本文主要是介绍论文笔记 BIRNet: Brain image registration using dual-supervised fully convolutional networks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BIRNet: Brain image registration using dual-supervised fully convolutional networks
Med Image Anal. 2019 May ; 54: 193–206. doi:10.1016/j.media.2019.03.006.
摘要
文章提出了一种通过从图像外观预测变形来进行图像配准的深度学习方法。由于获得用于训练的ground-truth可能具有挑战性,文章设计了一个受(dual-guidance)双重引导的全卷积网络: (1)使用现有配准方法获得的(deformation fields)变形场进行(groud-truth guidance)地面真实引导 (2)使用配准后的图像之间的差异的图像不相似性引导。第二种引导有助于避免过度依赖训练变形领域的监督。为了有效训练,文章进一步改进了具有(gap filling)间隙填充、(hierarchical loss)分层丢失和(mutil-source strategies)多源策略的深度卷积网络。
BIRNet预测一次通过的变形场,对参数调整不敏感。
文章主要动机和贡献:
1.与传统的配准方法相比,提出了一种端到端的一次快速变形预测框架,无需参数调整。
2.与基于深度学习的配准方法相比,文章旨在解决缺少理想地面真实变形的问题,进而进一步提高配准精度。我们提出了一种双重监督的深度学习策略,包括双重指导:1)使用传统配准方法估计的变形场进行地面真实性指导,以及2)图像不相似性指导,用于测量配准后强度图像之间的差异。一方面,地面实况指导使网络能够从常规方法中快速学习变形和正则化。另一方面,后一种图像差异性指导有助于避免过度依赖来自估计的地面真相变形场的监督,以进一步细化配准网络。
3.为了提高效率和准确性,基于基本U-Net(Ronneberger等人,2015)架构,文章进一步建议使用间隙填充来学习更多高级特征,并使用多通道输入(即梯度图和差异图)来更好地通知配准网络。
无监督方法的效果依赖于关于图像强度关系的假设,因此可能不是最佳的。
配准的一般公式:![]()
文章提出了一种用于大脑可变形配准的新型分层双监督FCN,下图为模型网络图,其中圈1到圈4分别代表做出的改进。
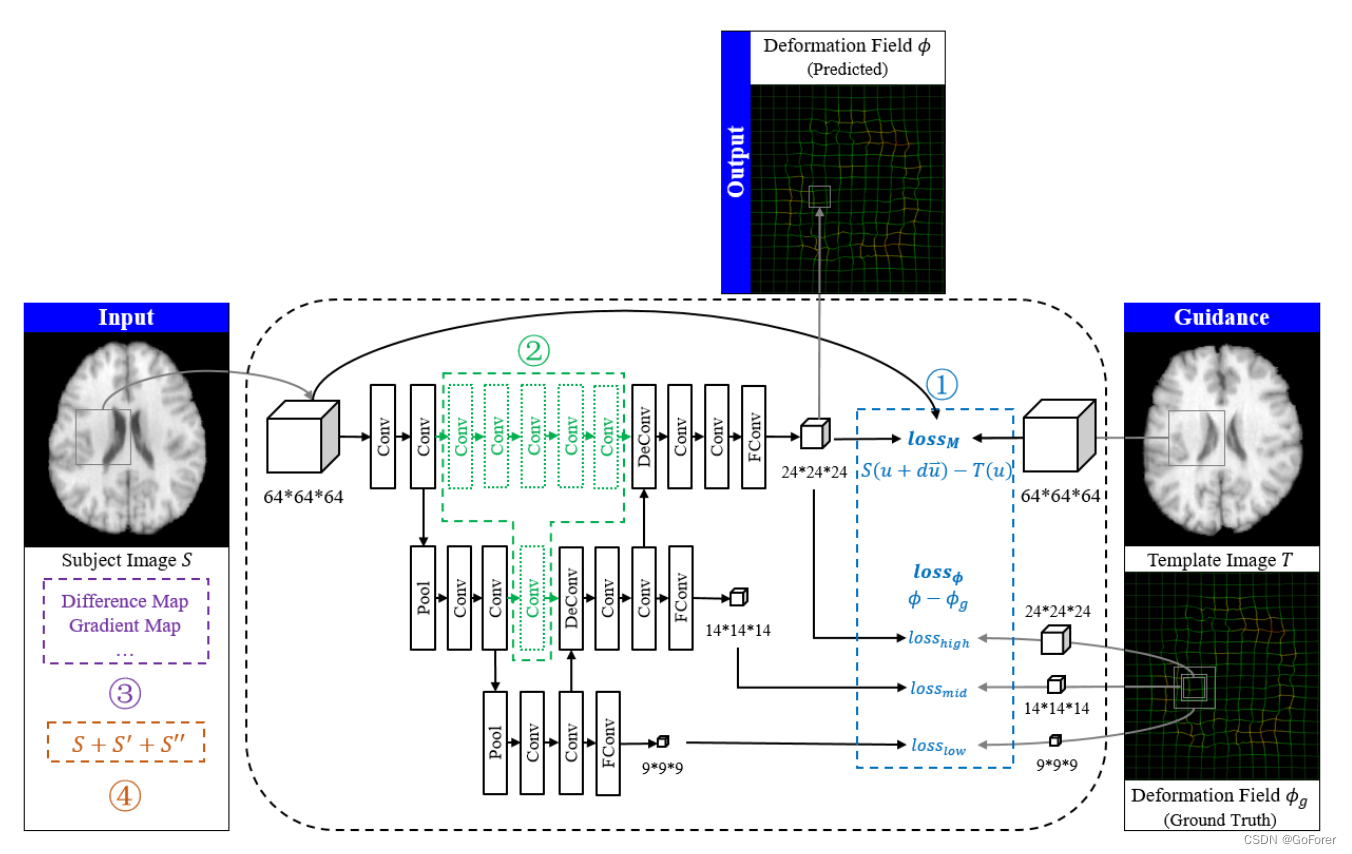
(个人理解:模型输入是一个64*64*64的patch,整个网络都是在局部的patch上进行的,输入数据会进行数据扩充,输入数据还会增加通道,输入差异图和梯度图来提高精度,在Unet网络中,每一层加入额外卷积补充信息,还有在每一层的下采样后进行分级损失计算,也就是文章中的分层监督;双重监督应该是指的是对预测变形场的patch和ground truth的patch计算loss,以及固定图像的patch和形变图片的patch做loss。)
文章实现基于重叠的64×64×64图像块。输出是24×24×24块位移矢量,因为可变形预测与图像的局部信息高度相关,而且只能估计中心区域的变形场。对于图像中变形场的端到端预测,使用基于U-Net(Ronneberger等人,2015)的回归模型。文章还提出了四种改进配准的策略:
1) 分级双重监督。除了变形场之外,还使用图像之间的差异作为监督训练的附加信息。还在U-Net的上采样路径中使用分层损失层,在前层中提供更多约束,以便于收敛。
2) 间隙填充。为了提高预测精度,在u型端之间进一步插入额外的卷积层,以连接低级和高级特征。
3) 多通道输入。除了图像强度之外,差异图和梯度图也被用作网络的输入。
4) 数据扩充。为了克服过度拟合,通过以不同程度扭曲图像并通过在训练中迭代地包括预测图像来增强训练数据。
分层双监督FCN
分级双重监督 a) 双重监督在我们的双重指导策略中,损失函数由两部分组成:1)𝑙oss𝜙 - 预测变形场与现有(训练)地面真实变形场之间的差异;2) 𝑙oss𝑀 - 基于当前经由网络估计的变形来计算模板和扭曲的对象图像之间的差异。
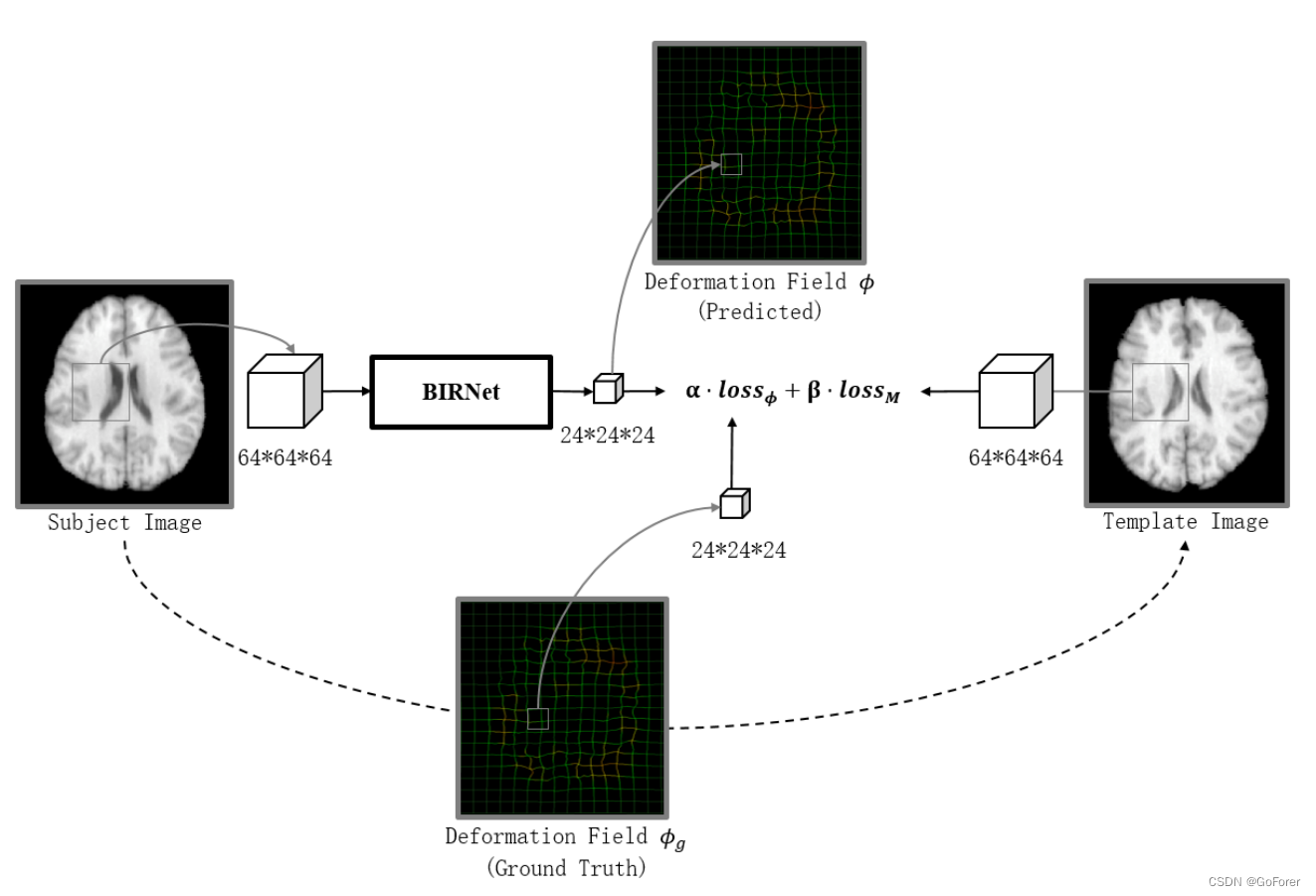
上图为两个loss的图示
loss𝜙是(Rohé等人,2017;Sokotti等人,2017)中定义的欧几里德距离,该距离假设地面真实变形场已经实现。所以它计算的是经过BORNet网络产生的形变场中那一局部和ground-truth中对一个的那一部分之间的距离(看图解释的),公式如下:
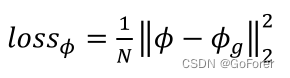
𝜙是预测的变形场,N是体素的数量
𝑙oss𝑀
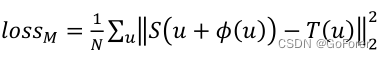
代表整个空间的提速坐标
,
代表
的位移。
整体损失函数:
![]()
其中α和𝛽这两个系数满足α≥ 0 , β ≥ 0,α+β=1。它们在训练过程中是动态变化的,即取更大的𝛼值,以加速收敛并实现更平滑的变形场,若采取更大的𝛽值,以优化配准。在实际实现中,我们首先将两个损失函数的范围归一化为[0,1]。然后,我们设置𝛼 = 0.8和𝛽 = 0.2 初始训练阶段(即前5个阶段)为,后期取𝛼 = 0.5和𝛽 = 0.5(即最后5个时期)。
总之,使用双重制导可以有效地结合两种损失函数的优点:1)由𝑙oss𝜙 使得收敛容易且快速;2)由𝑙oss𝑀 进一步细化配准结果,这可以解决不准确的地面真相问题。
分层监督在传统U-Net中,仅在最后一层计算损失,导致前卷积层中的次优参数(Schmidhuber,2015)。以这种方式,卷积层的前半部分的参数没有后半部分更新得多。这不仅会导致收敛缓慢,而且会过度拟合。因此,我们在每个层中添加一个损失函数,以直接监督网络的前(前)半部分的训练。
当我们使用大小为3×3×3的滤波器时,每个没有padding的卷积层各向同性地将(patch)面片大小减小一个体素。此外,每个池化层将进一步对面片进行降采样。因此,对于输入大小为64×64×64的输patch,将提取24×24×24大小作为高分辨率patch,14×14×14大小作为中分辨率patch,9×9×9大小作为低分辨率patch,
(个人理解) 64×64×64分辨率patch向高中低分辨率的patch转换的公式:
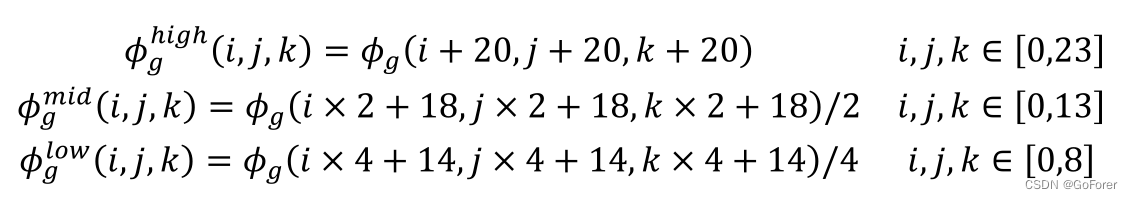
此时,预测变形场的不同尺寸的patch和ground truth的对应patch进行损失函数计算:
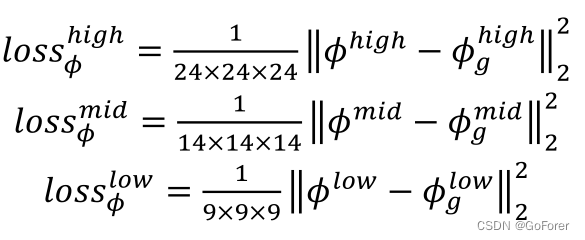
整体的损失函数:
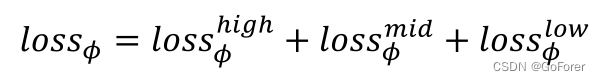
(Gap filling)间隙填充
下图中的黑色网络是U-Net的基本网络架构。它由收缩路径(左侧)和扩张路径(右侧)组成。收缩路径遵循卷积网络的典型架构。它包括两个3×3×3卷积的重复应用(即ReLU(He et al,2015)和批量归一化层(Ioffe和Szegdy,2015)可能遵循的卷积),以及2×2×2最大池操作,步长为2,用于下采样。在每个下采样步骤,将特征通道的数量加倍。扩展路径中的每一步都包括2×2×2反褶积,以对特征图进行上采样并将特征通道的数量减半,以及两个3×3×3卷积。在最后一层,使用1×1×1卷积将每个64个分量的特征向量映射到所需数量的类。为了恢复由于下采样而丢失的细节,我们从收缩路径连接相应裁剪的特征图。
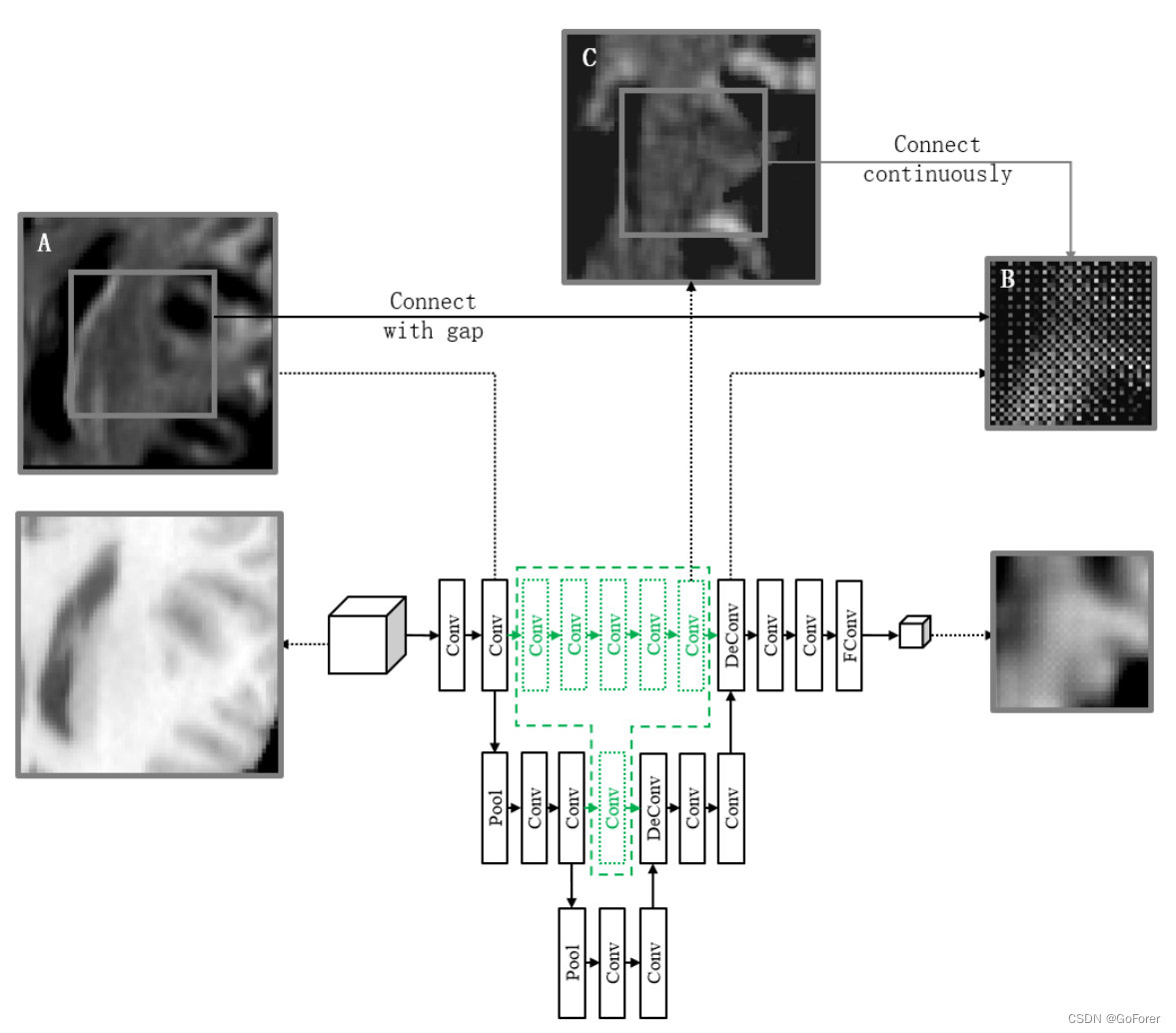
如图3所示,两个特征图A和B明显不同。特征图A类似于原始图像,而特征图B类似于变形场。显然,特征图a和B之间存在巨大的差距,它们通常由传统的U-Net连接在一起。这种差距使网络在培训和测试阶段的效率降低。
为了解决这个问题,我们建议在收缩阶段和扩展阶段的同一级别之间添加额外的卷积层(如图3中的绿色网络所示),以同步特征图的卷积路径。添加的卷积层的参数等于较低分辨率的卷积层。以这种方式,间隙填充后的特征图C将更类似于特征图B,提高了配准精度和训练速度。
(Multi-Channel Inputs)多通道输入
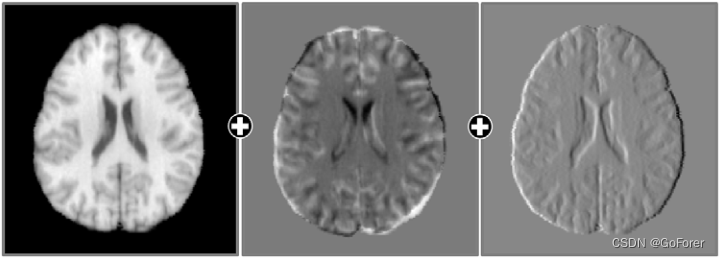
图像特征图,如差分图和梯度图,也可用于提高配准精度。虽然这些可以在深度学习网络中学习,但需要计算资源来学习它们。下图显示了多通道输入,包括原始图像、差异图和梯度图。不同的图被计算为对象图像和模板图像之间的强度差。梯度图提供边界信息以帮助结构对齐。此外,除了原始图像之外,还使用梯度图来计算图像相似度。然后,该约束确保边界区域可以比仅匹配原始强度图像中的图像相似性更精确地对齐。
Implementation 实施
下图显示了所提出的3D图像配准网络的架构,该网络基于图像外观的64×64×64输入patch和变形的24×24×24输出patch。网络使用3D Caffe实现(Jia等人,2014),并使用Adam优化(Kingma和Ba,2014)。我们将初始训练阶段的学习率设置为1e-3,微调训练阶段的为1e-8。该网络从主题图像中提取一个3D patch作为输入,并输出一个3D变形场patch,该patch分别由x、y和z维度的三个独立patch组成(注意,图中只显示了一个分支)。
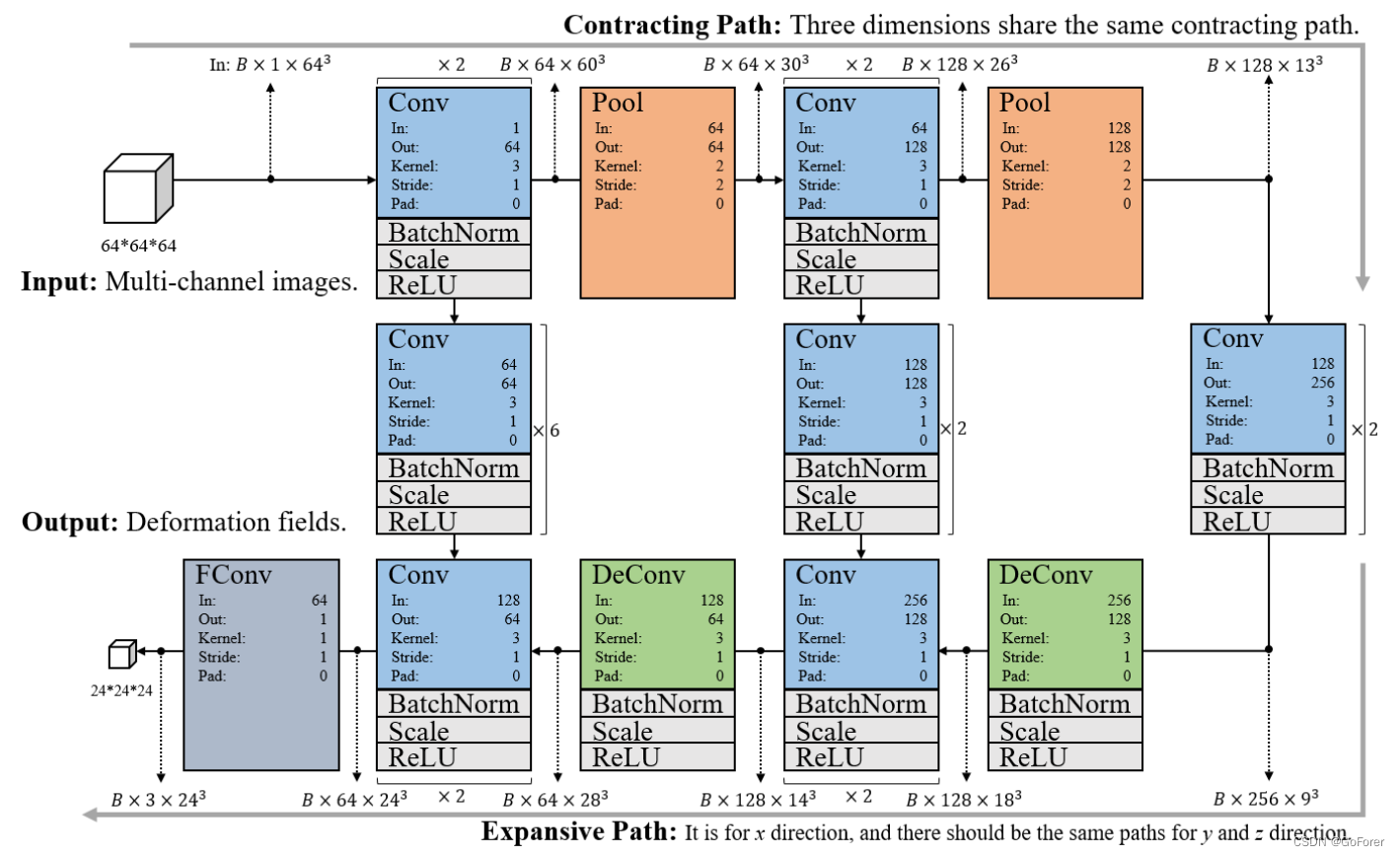
上图就是网络架构图的详细图,把每一层的网络层,输入输出等都详细地表示出来。
(Data Augmentation)数据扩充
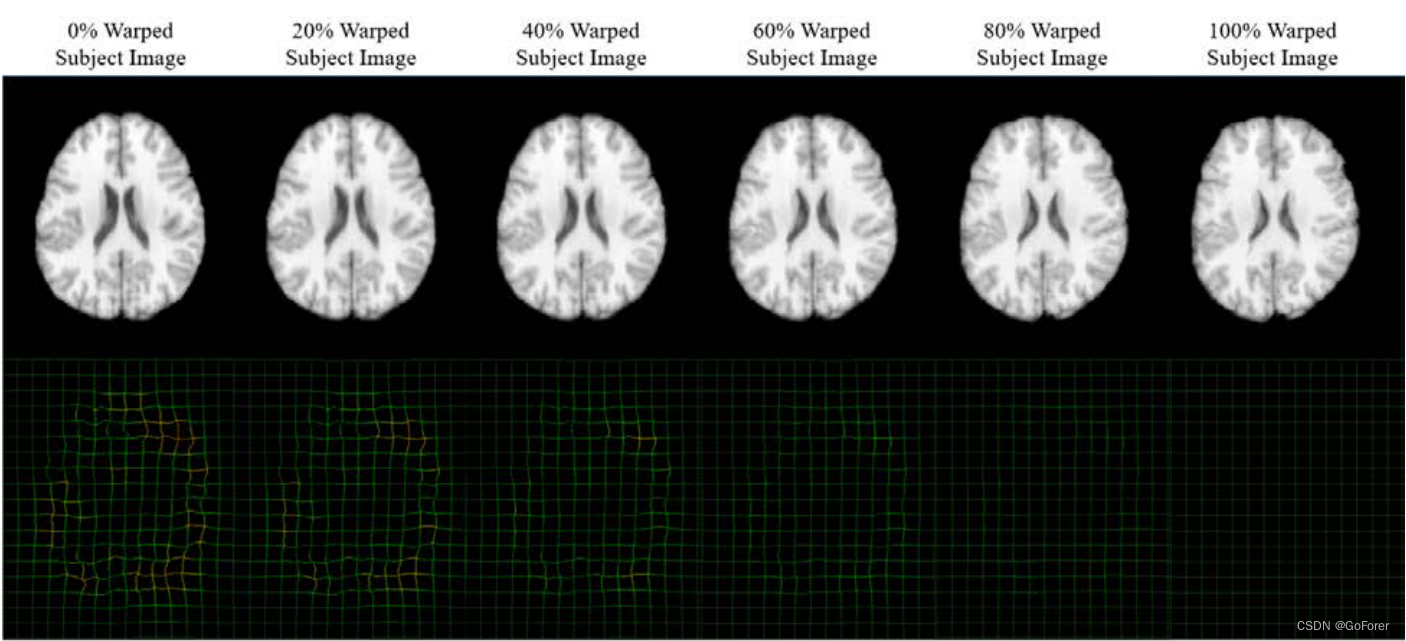
文章在3D脑部MR图像上进行评估。文章使用LONI LPBA40(Shattuck等人,2008)数据集(图像大小:220×220×184)进行训练,其中文章选择一幅图像作为模板,30幅图像作为训练图像,其余9幅图像作为验证图像。所有训练和验证数据的地面真实变形场均使用Diffeomorphic Demons(Vercauteren等人,2009)和SyN(Avants等人,2008)生成。因为它太小,无法进行有效的训练,所以扩充了数据集。这是通过用20%、40%、60%、80%和100%的地面真实变形来扭曲每个对象图像来实现的,同时相应的变形场是预测的目标。下图显示了一个示例。它之所以有效,是因为深度学习模型不会迭代计算变形场,因此具有不同变形程度的中间结果是深度网络训练的有效样本。这将训练数据集的大小显著扩展了6倍,并将允许粗变形和细变形参与训练。
实验
为了评估提出的方法的性能,本节将与几种最先进的可变形配准算法进行比较。使用LPBA40训练BIRNet,然后将其应用于四个不同的数据集,包括IBSR18(Klein等人,2009)、CUMC12(Klein等,2009),MGH10(Klein et al.,2009)和IXI30(Serag等人,2012)。文章选择了3种当时最先进的配准方法(Klein等人,2009),即Diffeomorphic Demons(Vercauteren等人,2009年)、FNIRT(Andersson等人,2007年)和SyN(Avants等人,2008年)进行比较。
基于LPBA40的评估
文章在LPBA40数据集上测试了BIRNet的性能。对于180张训练图像中的每一张,提取了300个大小为64×64×64的patch,总共提供了54000个训练patch。考虑了三种模型:1)原始U-Net,2)没有相似性指导的BIRNet,表示为BIRNet_WOS,3)使用双重指导的BIRRet(文章提出的方法)。下图显示了𝑙oss𝜙 这个𝑙oss𝑀 用于训练和验证。从下图(a)中可以看出,U-Net的性能随着训练的进行而饱和。BIRNet_WOS提高了性能,但BIRNet给出了最佳性能,它进一步考虑了图像的相似性/差异性。同时,BIRNet模型甚至达到了比图中的ground truth更好的精度。
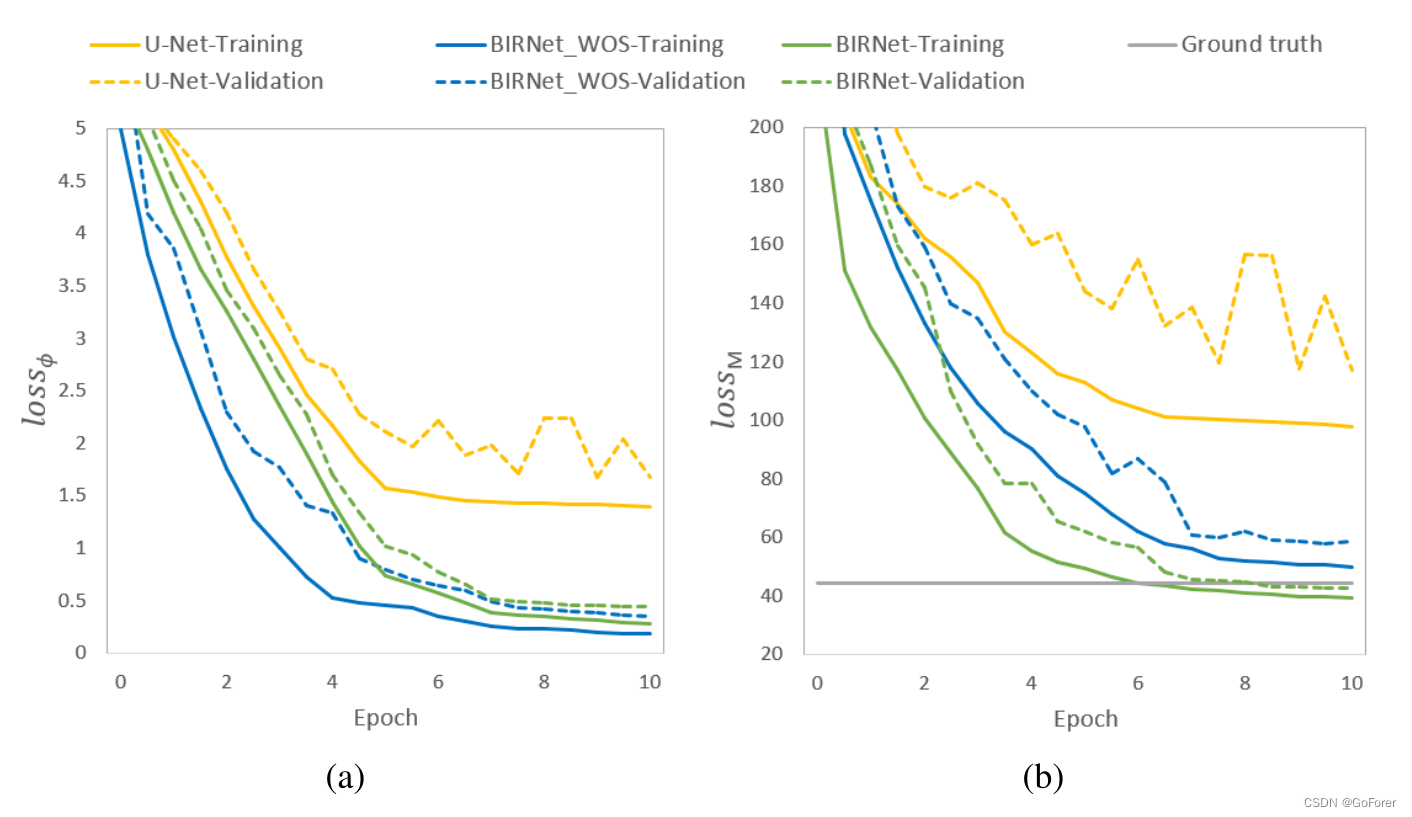
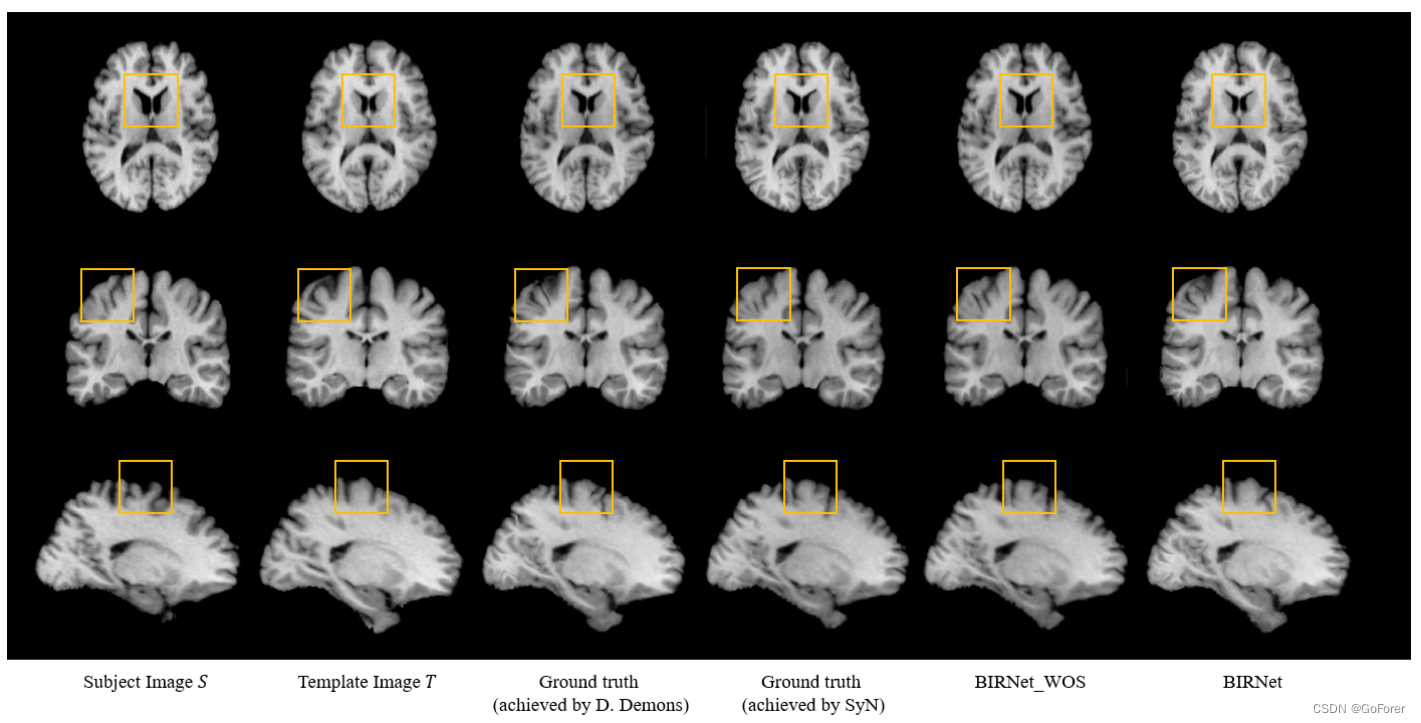
上图结果表明,图像相似性/差异损失可以为进一步细化训练模型提供有用的指导,即使地面真实变形场也不太准确。下图显示了配准结果的一个示例,确认BIRNet生成的结果与模板最相似,特别是在黄色正方形区域。
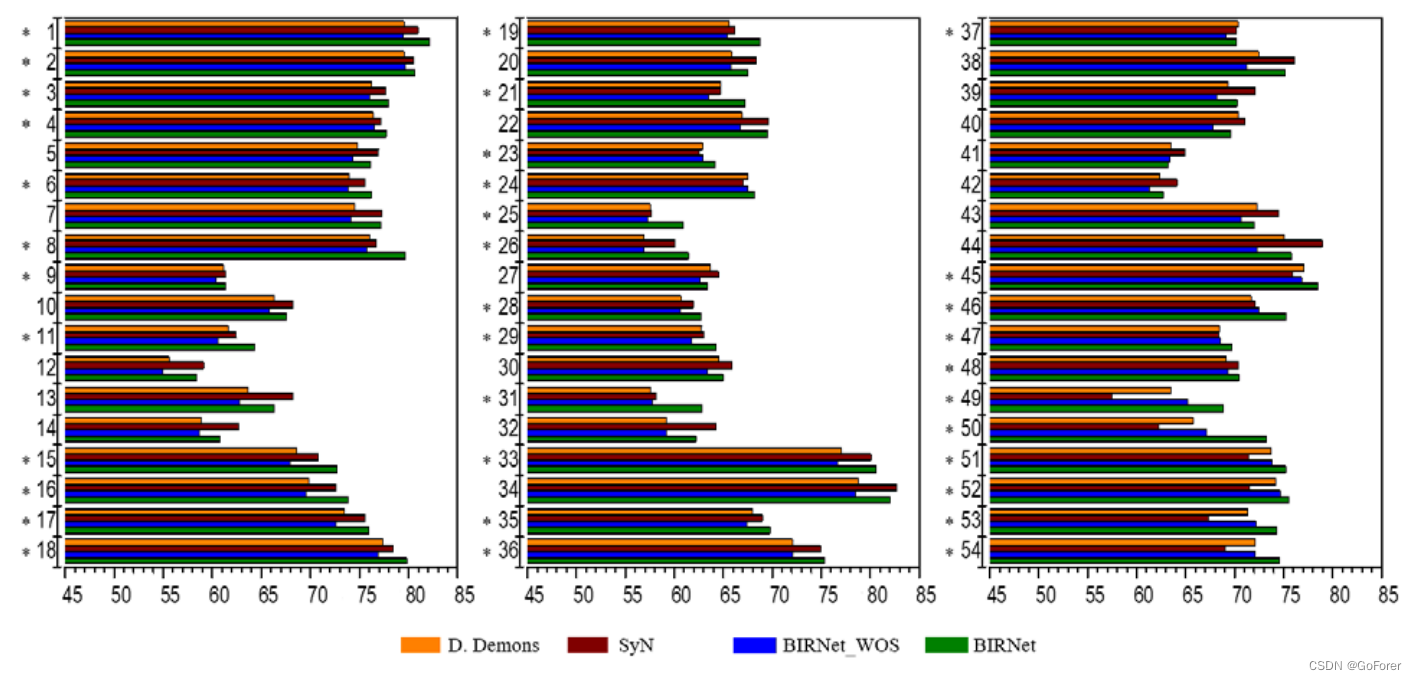
下图显示了54个大脑ROI的Dice相似系数(DSC)(ROI名称见表1,从(Shattuck等人,2008)获得)。我们观察到,BIRNet在54个ROI中的35个ROI中产生了更好的性能,而在其他19个ROI中,具有不同形态Demons和SyN的ROI的性能相当。BIRNet_WOS显示的精度比Diffeomorphic Demons和SyN稍差,这表明双重制导在提高性能方面是有效的。
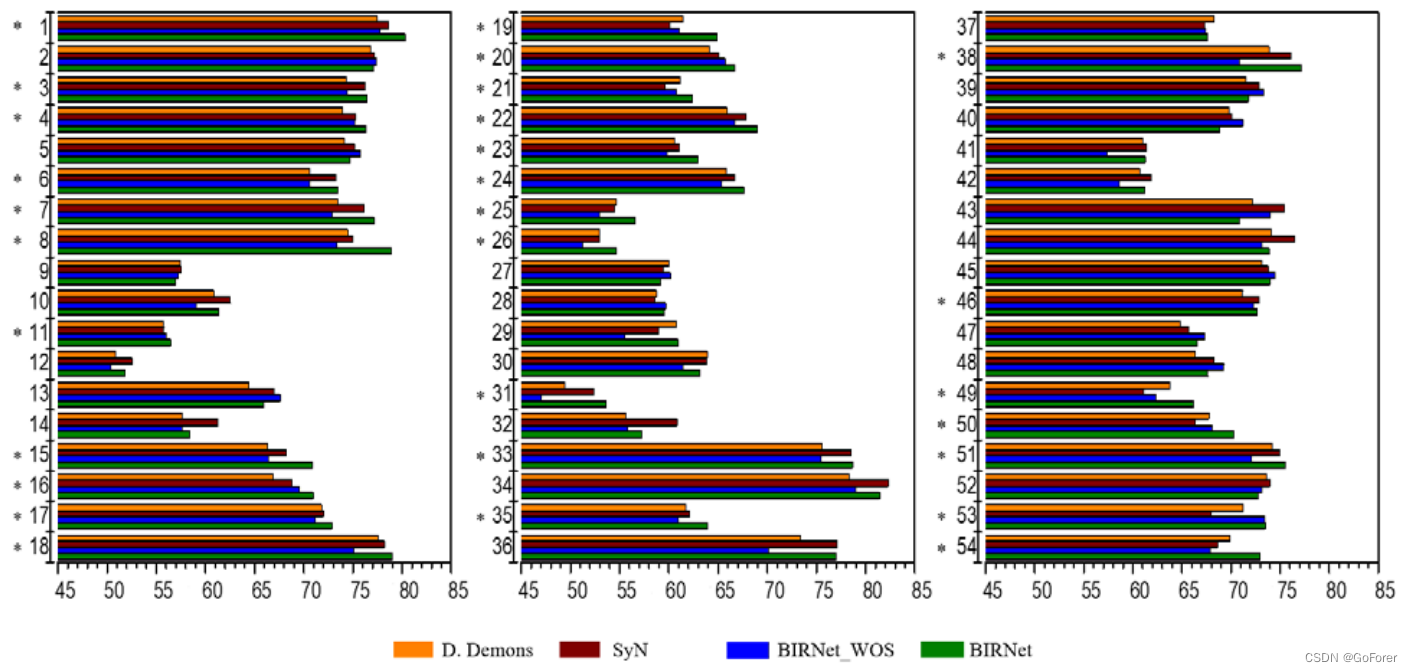
下图显示了来自LPBA40的9张验证对象图像的DSC结果。与Diffeomorphic Demons和SyN相比,BIRNet_WOS的性能略有下降,但仅下降了一小部分(即,平均低于1.5%)。BIRNet在54个ROI中有29个ROI的DSC值更高,与Diffeomorphic Demons和SyN相比,其他25个ROI的值非常相似,再次获得最佳性能。Diffeomorphic Demons、SyN、BIRNet_WOS和BIRNet的平均DSC分别为67.3%、68.1%、66.7%和69.2%。这些结果验证了BIRNet的可推广性。
基于IBSR18、CUMC12、MGH10、IXI30的评估
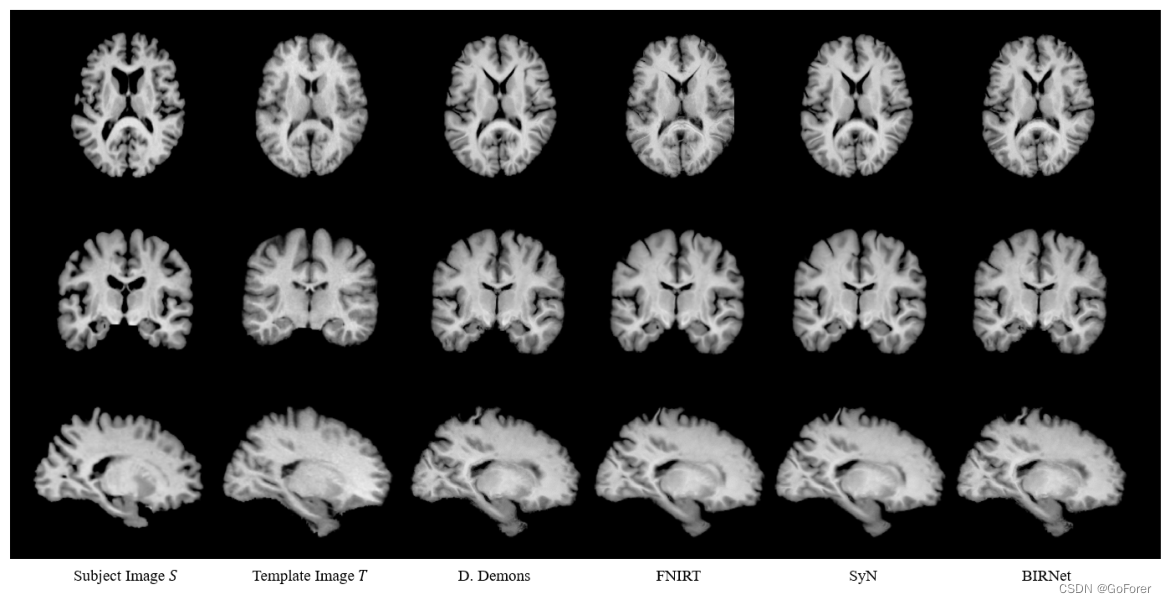
为了进一步评估BIRNet的准确性和可推广性,通过直接应用使用LPBA40数据集训练的模型,在四个不同数据集(即IBSR18(Klein等人,2009)、CUMC12(Klein et al.,2009),MGH10(Klein等,2009)和IXI30(Serag等人,2012))的总共70个大脑图像上进一步测试BIRNet,而无需任何额外的参数调整。IBSR18数据集的一个受试者的结果如下图所示:Diffeomorphoc Demons、SyN、FNIRT(Andersson等人,2007)和BIRNet。注意,对于SyN和FNIRT所示的结果基于针对每个图像单独确定的它们的最佳参数。
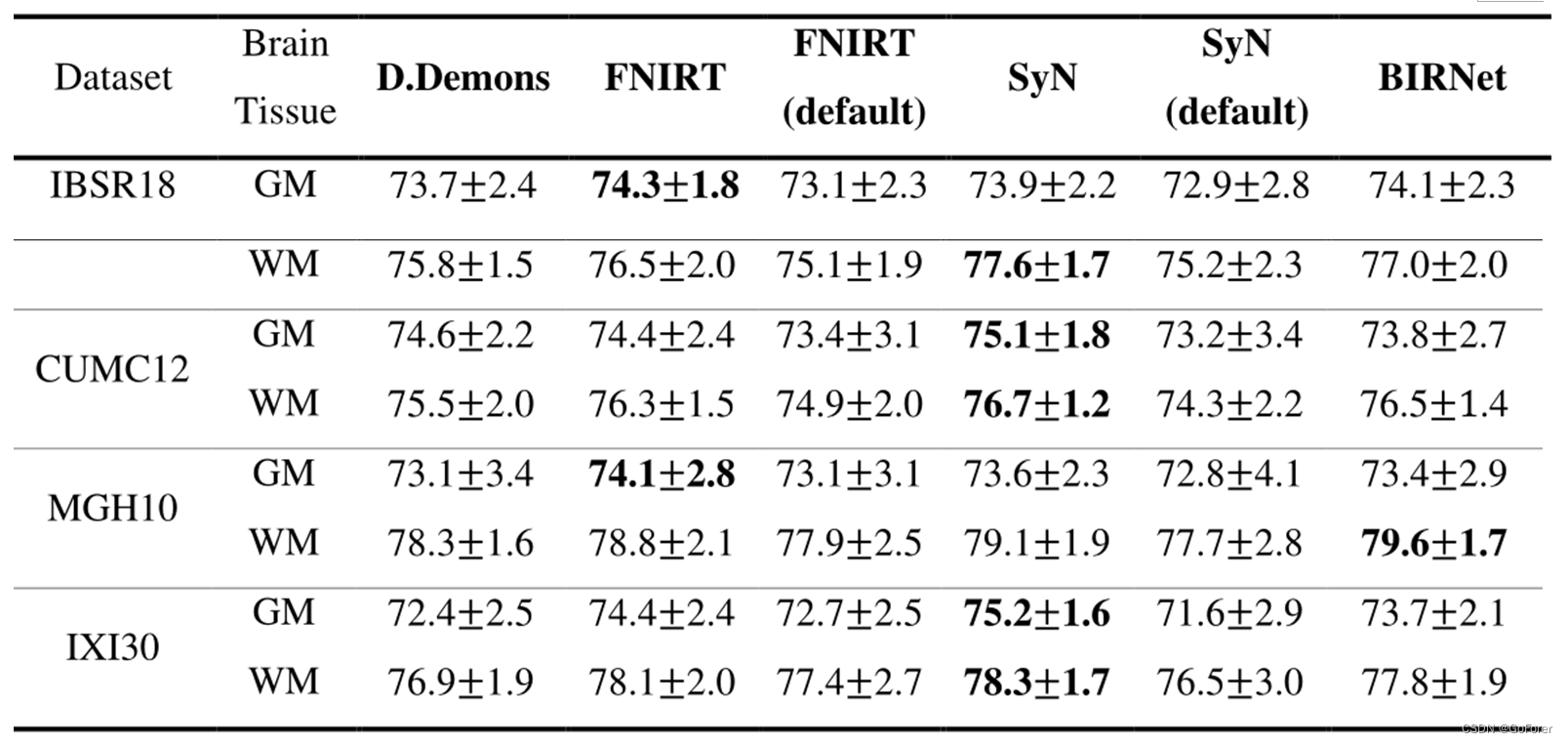
下表提供了基于这四个数据集中提供的GM和WM标签的灰质(GM)和白质(WM)的DSC。BIRNet的性能与经过微调的SyN和FNIRT相当(尤其是这四个数据集中的每一个),但不需要参数调整。这验证了BIRNet的可推广性。
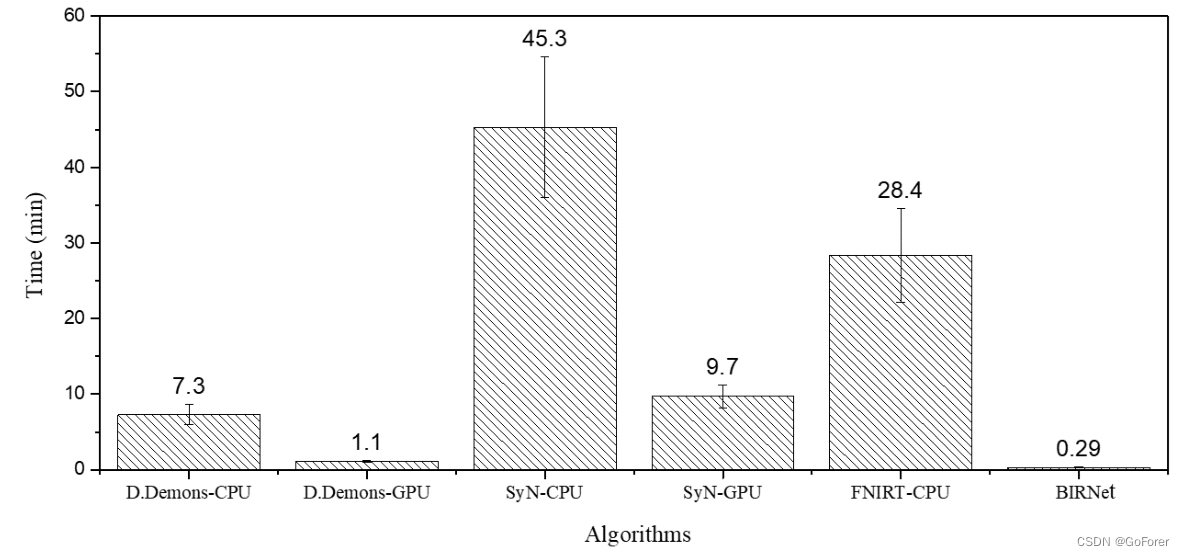
计算成本
下图显示了七种不同可变形配准算法的典型3D大脑图像(220×220×184)的计算成本:Diffeomorphic Demons-CPU(Vercauteren等人,2009)、Diffeomoric Demons-GPU(Muyan Ozzelik等人,2008)、SyN-CPU(Avants等人,2008年)、SyN-GPU(Luo等人,2015)、FNIRT-CPU(Andersson等人,2007)和BIRNet。很明显,BIRNet不需要任何迭代优化,只需要最少的时间。
结论
本文介绍了一种称为BIRNet的双引导全卷积神经网络。
为了解决缺乏地面真实性问题,BIRNet使用预先预测的地面真实性变形场和图像相似性/差异度量来指导训练阶段,从而使深度学习模型能够进一步细化结果。BIRNet采用了填补空白、分级监督、多通道输入和数据扩充等策略来提高注册准确性。实验结果表明,BIRNet在不需要参数调整的情况下实现了最先进的性能。
由于所提出的BIRNet方法是一种通用、快速、准确和易于使用的脑图像配准方法,因此它可以直接应用于许多实际的配准问题。然而,在未来的工作中仍有两个问题可以优化。首先,最近的模型将主题图像配准到固定模板图像,因此需要为新模板图像细化简单传输的模型。第二,预测变形场的平滑性由差纯训练样本来监督。因此,需要对学习模型使用额外的微分同胚约束,以使预测的变形场完全规则。
这篇关于论文笔记 BIRNet: Brain image registration using dual-supervised fully convolutional networks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







