本文主要是介绍信用评估与违约预测的模型性能调优—决策树集成学习应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在信贷风控场景中,贷前模型的应用对于申请用户的风险防范发挥着重要作用,例如信用评估、欺诈识别、违约预测等。模型的建立过程,必然需要某种机器学习算法来实现,而常用的算法包括逻辑回归、随机森林、XGBoost、LightGBM等,具体采用何种方法较为合适都需要根据建模样本与实际需求而定。但是,无论选取哪类算法,模型最终性能的认可往往不是一步到位的,是在模型训练阶段需要对模型参数经过多次调整优化,并通过模型效果对比选定表现相对较好的模型。本文从数据建模的实践经验出发,以集成学习决策树算法建立信用评估或违约预测模型为场景,介绍下模型性能调优的逻辑思路与注意事项。
对于常见的决策树集成学习模型,例如随机森林、XGBoost、LightGBM、GBDT、AdaBoost等算法,函数本身包含比较多的入模参数,这类参数又可以称为超参数。以XGBoost分类模型算法为例,比较重要的参数有max_depth(树的最大深度)、n_estimators(决策树的数量)、learning_rate(学习率)等,这些参数直接决定着模型训练的性能,对模型效果均有着重要影响。
在多数情况下,使用模型的默认参数进行模型拟合训练,也能够获得较好的预测准确度或分类结果,但是在实际业务中,往往需要获得更精确的模型结果,因此需要对模型的超参数进行调优。例如,XGBoost分类模型的超参数max_depth(树的最大深度)默认取3,然而在建模过程中,模型效果较优情况下的max_depth取值常常是大于3的。但是,此参数的具体取值不能随意设置,如果数值过小,可能会导致模型出现欠拟合,如果数值过大,可能会导致模型出现过拟合。因此,如何根据样本数据赋予某参数一个较为合理的取值,在实际建模过程中需要有一个合理的方式进行模型参数调优。
在实际工作中,最常用的模型调参方法是K折交叉验证与GridSearch网格搜索的综合应用方法,对于各类算法模型的训练拟合非常方便,尤其是针对具有较多参数的决策树集成学习算法,在建模过程中非常适用,而且在很多情况下成为模型性能优化的必备环节。本文将重点介绍下K折交叉验证、GridSearch网格的原理逻辑以及实现过程,便于大家理解掌握模型参数调优的具体方法。
1、K折交叉验证
在机器学习中,由于建模样本的训练集和测试集是随机划分的,因此为了更好地评估模型的有效性,有时会重复使用这些数据,以选出相对表现更好的模型。这个过程的具体描述,可以概况为对原始数据进行拆分,然后组合成为多组不同的训练集与测试集,其中训练集用于拟合模型,测试集用于评估模型,在整个环节某次的训练集可能是下次的测试集,因此称为交叉验证。
对于交叉验证的具体方法,包括简单交叉验证、K折交叉验证、留一交叉验证等,其中K折交叉验证用于相对较为广泛。K折交叉验证是指将建模数据集随机等分为K份,每次选取其中K-1份作为训练集,剩余1份作为测试集,经过训练后可以得到K个模型,然后将K个模型的平均测试效果作为最终的模型效果。通常情况下,如果训练集的样本量较小,则需要增大K值,以保证在每次模型迭代过程中有较多的数据参与模型训练;如果训练集的样本量较大,则需要减小K值,这样可以降低模型在不同样本数据上进行重复拟合性能评估的计算成本。
在Python语言中,K折交叉验证是通过cross_val_score( )函数实现的,代码样例如图1所示。
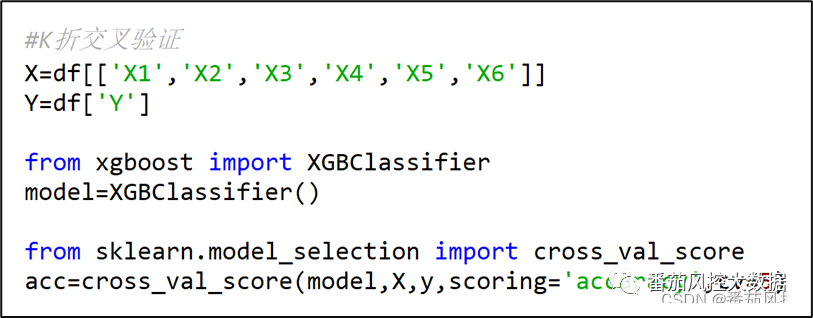
图1 K折交叉验证样例
在上图代码中,对于K折交叉验证函数cross_val_score( ),输入参数依次为模型名称model、特征变量数据X、目标变量数据Y、交叉验证次数cv、评估指标(准确度)scoring=‘accuracy’。其中,模型model可以自定义,样例中指定了XGBoost分类算法;评估指标是准确度accuracy,是函数默认值可以省略不写,若以ROC曲线的AUC值作为评估标准,则表示为scoring=‘roc_auc’;交叉验证次数cv赋值5,最终指标结果会输出5个accuracy值。
2、GridSearch网格
GridSearch网格搜索是一种穷举搜索的参数调优方法,具体流程是遍历所有的候选参数,循环建立模型并评估模型的有效性与准确性,从中选取性能表现最好的参数作为最终参数结果。举个例子,XGBoost分类模型的参数max_depth(树的最大深度),假设输入候选值为[3,5,10,20],则max_depth分别以3、5、10、20进行遍历,并以scoring设置的指标(accuracy、roc_auc)评估模型的性能,从而搜索确定最合适的max_depth取值。如果需要同时对多个参数进行优化,例如max_depth(树的最大深度)、n_estimators(决策树的数量),假设max_depth输入候选值为[3,5,10,20],n_estimators输入候选值为[5,10,20,50],则这2个参数可以构建出4*4=16的网格,从而使模型遍历形成了在网格(Grid)里进行搜索(Search)的过程,这就是GridSearch网格搜索的原理逻辑。
GridSearch网格搜索可以实现单参数调优和多参数调优,由于在实际建模场景中,模型的最终性能往往是由多个参数组合决定的,而且探究模型的较优性能时需要从多个参数维度综合考虑,因此GridSearch网格搜索在决策树集成学习模型的建立过程中,一般都是通过多参数调优进行的。
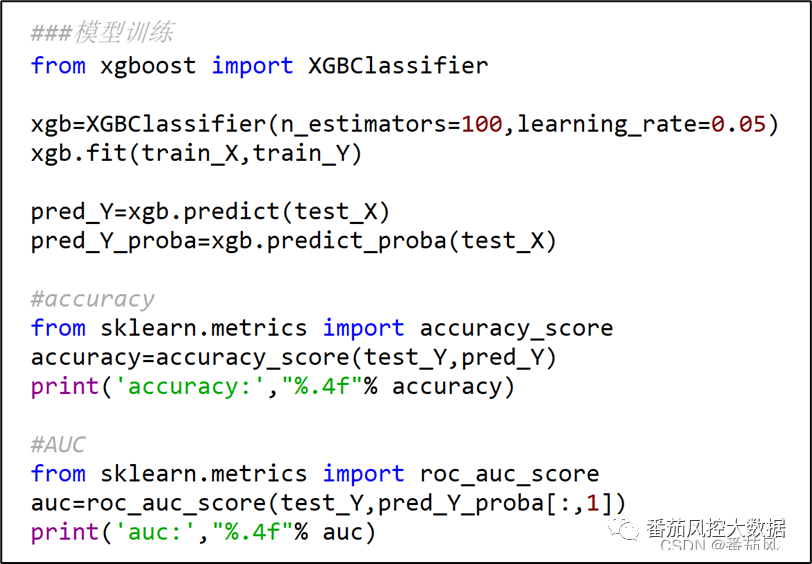
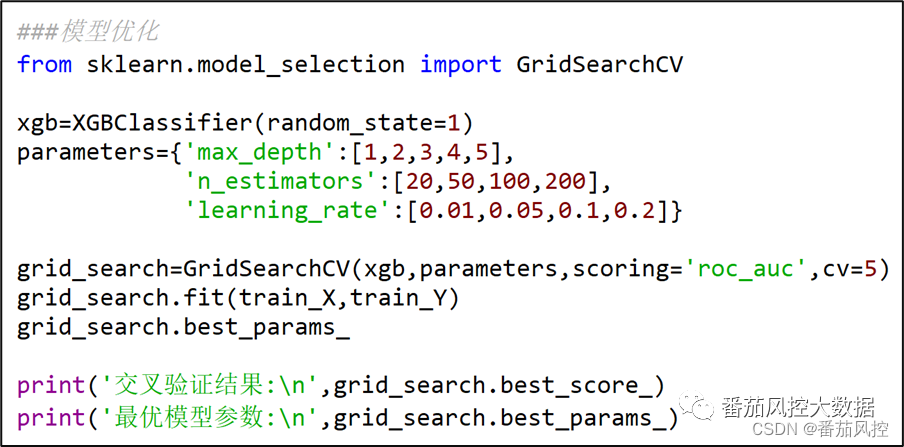
在Python语言中,GridSearch网格搜索是通过GridSearchCV( )函数实现的,现以XGBoost分类模型的参数n_estimators(决策树的数量)、max_depth(树的最大深度)、learning_rate(学习率)为例,说明模型多参数调优的实现过程,代码样例如图2所示。

图2 GridSearch网格搜索样例
在上图代码中,对于GridSearch网格搜索的模型参数形成了544=80种组合,模型将遍历80种参数情形,并通过AUC值作为模型性能评估指标,最终根据best_score_得到的模型指标最优值,采用best_params_输出对应的模型参数组合。以上过程便是在建立模型的参数调优环节,尤其是针对XGBoost、LightGBM、AdaBoost、GBDT、随机森林等决策树集成学习模型,这在实践中是非常重要的。
3、调参注意事项
根据前边对K折交叉验证与 GridSearch网格搜索的介绍,大家已熟悉模型参数调优的思路,并理解模型调参在建模中的重要性,这里简单描述下在参数调优过程的几个注意事项。
(1)除了某些场景下仅需要调整单个参数进行研究,一般情况下最好采用多参数调优进行模型性能的探索,原因是进行单参数调优时,其他参数会取默认值,此时就会忽略多个参数的组合影响。当然,比如研究某个参数对模型性能影响时,单参数调优的方法是最合适的。
(2)采用GridSearchCV函数得到的参数最优值,如果恰好是给定范围的边界值,那么需要进一步参数调优,原因是对于此参数的更优值很有可能存在于给定数值范围以外,此时有必要扩大参数取值范围,再次重新对模型进行网格搜索获取最优的模型参数组合。
(3)对于待优化的参数组合,每个参数的搜索取值范围,尽量不要太多,而且要结合具体场景对数值进行设置,这样是为了避免由于各调优参数给定数值较多,使得参数组合大幅增多,从而在网格搜索过程中,模型训练的时间较长效率降低,这种情况要考虑服务器的性能。因此,模型调优参数的搜索范围务必要结合实际场景以及建模经验进行综合设定,以保证模型调优的效率。
4、案例实操
为了便于大家对决策树集成学习模型性能调优的进一步理解,我们准备了具体的样本数据集与Python代码,供各位小伙伴实操练习,案例通过以XGBoost分类算法为例,详细介绍模型参数的调优过程与结果指标,具体代码包括数据导入、特征分析、数据清洗、模型训练、模型评估、模型调优等过程,详情请大家移步至知识星球查看相关内容。
关于本文所提到的决策树集成学习模型调优的实操内容,本次番茄风控除此文章,也在知识星球平台准备了相关的数据集与代码,帮助大家了解相关的实操内容,加入到知识星球,来参与本周番茄风控的【星球打榜赛】作业吧:

…
~原创文章
这篇关于信用评估与违约预测的模型性能调优—决策树集成学习应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





