本文主要是介绍科赛网新人赛-员工满意度预测 MSE 0.02882,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
科赛网新人赛-员工满意度预测 - 竞赛思路
- 原贴地址
- 项目地址
文章目录
- 科赛网新人赛-员工满意度预测 - 竞赛思路
- 有用的资料、文档、博客
- 环境与工具
- 1.0 基础知识
- 1.1 数据挖掘流程:
- 2.0 数据探索性分析
- 2.1 单变量分析
- 2.2 多变量分析
- 3.0 特征工程
- 3.1 特征创建
- 3.1.1 笛卡尔积特征创建
- 3.1.2 使用 number_project 对 average_monthly_hours 进行加权
- 3.2 特征筛选
- 3.2.1 互信息法
- 3.3 特征预处理
- 3.3.1 package 特征
- 3.3.2 无量纲化
- 4.0 建模
- 4.1 单模 RandomForestRegressior
- 4.2 Stacking 模型融合 Lightgbm + Xgboost + Ridge
- 5.0 冲分日志
有用的资料、文档、博客
| 类别 | 链接 |
|---|---|
| 数据预处理 API–Pandas | https://pandas.pydata.org/docs/reference/index.html |
| 机器学习库–Sklearn | https://scikit-learn.org/stable/modules/classes.html |
| 数据可视化库–Seaborn | http://seaborn.pydata.org/ |
| 木东居士的特征工程系列(强烈推荐) | https://blog.csdn.net/zhaodedong/article/details/103451692 |
| 数据科学大杀器模型-LightGBM | https://lightgbm.readthedocs.io/en/latest/Python-API.html |
| Baseline 代码 | https://www.kesci.com/home/competition/forum/5f0aa9679ac5ac002db1d29f |
| 模型融合博客 | https://wmathor.com/index.php/archives/1428/ |
| 新人赛讨论区 | https://www.kesci.com/home/competition/forumlist/5ec3b6987ba12c002d3e42bc |
| 机器学习CheatSheet | https://machinelearningmastery.com/ |
| 强烈推荐这个人的数据挖掘系列 | https://wmathor.com/index.php |
| 贝叶斯调参 | https://www.cnblogs.com/yangruiGB2312/p/9374377.html |
| Xgboost API Document | https://xgboost.readthedocs.io/en/latest/python/python_api.html |
环境与工具
- 编程语言:Python
- 环境:Anaconda
- 主要工具
- Numpy(矩阵计算、数值计算)
- Pandas(数据表分析)
- Matplotlib、Seaborn(数据可视化)
- Scikit-Learn(机器学习工具包)
1.0 基础知识
1.1 数据挖掘流程:
- 赛题 / 数据来源/ 背景 理解
- 数据探索性分析
- 数据预处理
- 特征工程(80%)
- 特征创建
- 特征筛选
- 特征预处理
- 建模
- 模型选择
- 模型训练
- 模型调参
- 模型效果检验
- 预测
2.0 数据探索性分析
2.1 单变量分析
- 数据认知(字段类型、统计量)
- 异常值探索
- 统计量分析
- 数据分布
- 数据可视化
2.2 多变量分析
- 相关性分析
3.0 特征工程
3.1 特征创建
我是做了很多别的尝试的,这里只给出能提升分数最多的方法
3.1.1 笛卡尔积特征创建
-
在做这个之前有考虑聚合特征创建,但是这个数据集一对多的关系很少,不适合使用 featuretools 这种工具做聚合特征创建
-
这个数据集里面大部分是类别型特征,而且维度不大,只有 9 维,因此对所有的类别型特征做二阶笛卡尔积来创建新特征

3.1.2 使用 number_project 对 average_monthly_hours 进行加权
- 通过相关性分析得知,
number_project和average_monthly_hours呈正相关 - 之前跑随机森林时对特征进行可视化,发现
average_monthly_hours的特征重要性非常高,重要性排前三 - 跑单模 LightGBM 发现,
average_monthly_hours的特征重要性甚至是排在第一 number_project本身应当作为连续值,如果这个特征进行独热编码,其实是丢失了其本身的大小关系!!!- 利用
number_project的大小关系对特征average_monthly_hours进行加权, l o g 2 log_2 log2 这个对数转换使得加权数值比较合理,不会太大也不会太小 - 不知道你有没有发现,
average_monthly_hours是以小时为单位,个人认为以天为单位的模型鲁棒性会更好,所以对这个值除以 24

3.2 特征筛选
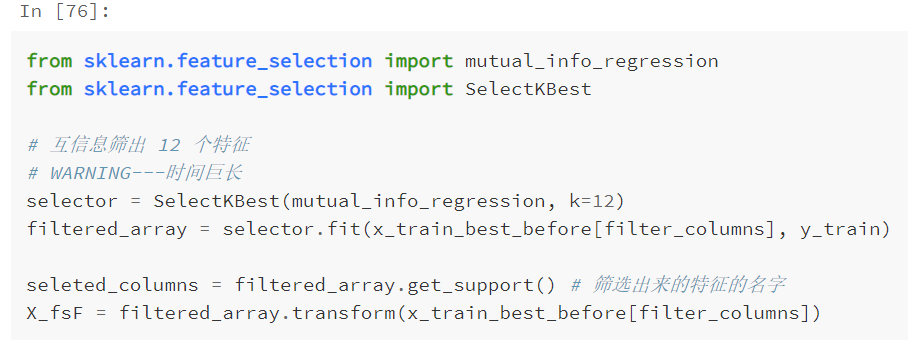
3.2.1 互信息法
使用互信息法,从笛卡尔积特征创建的四百多维的特征中筛选出 8 个最佳特征,互信息既可以捕捉单个特征与标签的线性关系,也可以捕捉单个特征与标签的非线性关系
3.3 特征预处理
3.3.1 package 特征
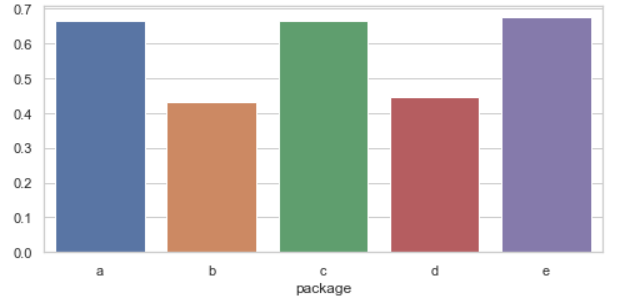
通过对 package 特征进行分组,求 satisfaction_level 的均值,发现 a, c, e 类别对应的均值很相近,b, d 类别对应的均值很相近,把 a, c, e 类别的归为一类,b, d类别的归为一类。
3.3.2 无量纲化
- 对
average_monthly_hours进行 MaxAbs 归一化
4.0 建模
根据别人的 Kernel,我发现单模效果最好的还是随机森林,自己也跑过 Lightgbm 发现效果并不理想
4.1 单模 RandomForestRegressior
4.2 Stacking 模型融合 Lightgbm + Xgboost + Ridge
5.0 冲分日志
2020-12-7
- 跑通 Baseline,并分析 Baseline 的方法
2020-12-8
- 跑了个 LightGBM,并进行了调参,但是没有 RF 效果好(MSE:0.032)
- 进行了 RF 调参,但是还是没有调参前的 RF 效果好
- Baseline 的 PCA + RF 第八名
2020-12-9
- 发现聚合特征创建不适合这个数据集,放弃 featuretools + 特征选择 + RF 这个思路
- 根据数据分析结果进行特征创建(package预处理:0.02936)第五名
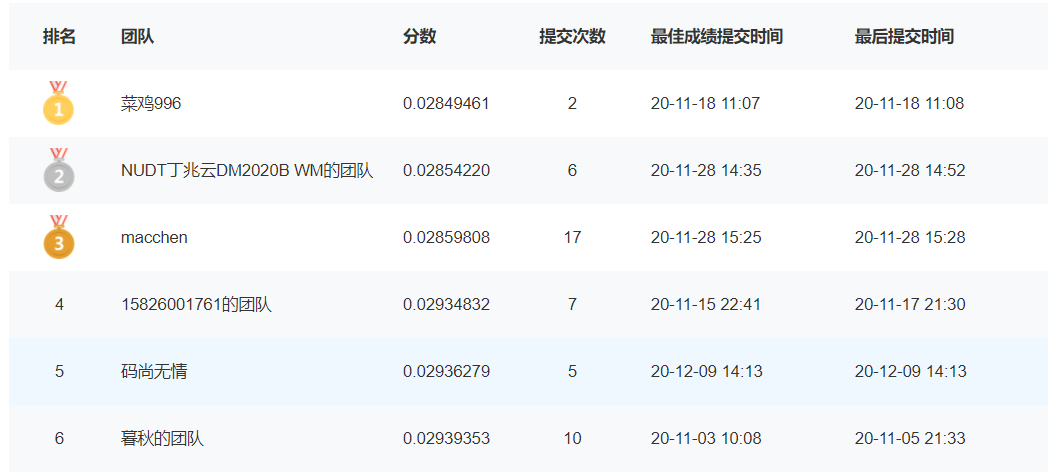
- 笛卡尔积特征创建 + f 检验(0.02933)第四名
- 笛卡尔积特征创建 + 互信息(0.02904271)第四名
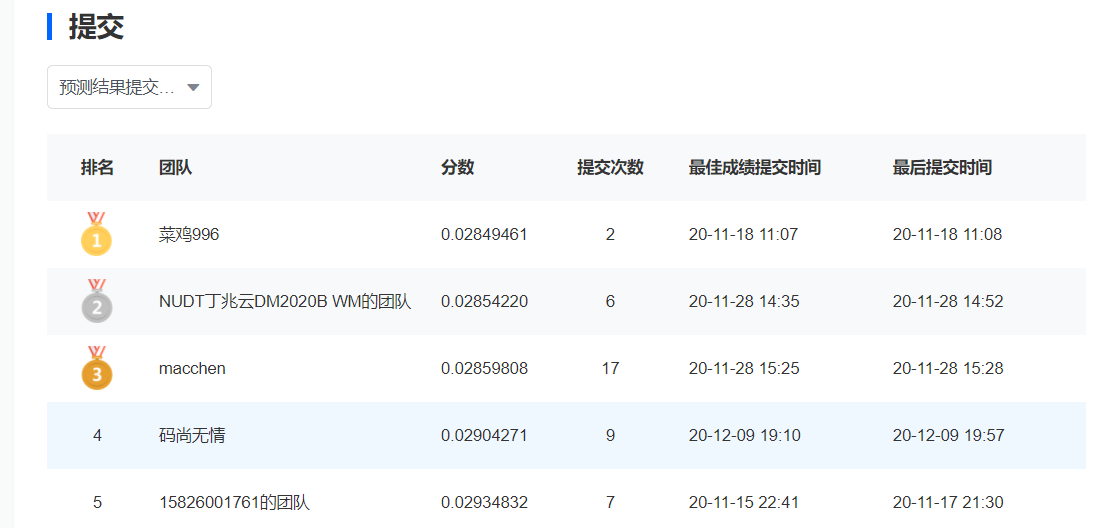
2020-12-10
- 先是跑了个lightgbm,发现这玩意儿练死劲儿不好用
- 尝试各种连续值处理
- 试了几种分箱,效果不理想
- 试了 box-cox,log变换,标准化,效果还可以,不过还是 MaxAbsscaler 效果最好
- 好家伙,要是上研了一定要买一台 i9 的笔记本💩😢
- 今天分数没长进
ps: 注意:把连续值处理那块改回来,明天尝试聚类分箱
2020-12-11
- 围绕连续值进行特征创建
- 利用 特征
number_project和average_monthly_hours创建新特征,MSE :0.02882(第四名)- 利用 特征
number_project和last_evaluation进行加权创建新特征,MSE 反而上升, 0.02892(第四)
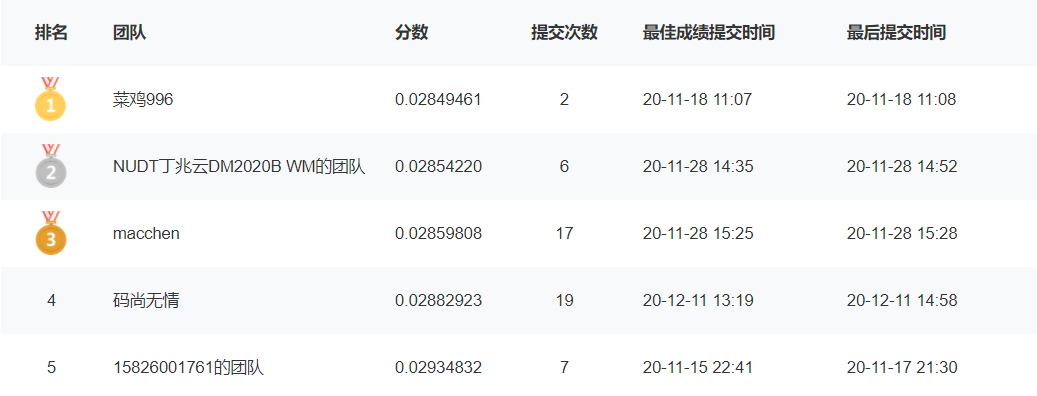
溜溜球,明天考六级,做题去了嘻嘻- 看了一下冠军方案的宣传,虽然说咱也没买他的课程吧,但是从他透的那一点,还是对我们有帮助的,摘录一下
- 要说明的是,我现在的方案多创建几个特征,就能超过这哥们当时的分数,这哥们的最终分数是 0.027,但是我感觉他的这一套流程不错,在此摘抄借鉴一下
- 对 lightgbm 使用贝叶斯调参
- Stacking 模型融合的三个模型分别是 随机森林回归、Xgboost、lightgbm
- 明天要做的事情:在今天最优的 train_data 上跑一个贝叶斯调参的rfr + 贝叶斯调参的lightgbm,然后进行模型融合,看能提升到怎么样一个分数,如果效果好,在以此为测试模型,不断创建新特征,来提升分数
- 根据大佬的博客,总结分析的套路、方法论这一套体系,以及每一环对应的知识、库、代码模板
注意:最优的数据集一定要 dump 下来,不要被分数冲昏了头脑👊
2020-12-12
- 早上不想干,下午考六级,晚上去到实验室都7点多了,沃日,六级考试真是折磨王,兰德里的折磨🙃
- 有点头疼,原来的模型跑了一下,凑合地把提交次数用完,然后新跑了个模型融合,是 Stacking 的 rfr + lgb,两个模型都没有网格搜索,然后元模型用了 岭回归,MSE 是 0.0290,感觉还是可以的,调参之后有望进入 0.027
- 累死了,回去睡觉
2020-12-13
- 失了智,要跑 Stacking 网格搜索,还是把 xgboost 的参数都搜一遍那种,其实用贪心法调参就好了
- 尝试了 用 last_evaluation 对 average_monthly_hours 加权,效果不佳
- 尝试了对 average_monthly_hours 进行聚类分箱,效果不佳
- 进行融合的模型,最好是类似于 rfr 的 bagging 模型,可以在 sklearn 上面搜一下
- 明天尝试对独热编码进行 embedding,要降维的话,肯定是要对有用的特征进行降维,通过特征重要性找到比较有用的类别型特征,然后 embedding
- https://www.kaggle.com/aquatic/entity-embedding-neural-net/comments
- https://blog.csdn.net/anshuai_aw1/article/details/83586404
2020-12-14
- 当前最重要的任务是分析出,训练集和测试集的数据分布不一样在哪儿
- 根据 进行分组,查看训练集和测试集差异较大的地方
2020-12-15
number_project3,4 归为一类,5和3、4的方差相差比较大,所以不将5和3、4归为一类time_spend_company5,6,7 分为一组(先不分,看提交之后分数是否提升),8,10 分为一组division“sales”,“technical”, “IT”, “RandD”, “hr” 归为一类

这篇关于科赛网新人赛-员工满意度预测 MSE 0.02882的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!