本文主要是介绍医学图像分割2 TransUnet:Transformers Make Strong Encoders for Medical Image Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TransUnet:Transformers Make Strong Encoders for Medical Image Segmentation
这篇文章中你可以找到一下内容:
- Attention是怎么样在CNN中火起来的?-Non Local
- Transformer结构带来了什么?-Multi Head Self Attention
- Transformer结构为何在CV中如此流行?-Vision Transformer和SETR
- TransUnet又是如何魔改Unet和Transformer?-ResNet50+VIT作为backbone\Encoder
- TransUnet的pytorch代码实现
- 作者吐槽以及偷懒的痕迹
引文
在医学图像分割领域,U形结构的网络,尤其是Unet,已经取得了很优秀的效果。但是,CNN结构并不擅长建立远程信息连接,也就是CNN结构的感受野有限。尽管可以通过堆叠CNN结构、使用空洞卷积等方式增加感受野,但也会引入一些奇怪的问题(包括但不限于卷积核退化、空洞卷积造成的栅格化),导致最终效果受限。
基于self-attention机制的Transformer结构在NLP任务中已经取得了重要的成就,Vision Transformer将Transformer结构引入了CV领域,并在当年取得了十分优秀的成果。Transformer因此在CV中流行起来。
话说回来,为什么Transformer结构能够在CV领域中获得不错的效果?
Attention is all you need?
在介绍Transformer之前,我们先看一下CNN结构中有什么好玩的东西。
先回顾一下 Non Local结构
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k} } )V Attention(Q,K,V)=softmax(dkQKT)V
从Non Local开始,注意力(Attention)机制在17、18年的各大顶会大杀四方,出现了包括NonLocal Net、DANet、PSANet、ISANet、CCNet等等网络。这里的核心思想只有一个,就是Attention机制,可以不限距离的建立远程连接,突破了CNN模型感受野不足的问题。当然,这种Attention的计算方法有一个缺陷就是计算量很大。因此,在这一个方向,CCNet、ISANet等等网络,也针对计算量大这一个缺陷进行优化,从而发了一些顶会论文。
当然,为什么会想到提出Non Local来计算Attention呢,是因为Non Local作者从Transformer中得到了灵感。所以,再回到提出Transformer的那篇经典论文《Attention is all you need》。
这篇论文主要是两个工作,一个是提出了Transformer,另一个则是Multi-head Attention,也就是用多头注意力机制来代替注意力。
Transformer的结构很简单,主要就是Multi-Head Atention、FFN、Norm几个模块。其中需要注意的就是Multi-Head Atention。
Multi-Head Atention其实并不难理解,Multi-Head Atention只是Attention机制中的一种。Multi-Head Atention顾名思义,也就是有多个Head,其中每一个Head计算一组注意力,也就是将Scaled Dot-Product Attention的过程做h次,再把输出合并起来。这样,同一个位置有拥有了h个表示,相比于Scaled Dot-Product Attention,输出的内容就更加丰富了。
M u l t i − H e a d A t t e n t i o n ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O \small Multi-Head Attention(Q, K, V) = Concat(head_1, ..., head_h)W^O Multi−HeadAttention(Q,K,V)=Concat(head1,...,headh)WO
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) \small head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
Vision Transformer - the pioneer from CNN to Transformer
Vision Transformer可谓是CV届的开路先锋,也是CVer的救世主,在没有Vit前,CVer不知道还要在Non Local中挣扎多久。(当然,现在Transformer也快挣扎不下去了)。
Vit的论文《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》Google的人取名字都挺有意思。
实现原理也很简单,Transformer处理的都是序列数据,而图像数据是不能直接输入Transformer的。因此呢,Vit就想了一个方法,把图像分成9块,也就是9个patch(当然,可以分成16块,25块等等,具体取决于你的一个patch的大小)。这样,再把patch按顺序拼接起来,变成一个序列,这个序列添加了一个positional encoding后,就可以输入Transformer中进行处理。这里的positional encoding作用是让模型知道图像patch的顺序,有助于模型学习。
Vit在ImageNet上的成功,让CV届看到了希望。分割是CV的一大任务,既然Vit能够进行分类,那他就能像ResNet一样充当分割任务的Backbone。
SERT Vit也能用于语义分割!
那么,在另一个CVPR顶会论文中,《Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers》SERT就最先使用Vit作为BackBone实现语义分割任务。
SERT模型实现也很简单,用经典的encoder-decoder网络,Vit作为BackBone,设计了三种不同的Decoder结构,进行语义分割实验,证明Vit在语义分割中是可行的。很简单的一个思路,先实现就能先吃到肉(感谢Vit白送的一个顶会)。
正文
前面废话了很多,都是关于CNN、Attention、Non Local、Transformer,我们回到TransUnet模型。CV论文中很大一部分都是拼凑剪裁(虽然TransUnet看起来也像是拼凑剪裁)。不过,拼凑剪裁也是一门艺术。正如下图,TransUnet结构。
还是很经典的Unet形网络,但和CNN-base的Unet不同,这里前三层是CNN-based,但是最后一层是Transformer-based。也就是把Unet的encoder最后一层换成了Transformer模型。
为什么只有一层Transformer
TransUnet只将其中一部分换成Transformer也是有它自己的考虑。虽然Transformer能够获得到全局的感受野,但是在细节特征的处理上存在缺陷。
SegFormer:《Segmenter: Transformer for Semantic Segmentation》论文中讨论了patch size大小对于模型预测结果的影响,发现,大patch size虽然计算速度更快,但是边缘的分割效果明显很差,而小patch size边缘相对更为精确一些。
很多事实都证明,Transformer对于局部的细节分割是有缺陷的。而CNN反而是得益于其局部的感受野,能够较为精确恢复细节特征。因此呢,TransUnet模型只替换了最后一层,而这一层则更多关注全局信息,这是Transformer擅长的,至于浅层的细节识别任务则由CNN来完成。
TransUnet具体细节
- decoder结构很简单,还是典型的skip-connection和upsample结合。
- 对于encoder部分:
- 作者选取了ResNet50的前三层作为CNN结构,这很好理解,ResNet牛逼嘛。
- 最后一层则是Vit结构,也就是12层Transformer Layer
- 作者把encoder叫做R50-ViT。
对于Vit的一些介绍,可以看另一篇文章:VIT+SETR,本文就偷懒省略了。
不过,需要注意的是,如果输入Vit的大小为(b, c, W, H),patch size=P时,Vit的输出为(b, c, W/P, H/P), 也就是 H / P H/P H/P , W / P W/P W/P,需要上采样到(W, H)大小。
TransUnet模型实现
Encoder部分
Encoder部分主要由ResNet50和Vit组成,在ResNet50部分,取消掉stem_block结构中的4倍下采样,保留前三层模型结构,这三层都选择两倍下采样,其中最后一层的输出作为Vit的输入,这样保证了feature size、channel number和原图对应。
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):expansion: int = 4def __init__(self, inplanes, planes, stride = 1, downsample = None, groups = 1,base_width = 64, dilation = 1, norm_layer = None):super(BasicBlock, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dif groups != 1 or base_width != 64:raise ValueError("BasicBlock only supports groups=1 and base_width=64")if dilation > 1:raise NotImplementedError("Dilation > 1 not supported in BasicBlock")# Both self.conv1 and self.downsample layers downsample the input when stride != 1self.conv1 = nn.Conv2d(inplanes, planes ,kernel_size=3, stride=stride, padding=dilation,groups=groups, bias=False,dilation=dilation)self.bn1 = norm_layer(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(planes, planes ,kernel_size=3, stride=stride, padding=dilation,groups=groups, bias=False,dilation=dilation)self.bn2 = norm_layer(planes)self.downsample = downsampleself.stride = stridedef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass Bottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample= None,groups = 1, base_width = 64, dilation = 1, norm_layer = None,):super(Bottleneck, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dwidth = int(planes * (base_width / 64.0)) * groups# Both self.conv2 and self.downsample layers downsample the input when stride != 1self.conv1 = nn.Conv2d(inplanes, width, kernel_size=1, stride=1, bias=False)self.bn1 = norm_layer(width)self.conv2 = nn.Conv2d(width, width, kernel_size=3, stride=stride, bias=False, padding=dilation, dilation=dilation)self.bn2 = norm_layer(width)self.conv3 = nn.Conv2d(width, planes * self.expansion, kernel_size=1, stride=1, bias=False)self.bn3 = norm_layer(planes * self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass ResNet(nn.Module):def __init__(self,block, layers,num_classes = 1000, zero_init_residual = False, groups = 1,width_per_group = 64, replace_stride_with_dilation = None, norm_layer = None):super(ResNet, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dself._norm_layer = norm_layerself.inplanes = 64self.dilation = 2if replace_stride_with_dilation is None:# each element in the tuple indicates if we should replace# the 2x2 stride with a dilated convolution insteadreplace_stride_with_dilation = [False, False, False]if len(replace_stride_with_dilation) != 3:raise ValueError("replace_stride_with_dilation should be None "f"or a 3-element tuple, got {replace_stride_with_dilation}")self.groups = groupsself.base_width = width_per_groupself.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)self.bn1 = norm_layer(self.inplanes)self.relu = nn.ReLU(inplace=True)self.layer1 = self._make_layer(block, 64//4, layers[0], stride=2)self.layer2 = self._make_layer(block, 128//4, layers[1], stride=2, dilate=replace_stride_with_dilation[0])self.layer3 = self._make_layer(block, 256//4, layers[2], stride=2, dilate=replace_stride_with_dilation[1])self.layer4 = self._make_layer(block, 512//4, layers[3], stride=1, dilate=replace_stride_with_dilation[2])self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512 * block.expansion, num_classes)for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)# Zero-initialize the last BN in each residual branch,# so that the residual branch starts with zeros, and each residual block behaves like an identity.# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677if zero_init_residual:for m in self.modules():if isinstance(m, Bottleneck):nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]elif isinstance(m, BasicBlock):nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]def _make_layer(self,block,planes,blocks,stride = 1,dilate = False,):norm_layer = self._norm_layerdownsample = Noneprevious_dilation = self.dilationif dilate:self.dilation *= stridestride = strideif stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False),norm_layer(planes * block.expansion))layers = []layers.append(block(self.inplanes, planes, stride, downsample, self.groups, self.base_width, previous_dilation, norm_layer))self.inplanes = planes * block.expansionfor _ in range(1, blocks):layers.append(block(self.inplanes,planes,groups=self.groups,base_width=self.base_width,dilation=self.dilation,norm_layer=norm_layer,))return nn.Sequential(*layers)def _forward_impl(self, x):out = []x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.layer1(x)out.append(x)x = self.layer2(x)out.append(x)x = self.layer3(x)out.append(x)# 最后一层不输出# x = self.layer4(x)# out.append(x)return outdef forward(self, x) :return self._forward_impl(x)def _resnet(block, layers, pretrained_path = None, **kwargs,):model = ResNet(block, layers, **kwargs)if pretrained_path is not None:model.load_state_dict(torch.load(pretrained_path), strict=False)return modeldef resnet50(pretrained_path=None, **kwargs):return ResNet._resnet(Bottleneck, [3, 4, 6, 3], pretrained_path,**kwargs)def resnet101(pretrained_path=None, **kwargs):return ResNet._resnet(Bottleneck, [3, 4, 23, 3], pretrained_path,**kwargs)if __name__ == "__main__":v = ResNet.resnet50().cuda()img = torch.randn(1, 3, 512, 512).cuda()preds = v(img)# torch.Size([1, 64, 256, 256])print(preds[0].shape)# torch.Size([1, 128, 128, 128])print(preds[1].shape)# torch.Size([1, 256, 64, 64])print(preds[2].shape)
接着是Vit部分,Vit接受ResNet50的第三个输出。
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrangedef pair(t):return t if isinstance(t, tuple) else (t, t)class PreNorm(nn.Module):def __init__(self, dim, fn):super().__init__()self.norm = nn.LayerNorm(dim)self.fn = fndef forward(self, x, **kwargs):return self.fn(self.norm(x), **kwargs)class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout = 0.):super().__init__()self.net = nn.Sequential(nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)class Attention(nn.Module):def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):super().__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5self.attend = nn.Softmax(dim = -1)self.dropout = nn.Dropout(dropout)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):qkv = self.to_qkv(x).chunk(3, dim = -1)q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)dots = torch.matmul(q, k.transpose(-1, -2)) * self.scaleattn = self.attend(dots)attn = self.dropout(attn)out = torch.matmul(attn, v)out = rearrange(out, 'b h n d -> b n (h d)')return self.to_out(out)class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):super().__init__()self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn xclass ViT(nn.Module):def __init__(self, *, image_size, patch_size, dim, depth, heads, mlp_dim, channels = 512, dim_head = 64, dropout = 0., emb_dropout = 0.):super().__init__()image_height, image_width = pair(image_size)patch_height, patch_width = pair(patch_size)assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'num_patches = (image_height // patch_height) * (image_width // patch_width)patch_dim = channels * patch_height * patch_widthself.to_patch_embedding = nn.Sequential(Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),nn.Linear(patch_dim, dim),)self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))self.cls_token = nn.Parameter(torch.randn(1, 1, dim))self.dropout = nn.Dropout(emb_dropout)self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)self.out = Rearrange("b (h w) c->b c h w", h=image_height//patch_height, w=image_width//patch_width)# 这里上采样倍数为8倍。为了保持和图中的feature size一样self.upsample = nn.UpsamplingBilinear2d(scale_factor = patch_size//2)self.conv = nn.Sequential(nn.Conv2d(dim, dim, 3, padding=1),nn.BatchNorm2d(dim),nn.ReLU())def forward(self, img):# 这里对应了图中的Linear Projection,主要是将图片分块嵌入,成为一个序列x = self.to_patch_embedding(img)b, n, _ = x.shape# 为图像切片序列加上索引cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)x = torch.cat((cls_tokens, x), dim=1)x += self.pos_embedding[:, :(n + 1)]x = self.dropout(x)# 输入到Transformer中处理x = self.transformer(x)# delete cls_tokens, 输出前需要删除掉索引output = x[:,1:,:]output = self.out(output)# Transformer输出后,上采样到原始尺寸output = self.upsample(output)output = self.conv(output)return outputimport torch
if __name__ == "__main__":v = ViT(image_size = (64, 64), patch_size = 16, channels = 256, dim = 512, depth = 12, heads = 16, mlp_dim = 1024, dropout = 0.1, emb_dropout = 0.1).cpu()# 假设ResNet50第三层输出大小是 1, 256, 64, 64 也就是b, c, W/8, H/8img = torch.randn(1, 256, 64, 64).cpu()preds = v(img)# 输出是 b, c, W/16, H/16# preds: torch.Size([1, 512, 32, 32])print("preds: ",preds.size())
再把两个部分合并一下,包装成TransUnetEncoder类。
class TransUnetEncoder(nn.Module):def __init__(self, **kwargs):super(TransUnetEncoder, self).__init__()self.R50 = ResNet.resnet50()self.Vit = ViT(image_size = (64, 64), patch_size = 16, channels = 256, dim = 512, depth = 12, heads = 16, mlp_dim = 1024, dropout = 0.1, emb_dropout = 0.1)def forward(self, x):x1, x2, x3 = self.R50(x)x4 = self.Vit(x3)return [x1, x2, x3, x4]if __name__ == "__main__":x = torch.randn(1, 3, 512, 512).cuda()net = TransUnetEncoder().cuda()out = net(x)# torch.Size([1, 64, 256, 256])print(out[0].shape)# torch.Size([1, 128, 128, 128])print(out[1].shape)# torch.Size([1, 256, 64, 64])print(out[2].shape)# torch.Size([1, 512, 32, 32])print(out[3].shape)
Decoder部分
Decoder部分就是经典的Unet decoder模块了,接受skip connection,然后卷积,上采样、卷积。同样包装成TransUnetDecoder类。
class TransUnetDecoder(nn.Module):def __init__(self, out_channels=64, **kwargs):super(TransUnetDecoder, self).__init__()self.decoder1 = nn.Sequential(nn.Conv2d(out_channels//4, out_channels//4, 3, padding=1), nn.BatchNorm2d(out_channels//4),nn.ReLU() )self.upsample1 = nn.Sequential(nn.UpsamplingBilinear2d(scale_factor=2),nn.Conv2d(out_channels, out_channels//4, 3, padding=1),nn.BatchNorm2d(out_channels//4),nn.ReLU() )self.decoder2 = nn.Sequential(nn.Conv2d(out_channels*2, out_channels, 3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU() )self.upsample2 = nn.Sequential(nn.UpsamplingBilinear2d(scale_factor=2),nn.Conv2d(out_channels*2, out_channels, 3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU() )self.decoder3 = nn.Sequential(nn.Conv2d(out_channels*4, out_channels*2, 3, padding=1),nn.BatchNorm2d(out_channels*2),nn.ReLU() ) self.upsample3 = nn.Sequential(nn.UpsamplingBilinear2d(scale_factor=2),nn.Conv2d(out_channels*4, out_channels*2, 3, padding=1),nn.BatchNorm2d(out_channels*2),nn.ReLU() )self.decoder4 = nn.Sequential(nn.Conv2d(out_channels*8, out_channels*4, 3, padding=1),nn.BatchNorm2d(out_channels*4),nn.ReLU() )self.upsample4 = nn.Sequential(nn.UpsamplingBilinear2d(scale_factor=2),nn.Conv2d(out_channels*8, out_channels*4, 3, padding=1),nn.BatchNorm2d(out_channels*4),nn.ReLU() )def forward(self, inputs):x1, x2, x3, x4 = inputs# b 512 H/8 W/8x4 = self.upsample4(x4)x = self.decoder4(torch.cat([x4, x3], dim=1)) x = self.upsample3(x)x = self.decoder3(torch.cat([x, x2], dim=1))x = self.upsample2(x)x = self.decoder2(torch.cat([x, x1], dim=1))x = self.upsample1(x)x = self.decoder1(x)return xif __name__ == "__main__":x1 = torch.randn([1, 64, 256, 256]).cuda()x2 = torch.randn([1, 128, 128, 128]).cuda()x3 = torch.randn([1, 256, 64, 64]).cuda()x4 = torch.randn([1, 512, 32, 32]).cuda()net = TransUnetDecoder().cuda()out = net([x1,x2,x3,x4])# out: torch.Size([1, 16, 512, 512])print(out.shape)
TransUnet类
最后将Encoder和Decoder包装成TransUnet。
class TransUnet(nn.Module):# 主要是修改num_classes def __init__(self, num_classes=4, **kwargs):super(TransUnet, self).__init__()self.TransUnetEncoder = TransUnetEncoder()self.TransUnetDecoder = TransUnetDecoder()self.cls_head = nn.Conv2d(16, num_classes, 1)def forward(self, x):x = self.TransUnetEncoder(x)x = self.TransUnetDecoder(x)x = self.cls_head(x)return xif __name__ == "__main__":# 输入的图像尺寸 [1, 3, 512, 512]x1 = torch.randn([1, 3, 512, 512]).cuda()net = TransUnet().cuda()out = net(x1)# 输出的结果[batch, num_classes, 512, 512]print(out.shape)
在Camvid测试集上测试一下
因为手头没有合适的医学领域的图像,就随便找个数据集测试一下分割效果。
Camvid是自动驾驶领域的一个分割数据集,八九百张图像比较少,在我的电脑上运行快一点。
一些参数设置如下
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
import warnings
warnings.filterwarnings("ignore")
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CamVidDataset(torch.utils.data.Dataset):"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.Args:images_dir (str): path to images foldermasks_dir (str): path to segmentation masks folderclass_values (list): values of classes to extract from segmentation maskaugmentation (albumentations.Compose): data transfromation pipeline (e.g. flip, scale, etc.)preprocessing (albumentations.Compose): data preprocessing (e.g. noralization, shape manipulation, etc.)"""def __init__(self, images_dir, masks_dir):self.transform = A.Compose([A.Resize(512, 512),A.HorizontalFlip(),A.VerticalFlip(),A.Normalize(),ToTensorV2(),]) self.ids = os.listdir(images_dir)self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]def __getitem__(self, i):# read dataimage = np.array(Image.open(self.images_fps[i]).convert('RGB'))mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))image = self.transform(image=image,mask=mask)return image['image'], image['mask'][:,:,0]def __len__(self):return len(self.ids)# 设置数据集路径
DATA_DIR = r'../blork_file/dataset//camvid/' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train_images')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'valid_images')
y_valid_dir = os.path.join(DATA_DIR, 'valid_labels')train_dataset = CamVidDataset(x_train_dir, y_train_dir,
)
val_dataset = CamVidDataset(x_valid_dir, y_valid_dir,
)train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=True, drop_last=True)
一些模型和训练过程设置
from d2l import torch as d2l
from tqdm import tqdm
import pandas as pd
import monai
# model
model = TransUnet(num_classes=33).cuda()
# training loop 100 epochs
epochs_num = 100
# 选用SGD优化器来训练
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
schedule = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[30,80], gamma=0.5)# 损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)def evaluate_accuracy_gpu(net, data_iter, device=None):if isinstance(net, nn.Module):net.eval() # Set the model to evaluation modeif not device:device = next(iter(net.parameters())).device# No. of correct predictions, no. of predictionsmetric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):# Required for BERT Fine-tuning (to be covered later)X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)output = net(X)metric.add(d2l.accuracy(output, y), d2l.size(y))return metric[0] / metric[1]# 训练函数
def train_ch13(net, train_iter, test_iter, loss, optimizer, num_epochs, schedule, devices=d2l.try_all_gpus()):timer, num_batches = d2l.Timer(), len(train_iter)animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1], legend=['train loss', 'train acc', 'test acc'])net = nn.DataParallel(net, device_ids=devices).to(devices[0])# 用来保存一些训练参数loss_list = []train_acc_list = []test_acc_list = []epochs_list = []time_list = []lr_list = []for epoch in range(num_epochs):# Sum of training loss, sum of training accuracy, no. of examples,# no. of predictionsmetric = d2l.Accumulator(4)for i, (X, labels) in enumerate(train_iter):timer.start()if isinstance(X, list):X = [x.to(devices[0]) for x in X]else:X = X.to(devices[0])gt = labels.long().to(devices[0])net.train()optimizer.zero_grad()result = net(X)loss_sum = loss(result, gt)loss_sum.sum().backward()optimizer.step()acc = d2l.accuracy(result, gt)metric.add(loss_sum, acc, labels.shape[0], labels.numel())timer.stop()if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[3], None))schedule.step()test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f"epoch {epoch+1}/{epochs_num} --- loss {metric[0] / metric[2]:.3f} --- train acc {metric[1] / metric[3]:.3f} --- test acc {test_acc:.3f} --- lr {optimizer.state_dict()['param_groups'][0]['lr']} --- cost time {timer.sum()}")#---------保存训练数据---------------df = pd.DataFrame()loss_list.append(metric[0] / metric[2])train_acc_list.append(metric[1] / metric[3])test_acc_list.append(test_acc)epochs_list.append(epoch+1)time_list.append(timer.sum())lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])df['epoch'] = epochs_listdf['loss'] = loss_listdf['train_acc'] = train_acc_listdf['test_acc'] = test_acc_listdf["lr"] = lr_listdf['time'] = time_listdf.to_excel("../blork_file/savefile/TransUnet_camvid.xlsx")#----------------保存模型------------------- if np.mod(epoch+1, 5) == 0:torch.save(net.state_dict(), f'../blork_file/checkpoints/TransUnet_{epoch+1}.pth')# 保存下最后的modeltorch.save(net.state_dict(), f'../blork_file/checkpoints/TransUnet_last.pth')# 开始训练
train_ch13(model, train_loader, val_loader, lossf, optimizer, epochs_num, schedule)训练结果:
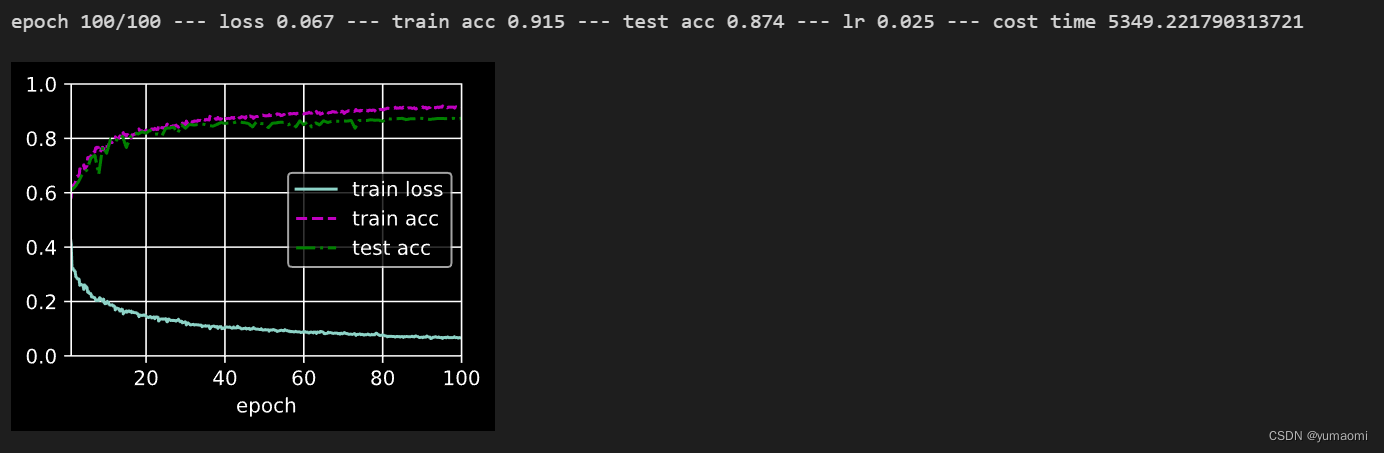
说在最后
文章的代码虽然比较粗糙,但大抵上是与TransUnet原图对应的。如果你想得到不同规模的模型,需要更改的只是每一层的通道数量,你需要在ResNet50中、Vit、Decoder中进行修改和确认。如果你想将TransUnet用在不同的数据集中,你只需要在创建模型时修改num_classes的数值即可。
作者注:
- num_classes的构成主要为:background+类别1+类别2+类别n。
- 作者比较懒,还在自我批评中。如果作者不懒的话,可以把通道数的关系连接一下,这样只需要改一处就可以修改模型规模了,不像现在需要改好几个地方,还需要进行验证。
- 不过,验证的过程也是学习的过程,所以,多看一看代码改一改对小白来说是有很大的好处的。
- 因此,作者在这里为自己偷懒找了一个不错的借口。
- 这篇文章写完了TransUnet,应某位读者的要求,下一篇文章会写SwinUnet。
- 个人认为,Transformer效果不一定会很好。至少作者在自己的细胞数据集上测试情况来讲,Swin Transformer的结果不如传统的CNN模型来得更好。Transformer存在的缺陷很明显,同时GPU资源消耗很大。但是在大物体上的分割效果会很不错,这也是注意力机制的强大之处。但其在细小物体和边界的处理上,明显来的不那么好。这种情况下,使用deformable-DETR中提到的multi-scale Deformable Attention或许会达到一个不错的效果,毕竟可以更关注局部信息。不过2022年的各大顶会已经也都开始了对Transformer的魔改,融合CNN到Transformer中,从而达到局部全局两手抓的效果,像什么MixFormer、MaxVit啊等等。
- 总之呢,个人认为,CV快到瓶颈期了,期待下一匹黑马诞生,干翻Transformer和CNN。
这篇关于医学图像分割2 TransUnet:Transformers Make Strong Encoders for Medical Image Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







