本文主要是介绍只谈代码之用pytorch写一个经常用来测试时序模型的简单常规套路(LSTM多步迭代预测)...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
就一句话。
不谈感情,只谈代码。
本系列的代码可以当作入门,复习,作为模板修改成自己的,都是可以的。
这个系列会长期更新下去,主要与python,机器学习,数据挖掘,tensorflow,pytorch相关,后期自己准备复习一些java,学习一些go相关也会一起分享。
一来是大家都代码实战的诉求其实是比理论多的多,总会有人在我文章下面问:有代码吗?能给份代码嘛?
说实话,很多代码给不了,也没法给,我不太喜欢这样白嫖,还是希望各位自己去做一些事情,这样才是对自身的要求和提高,也是一个程序员的素养。
二来,也算自己对一些基础的积累和巩固,尽量两天一篇,每天保持对代码的嗅觉。
今天讲的是pytorch框架下,写一个平时常用来测试的小例子,关于时间序列,模型用的最简单的LSTM,多步迭代预测~
前情提要:
【PyTorch修炼】三、先做减法,具体例子带你了解torch使用的基本套路(简单分类和时间序列预测小例子)
【PyTorch修炼】二、带你详细了解并使用Dataset以及DataLoader
【PyTorch修炼】三、先做减法,具体例子带你了解torch使用的基本套路(简单分类和时间序列预测小例子)
1. 导入我们需要用到的包,此教程 包含可视化以及模型训练和测试
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltimport torch
import torch.nn as nn2. 对于demo,尝试模型,我们可以用自己模拟的数据或者公开数据集,这里为了方便,采用自己模拟sin函数,并可视化
x = torch.linspace(0, 999, 1000)
y = torch.sin(x*2*3.1415926/70)plt.xlim(-5, 1005)
plt.xlabel('x')
plt.ylabel('sin(x)')
plt.title("sin")
plt.plot(y.numpy(), color='#800080')
plt.show()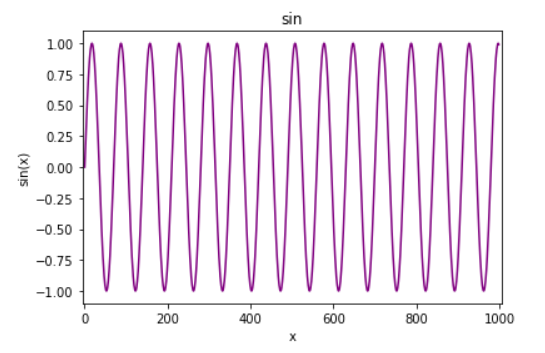
3. 分训练集和测试集,并且需要对数据进行time windows分割
# len(test):50
train_y= y[:-70]
test_y = y[-70:]滑窗创建数据集
def create_data_seq(seq, time_window):out = []l = len(seq)for i in range(l-time_window):x_tw = seq[i:i+time_window]y_label = seq[i+time_window:i+time_window+1]out.append((x_tw, y_label))return out
time_window = 60
train_data = create_data_seq(train_y, time_window)4. 定义lstm模型
https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html#torch.nn.LSTM
https://pytorch.org/docs/stable/generated/torch.nn.Linear.html#torch.nn.Linear
【Deep Learning】通俗大白话详述RNN理论和LSTM理论
【Deep Learning】详细解读LSTM与GRU单元的各个公式和区别
class MyLstm(nn.Module):def __init__(self, input_size=1, hidden_size=128, out_size=1):super(MyLstm, self).__init__()self.hidden_size = hidden_sizeself.lstm = nn.LSTM(input_size=input_size, hidden_size=self.hidden_size, num_layers=1, bidirectional=False)self.linear = nn.Linear(in_features=self.hidden_size, out_features=out_size, bias=True)self.hidden_state = (torch.zeros(1, 1, self.hidden_size), torch.zeros(1, 1, self.hidden_size))def forward(self, x):out, self.hidden_state = self.lstm(x.view(len(x), 1, -1), self.hidden_state)pred = self.linear(out.view(len(x), -1))return pred[-1]5. 训练准备工作
(1) 超参数
(2) 定义loss,优化器,实例化模型
(3) 训练模型,为了更加直观,加入对test_y的预测最终可视化
learning_rate = 0.00001
epoch = 10
multi_step = 70model = MyLstm()
mse_loss = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, betas=(0.5,0.999))device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model.to(device)for i in range(epoch):for x_seq, y_label in train_data:x_seq = x_seq.to(device)y_label = y_label.to(device)model.hidden_state = (torch.zeros(1, 1, model.hidden_size).to(device), torch.zeros(1, 1, model.hidden_size).to(device))pred = model(x_seq)loss = mse_loss(y_label, pred)optimizer.zero_grad()loss.backward()optimizer.step()print(f"Epoch {i} Loss: {loss.item()}")preds = []labels = []preds = train_y[-time_window:].tolist()for j in range(multi_step):test_seq = torch.FloatTensor(preds[-time_window:]).to(device)with torch.no_grad():model.hidden_state = (torch.zeros(1, 1, model.hidden_size).to(device), torch.zeros(1, 1, model.hidden_size).to(device))preds.append(model(test_seq).item())loss = mse_loss(torch.tensor(preds[-multi_step:]), torch.tensor(test_y))print(f"Performance on test range: {loss}")plt.figure(figsize=(12,4))plt.xlim(700,999)plt.grid(True)plt.plot(y.numpy(),color='#8000ff')plt.plot(range(999-multi_step,999),preds[-multi_step:],color='#ff8000')plt.show()结果
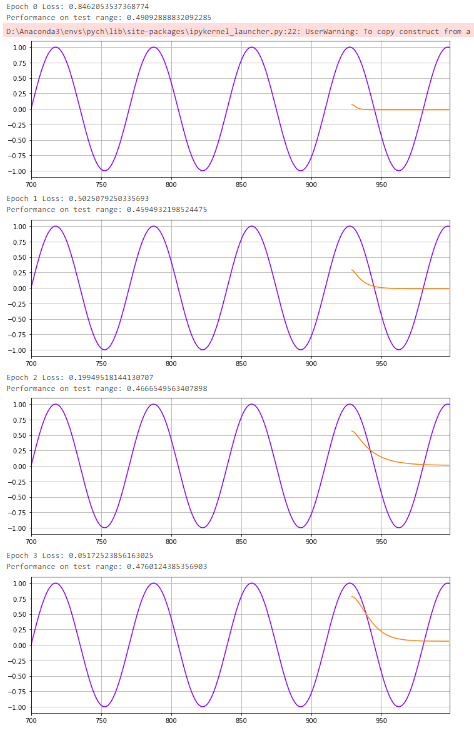
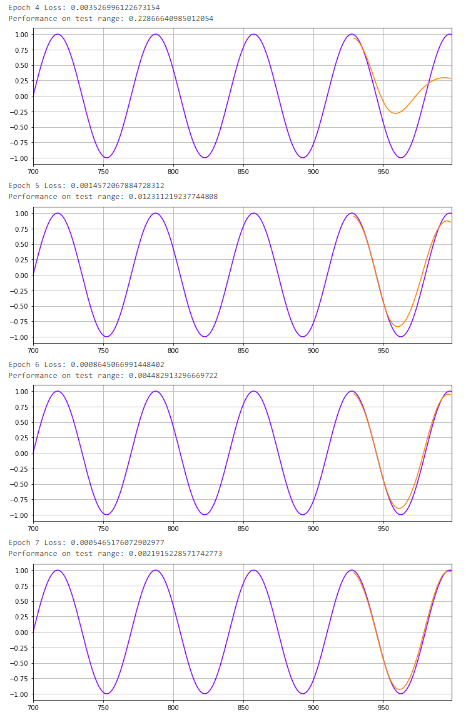 完整代码:https://github.com/chehongshu/AIwoniuche_Learning/blob/master/Pytorch_LSTM_examples/demo-timeseries.ipynb
完整代码:https://github.com/chehongshu/AIwoniuche_Learning/blob/master/Pytorch_LSTM_examples/demo-timeseries.ipynb
这篇关于只谈代码之用pytorch写一个经常用来测试时序模型的简单常规套路(LSTM多步迭代预测)...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





