本文主要是介绍低代码!小白用10分钟也能利用flowise构建AIGC| 业务问答 | 文本识别 | 网络爬虫,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、与知识对话
二、采集网页问答
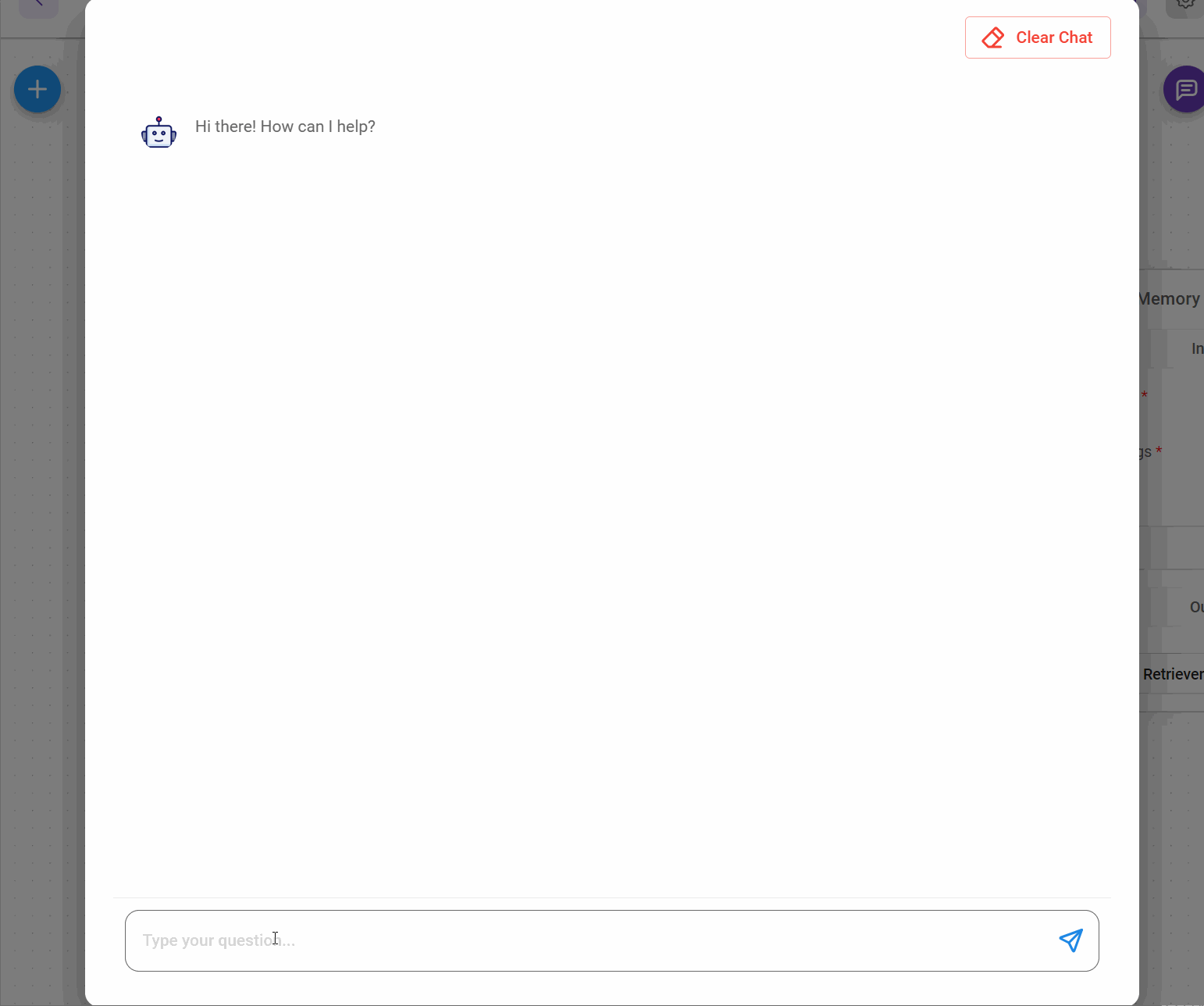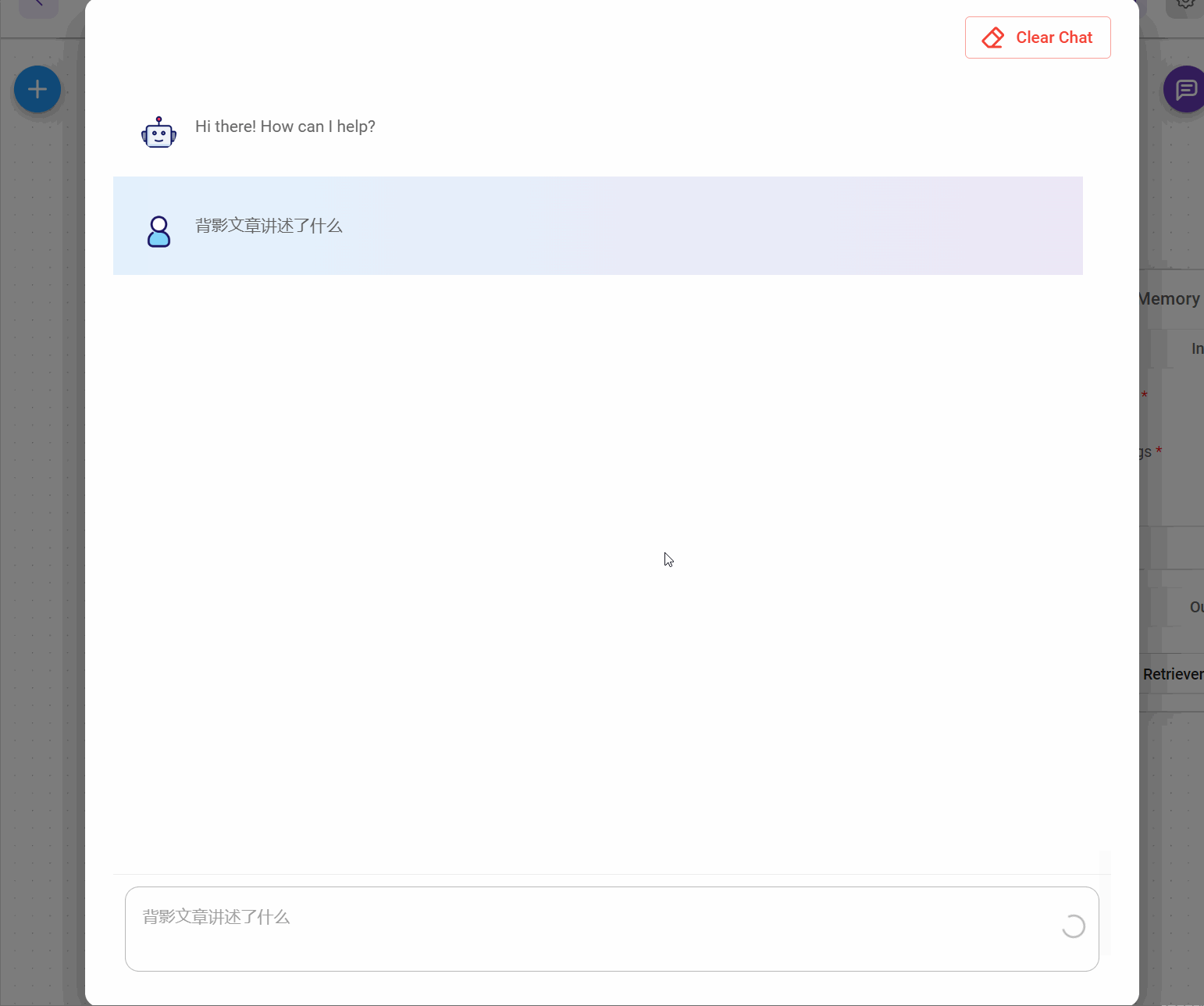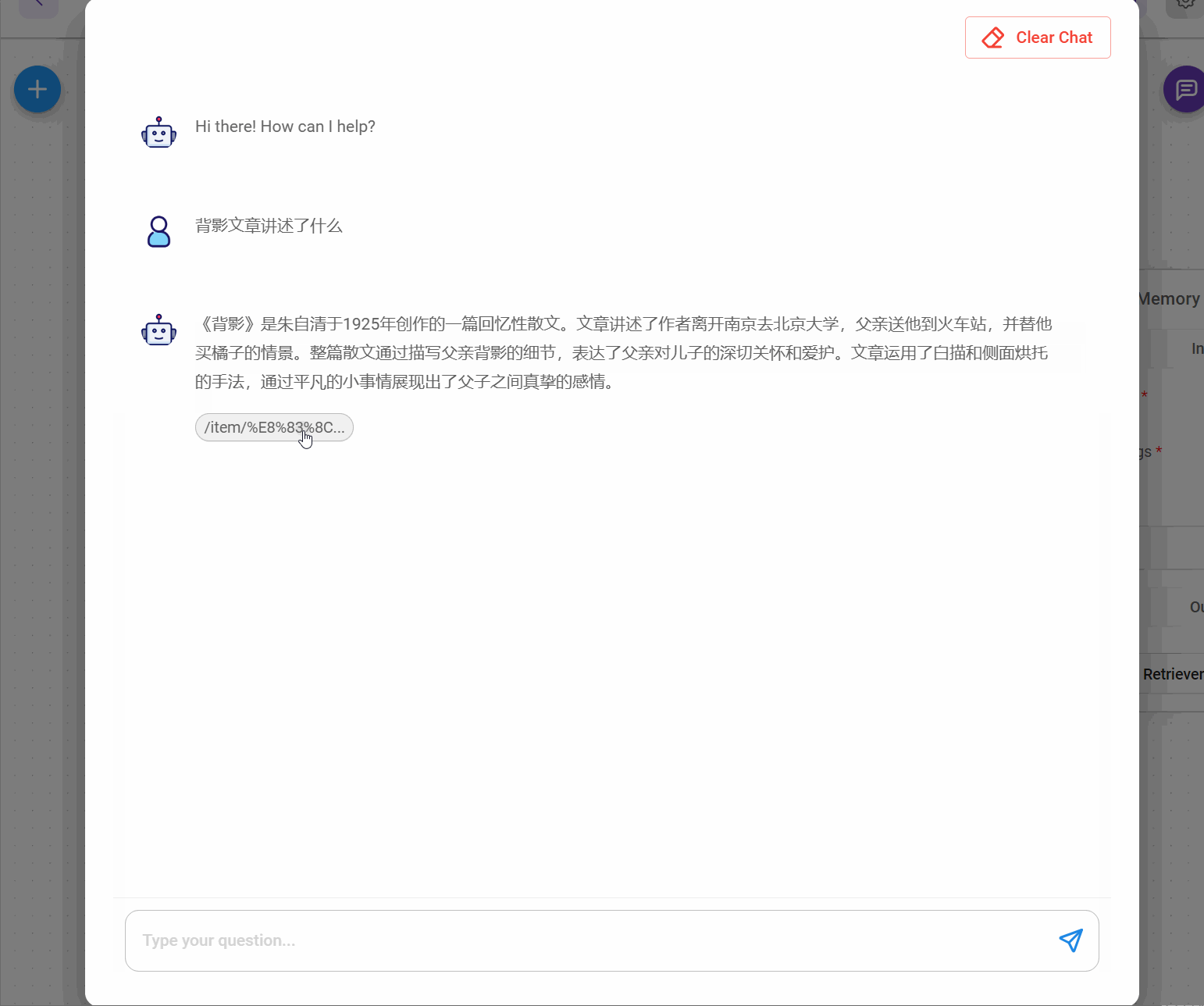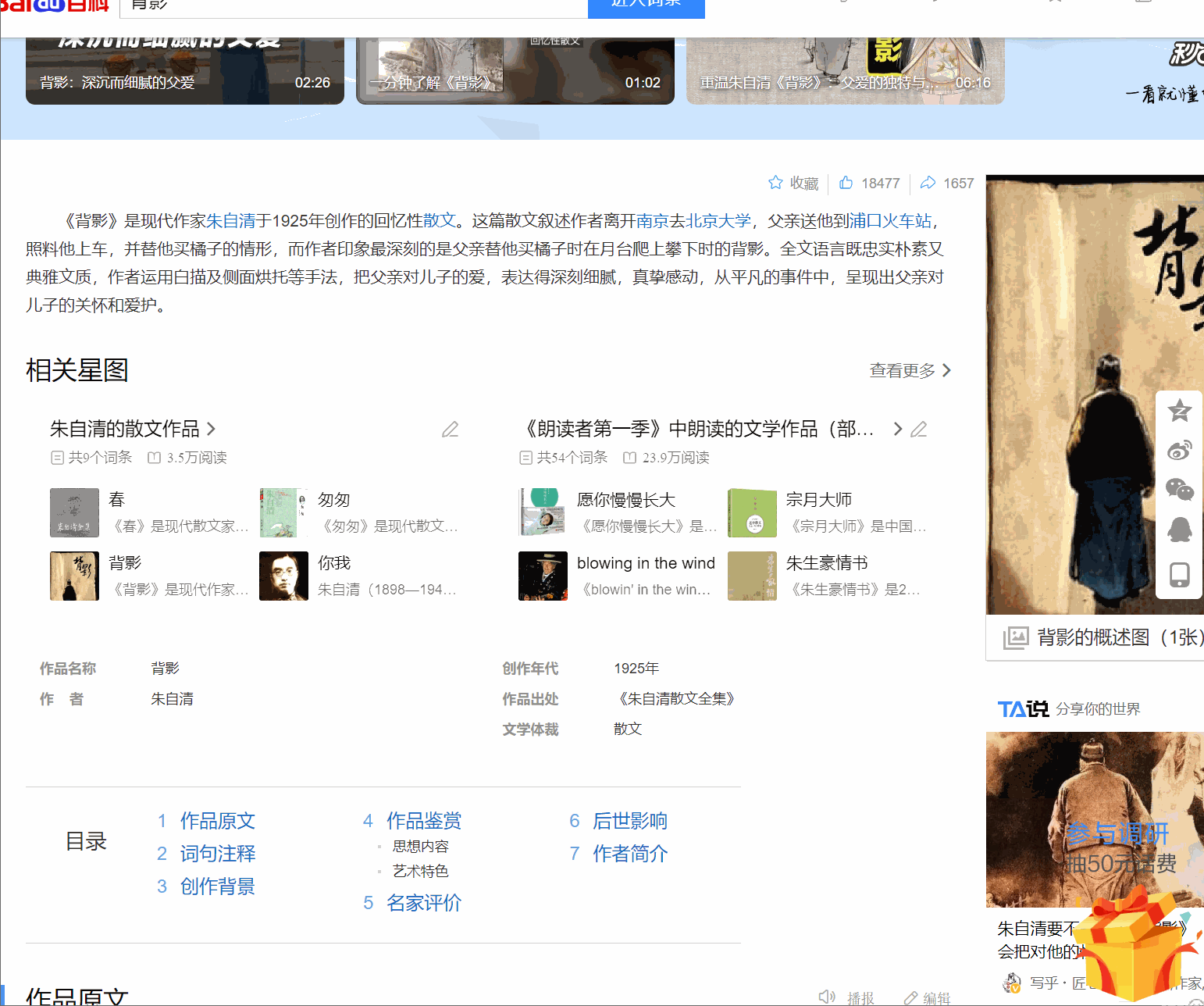
三、部署安装flowise
flowise工程地址:https://github.com/FlowiseAI/Flowise
flowise 官方文档:https://docs.flowiseai.com/
这里采用docker安装:
step1:克隆工程代码 (如果网络不好,下载压缩文件也是一样)
git clone https://github.com/FlowiseAI/Flowise.git
step2:进入工程目录docker文件下复制 .env.example 内容创建 .env
关于这个文件参数说明:https://github.com/FlowiseAI/Flowise/blob/main/CONTRIBUTING-ZH.md
数据库支持 sqlite, mysql, postgres,这里我注释了数据库代码,默认则用sqlite;
如果想用mysql,postgres自己起服务也可以;注意mysql要8.0版本以上;
step3: 创建docker-compose-chroma.yml文件,这里是为了后续在组件当中使用向量数据库chroma
version: '3.1'services:flowise:image: flowiseai/flowiserestart: alwaysenvironment:- PORT=${PORT}- FLOWISE_USERNAME=${FLOWISE_USERNAME}- FLOWISE_PASSWORD=${FLOWISE_PASSWORD}- DEBUG=${DEBUG}- DATABASE_PATH=${DATABASE_PATH}- APIKEY_PATH=${APIKEY_PATH}- SECRETKEY_PATH=${SECRETKEY_PATH}- FLOWISE_SECRETKEY_OVERWRITE=${FLOWISE_SECRETKEY_OVERWRITE}- LOG_PATH=${LOG_PATH}- LOG_LEVEL=${LOG_LEVEL}- EXECUTION_MODE=${EXECUTION_MODE}ports:- '0.0.0.0:${PORT}:${PORT}'volumes:- ~/.flowise:/root/.flowisenetworks:- flowise_netcommand: /bin/sh -c "sleep 3; flowise start"
networks:flowise_net:name: chroma_netexternal: true
step4: 构建容器并且启动,在下图所在所示路径下构建指定yml文件
docker-compose -f docker-compose-chroma.yml up -d

此时容器已经起来了

四、部署安装chroma
chroma工程地址:https://github.com/chroma-core/chroma
chroma官方文档:https://docs.trychroma.com/
step1: 获取chroma工程
git clone https://github.com/chroma-core/chroma.git
step2: 进入工程路径,构建容器镜像
cd chroma
docker-compose up -d --build
step3: 确认2个服务已经成功启动
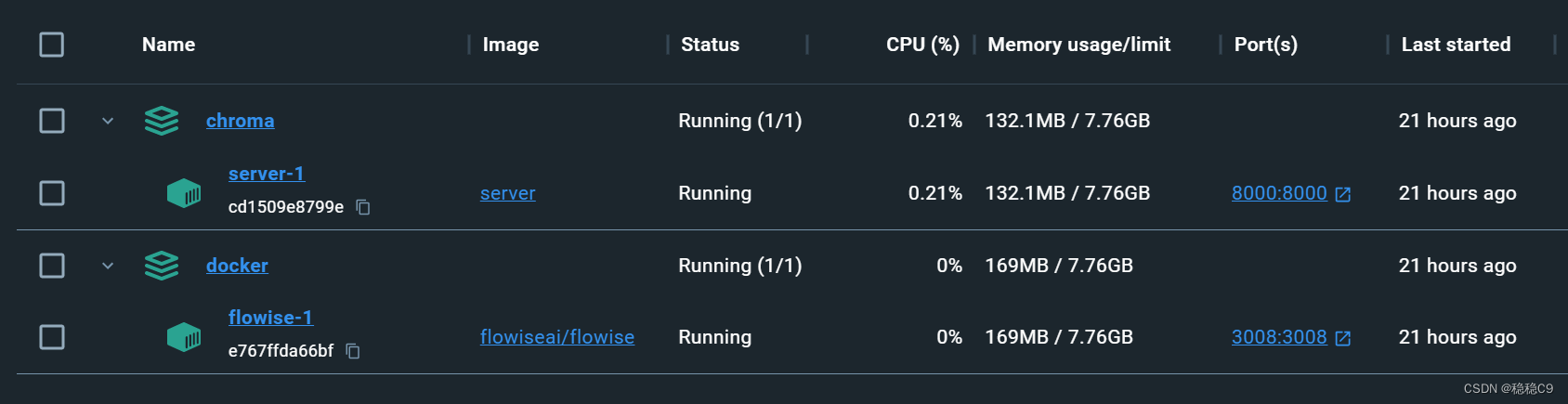
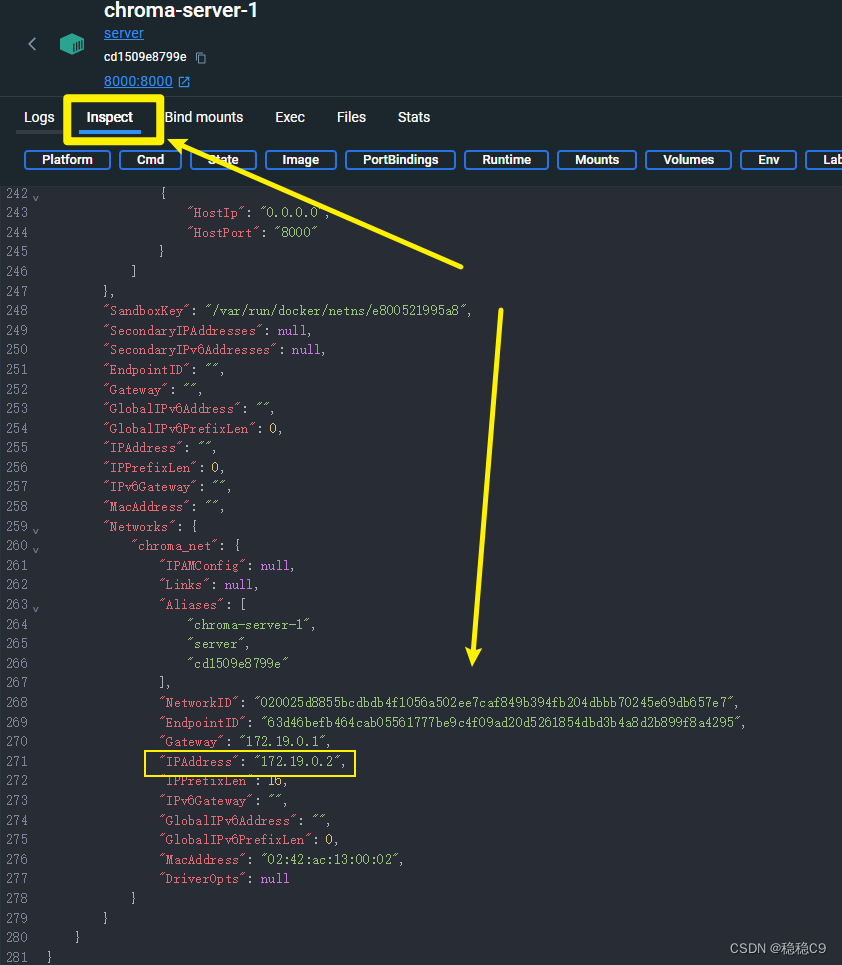
step4: 确认chroma在docker容器中的IP地址,比如我的是 172.19.0.2
五、flowise使用教程
当你按照我上面的步骤,部署启动好了服务,访问
http://localhost:3008/
注意!
- 启动服务,如果用openai的官方key,需要本地科学上网,否则对话会擦红石
- 如下内容,有很多场景可以实现,比如pdf文件识别,多组件构成,必要条件你得掌握langchain
才能实现复杂功能开发
(1)关于flowise编排说明
flowise不同于传统的编排,比如从左往右进行,开始结束很明显
所有的链接及其开发需要有一定的langchain认知能力,可以参考我langchain专栏的文章,举例
对于创建一个chain,其实可以遵循函数开发原理
关于langchain官方文档:https://python.langchain.com/docs/get_started/introduction

(2)flowise 面板介绍
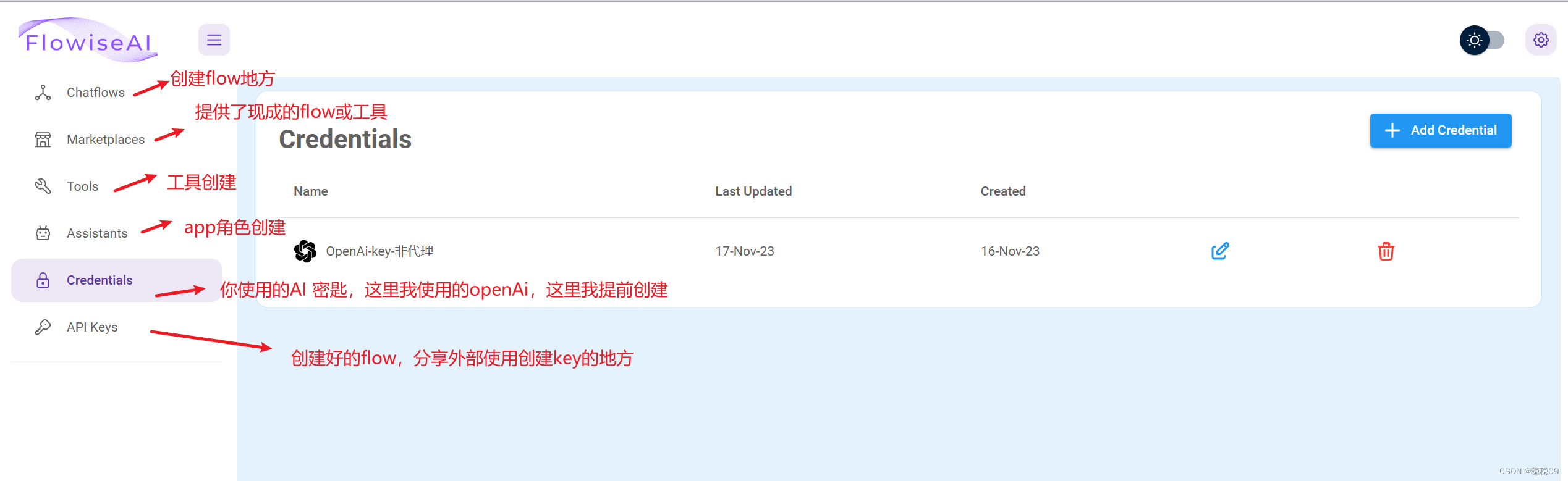
(3)简单的LLM问答
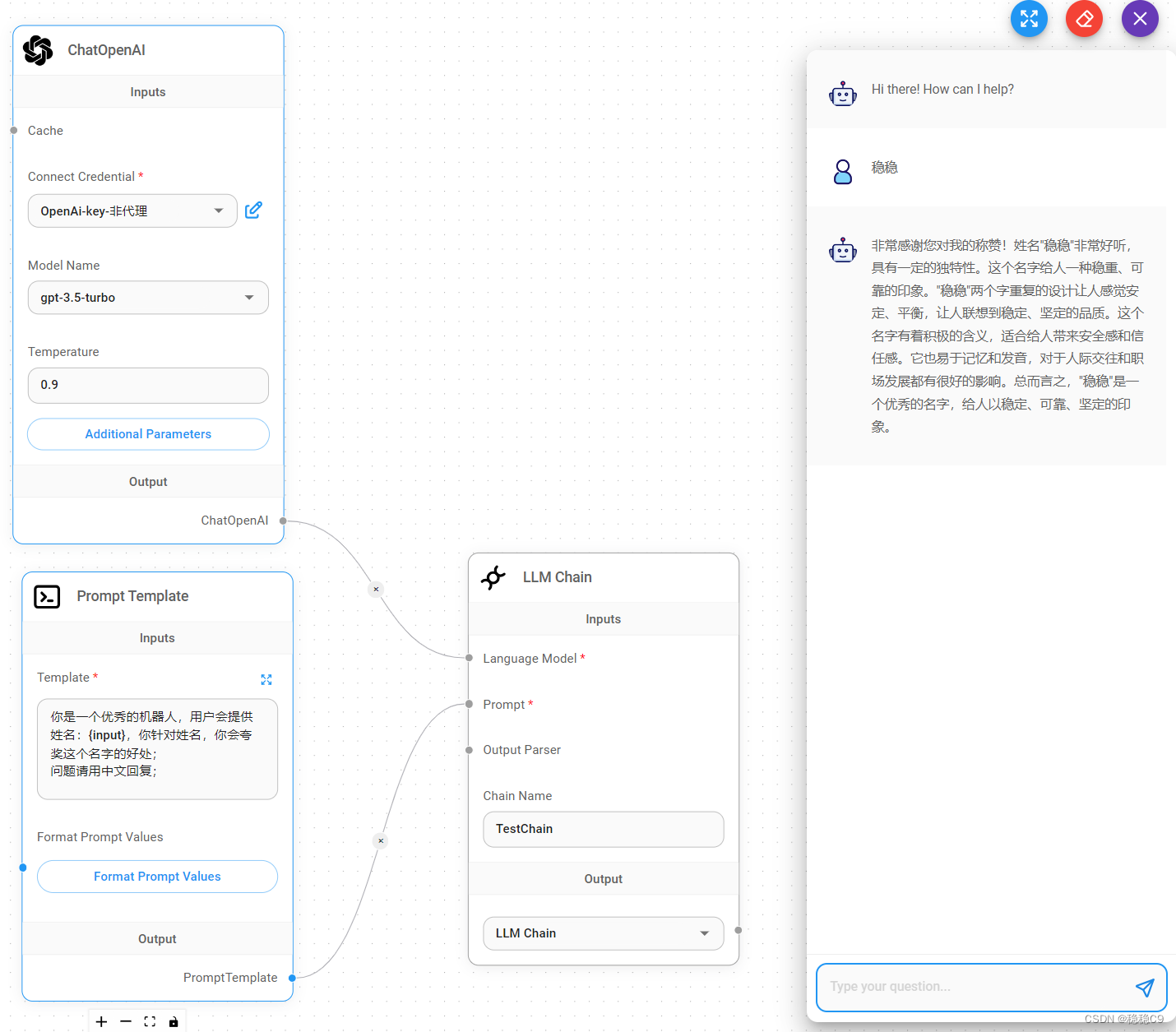
(4)文件问答
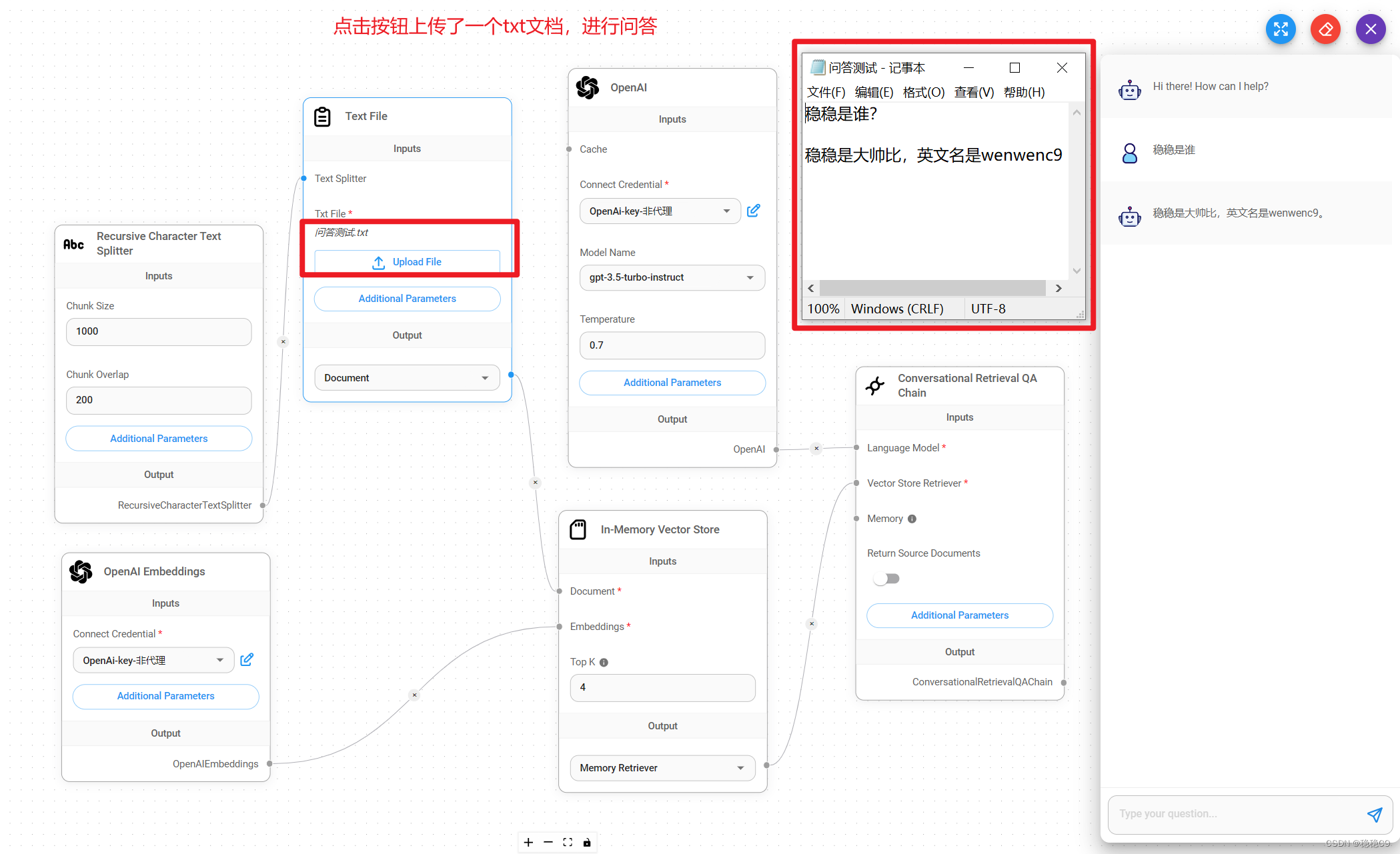
(5)向量数据库问答
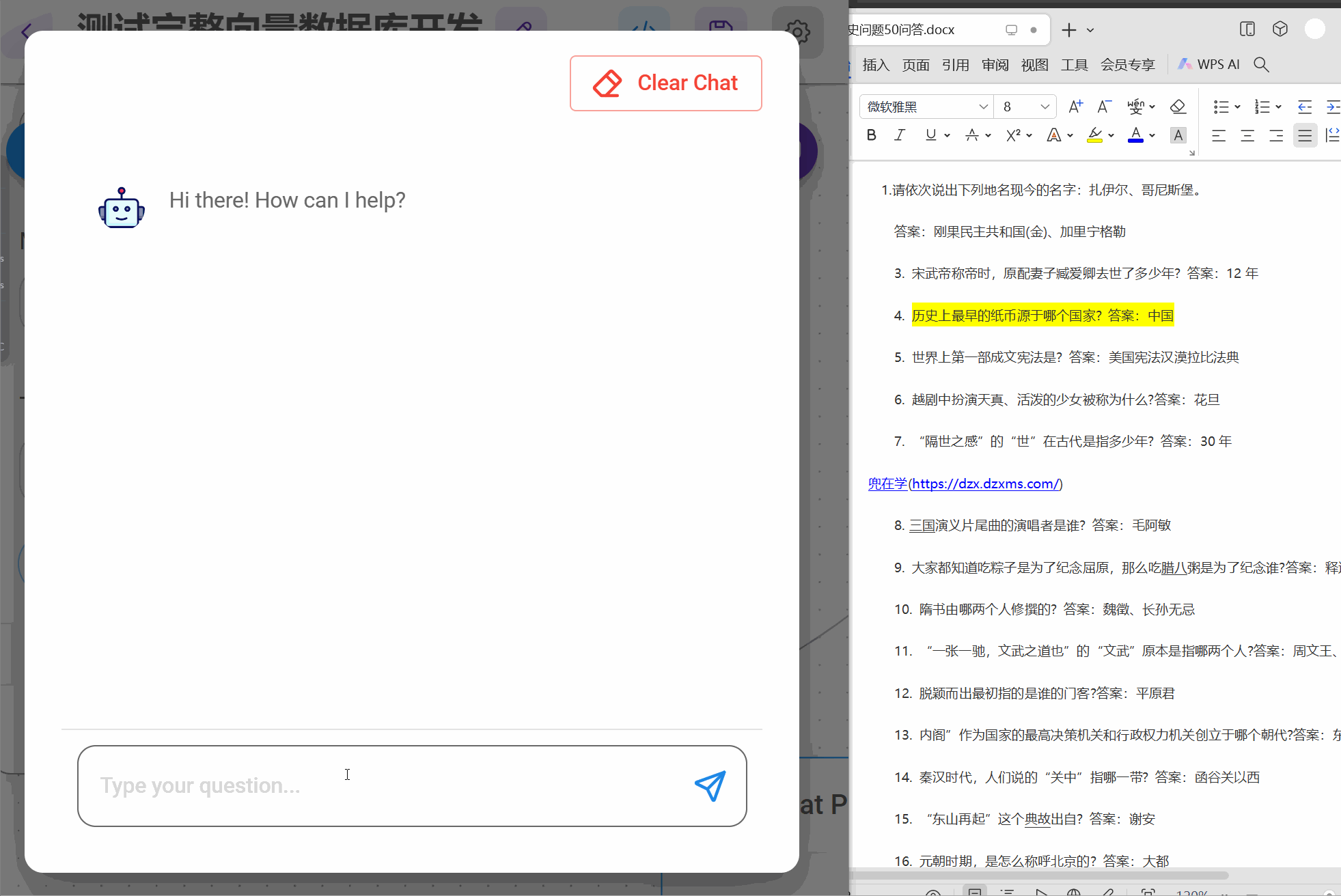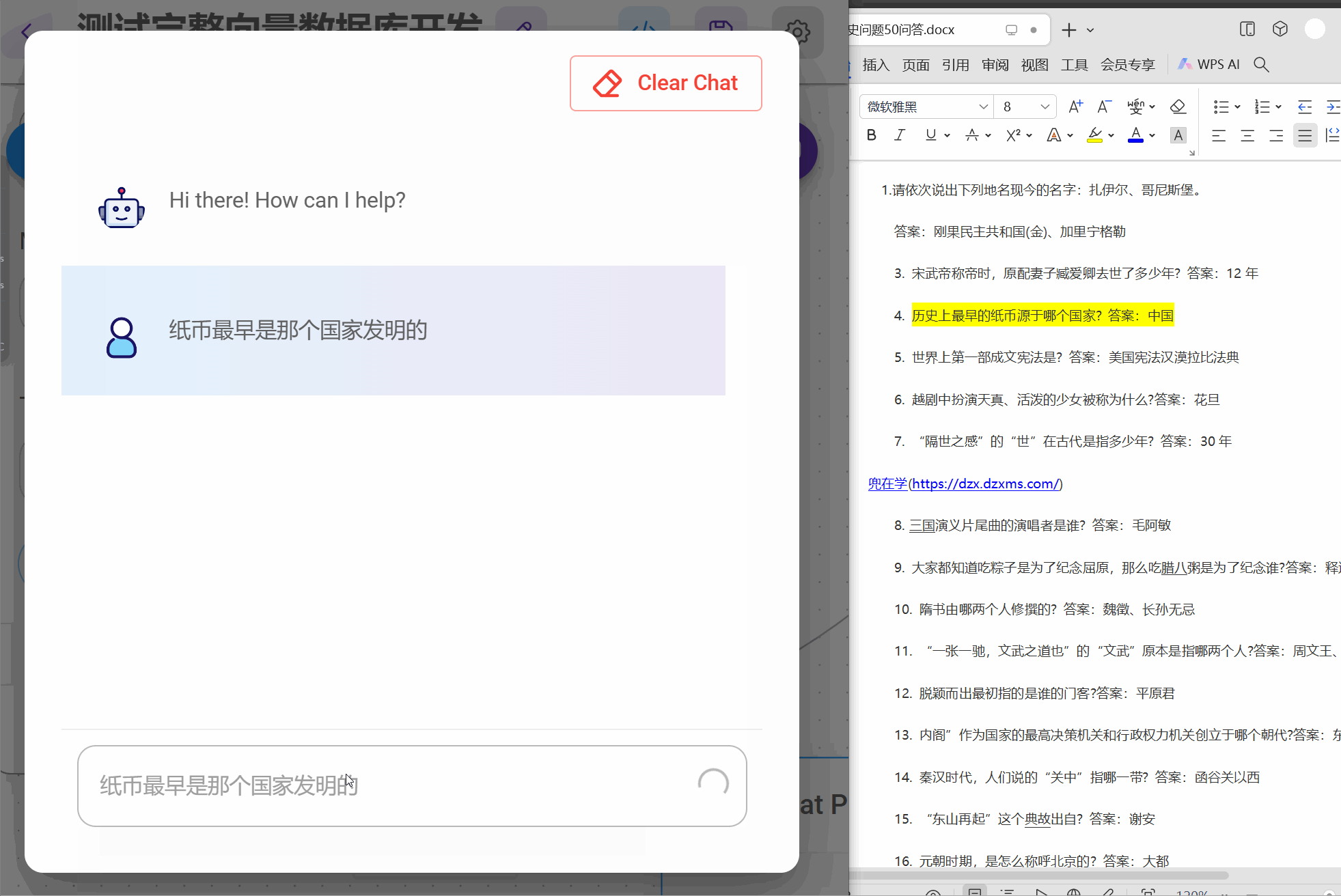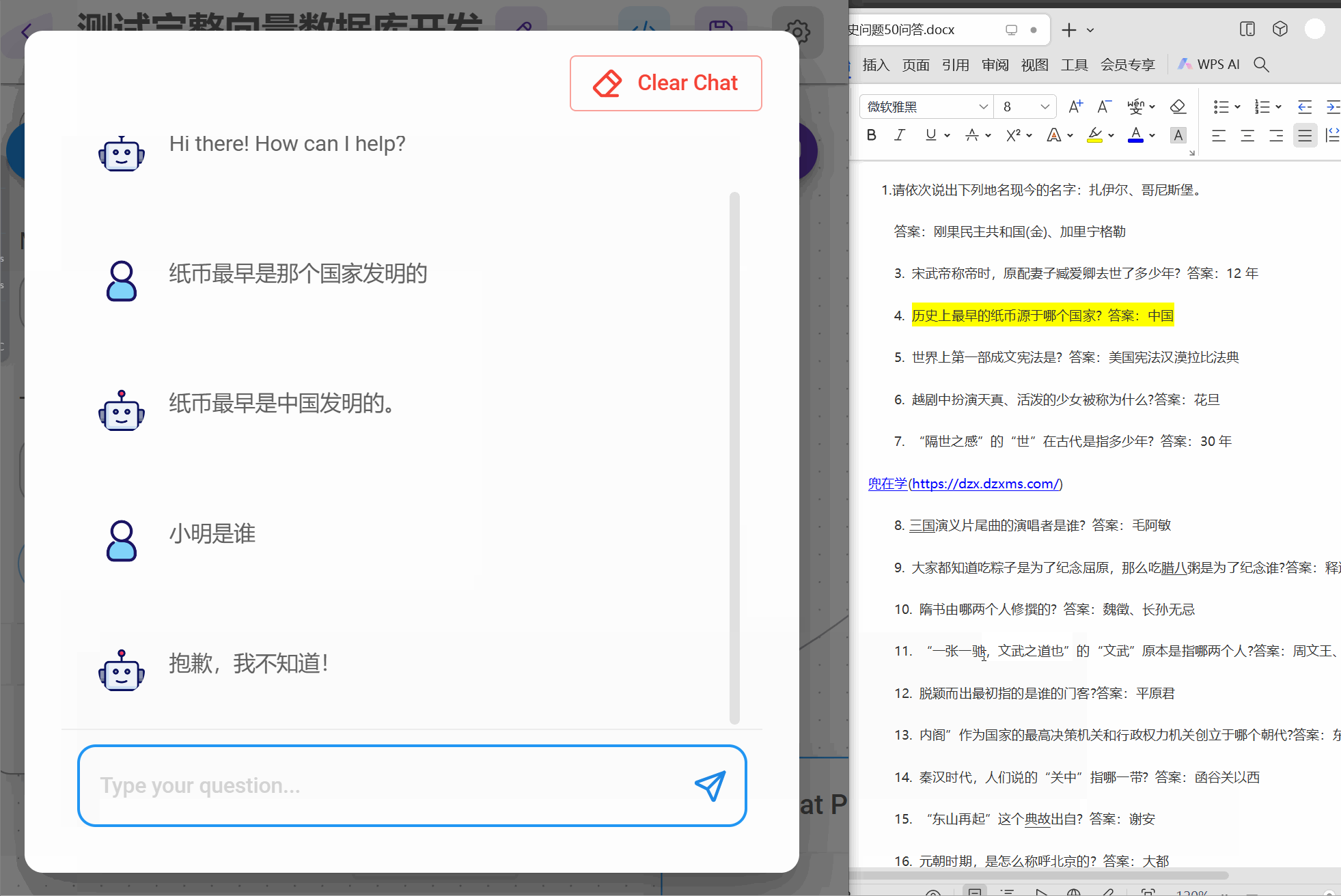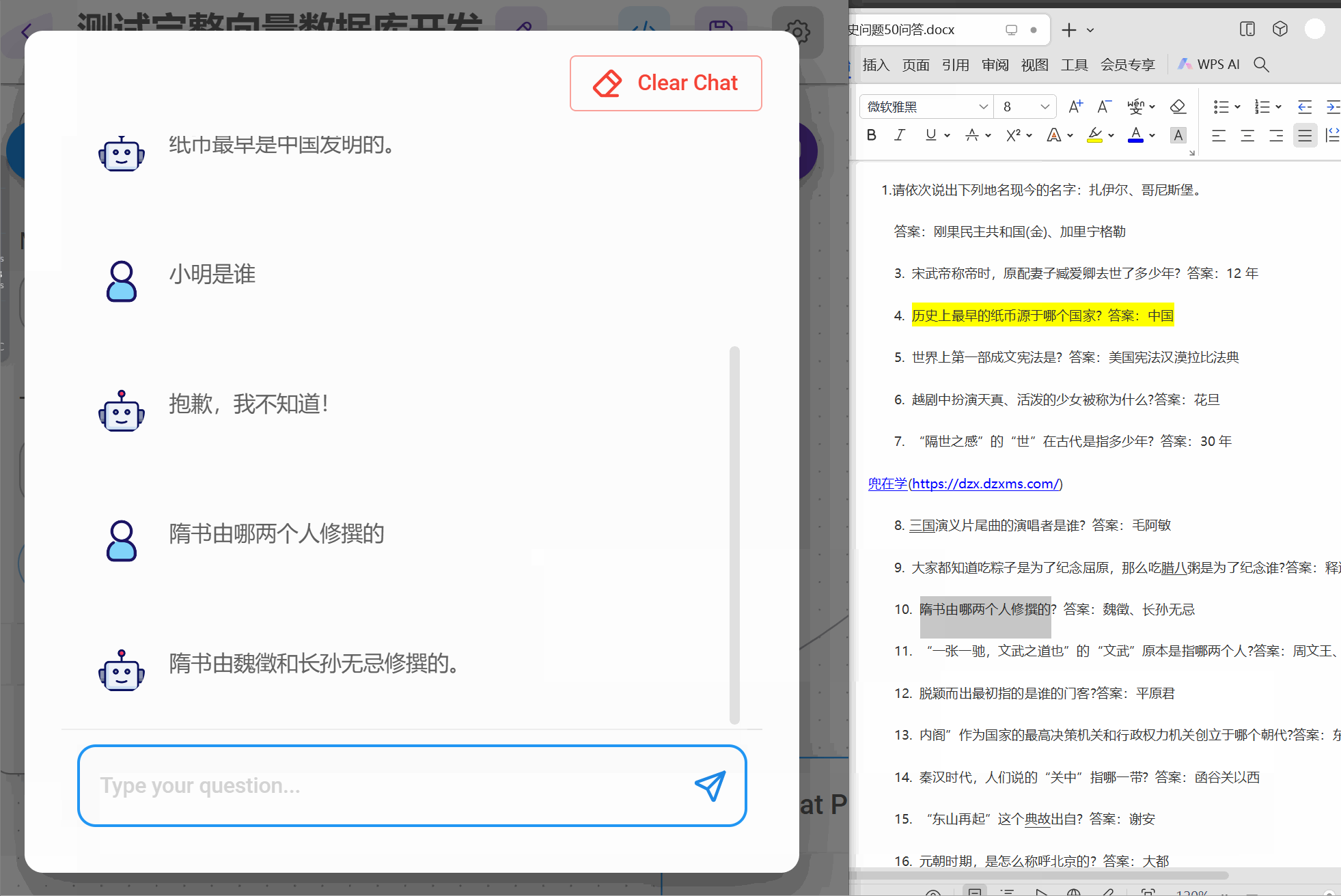
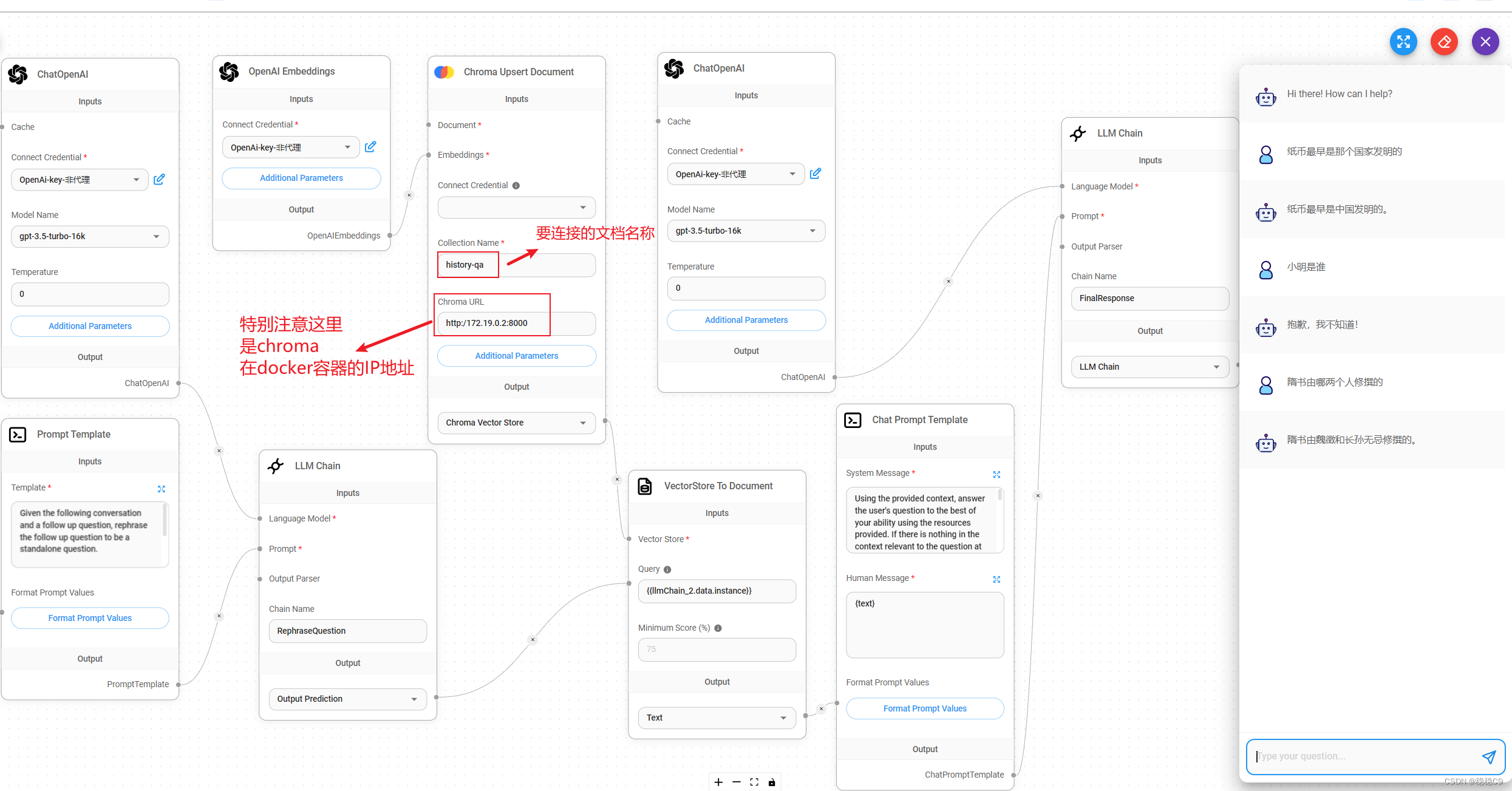
在实现这个flow时候,需要提前将数据向量化到数据库,准备任意QA文档,我这里50个历史问答
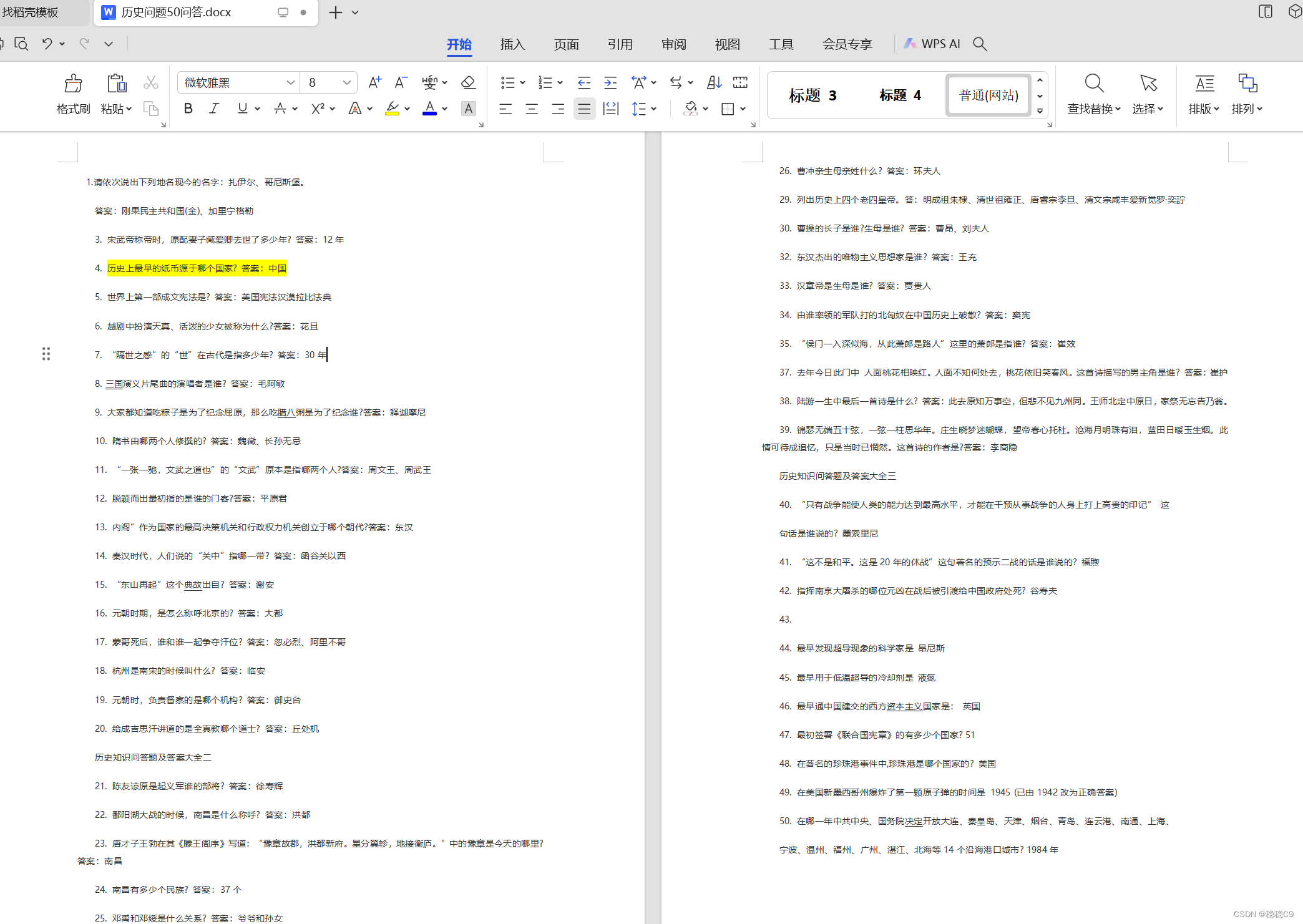
step1 将文档构建到向量数据库
from langchain.embeddings import OpenAIEmbeddings, SentenceTransformerEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import Docx2txtLoader
import chromadb
import os
import uuidos.environ["OPENAI_API_KEY"] = '你的OpenAikey'# 加载器
loader = Docx2txtLoader(r'C:\Users\wenwenc9\Desktop\历史问题50问答.docx')
documents_source = loader.load()# 切割文件
text_splitter = RecursiveCharacterTextSplitter(chunk_size=50, chunk_overlap=20)
documents = text_splitter.split_documents(documents_source)将文件向量到数据库
client = chromadb.HttpClient(host='localhost', port=8000)
# embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
embedding_function = OpenAIEmbeddings(model="text-embedding-ada-002")# 通过langchain使用向量库
Chroma = Chroma(client=client,embedding_function=embedding_function,
)try:collection = client.create_collection(name='history-qa', embedding_function=embedding_function)print("不存在集合,创建数据库")# 为每个文档创建一个文档id,并且将文档id,元数据,文档内容添加到数据库# 为文档增加iddoc_ids = [str(uuid.uuid4()) for _ in documents]for i, _doc in enumerate(documents):_id = doc_ids[i]_doc.metadata['doc_id'] = _id # 构建文档序号属性Chroma._collection = collection# 存储文档Chroma.add_documents(documents)
except Exception as e:collection = client.get_collection(name='history-qa', embedding_function=embedding_function)Chroma._collection = collectionprint('已经存在集合,进行查询')res = Chroma.as_retriever().invoke("历史最早的纸币是那个国家发行的?")
print(res)step2:验证是否成功构建生成向量
import osos.environ["OPENAI_API_KEY"] = '你的key'import chromadbfrom langchain.embeddings import OpenAIEmbeddingsembedding_function = OpenAIEmbeddings()client = chromadb.HttpClient(host='localhost', port=8000)# 按名称从现有集合中获取集合对象。 如果未找到,将引发异常。
collection = client.get_collection(name="history-qa")
res = collection.peek(2) # 返回集合中前 2 项的列表
print(res)
step4 在flowise服务构建 flow编排
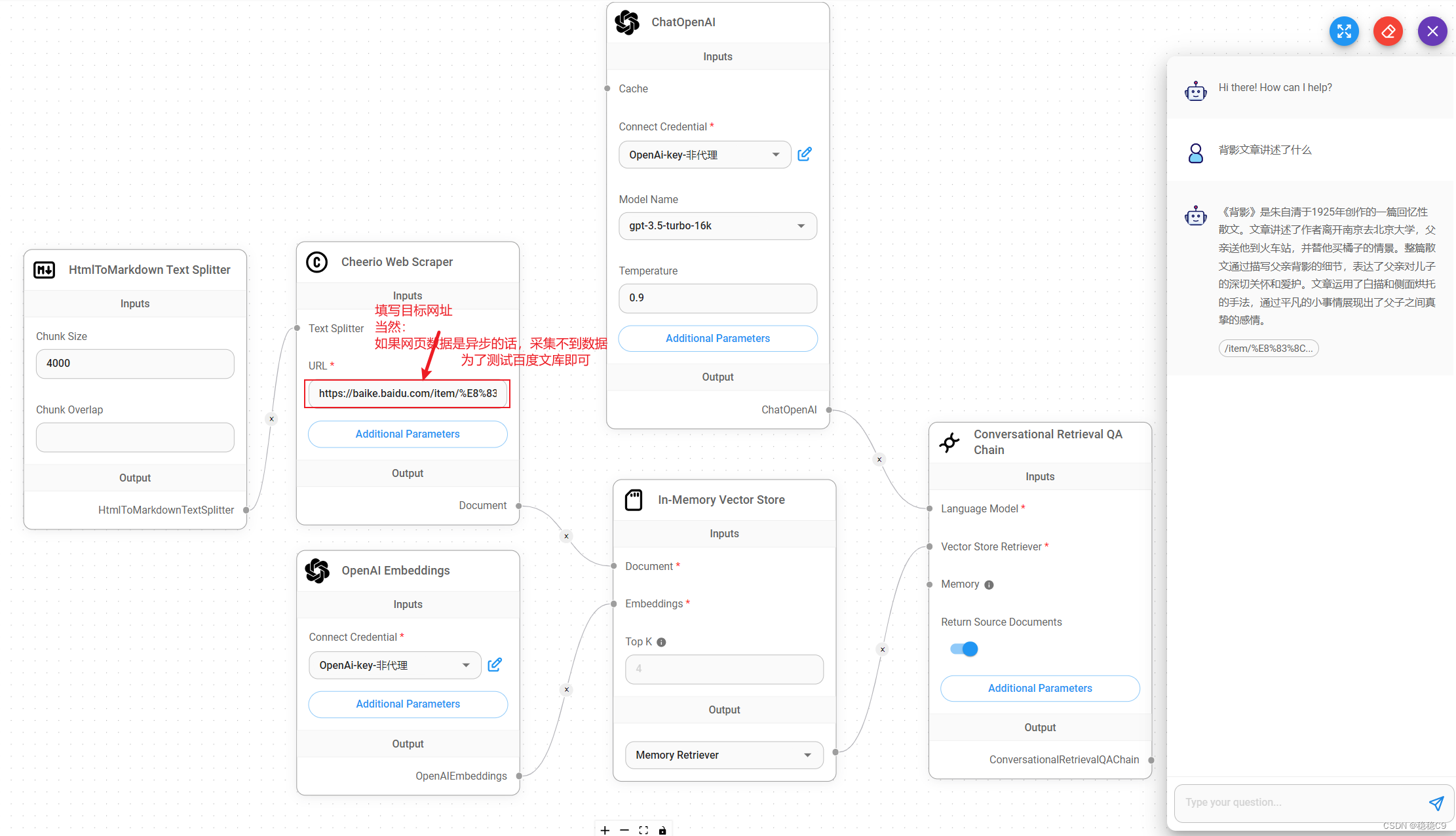
(6)网页采集问答
目标地址
https://baike.baidu.com/item/%E8%83%8C%E5%BD%B1/2663983?fr=ge_ala
这篇关于低代码!小白用10分钟也能利用flowise构建AIGC| 业务问答 | 文本识别 | 网络爬虫的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



