本文主要是介绍集群路径规划学习(一)之EGO-swarm仿真,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码调试与编译
源代码下载
https://github.com/ZJU-FAST-Lab/ego-planner-swarm/tree/master
按照代码要求配置安装环境
sudo apt-get install libarmadillo-dev文件对应拷贝与调整
新建工作空间文件夹
XF_EGOworkspace

新建src
在src文件夹下开启终端,输入:
catkin_init_workspace
复制对应的src下的功能包到工作空间下的src文件夹中
- 退回到工作空间目录,复制除去src文件夹之外的所有文件到该工作空间目录下。
- 复制下载的文件到这个文件夹中
在该文件夹下启动编译
但是由于一下错误的存在,需要单独先编译一个功能包
执行代码:
catkin_make -DCATKIN_WHITELIST_PACKAGES=“uav_simulator/Utils/multi_map_servermulti_map_server”
Missing: multi_map_server/MultiOccupancyGrid.h during building --> found in https://github.com/HKUST-Aerial-Robotics/Fast-Planner/tree/master/uav_simulator/Utils/multi_map_server #65
复制如下h文件到
工作空间文件夹/develop/include/muti_map_server/下。
下载地址:https://github.com/HKUST-Aerial-Robotics/plan_utils/tree/master/multi_map_server/msg_gen/cpp/include/multi_map_server
接着编译工作空间下所有的功能包
catkin_make -DCATKIN_WHITELIST_PACKAGES=""
至此编译成功
path配置
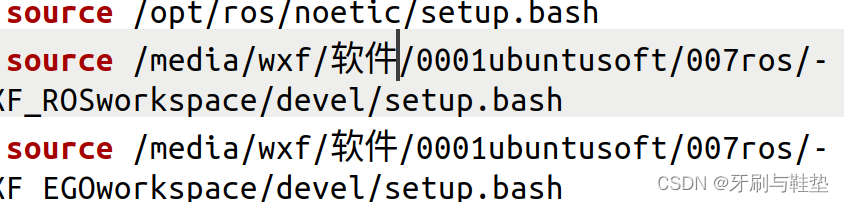
工作空间路径加入到主目录下的.bashrc文件的最后一行

正常是不应该少这个h文件的,应该是先编译子功能包,就会自动成成,不过因为他们封装好的代码已经调用了.h文件,所以只能找他们之前做好的h文件补全进来了。
执行launch文件
没有ego_planner的文件啊 ?
source devel/setup.bash
roslaunch ego_planner simple_run.launch找到原因了,这是因为,功能包的名字与功能包文件夹的名字不一致!
 功能包文件夹下的,package.xml是描述功能包的文件,这个plan_manage文件其实是ego_planner功能包。
功能包文件夹下的,package.xml是描述功能包的文件,这个plan_manage文件其实是ego_planner功能包。

但是,为什么要改这一下子呢?
深度解析simple_run.launch文件
 他找的是功能包ego_planner而不是功能包文件夹的位置。一个是rviz。launch文件一个是swarm.launch文件的嵌套调用。
他找的是功能包ego_planner而不是功能包文件夹的位置。一个是rviz。launch文件一个是swarm.launch文件的嵌套调用。
这篇关于集群路径规划学习(一)之EGO-swarm仿真的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




