本文主要是介绍论文阅读[121]使用CAE+XGBoost从荧光光谱中检测和识别饮用水中的有机污染物,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【论文基本信息】 标题:Detection and Identification of Organic Pollutants in
Drinking Water from Fluorescence Spectra Based on Deep Learning Using
Convolutional Autoencoder 标题译名:基于使用卷积自动编码器的深度学习,从荧光光谱中检测和识别饮用水中的有机污染物
期刊与年份:Water 2021(JCR - Q2)
作者机构:浙江大学控制科学与工程学院
原文:https://www.mdpi.com/2073-4441/13/19/2633
一、介绍
- 荧光光谱由于其多重优势,越来越多地被用于检测水处理系统中的污染物。
- 荧光光谱实验的结果以EEM的形式提供。然而,EEM很难直接分析,因为它是高维的。
- 多路方法是典型的EEM降维方法,包括主成分分析(PCA)和平行因子分析(PARAFAC)。
- 尽管它们被广泛使用,但它们有一些局限性。例如,它们提取的特征是线性的,这种线性可能会带来特征信息的损失,从而降低检测精度。
- 近年来,许多学者提出了其他荧光分析方法来弥补这一不足。此外,深度学习在图像识别中的日益成熟,也为实现光谱特征提取提供了新的思路。
- 然而,这些方法几乎没有提到模型在水质背景变化下的适应性。
- 本文介绍一种基于EEM的饮用水中有机污染物检测新方法,该方法适用于在水质背景波动的情况下,低浓度分析物的光谱信号较弱的情况。
- 该方法设计了深度卷积自动编码器(CAE),用于降低EEM的维数并从中提取多层特征。它保证了有机污染物光谱在背景变化下的特征不变性,以及有机污染物光谱非线性特征的泛化自动学习;接着使用XGBoost分类器(一种梯度增强方法)来识别有机污染物。对3种有机污染物进行了测试,以验证上述方法。
二、方法
2.1 模型架构
图1:识别和测量水样中有机污染物的流程图。

2.2 数据预处理
采用三次插值法减少瑞利散射,消除拉曼散射。
2.3 卷积自动编码器
自动编码器是一种典型的自监督学习算法,它分为两部分:编码器和解码器。

编码器将高维输入数据x转换成低维编码表示h;解码器将低维编码h恢复为高维原始输入x。
f:非线性激活函数;W, W’:权重;b, b’:偏置
传统的自动编码器忽略了图像的邻域特征,并且输入层和隐藏层完全连接,引入了太多冗余参数。CAE直接处理二维图像,提取重叠块上的特征,并保留图像的邻域特征。多层CAE叠加形成了一个深层CAE,可用于提取深层光谱特征。
假设卷积层具有H个特征图,第k个特征图的权重矩阵为Wk,偏移量为bk,激活函数为f。使用EEM作为输入x来训练卷积层神经元,以获得第k−th(k=1,2,··,H)特征图: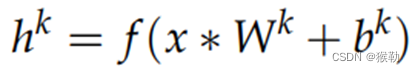
*:二维卷积
然后由解码器获得特征图的重建: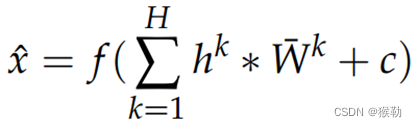
Wk:第k个特征图的权重矩阵Wk的转置;c:偏移量。
卷积自动编码器的目的是最小化重构误差函数E(W,b)的值: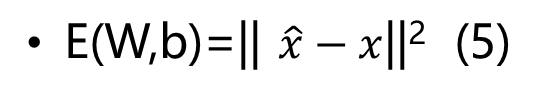
卷积自动编码器的工作过程如下图所示。
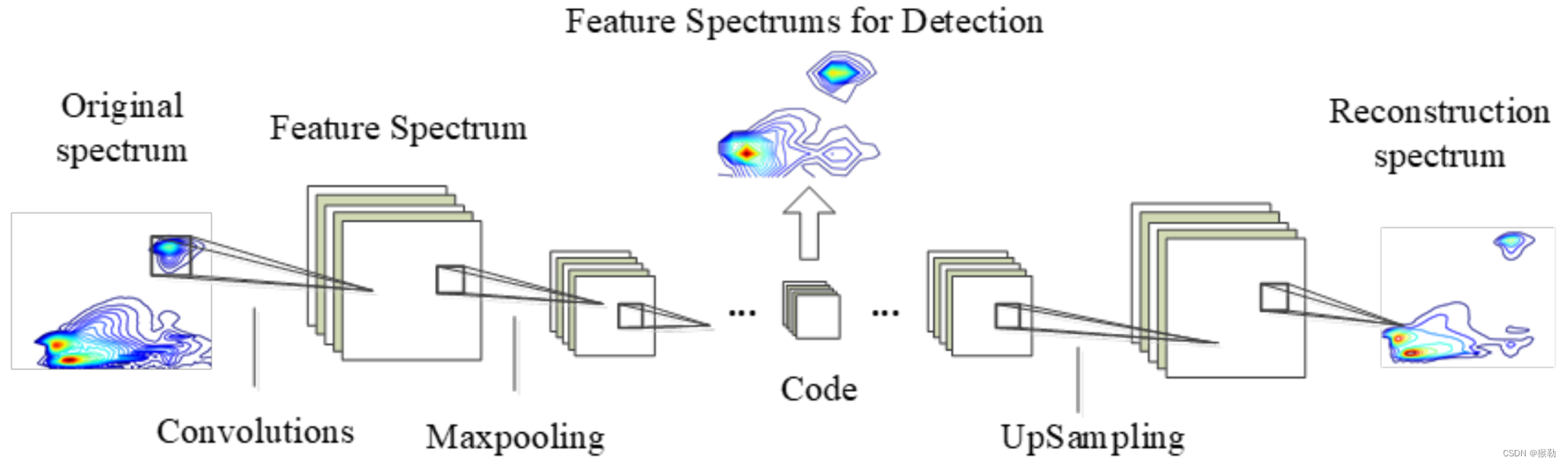
输入:原始光谱。
编码器层:由卷积层、ReLU激活函数(公式9,见下)和最大池化层组成。
每个编码器层都有相应的解码器层。
每个编码器中的最大采样层(即最大池化层)存储特征图上最大值的索引。
解码器中的上采样层使用由相应编码器存储的位置对特征图进行采样,并通过解码器中的卷积层来重建输入的光谱。
本文使用的编码器和解码器网络由3个层组成,每个层的卷积核心大小分别为16、8和6通道。通过卷积层和Sigmoid激活函数(公式10,见下)重建解码器的最终输出。使用随机梯度下降方法一次更新一次单个训练图像的参数。

2.4 XGBoost分类器
XGBoost是2016年提出的一种可扩展的Boost树机器学习方法,基于Gradient boosting。Gradient boosting是一种基于迭代累积的决策树算法,它构建一组弱决策树,并将多个决策树的结果累积为最终预测输出。
XGBoost的目标函数:J(Θ)=L(Θ)+Ω(Θ) (11)
Θ:模型训练参数。L:损失函数(均方误差或交叉熵)Ω:正则化术语(term),用于在模型复杂性和准确性之间取得平衡。
由于基础分类器是决策树,因此模型输出为K个回归树fk的集合F的投票或平均值: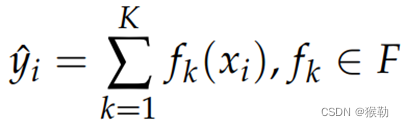
假设有n个训练样本,在第t次迭代后,目标函数转化为: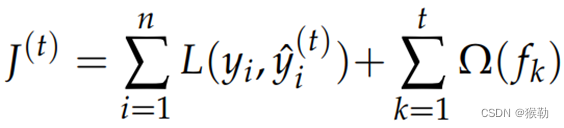
三、结果与讨论
3.1 荧光与样本描述
使用日立F-4600荧光分光光度计进行所有荧光测量。
使用饮用水中经常检测到的3种有机污染物作为测试化合物:苯酚、罗丹明B和水杨酸。
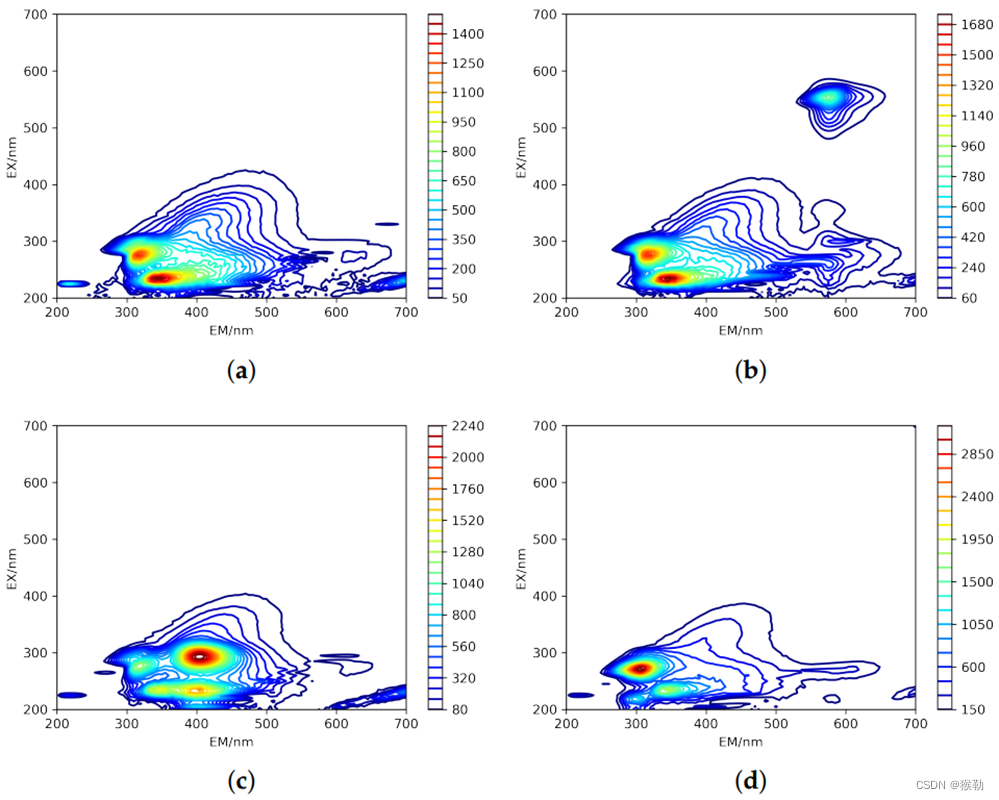
图3:4个样品在预处理后的光谱(饮用水、罗丹明B、水杨酸、苯酚,溶液浓度为20µg/L)。从图中可以读出,罗丹明B的特征峰为545–555/570–580nm,水杨酸的特征峰为290–300/400–410nm。苯酚的特征峰为270–280/305–315,在饮用水的一个特征峰(260–290/280–320)之内。
3.2 基于CAE的光谱特征提取结果
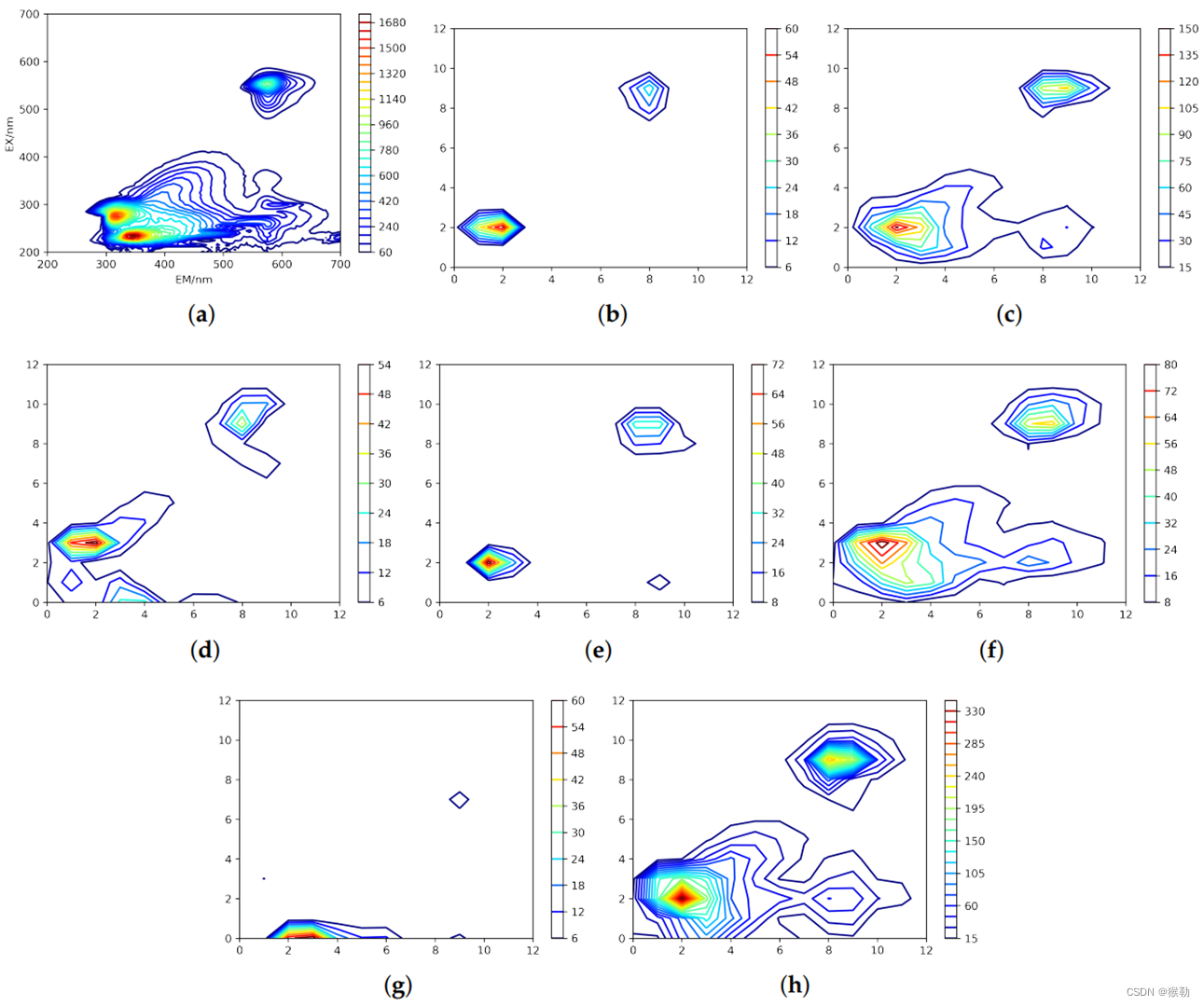
输入100×100的光谱,提取特征,得到特征光谱。它是一个6通道特征图,每个通道的尺寸为13×13。
图4:(a)同图3(b),浓度为20µg/L的罗丹明B的光谱。(b)–(g)是6个通道的特征图,(h)是(b)–(g)的叠加结果。结合(a)和图(b)–(h),可以看出CAE在EEM中同时寻找高贡献(点)和纹理特征。
3.3 基于XGBoost的定性识别结果
将浓度高于10µg/L的分析物样品定义为高浓度样品,浓度等于或低于10µg/L的定义为低浓度样品。
3.3.1 饮用水中高浓度有机污染物的检测
表1:高浓度有机污染物检测结果对比,其中RhB代表罗丹明B,SA代表水杨酸。召回率均为100%,说明3种方法都可以正确识别饮用水中高浓度的3种有机物。

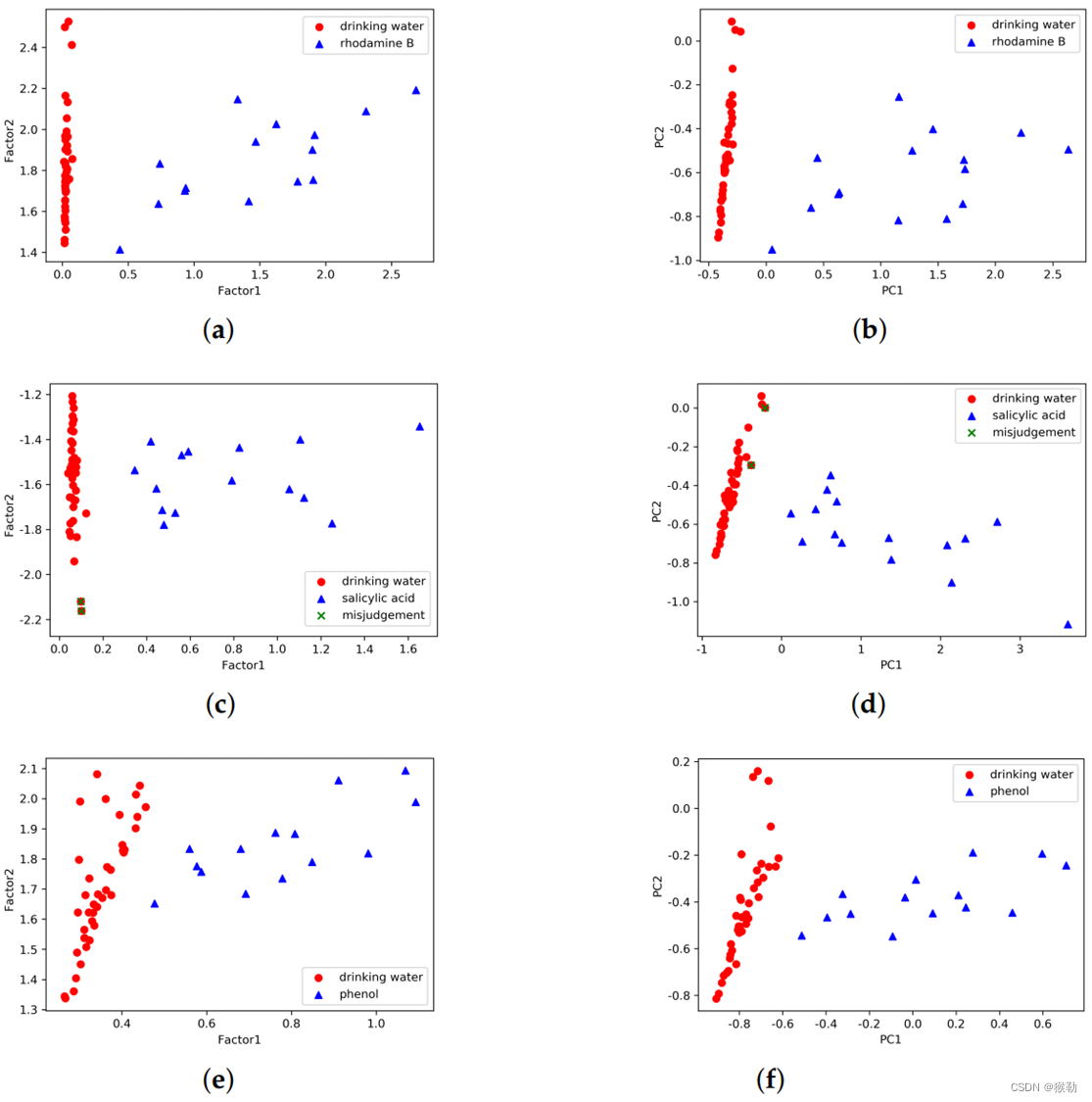
图5:使用多路分解方法得到的主要特征向量。从(c)(d)可以看出,一些饮用水样本可能会被误判为含有水杨酸,从而导致假阳性。
| 有机物\方法 | PARAFAC | PCA |
|---|---|---|
| 罗丹明B | (a) | (b) |
| 水杨酸 | © | (d) |
| 苯酚 | (e) | (f) |
3.3.2 饮用水中低浓度有机污染物的检测
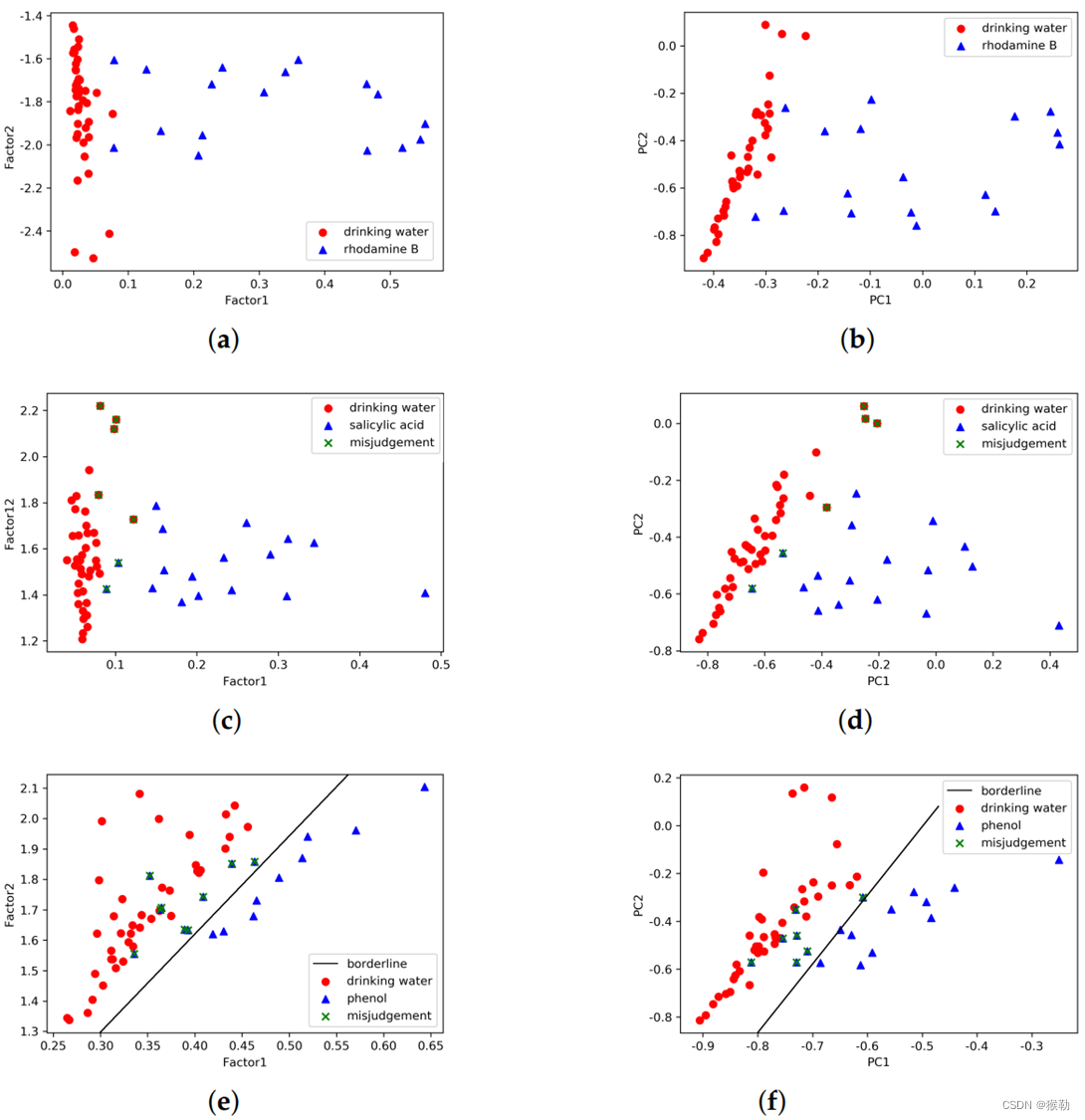
表2:低浓度有机污染物检测结果对比。

图7:使用多种分解方法鉴定低浓度测试样品。对于水杨酸和苯酚,存在假阳性。
| 有机物\方法 | PARAFAC | PCA |
|---|---|---|
| 罗丹明B | (a) | (b) |
| 水杨酸 | © | (d) |
| 苯酚 | (e) | (f) |
如下图所示,从上下两行的对比可以看出,训练样本的分类边界与测试样本有着显著差异。造成这种结果的主要原因是:多路方法只提取光谱的线性特征,对背景水质的变化不敏感。
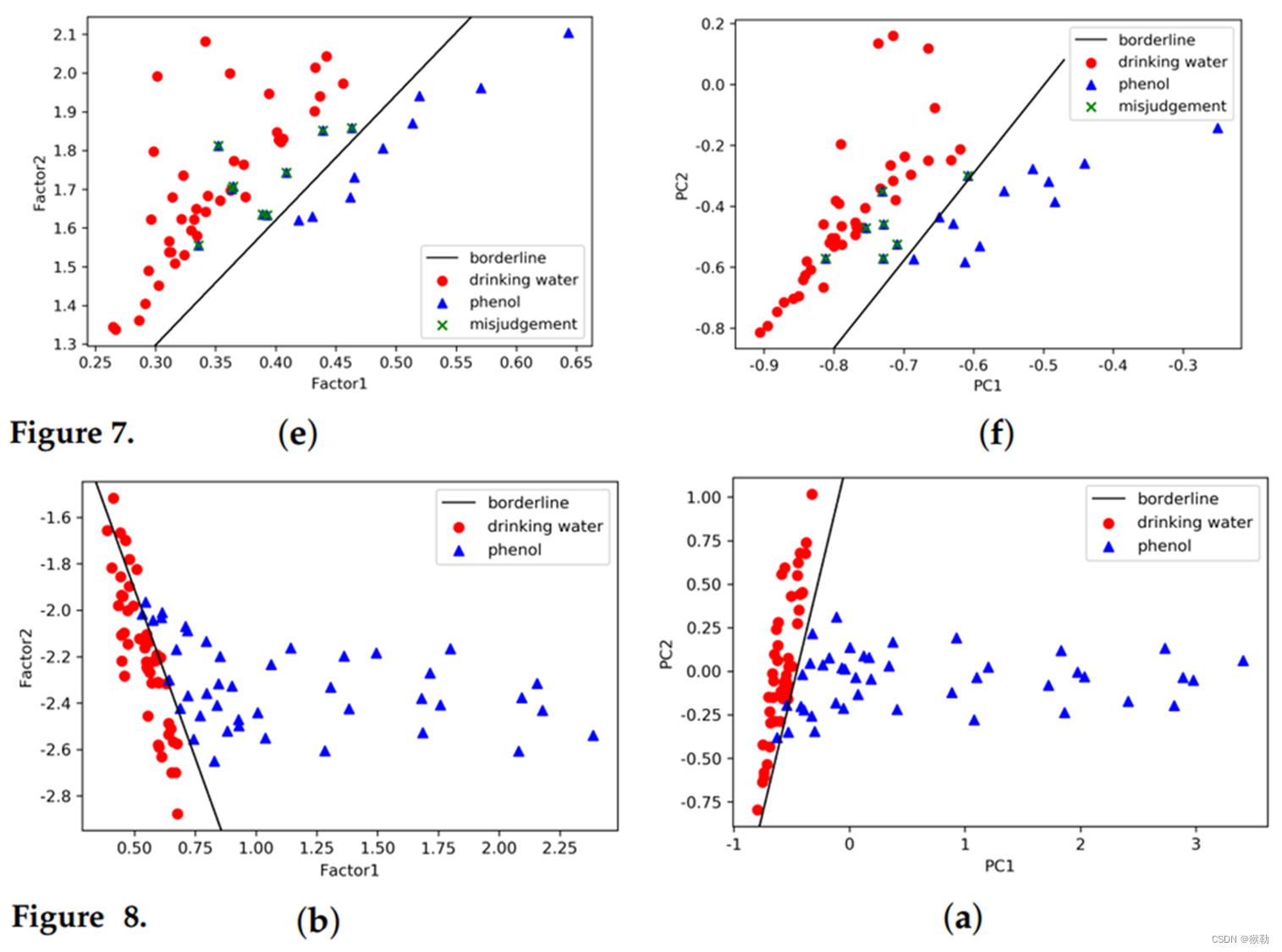
图9:通道4(浓度为4µg/L)的特征光谱。其中a为测试样本,b为饮用水,c为训练样本。a与c的相似度非常高,说明了CAE的有效性。
3.3.3 饮用水背景波动的影响
- 由于受到水处理厂的活动和运输过程中物质的变化的影响,饮用水的质量经常出现波动。
- 在3个月的时间内,以均匀的时间间隔对饮用水进行采样,记录荧光光谱。
图10:其中4个样品的荧光光谱。水质在样品1和2之间以及样品3和4之间仅略有波动,但是在样品2和样品3之间的水质变化剧烈。

接下来,将3个月内采集的200个饮用水样本添加到先前的测试样本中,进行分析。
表3:将饮用水视为污染物的误报率。CAE的误报率均为0。

表4:将污染物视为正常水样的误报率。CAE对苯酚的误报率最低。

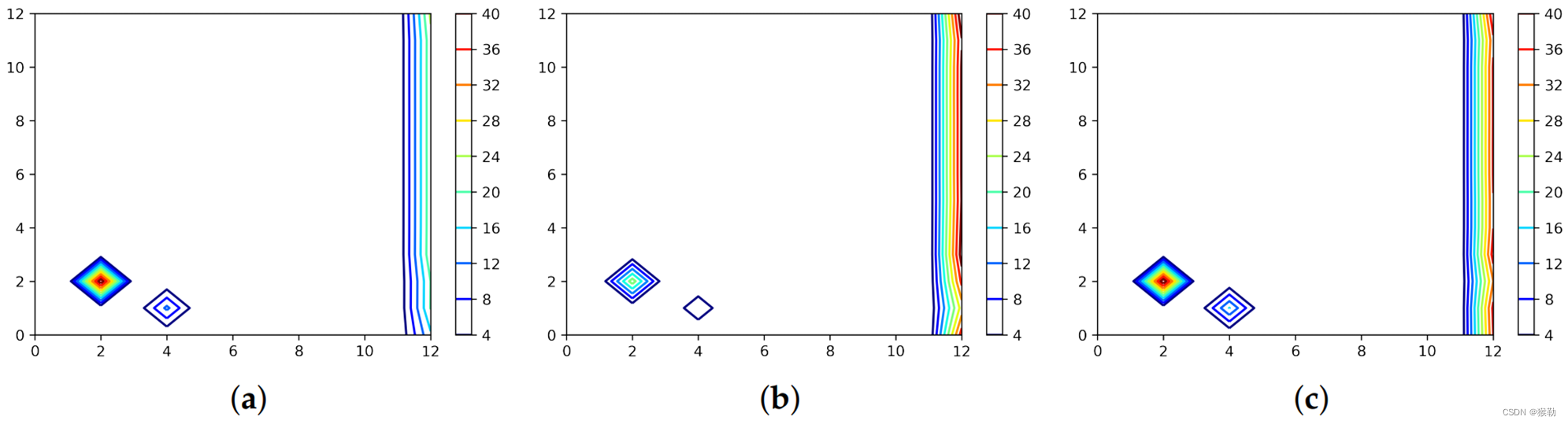
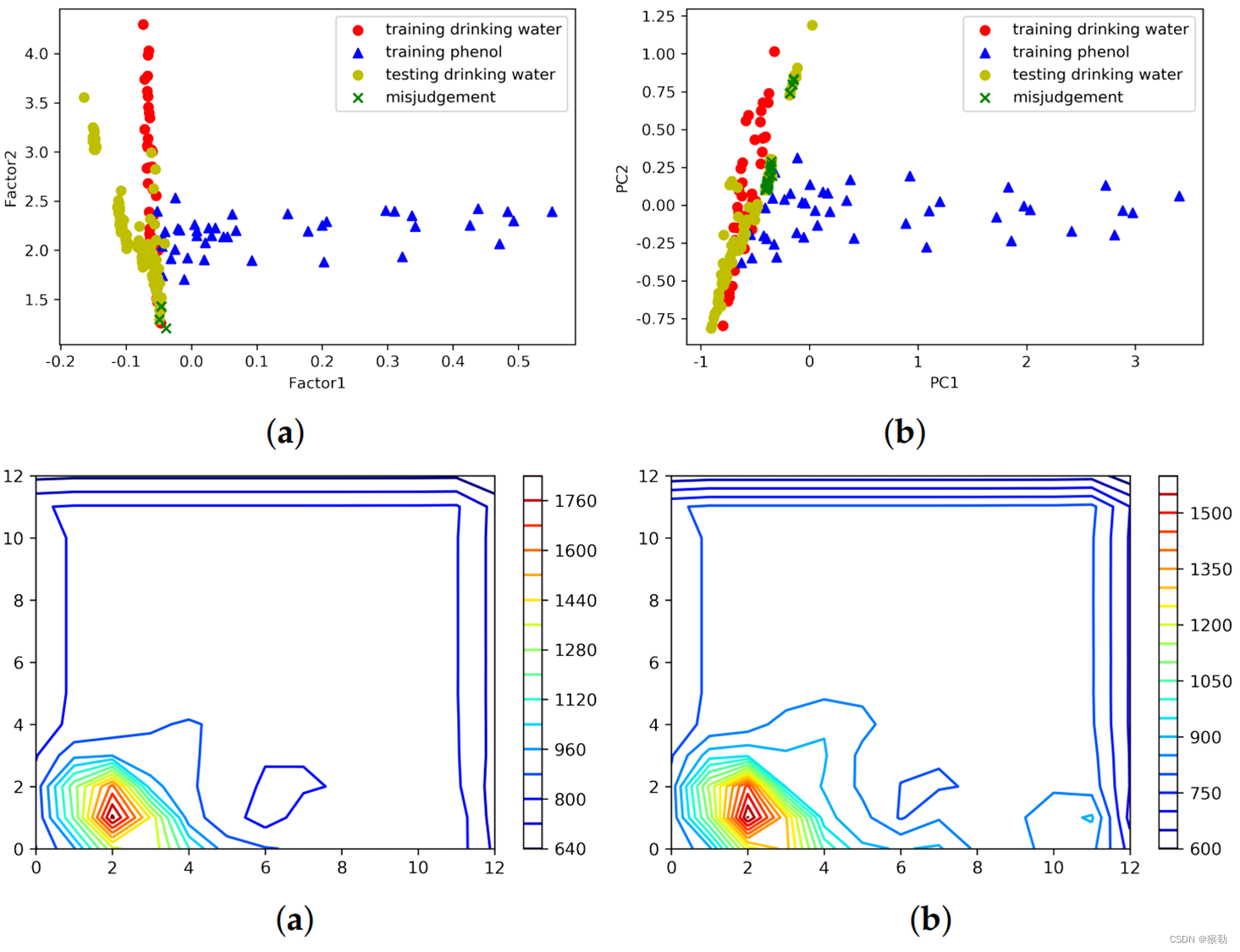
通过查看三种方法在训练和设置样本中提取的特征,进一步研究了原因,如下图所示。
上排:将饮用水误报为苯酚,PARAFAC的误报率达到2%,而PCA的误报率达到14%。
下排:训练集和测试集中饮用水的特征谱。
四、结论
针对饮用水中有机污染物的特征进行分类的问题,本文提出了CAE+XGBoost的新方法,该方法优于传统方法。传统方法在污染物浓度较低时的识别性能较差,且更容易受到干扰。由于CAE可以获取多层卷积特征的并减少信息损失,因此它能够从光谱中收集高贡献(点)和纹理特征,从而获得更好的污染物识别性能。
随着在线光谱仪的快速发展和在线监测站点的快速增加,本文的新方法可以在在线监测和饮用水污染预警系统中得到应用。
这篇关于论文阅读[121]使用CAE+XGBoost从荧光光谱中检测和识别饮用水中的有机污染物的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





