本文主要是介绍基于 zui.sexy的模态选择器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
利用zui的chose组件,封装的一个模态框选择器;
版本 1.0.0;
支持页面多个选择器;
支持查询功能;
效果图如下:
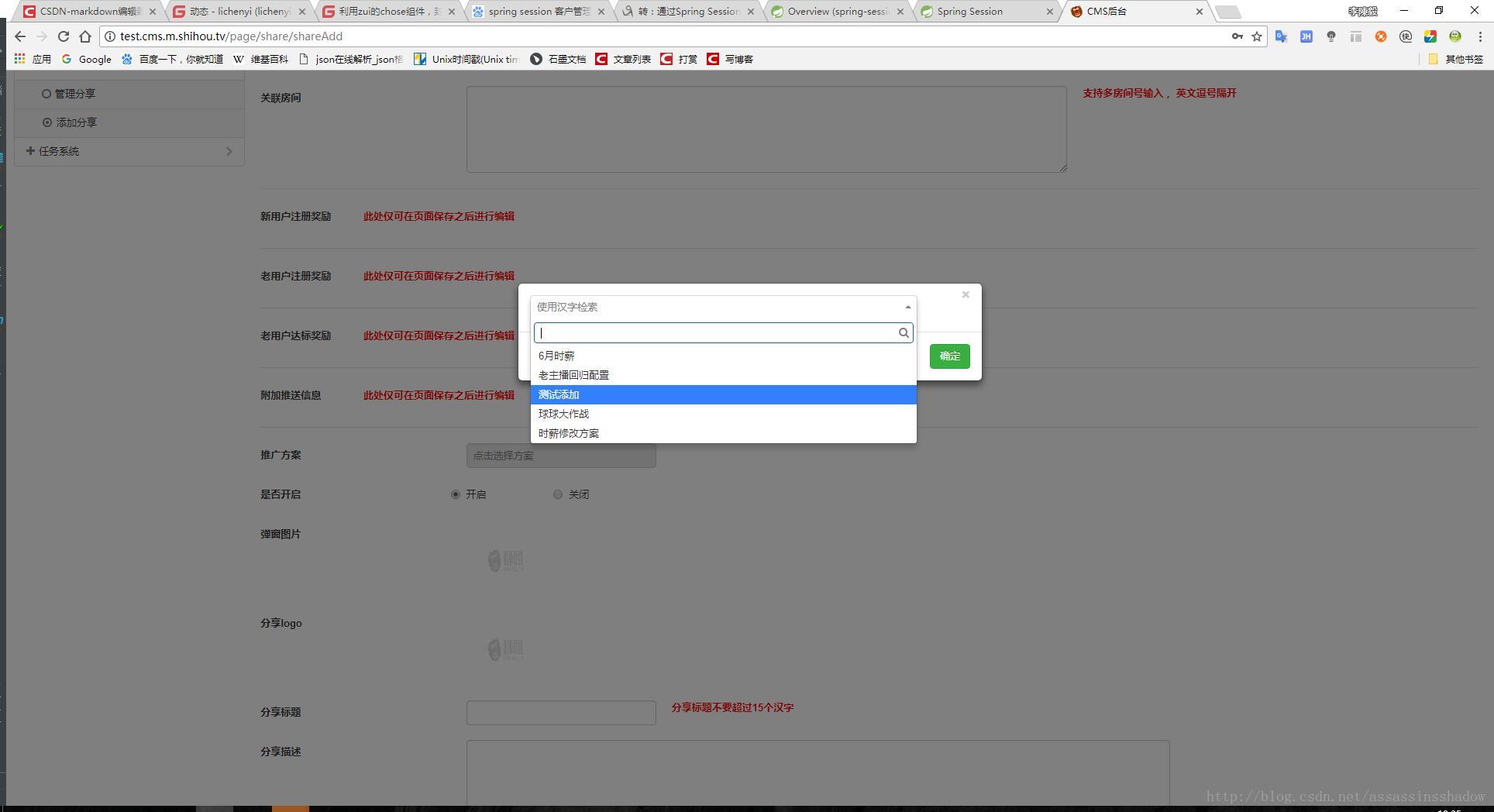
项目地址:https://gitee.com/lichenyi-gitee/html.zui.chosetable.git
有疑问可以留言:
如果觉得文章真心好, 请打赏下我吧,程序员赚钱不容易。 十块八块不嫌多, 一块两块也是爱啊!

这篇关于基于 zui.sexy的模态选择器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







