本文主要是介绍Python爬虫学习(利用requests库查询12306官网车票信息),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 分析流程
- 接口信息
- 获取站点中文对应的英文字母(1)
- 查询车票信息(2)
- 查询车票价格信息(3)
- 实现
- 运行
分析流程
12306上获取相关车票信息,输入的查询数据流向:
- 用户进入官网时,前端向接口1发送GET请求得到站点中文对应英文字母信息
- 用户在查询页面输入或选择出发地、目的地及相关参参数(包括出发日期、票的种类等),得到用户的出行信息
- 利用步骤1得到的数据与用户出行的站点信息匹配,得到站点对应英文字母
- 利用站点对应字母构造请求参数向接口2提交,获取车票信息
- 可利用某一车票信息构造请求参数向接口3提交得到其相应车票的价格
接口信息
获取站点中文对应的英文字母(1)
- 接口:https://www.12306.cn/index/script/core/common/station_name_v10036.js
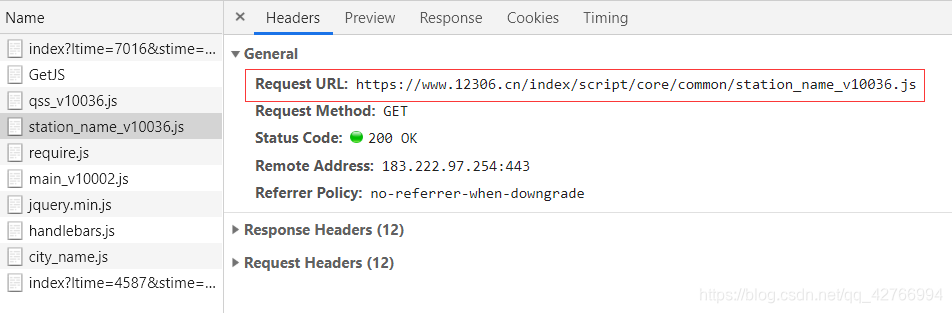
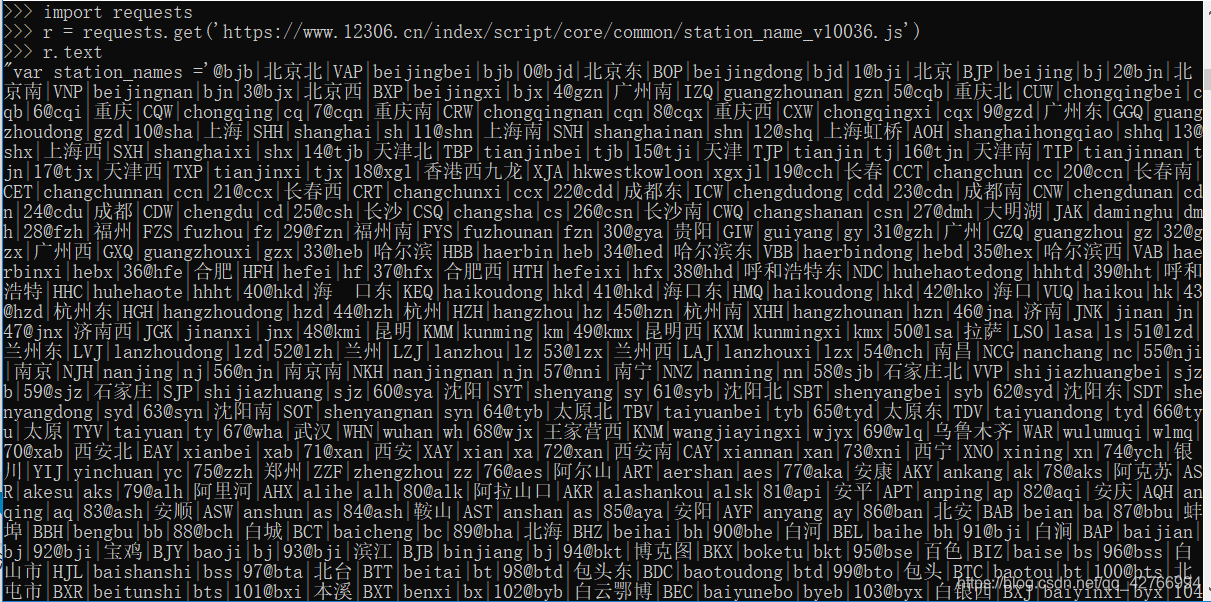
得到的数据格式如下
查询车票信息(2)
-
接口:https://kyfw.12306.cn/otn/leftTicket/query (GET)

参数依次是:时间、出发地、目的地、成人(ADULT)或学生(0X00),其中出发、目的地是以大写英文代替(含义在下面返回数据的map字段下)(亦有相关接口获取地方的英文含义,后续给出) -
利用Postman工具测试
向上图中那个Resquest URL发起GET请求,得到数据,我们发现在result字段下的数据做一下处理就可以得到车票的相关信息


查询车票价格信息(3)
- 接口:https://kyfw.12306.cn/otn/leftTicket/queryTicketPrice (GET)

参数值在车票信息result字段下 - 原理同理(不做重复)
实现
import requests
from datetime import datetime
import osclass Ticket_inquiry():def __init__(self):self.headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'}self.train_info = \['train_no', 'train_number', 'station_begin', 'station_end', 'begin', 'end', 'begin_time', 'end_time', 'duration', 'is_nextday','no_seat', 'hard_seat'] # 整理官网得到相关信息self.ticket_info_index = \[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 26, 29] #官网得到相关信息的索引位置self.begin = '' # 每次查询的出发地self.end = '' # 目的地self.ticket_info = None # 从官网获取的信息self.now_datetime = '' # 当前时间 格式: '2019-01-01'self.ticket_datetime = '' # 查询车票时间self.query_ans = list() # 查询结果self.stations = dict() # 得到的站点所对应的大写字母self.stations_file_path = 'D:\\stations.txt' # 得到的站点所对应的大写字母的信息的保存路径self.open_stations()def create_datetime(self, count=0):year = datetime.now().yearmonth = datetime.now().monthday = datetime.now().dayticket_day = int(day) + countf = '{0:4}-{1:{3}2}-{2:{3}2}' # 格式:2019-01-01self.now_datetime = f.format(year, month, day, '0')self.ticket_datetime = f.format(year, month, ticket_day, '0')def get_ticket_info(self, begin='', end='', date=0, isadult=True):self.ticket_info = Noneself.create_datetime(date)url = 'https://kyfw.12306.cn/otn/leftTicket/query' # 接口if isadult:purpose_codes = 'ADULT'else:purpose_codes = '0X00'params = {'leftTicketDTO.train_date':self.ticket_datetime,'leftTicketDTO.from_station':begin,'leftTicketDTO.to_station':end,'purpose_codes':purpose_codes} # 所需参数try:r = requests.get(url, params=params, headers=self.headers)r.raise_for_status()# r.encoding = r.apparent_encodingif r.status_code == 200:self.ticket_info = r.json() # 转换为json数据else:print('Server error!')except:print('Request ticket_info error!')finally:return self.ticket_infodef get_ticket_price(self, train_no='', from_station_no='', to_station_no='', seat_types='', train_date=''): # 获取价格信息url = 'https://kyfw.12306.cn/otn/leftTicket/queryTicketPrice' # 接口params = \{'train_no':train_no, 'from_station_no':from_station_no, 'to_station_no':to_station_no, 'seat_types':seat_types, 'train_date':train_date} try:r = requests.get(url, params=params, headers=self.headers)r.raise_for_status()if r.status_code == 200:return r.json()else:print('Server error!')except:print('Resquet praice_info error!')return Nonedef organize_ticket_info(self): # 整理得到的信息if self.ticket_info is not None:results = self.ticket_info['data']['result']if results is not None:stations = self.ticket_info['data']['map']speed_num = 0for result in results:speed_num += 1print('\r正在查询..{:.1f}%'.format(100*speed_num/len(results)), end='')ans = dict()result_list = result.split('|')count = 0for train in self.train_info:ans[train] = result_list[self.ticket_info_index[count]]count += 1data = self.get_ticket_price(result_list[2], result_list[16], result_list[17], result_list[35], self.ticket_datetime) # 获取价格信息, 日期:13try:data = data['data']price_info = dict()price_info['no_seat'] = data['WZ']price_info['hard_seat'] = data['A1']price_info['hard_sleeper'] = data['A3']price_info['soft_sleeper'] = data['A4']except:passans['price_info'] = price_infoself.query_ans.append(ans)# print(self.query_ans)self.save_stations(stations)return self.query_ansdef print_ticket_info(self):os.system('cls')t = self.query_ansif t:print('\n%s - %s\n---' % (self.begin, self.end))for train_info in self.query_ans:try:print('车次:%-5s %s开-%s到 价格:%s(硬座)、%s(硬卧)'\% (train_info['train_number'], train_info['begin_time'], train_info['end_time'], \train_info['price_info']['hard_seat'], train_info['price_info']['hard_sleeper']))except:passprint('---\n')else:print('无票!\n')self.query_ans = []def save_stations(self, stations={}):if stations is not None:stations_chinese = dict()for key, val in stations.items():stations_chinese[val] = keyself.stations.update(stations_chinese)with open(self.stations_file_path, 'w') as file_object:file_object.write(str(self.stations))def open_stations(self):try:with open(self.stations_file_path, 'r') as file_object:stations_str = file_object.read()if stations_str is not None:self.stations = eval(stations_str)return self.stationsexcept:passdef use_chinese_query(self, begin='', end='', date=0):self.open_stations()try:self.begin = str(begin)self.end = str(end)begin = self.stations[self.begin]end = self.stations[self.end]if begin and end:self.get_ticket_info(begin, end , int(date))return Trueexcept:return False if __name__ == '__main__':ticket = Ticket_inquiry()while True:begin = input('请输入出发地:')end = input('请输入目的地:')date = input('几天后出发(0:今天):')if not ticket.use_chinese_query(begin, end, date):ticket.get_ticket_info(str(begin).upper(), str(end).upper(), int(date))ticket.organize_ticket_info()ticket.print_ticket_info()
运行

注:这里输入出发地、目的地需要先用代表车站的英文字母查一遍,程序会将其英文字母所对应车站以字典形式以更新的形式存放在文件中,以后才可用这里面有的中文作为查询条件查询

这篇关于Python爬虫学习(利用requests库查询12306官网车票信息)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







