本文主要是介绍第三章:人工智能深度学习教程-基础神经网络(第二节-ANN 和 BNN 的区别),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在本文中,我们将了解单层感知器及其使用 TensorFlow 库在Python中的实现。神经网络的工作方式与我们的生物神经元的工作方式相同。
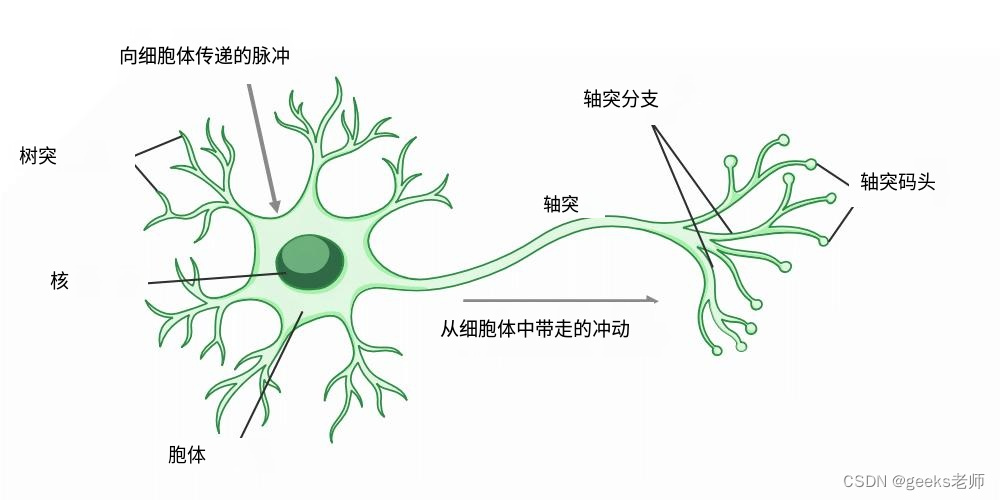
生物神经元的结构
生物神经元具有三个基本功能
-
接收外部信号。
-
处理信号并增强是否需要发送信息。
-
将信号传递给目标细胞,目标细胞可以是另一个神经元或腺体。
同样,神经网络也能发挥作用。
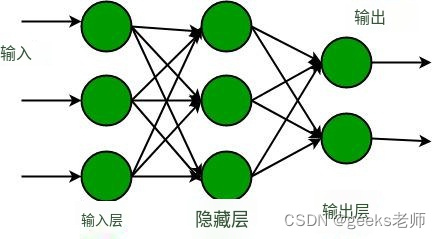
机器学习中的神经网络
什么是单层感知器?
它是最古老且最早引入的神经网络之一。它是由弗兰克·罗森布拉特 (Frank Rosenblatt)于1958 年提出的。感知器也称为人工神经网络。感知器主要用于计算AND、OR、NOR等具有二进制输入和二进制输出的逻辑门。
感知器的主要功能是:-
-
从输入层获取输入
-
对它们进行加权并总结。
-
将总和传递给非线性函数以产生输出。
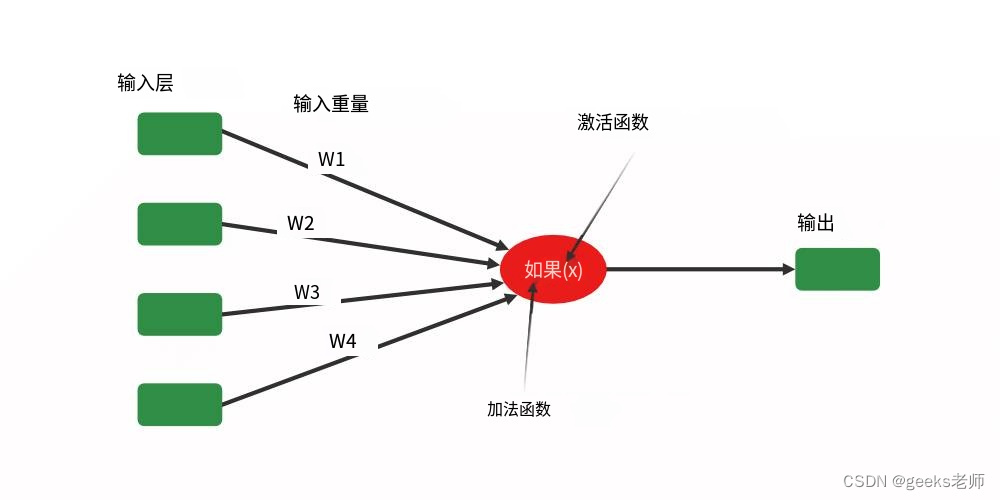
单层神经网络
这里的激活函数可以是sigmoid、tanh、relu等任何函数。根据需求,我们将选择最合适的非线性激活函数以产生更好的结果。现在让我们实现一个单层感知器。
单层感知器的实现
现在让我们使用 TensorFlow 库使用“MNIST”数据集实现一个单层感知器。
Step1:导入必要的库
-
Numpy – Numpy 数组非常快,可以在很短的时间内执行大量计算。
-
Matplotlib – 该库用于绘制可视化效果。
-
TensorFlow – 这是一个用于机器学习和人工智能的开源库,提供一系列函数以通过单行代码实现复杂的功能。
Python3
import numpy as np
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt# 开启内联绘图
%matplotlib inline
步骤 2:现在使用导入版本的张量流中的“Keras”加载数据集。
Python3
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
这段代码导入了一些常用的Python库,包括NumPy(用于数值计算)、TensorFlow(用于深度学习)、Keras(用于构建神经网络模型)以及Matplotlib(用于绘图和数据可视化)。通过
%matplotlib inline,我们可以在Jupyter Notebook或IPython环境中直接在输出单元格中显示图形,而不需要单独的窗口。这些库的使用使得在进行深度学习和数据可视化任务时更加方便。
步骤 3:现在显示数据集中单个图像的形状和图像。图像大小包含28*28的矩阵,训练集长度为60,000,测试集长度为10,000。
Python3
# 获取训练集的长度
len(x_train)# 获取测试集的长度
len(x_test)# 获取第一个训练图像的形状
x_train[0].shape# 显示第一个训练图像
plt.matshow(x_train[0])这段代码执行以下操作:
len(x_train)返回训练集中样本的数量。len(x_test)返回测试集中样本的数量。x_train[0].shape获取第一个训练图像的形状,通常是一个28x28像素的二维数组。plt.matshow(x_train[0])用Matplotlib库显示第一个训练图像,可以通过该图像来查看手写数字的外观。这些操作有助于了解MNIST数据集的规模和内容,并可以用于数据预处理和可视化。
输出:
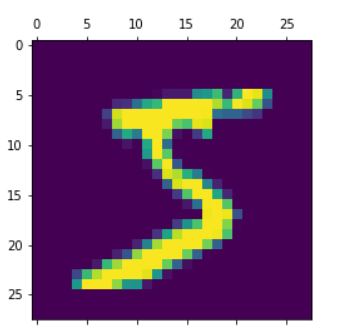
来自训练数据集的样本图像
步骤 4:现在标准化数据集,以便快速准确地进行计算。
Python3
# 对数据集进行标准化
x_train = x_train / 255
x_test = x_test / 255# 扁平化数据集以便进行模型构建
x_train_flatten = x_train.reshape(len(x_train), 28*28)
x_test_flatten = x_test.reshape(len(x_test), 28*28)
这段代码执行以下操作:
对训练集
x_train和测试集x_test进行标准化,将像素值从0到255的范围缩放到0到1的范围,这是一种常见的数据预处理步骤。扁平化数据集,将每个图像从一个二维数组(28x28像素)转换为一个一维数组(784个像素),以便于后续的模型构建。这是因为深度学习模型通常需要输入的是一维数据。
这些操作是为了准备数据以用于深度学习模型的训练,以便更好地处理图像数据。
第5步:构建具有单层感知的神经网络。在这里我们可以观察到,该模型是一个单层感知器,仅包含一个输入层和一个输出层,不存在隐藏层。
Python3
model = keras.Sequential([keras.layers.Dense(10, input_shape=(784,), activation='sigmoid')
])model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']
)model.fit(x_train_flatten, y_train, epochs=5)
这段代码执行以下操作:
创建一个Keras顺序模型,该模型包含一个具有10个神经元的全连接层(
keras.layers.Dense),输入形状为(784,),激活函数为'sigmoid'。这是一个简单的神经网络模型。编译模型,指定优化器为'adam',损失函数为'sparse_categorical_crossentropy'(适用于多类别分类问题),并选择评估指标为'accuracy'(准确度)。
使用训练数据
x_train_flatten和相应的标签y_train对模型进行训练,训练周期数为5(epochs=5)。这些操作构建了一个简单的神经网络模型,并使用训练数据对其进行了训练,以便用于多类别分类任务,例如手写数字识别。
输出:
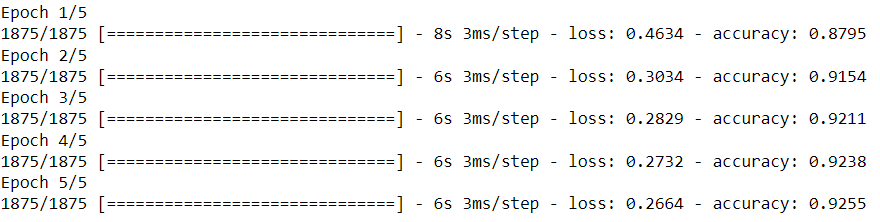
在训练过程中,通常会产生一系列的训练日志,包括损失和准确度等信息。这些信息会在训练的每个周期(epoch)后显示。由于这些信息的输出取决于您的运行环境,我无法提供确切的训练输出。您可以将代码放入一个Jupyter Notebook或Python脚本中运行以查看详细的训练输出。
通常,您可以期望在每个周期的训练输出中看到损失值和准确度的变化,以便跟踪模型的训练进展。当训练完成后,您可以使用模型进行预测,并评估其性能,例如在测试数据上计算准确度。这些步骤通常会在训练后的代码中进行。如果您有特定的输出或问题,可以提供更多详细信息,以便我能够提供更具体的帮助。
步骤6:输出模型在测试数据上的准确率。
Python3
model.evaluate(x_test_flatten, y_test)
这段代码执行了模型的评估操作,使用测试数据
x_test_flatten和相应的测试标签y_test来计算模型在测试数据上的性能指标。这些性能指标通常包括损失值和准确度等,用于衡量模型在测试数据上的表现。评估的结果将根据模型的性能和测试数据而异,通常以一个包含指标值的列表返回。
输出:
[损失值, 准确度]
损失值表示模型在测试数据上的损失值,通常是一个非负数,表示模型对测试数据的拟合程度。准确度表示模型在测试数据上的准确度,通常以百分比形式表示,表示模型在测试数据中正确分类的比例。具体的数值将根据模型的训练和测试数据集而有所不同。您可以运行这段代码以查看实际的输出结果,以便了解模型在测试数据上的性能。
这篇关于第三章:人工智能深度学习教程-基础神经网络(第二节-ANN 和 BNN 的区别)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







