本文主要是介绍西瓜书第一二章,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第一章
机器学习: 人的“经验”对应计算机中的“数据”,让计算机来学习这些经验数据,生成一个算法模型,在面对新的情况中,计算机便能作出有效的判断,这便是机器学习。
机器学习研究的主要内容:学习算法。从数据中产生模型(model)的算法。
Mitchell 给出一个更形式化的定义:假设用 P 来评估计算机在任务 T 上的性能,若一个程序利用经验 E 在 T 中任务上取得了性能上的改善,则我们说关于 P 和 T,改程序对 E 进行了学习。
- P:计算机程序在某任务类T上的性能。
- T:计算机程序希望实现的任务类。
- E:表示经验,即历史的数据集。
分类、回归和聚类是机器学习的三大任务。分类和回归都是预测任务,区别在于预测值是离散还是连续;聚类将训练集中的数据分成若干组(簇),以帮助发现一些数据内在的规律。
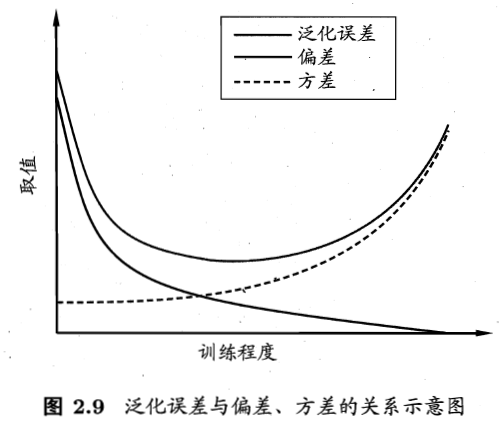
泛化能力(generalization):学得模型适用于新样本的能力。能够反映出样本空间的特性的训练集越有可能经过学习得到具有强泛化能力的模型。
第二章
过拟合(overfitting):学习能力过于强大,把训练样本自身的一些特点当成所有潜在样本都会有的一般性质,导致泛化能力下降
欠拟合(underfitting):学习能力太差,对训练样本的一般性质尚未学好
评估方法:
1、留出法:将数据集D划分为两个互斥的集合,一个作为训练集S,一个作为测试集T,即D=S∪T且S∩T=∅。
2、交叉验证法:将数据集D划分为k个大小相同的互斥子集,每次用k-1个子集的并集作为训练集,余下的子集作为测试集。
可进行k次训练和测试,最终返回k个测试结果的均值
交叉验证法评估结果的稳定性很大程度上取决于k的取值,k最常用的取值是10,此时称为10折交叉验证,其他常用5,20;
3、自助法:留出法和交叉验证都保留了一部分样本用于测试,导致训练集实际上比 D 小,这会引入因训练样本规模不同而导致的估计偏差。自助法(boostrapping)是一种解决方案。
我们通过对有 m 个样本的 D 进行 m 次采样得到 D’,用 D’ 作为训练集,D\D’ 作为测试集。显然,有些样本在 D’ 中出现多次,有些一次也不出现。
样本在 m 次采样中都不被采样到的概率为 ( 1 − 1 m ) m (1-\frac{1}{m})^m (1−m1)m ,取极限得到其概率为 1 e = 0.368 \frac{1}{e}=0.368 e1=0.368,即 D 中约有 37% 的样本未出现在 D’ 中。依旧有不曾出现在训练集中的样本用于测试,这样的测试结果成为“包外估计”。
优点:在数据集较小难以划分 T 和 S 时很有用;同时能够产生多个不同的训练集,对集成学习有帮助
缺点:自助法产生的数据集改变了初始数据集的分布(样本出现的次数发生改变),会引入估计偏差
因此在样本数量足够时,多采用留出法和交叉验证法。
评估指标:
准确率 = 所有预测对的 / 所有样本 = (真阳性 + 真阴性)/ (真阳+真阴+假阳+假阴)
敏感度(召回率) = 好人被预测对的 / 所有真实是好人 = 真阳 / (真阳 + 假阴)
特异度 = 坏人被预测对的 / 所有真实是坏人 = 真阴 / (真阴 + 假阳)
准确率 = TP / TP + NP
F分数 = 准确率和召回率的调和平均数
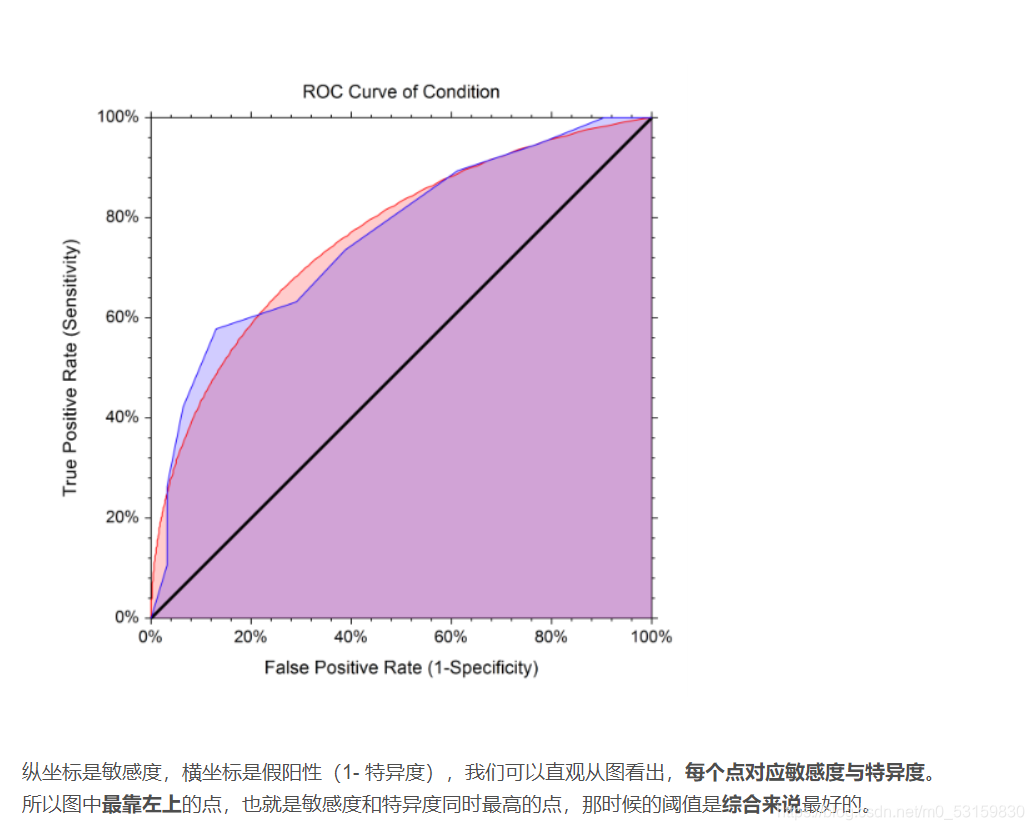
ROC曲线 同时关注特异度和敏感度,使得两者和最大
首先,召回率和精准率是基于好人的标准上的。F分数也只是关注辨识好人的能力。
其次,分析好人标准于同时影响敏感度与特异度。已经知道好人标准会影响敏感度(召回率),同时,好人标准也会影响特异度,因为好人的标准越高,就越多坏人可以被认出来,特异度就变高(真阴变多,假阳减少),但是召回率就变低,因为有些不是特别好的好人可能也被当为坏人了。相反,好人标准变低,坏人容易被认为好人(真阴减少,假阳变多),特异度就变低,同时召回率就升高了(真阳变多,假阴变少)。
最后分析ROC曲线的实际意义。这个好人标准,就是机器学习中所说的阈值,调节阈值
这篇关于西瓜书第一二章的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!