本文主要是介绍CDH Hive Metastore canary,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
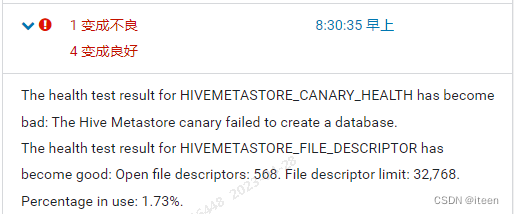
现象:CDH平台突然报错,报错信息为:The Hive Metastore canary failed to create a database
排查一下两点都未发现问题:
- 检查hiveServer2日志(hadoop-cmf-hive-HIVEMETASTORE.log.out)无异常
- 检查元数据依赖的数据库(我安装是mysql),无异常发现
于是在网上搜索,发现很有可能是sentry和hive间通信出现问题,
看了sentry日志
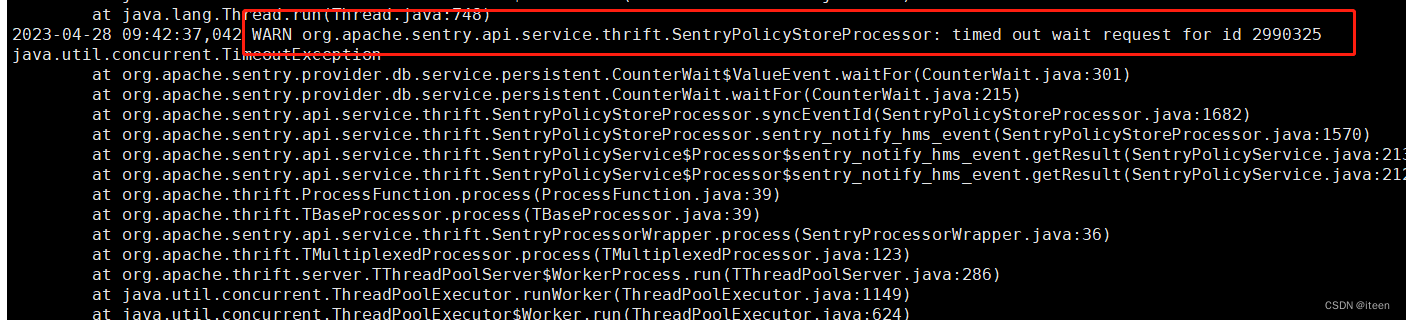
2023-04-28 09:40:57,069 WARN org.apache.sentry.api.service.thrift.SentryPolicyStoreProcessor: timed out wait request for id 2990308
java.util.concurrent.TimeoutException
at org.apache.sentry.provider.db.service.persistent.CounterWait$ValueEvent.waitFor(CounterWait.java:301)
at org.apache.sentry.provider.db.service.persistent.CounterWait.waitFor(CounterWait.java:215)
at org.apache.sentry.api.service.thrift.SentryPolicyStoreProcessor.syncEventId(SentryPolicyStoreProcessor.java:1682)
at org.apache.sentry.api.service.thrift.SentryPolicyStoreProcessor.sentry_notify_hms_event(SentryPolicyStoreProcessor.java:1561)
at org.apache.sentry.api.service.thrift.SentryPolicyService$Processor$sentry_notify_hms_event.getResult(SentryPolicyService.java:2137)
at org.apache.sentry.api.service.thrift.SentryPolicyService$Processor$sentry_notify_hms_event.getResult(SentryPolicyService.java:2122)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.sentry.api.service.thrift.SentryProcessorWrapper.process(SentryProcessorWrapper.java:36)
at org.apache.thrift.TMultiplexedProcessor.process(TMultiplexedProcessor.java:123)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
二、原因分析
HMS 会实时向 Sentry 同步 Notifications 请求,当需要大批同步消息需要处理,后台线程处理不过来,消息压滞就会出现这个异常。这个异常不影响集群正常使用,只是会导致create, drop 等操作慢,需要等待 200s,等待的目的也是为了追上最新的 id。
三、解决措施/建议
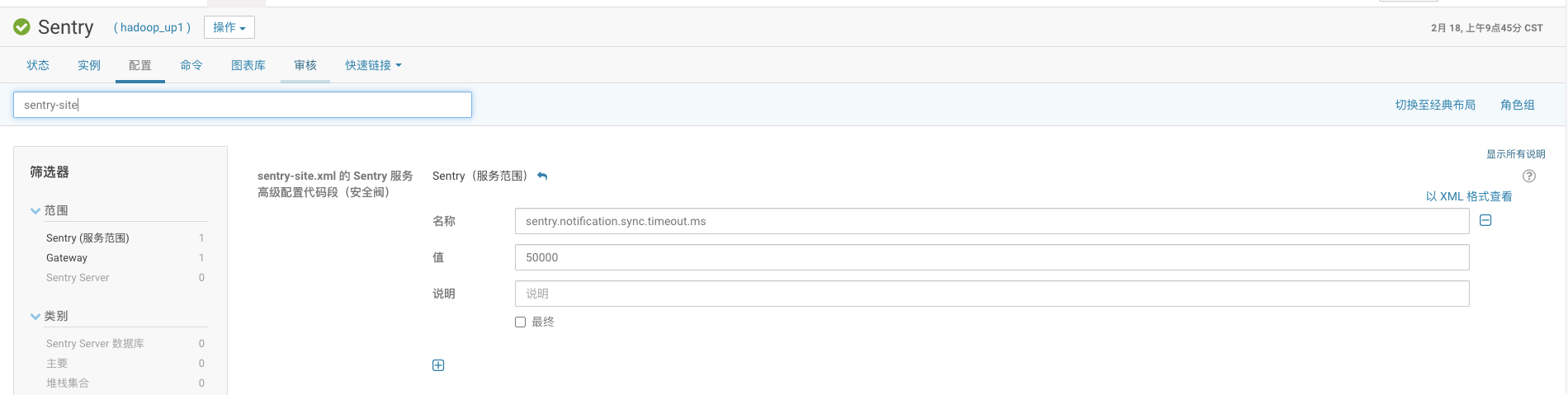
1、适当调小 sentry.notification.sync.timeout.ms 参数
该参数默认是 200s,调小该参数,可适当减小 create/drop/alter 等操作的等待时间,消息积压不多的情况可以选择这种方式让 sentry 自行消费处理掉。
Cloudera 修改 Sentry 服务的参数配置:
修改参数后重启 Sentry 服务,发现 HMS 出现 canary 异常后超时时间在 50s 多一点,说明参数生效。
2、监控 sentry 元数据 SENTRY_HMS_NOTIFICATION_ID 信息
直接获取 sentry 元数据 SENTRY_HMS_NOTIFICATION_ID 表的最新记录,如果没有更新则表示消息出现了滞后,此时 HMS 必会出现 canary 异常。
mysql> select * from SENTRY_HMS_NOTIFICATION_ID order by NOTIFICATION_ID desc limit 1;
+-----------------+
| NOTIFICATION_ID |
+-----------------+
| 184490926 |
+-----------------+
1 row in set (0.00 sec)
3、更新 sentry 消息同步记录
如果消息积压的太多,sentry 慢慢消费的时间太长的话,可能一直追不上 HMS 的最新 id,此时可以选择丢掉这些信息,具体操作在 sentry 元数据的 SENTRY_HMS_NOTIFICATION_ID 表中插入一条最大值(该最大值等于当前消息的 id 值,从 hive 元数据的 NOTIFICATION_SEQUENCE 表中获取 ),重启 sentry 服务。
use sentry;
insert into SENTRY_HMS_NOTIFICATION_ID values(184472866);
更新后 create 操作时间正常参考链接
Hive HMS Canary 时间较长异常分析 - 开发者博客
2022-09-28 大量删除hive分区导致hivemetastore canary - 简书
这篇关于CDH Hive Metastore canary的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![掌握Hive函数[2]:从基础到高级应用](https://i-blog.csdnimg.cn/direct/49298177ab7c4101b27f72a6abf5b84d.png)


