本文主要是介绍【单目标轨迹预测】TNT: Target-driveN Trajectory Prediction(翻译+笔记),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
摘要
- 问题: 智能体未来的行为意图难以预测且是多模态性的。
- 思路:在中等时间步长的预测中,目标未来的模式可以通过一组目标状态来有效的捕获
- 方法:第一步,通过编码智能体与环境和其他智能体的交互,来预测智能体未来T步长可能的目标状态;第二步,生成以目标为条件的轨迹状态序;第三步,估计轨迹可能性和最后选择一个紧凑的轨迹预测集。
- 区别:(1)之前的工作将智能体意图建模为潜在变量,并依赖于测试时间采样来生成不同的轨迹;(2)本文提出的是一种可解释的显示的位置空间来表示。
-
6 结论
- 本文提出了一种新的多模态轨迹预测框架TNT。它包括三个可解释的阶段:目标预测、目标条件运动估计和轨迹评分。TNT在四个具有挑战性的真实世界预测数据集上实现了最先进的性能
-
1 导言
(研究所在的背景以及研究的意义所在)
- 问题陈述(与已存在的方法合并为一段)
- 未来预测关键的挑战是高度的不确定性,其主要原因是其他主体的意图和潜在特性是未知的。
- 已存在的方法
- 建模高度多模态的方法:使用灵活的,可以从中抽取样本的潜在分布
- CAVE,GAN, single-step policy roll-out methods
- 缺点:
- 使用隐变量对建模意图的可解释性差;
- 需要测试时间抽样来评估概率查询
- 我们的工作
- 观察;
- 在中等时间步长的预测中,目标未来的模式可以通过一组目标状态来有效的捕获.
- 这些目标不仅基于可解释的物理实体(例如位置),而且还与意图密切相关(例如变道或右转)。我们推测目标的空间可以在场景中离散——允许确定性模型并行生成不同的目标——然后细化到更精确。
- 方法
- (1)目标预测在给定的场景背景下估计候选目标的分布;(2)目标条件运动估计预测每个目标的轨迹状态序列;(3)评分和选择估计每个预测轨迹的可能性,考虑到所有其他预测轨迹的上下文
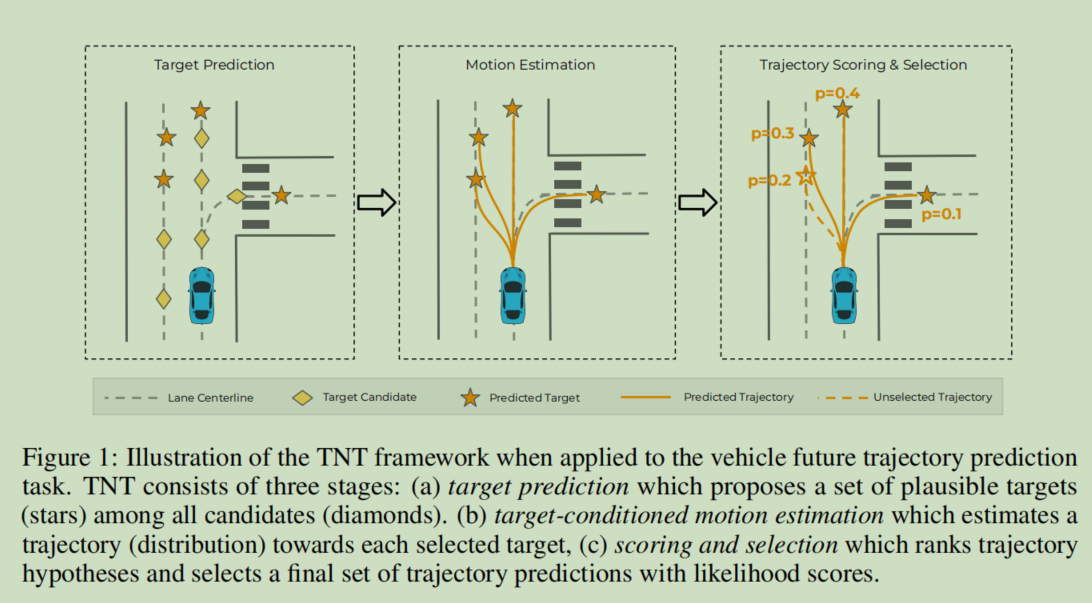
- 观察;
- 问题陈述(与已存在的方法合并为一段)
- 笔记:交通参与者的未来运动是多模态的,作者认为可以先通过对未来有限个目标位置进行建模,先判断意图,再通过交互建模轨迹集合,选出最可能的轨迹。这是比较符合直观的做法。
-
2 相关工作
(引用别人文献说明一些方法)- 要解决的问题:建模多模态的未来分布
- 方法:
- 将未来模式隐式地建模为隐变量
- 目的:捕获智能体的潜在意图
- 方法:CAVE,flow-based generative models,SocialGAN
- 缺点:无法融入专家知识;需要在隐空间随机抽样,以获得运行时的潜在分布,不符合实际部署
- 将轨迹预测任务分解为子任务,希望每个子任务更易于解决,并提供可解释的中间结果
- 基于规划的行人预测:
- 首先估计了目的地的贝叶斯后验分布,然后使用逆强化学习(IRL)来规划轨迹
- Rehder等人[29]引入了定义为短期目标的概念,并将问题分解为目标分布估计和目标导向规划
- 目标被定义为高斯潜在变量的混合
- 基于规划的行人预测:
- 将输出空间离散为意图[32]或具有锚点[33,34]的工作
- IntentNet
- 手动为自动驾驶车辆定义了几种常见的运动类别,如左转和车道的变化,并为每个意图学习了一个单独的运动预测器。这种手动分类依赖于任务和数据集,可能过于粗糙,无法捕获类别内的多模态。
- MultiPath [33] and CoverNet
- 将轨迹量化为锚,其中轨迹预测任务被重新表述为锚点选择和偏移回归。锚点要么预先聚类成一个固定的先验[33],要么基于运动学启发式[34]动态获得。
- IntentNet
- 我们的
- 与锚定轨迹不同,TNT中的目标的维度要低得多,可以通过均匀采样或基于专家知识(如HD地图)很容易地离散。因此,它们可以更可靠地估计
- 将未来模式隐式地建模为隐变量
-
3 问题公式
- 给定历史状态
, 智能体场景交互
,目标是求未来轨迹状态
, 简介表示捕获的目标为
- 目标概率可以分为两部分:(1)智能体目标意图的不确定性,(2)控制(路径的)不确定性。以目标空间和位置两个条件组成的概率,即在已知历史条件下选择该目标空间概率和指定了目标空间,选择该轨迹的联合概率,空间是可以连续积分的,路径采用轨迹单峰分布设计。
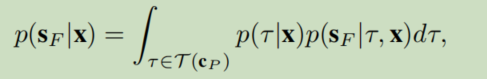
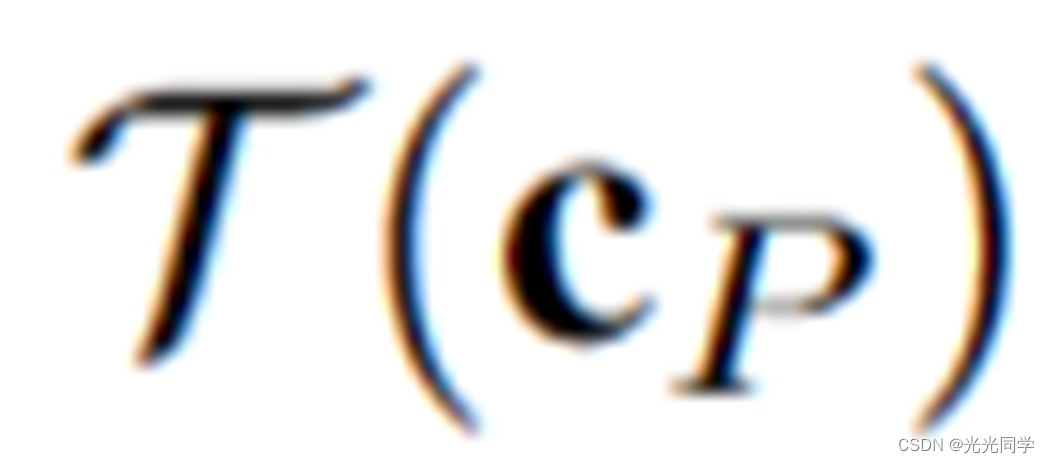 表示根据观察的上下文
表示根据观察的上下文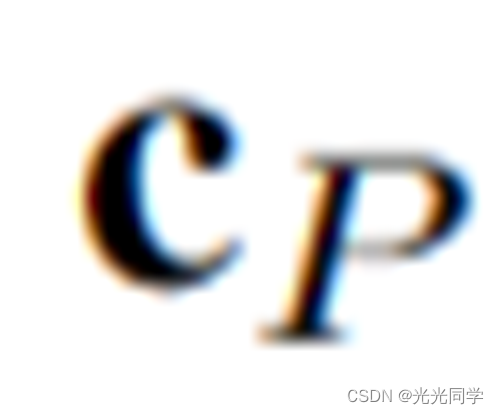 产生的合理的位置分布。
产生的合理的位置分布。- 目标变成了合理的设计目标空间位置,实际操作中可以通过采样离散目标空间,然后很容易的就可以加入专家知识,
- 总的来说,第一阶段基于观察到的上下文,用一组离散的目标状态 对意图进行不确定性建模,输出目标分布:
;
- 第二阶段条件概率,单峰分布,前两个产生的概率:
-
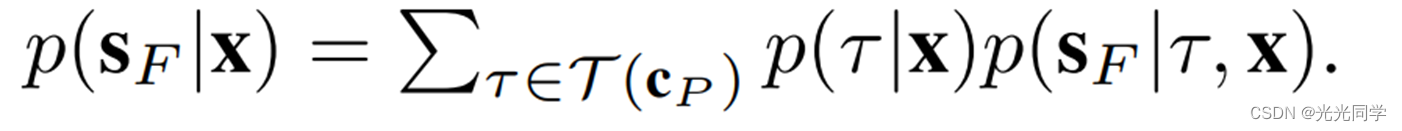
- 第三阶段:设计评分函数
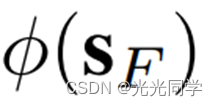 来选择最佳的预测集
来选择最佳的预测集
-
- 给定历史状态
-
4 整体模型
-
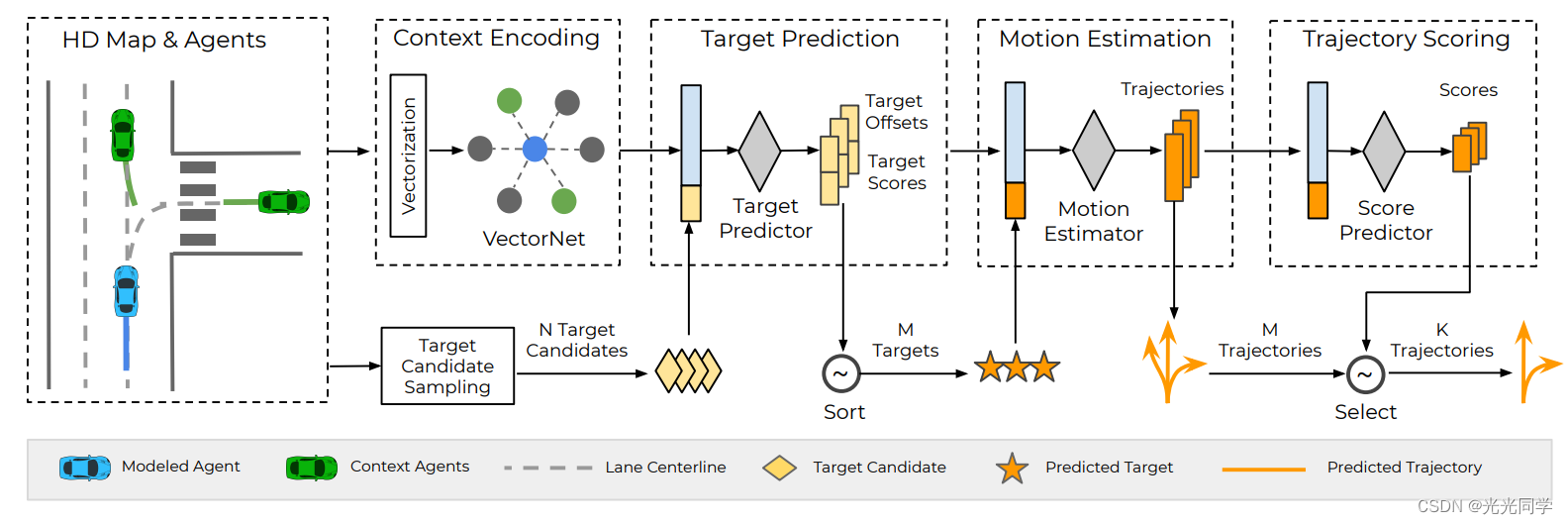
这张是模型的概况图。首先编码上下文信息作为输入,后面是模型的三个核心部分:(1)目标预测提出几个最初的M个目标集合;(2)目标条件运动估计评估了一条轨迹;(3)计分和选择对轨迹假设进行排序并输出最终的一组 K 个预测轨迹。
4.1 场景信息编码
作为预测的第一步,场景信息编码主要是捕捉智能体之间以及智能体和场景信息之间的交互。TNT 可以使任意适用的场景编码器。
当HD地图可以使用时,可以使用作为先进的VectorNet进行编码。其中折现用来抽抽象高清地图的元素cp(车道线、交通标志)以及智能体的轨迹sp;然后使用子图网路去编码每一个折线,其中包含可变数量的向量;然后使用全局图对折线之间的交互进行建模。输出是全局上下文每个建模智能体的特征 x。
如果场景上下文仅以自上而下的图像形式提供,ConvNet 用作上下文编码器
4.2 轨迹预测
在公式(1)中,目标定义为在时间步长T时,智能体可能的位置(x,y)。在目标预测阶段,目的是提出智能体未来目标分布
.我们通过一组具有连续偏移的 N 个离散量化位置对潜在的未来目标进行建模,
![]() ,然后可以通过离散连续分解对目标上的分布进行建模:
,然后可以通过离散连续分解对目标上的分布进行建模:
![]()
![]() 是位置选择的离散分布
是位置选择的离散分布,项 N (·|ν(·)) 表示广义正态分布,我们选择 Huber 作为距离函数。 我们将平均值表示为 ν(·) 并假设单位方差。可训练函数 f(·) 和 ν(·) 使用 2 层多层感知器 (MLP) 实现,目标坐标
和场景上下文特征 x 作为输入。 他们预测目标位置及其最可能的偏移量的离散分布。 这个阶段训练的损失函数由下式给出
![]()
其中 是交叉熵,
是 Huber 损失; u 是最接近真值位置的目标,
是 u 与真值的空间偏移量。
离散目标空间的选择在不同的应用程序中是灵活的,如图 3 所示。在车辆轨迹预测问题中,我们从高清地图中统一采样车道中心线上的点,并将它们用作目标候选(标记为黄色黑桃), 假设车辆永远不会远离车道; 对于行人,我们在智能体周围生成一个虚拟网格,并使用网格点作为目标候选。 对于每个候选目标,TNT 目标预测器产生一个元组 (π, ∆x, ∆y);回归的目标被标记为橙色星。 与直接回归相比,将未来建模为一组离散目标的最突出优势是它不会受到模式平均的影响,而模式平均是阻碍多模态预测的主要因素。
在实践中,我们对大量目标候选者进行过采样作为此阶段的输入,例如 N = 1000,以增加潜在未来位置的覆盖范围; 然后保留较少数量的它们作为输出,例如 top M = 50,用于进一步处理,因为 M 的一个好的选择有助于在目标召回和模型效率之间取得平衡。
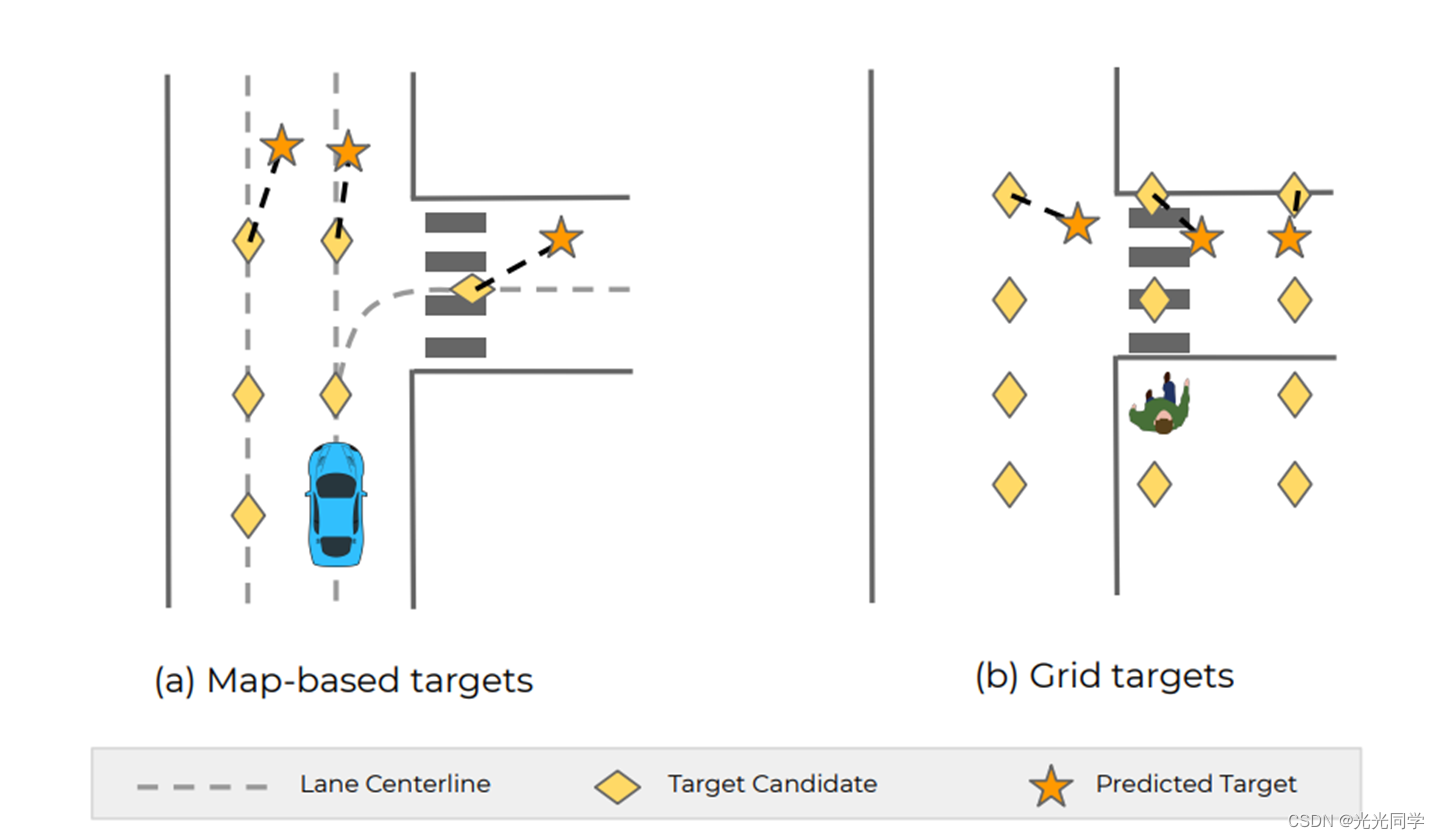
图 3:TNT 支持灵活选择目标。 车辆目标候选点从车道中心线采样。 行人目标候选点从以行人为中心的虚拟网格中采样。
4.3 目标条件运动估计
在第二阶段,我们再次使用广义正态分布对给定目标的轨迹可能性建模为:
这做了两个假设。 首先,未来的时间步长是条件独立的,这使得我们的模型通过避免顺序预测来提高计算效率,就像在 [21, 31, 33, 34] 中所做的那样。 其次,我们正在做出强有力但合理的假设,即在给定目标的情况下,轨迹的分布是单峰的(正态的)。 对于短期而言,这当然是正确的; 对于更长的时间范围,可以在(中间)目标预测和运动估计之间进行迭代,以使假设仍然成立。
此阶段使用 2 层 MLP 实现。 它以上下文特征 x 和目标位置 τ作为输入,并为每个目标输出一个最可能的未来轨迹
。 由于它以第一阶段的预测目标为条件,为了实现平滑的学习过程,我们在训练时通过提供地面实况位置
作为目标。 这个阶段的损失项是预测状态
和真实状态
之间的距离:
![]()
其中 被实现为每步坐标偏移上的 Huber 损失。
4.4 轨迹评分与选择
我们的最后阶段估计完整的未来轨迹 的可能性。 这与第二阶段不同,第二阶段随着时间步长和目标分解,也不同于第一阶段,它只知道目标,但没有完整的轨迹——例如,一个目标可能被估计为具有很高的可能性,但有一条完整的轨迹可以到达 该目标可能不会。
我们使用最大熵模型对第二阶段的所有 M 个轨迹进行评分:
![]()
其中 g(·) 被建模为 2 层 MLP。 这个阶段训练的损失项是预测分数和ground truth分数之间的交叉熵,
![]()
其中每个预测轨迹的地面实况分数由其到地面实况轨迹的距离定义:
![]() 其中 D(·) 以米为单位,α 为温度。
其中 D(·) 以米为单位,α 为温度。
距离度量定义为:![]()
为了从评分的 M 轨迹中获得最终的一小组 K 预测轨迹,我们实施了一种轨迹选择算法来拒绝接近重复的轨迹。 我们先按照分数降序对轨迹进行排序,然后贪婪地挑选它们; 如果一个轨迹距离所有选定的轨迹足够远,我们也选择它,否则排除它。 此处使用的距离度量与评分过程相同。 这个过程的灵感来自于通常用于计算机视觉问题的非极大值抑制算法,例如目标检测。
4.5 训练和推理细节
上述 TNT 公式产生完全监督的端到端训练,具有总损失函数:
![]()
![]()
在推理时,TNT 的工作方式如下:(1)编码上下文; (2) 采样N个候选目标作为目标预测器的输入,取前M个目标估计为; (3) 从运动估计模型
中获取 M 个目标中每个目标的 MAP 轨迹; (4) 通过
对 M 条轨迹进行评分,并选择最终的 K 条轨迹集。
- 实验
上下文编码:作者用一组折线和向量来表示地图元素和轨迹。每个向量表示为[ps, pe, f, idp],其中ps和pe是向量的起点和终点,f是特征向量,可以包含像车道状态这样的特征类型,idp是向量所属的折线索引。将向量坐标归一化,最后观察到的时间步以智能体的位置为中心。向量化后,VectorNet 用于对建模智能体的上下文进行编码,其输出特征将被 TNT 消耗。 一个例外是斯坦福无人机数据集,它不提供地图数据,因此我们使用标准的 ResNet-50 [38] ConvNet 对鸟瞰图像进行编码以进行上下文编码。
目标候选抽样: 对于车辆轨迹预测,我们从车道中心线(Argoverse 数据集)或车道边界(INTERACTION 数据集)中采样点作为目标候选。 每米至少采样一个点。 对于行人轨迹预测,由于行人具有更大的移动灵活性,我们在智能体周围构建了一个矩形 2D 网格(例如 10m × 10m),每个单元格的中心(例如 1m × 1m)是一个候选目标。
模型细节:TNT 的所有三个阶段的模型架构都是 2 层 MLP,隐藏单元的数量设置为 64。我们将 ψ(sF) 中的温度 α 设置为 0.01。 损失权重为 λ1 = 0.1, λ2 = 1.0, λ3 = 0.1。 TNT 使用 Adam 优化器进行端到端训练,大约 50 个 epoch [39]。 学习率设置为 0.001,批量大小为 128。
指标: 我们采用广泛使用的平均位移误差 (ADE) 和最终位移误差 (FDE)。 为了评估一组 K 个预测轨迹的 ADE 和 FDE,我们使用 minADEK 和 minFDEK。 除了以像素为单位的斯坦福无人机数据集外,位移均以米为单位。 在 Argoverse 上,我们还报告了未命中率 (MR),它根据 FDE 衡量没有任何预测位于地面实况 2 米范围内的场景的比率。
5.3 消融研究
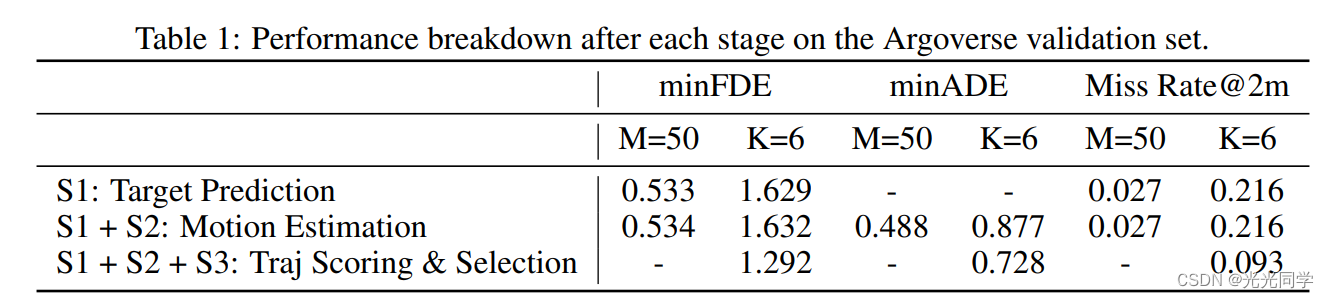
按阶段划分的性能。 我们通过跟踪 Argoverse 数据集上的性能来讨论 TNT 每个阶段的功效,如表 1 所示。我们可以看到 S1 在 M = 50 时实现了良好的目标召回率,如 minFDE 和 Miss Rate 所示; S2 进一步生成由 minADE 度量评估的轨迹。 S1 和 S2 之间的 minFDE 几乎相同,这证实了条件运动估计能够生成在条件目标处结束的轨迹这一事实。 最后,S3 将预测数量缩小到 K = 6,与 M = 50 相比没有太大损失。
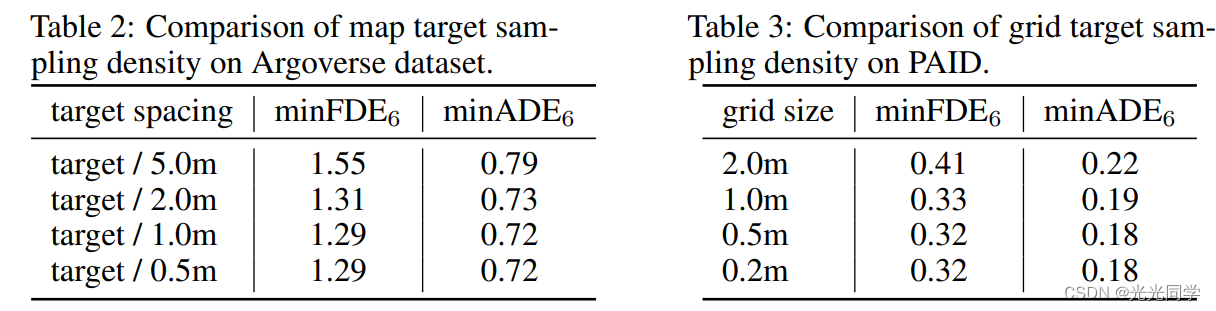
目标候选抽样: 目标候选采样密度对 TNT 的性能有影响,分别如 Argoverse 上的表 2 和 PAID 上的表 3 所示。 对于 Argoverse 中的车辆,我们从车道中采样目标,测量为沿折线的目标间距。 对于 PAID 中的行人,由于他们有更多的行动自由,我们凭经验发现网格目标的性能比基于地图的目标好得多,并且只报告网格目标结果。 我们观察到更密集的目标会在饱和点之前带来更好的性能。
- 讨论
- 附录
这篇关于【单目标轨迹预测】TNT: Target-driveN Trajectory Prediction(翻译+笔记)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









