本文主要是介绍决策树算法:随机森林民主算法【02/2】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
决策树民主:随机森林算法
一、介绍:
记住您在阅读亚马逊上的所有评论后进行的最后一次购买,或者在查看 IMDb 评级后您观看的以前的电影。人类是社会动物,他人的意见和行为自然会影响我们。我们的决定在很大程度上取决于“群体智慧”的概念,即群体的集体决策和选择可以平均个人的偏见和错误,并提出更准确的答案。

随机森林算法的工作方式类似,其中最终决策是通过对多个机器学习模型的输出执行多数计数或平均值来做出的。要理解随机森林算法,我们必须熟悉决策树和打包集成学习,因为这两个概念构成了骨干。
二、决策树:
决策树是一种监督学习算法,它使用树状结构根据输入数据做出决策。它将数据划分为分支,并将结果分配给叶节点。
简单来说,决策树是 if-else 语句的广泛集合。在这里,我添加了一个指向我上一篇文章的链接,其中我已经清楚地解释了决策树算法。
三、装袋集成学习:
bagging 代表 引导聚合。它是使用最广泛的集成学习技术之一。集成学习是一种结合多个机器学习模型以创建更准确、更健壮的模型的技术。有许多集成学习技术,例如:
- 装袋
- 提高
- 堆垛
简单来说,bagging 集成学习技术结合了多个机器学习模型的结果,以提高整体性能。
构成Bagging Ensemble Learning技术思想的两个最重要的概念是Bootstrapping和Aggregation。
3.1 引导:
Bootstrapping是机器学习中的一个统计术语,是指将大型数据集随机采样为小子集。此外,每个引导示例用于训练多个模型。
这是减少过度拟合的一种非常有效的方法。此方法提高了整体机器学习模型的准确性和鲁棒性。我们可以通过对行和列或两者进行采样来实现引导,如下所示:
- 使用替换的行采样:在此方法中,从数据集中选择随机行并进行替换,这意味着子数据集中可以多次出现每一行。
- 无保留的行采样: 在此方法中,从数据集中选择随机行而不进行替换,这意味着每行在子数据集中只能出现一次,这意味着子数据集中的所有行都是唯一的。
- 列/特征采样与替换: 在此方法中,从数据集中选择随机列或特征并进行替换,这意味着每个列可以在子数据集中多次出现。
- 无保留的列/特征采样: 在此方法中,从数据集中选择随机列或特征而不进行替换,这意味着每列在子数据集中只能出现一次,这意味着子数据集中的所有列都是唯一的。
- 行和列的组合采样: 在此方法中,为子数据集选择随机行和列。
3.2 集合体:
聚合是指袋装集成学习的最后阶段,在该阶段中,我们根据各自袋装集成学习中使用的多个机器学习模型的输出,在分类的情况下执行多数计数,在回归问题的情况下执行平均值。
聚合可提高模型的准确性。通过组合多个数据点,模型可以了解有关数据基础分布的更多信息。
Bagging Ensemble Learning,来源:作者图片
四、什么是随机森林算法?
随机森林是一种监督式机器学习算法,可提高决策树的性能和预测能力。 随机森林中的术语“森林”是指在训练阶段协同工作的决策树的集合。
随机森林算法由Leo Breiman和Adele Cutle给出。
最重要的关键是,如果bagging ensemble learning技术中使用的所有机器学习模型或算法都是决策树,则称为随机森林。
在分类的情况下,它执行多数计数,而在回归中,它计算多个决策树的平均值。

上图显示了数据如何在 n 个决策树之间划分,每个决策树生成不同的结果。我们在分类问题的情况下执行多数计数,在回归的情况下执行平均值。
五、随机森林算法如何工作?
在这里,我将向你们直观地了解随机森林算法在幕后的工作原理,并附上逐步解释。
5.1. 导入数据集:
在这里,我采用一个包含 400 行和五列的数据集,其中三列被选择为输入:“性别”、“年龄”和“估计工资”,而“购买”列设置为输出。
import pandas as pd
df = pd.read_csv('social_network.csv')
df.head()
我对数据集的分类“性别”列执行了一个热编码,并删除了该列的“用户ID”:
df = df.iloc[:, 1:]
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['Gender'] = le.fit_transform(df['Gender'])
df.head()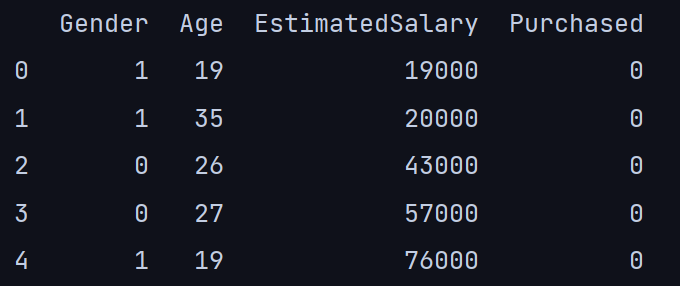
2. 将整个数据集拆分为训练和测试子数据集:
在此步骤中,我将整个数据集拆分为训练集和测试集;我没有使用 sklearn 模型选择,而是手动执行了它。我在 .sample 方法的帮助下通过传递 replace = False 选择了随机的唯一行。
# train dataset:
df_train = df.sample(350, replace=False)
# random 350 rows will be selected
# and all rows will be unique because, replace = False# test dataset:
df_test = df.sample(50, replace=False)
x_test = df_test.iloc[:, :3]
y_test = df_test.iloc[:, 3]3. 引导:
正如我所提到的,在随机森林算法中,相同的数据集被划分为不同的子数据集,每个子数据集被馈送到不同的决策树。基于这个概念,我编写了一个引导函数,将整个数据集拆分为不同行的随机子集。
我通过将整个数据集划分为多个子集来执行引导。具体来说,“行采样与替换”。
# function to randomly select specified number of rows from the training dataset:
from sklearn.preprocessing import StandardScaler
def random_rows(df, n):df = df.sample(n, replace=True) # replace=True, there will be duplicate rows sc = StandardScaler()x_train = df.iloc[:, :3].valuesx_train = sc.fit_transform(x_train)y_train = df.iloc[:, 3]return x_train, y_trainx_train, y_train = random_rows(df_train, 115)
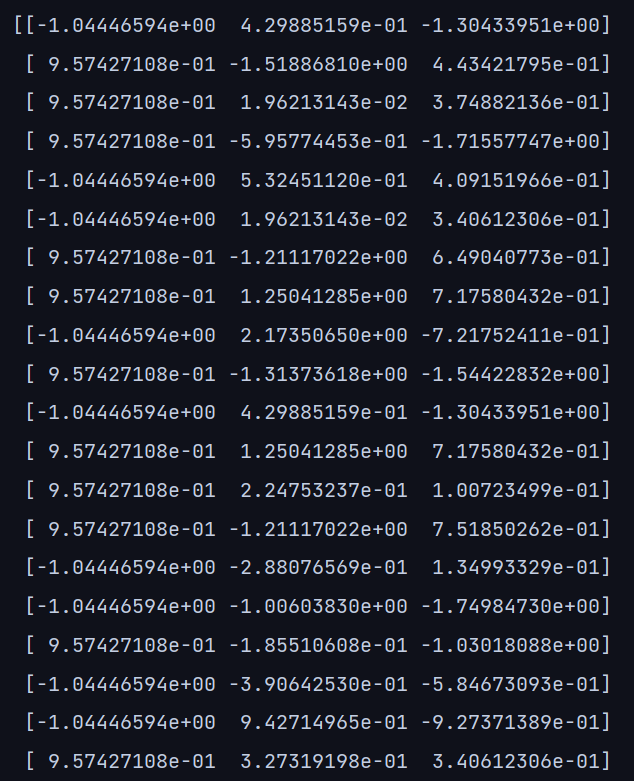
# random 115, rows will be selected from the training datasetprint(x_train)
print(y_train)输出:x_train
output: y_train
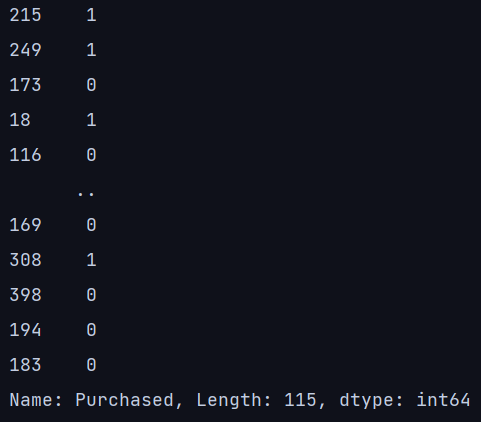
从行索引号中我们可以清楚地看到,所有行都是随机选择的子集。
4. 构建多个决策树模型:
在这里,我为三种决策树算法创建了三个子集;所有三个子数据集都将具有可替换的随机行,这意味着同一行可以出现多次。
x1, y1 = random_rows(df_train, 115)
x2, y2 = random_rows(df_train, 115)
x3, y3 = random_rows(df_train, 115)Three decision tree models are as follows:
from skleran.tree import DecisionTreeClassifier
# decision tree model 1:
dt1 = DecisionTreeClassifier()
dt1.fit(x1, y1)# decision tree model 2:
dt2 = DecisionTreeClassifier()
dt2.fit(x2, y2)# decision tree model 3:
dt3 = DecisionTreeClassifier()
dt3.fit(x3, y3)5. 测试阶段:
在最后阶段,我将输入值从测试数据集传递到所有决策树并执行多数计数。
print(x_test.head())
print(y_test.head())输出:x_test
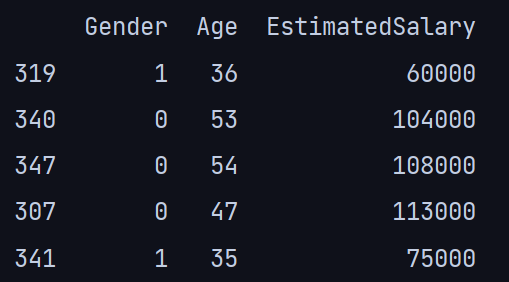
输出:y_test

xs = sc.fit_transform(x_test)
test = xs[3,:].reshape(1, 3)
print("Result of decision tree 1: ", dt1.predict(test))
print("Result of decision tree 2: ", dt2.predict(test))
print("Result of decision tree 3: ", dt3.predict(test))所有决策树的上述结果显示多数计数为 [1]。因此,最终值为 [1]。为了证明结果,我们可以看到测试数据集中行索引 307 的值为 [1],因此进行了验证。
六、使用 sklearn 库实现随机森林算法:
# imported the required libraries:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import seaborn as sns# imported the dataset:
df = pd.read_csv('social_network.csv')
df = df.iloc[:, 1:]# performed One Hot Encoding on the gender column:
le = LabelEncoder()
df['Gender'] = le.fit_transform(df['Gender'])# split the dataset into train and test:
x = df.iloc[:, 0:3].values
y = df.iloc[:, 3]
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=42, test_size=0.2)# decision tree algorithm model:
dt = DecisionTreeClassifier()
dt.fit(x_train, y_train)# random forest model:
rf = RandomForestClassifier(n_estimators=300)
rf.fit(x_train, y_train)# testing phase for both decision tree and random forest
y_pred1 = dt.predict(x_test)
y_pred2 = rf.predict(x_test)# accuracy score and cofusion matrix of decision tree and random forest:
print("Accuracy Score of decision tree: ", accuracy_score(y_test, y_pred1))
sns.heatmap(confusion_matrix(y_test, y_pred1), annot=True)
plt.title("Confusion Matrix of Decision Tree")
plt.show()print("Accuracy Score of random forest: ", accuracy_score(y_test, y_pred2))
sns.heatmap(confusion_matrix(y_test, y_pred1), annot=True)
plt.title("Confusion Matrix of Random Forest")
plt.show()

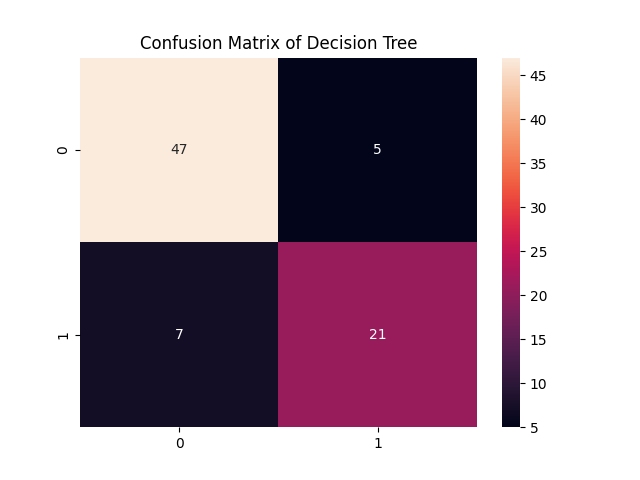
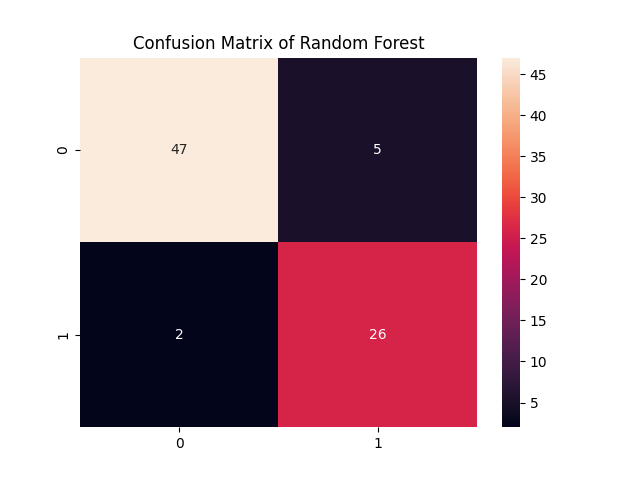
决策树和随机森林的混淆矩阵
从上面的例子中,我们可以看到单个决策树的准确率得分为:85%,而随机森林的准确率得分为:91%,准确率提高了近6%。
七、随机森林算法的优点:
在多个优点中,最重要的两个是:
- 准确性:随机森林是一种非常精确的算法,特别擅长处理具有许多特征的复杂数据集。
- 鲁棒性:随机森林是一种稳健的算法,这意味着它不容易受到数据中的噪声或异常值的影响。因为异常值分布在多个子数据集中。
八、结论:
请记住,我提到了决策树的民主:随机森林,因为随机森林像民主一样运作。在民主国家,具有多数投票规则的政党,同样是随机森林,在分类问题的情况下根据多数票做出最终决定。在这里,我添加了一个指向在乳腺癌数据集上执行的随机森林算法项目的链接。GitHub - mrinmoyxb/Breast-Cancer-Detection-Model: Machine Learning Breast Cancer Detection model performed using Random Forest Algorithm
这篇关于决策树算法:随机森林民主算法【02/2】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








