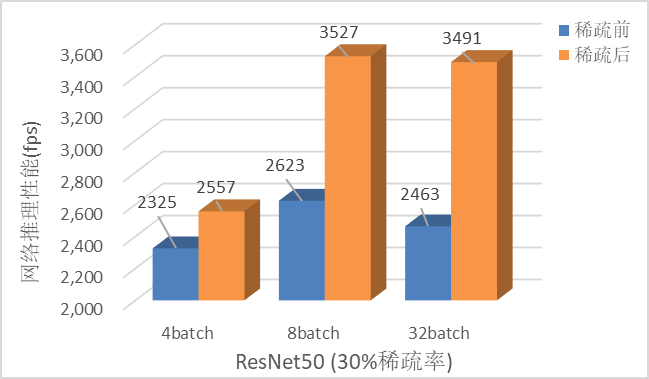
性能方面,主要测试了ResNet-50在不同batch-size情况下的性能情况,在batch-size=32场景下通道稀疏约提升了40%的推理速度。
使用方面,开发者同样只需要调用AMCT提供的API,配置你期望的全局稀疏率或者每一层的稀疏率即可,工具能自动判定可稀疏通道,轻松完成稀疏工作。
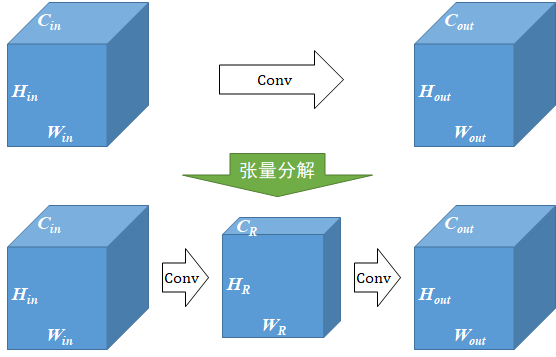
4 张量分解:低秩近似,降低模型计算量
对于卷积神经网络来说,卷积层的运算量是占网络总运算量的大头,并且卷积核越大,参数量和计算量越庞大。
而张量分解,正是采用数学方法,将一个大卷积核通过低秩近似分解为多个小卷积核,构造计算量更小的卷积算子,从而达到压缩模型与计算量的目的。
以1个64*64*3*3的卷积分解为32*64*3*1和64*32*1*3的级联卷积为例,可以减少1 - (32*64*3*1 + 64*32*1*3) / 64*64*3*3 = 66.7%的计算量,在计算结果近似的情况下带来更具性价比的性能收益。
AMCT中的张量分解则充分考虑昇腾AI处理器硬件特性,选择能够充分发挥硬件算力的卷积形式,尽可能减小搬运开销对算子性能的影响。
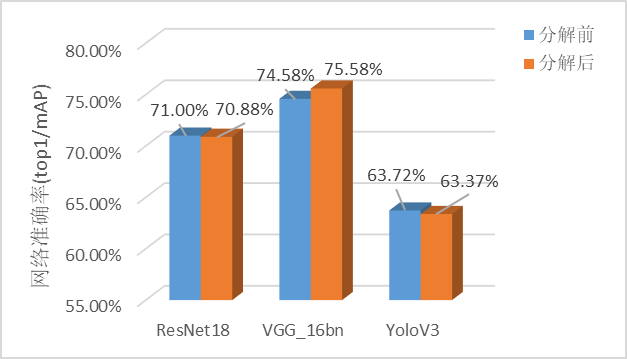
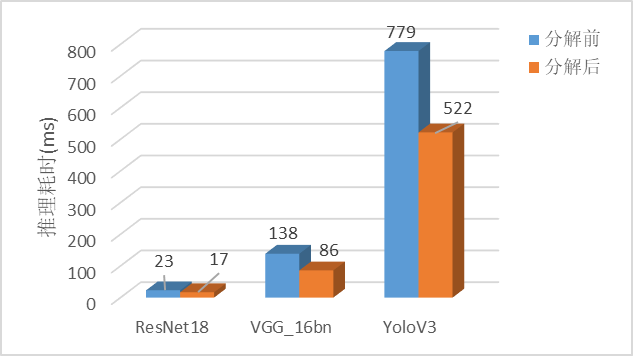
实验表明,张量分解在昇腾AI处理器的推理速度以及模型大小的优化上都起到了非常显著的效果。
经测试,13张经典CV网络经过张量分解后,推理时间平均减少24.4%,模型大小平均减少38.8%,而finetune后的精度几乎与分解前相当(最大损失不超过0.5%)。
使用方面,通过AMCT提供的API,开发者仅需调用1或2个接口(取决于框架),即可完成对原始模型的分解,并对分解后的模型进行finetune。
写在最后
CANN作为释放昇腾硬件算力的关键平台,面对既要保精度又要提性能的尴尬问题,坚持“精度和性能两手抓,两手都要硬”,始终站在开发者视角,想开发者所想,及开发者所及。通过深耕先进的模型压缩技术,聚力打造AMCT模型压缩工具,在保证模型精度前提下,不遗余力地降低模型的存储空间和计算量。
轻装前行,放得远方!面对人工智能的蓬勃发展,相信通过CANN构筑的模型缩小隧道,定将给大参数量、大计算量的AI模型带来更加广阔的应用场景,和更加巨大的想象空间!
欢迎登陆昇腾社区网站LINK或扫描下方二维码了解更多信息。

这篇关于CANN5.0黑科技解密 | 别眨眼!缩小隧道,让你的AI模型“身轻如燕”!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









