本文主要是介绍基于labelme和python的图像违禁品提取和注入新背景图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、摘要
二、违禁品的标注
三、违禁品的提取和注入新背景图
一、摘要
本文使用labelme软件手动标注出图像中的15类违禁品,如枪、刀、打火机等,将标注结果生成json文件。使用labelme_json_to_dataset命令将json文件转换成一个包含label图像的文件。采用遍历label图像像素点,判断像素是否为黑色的方法,将对应的原图像中的违禁品逐像素地注入到新背景图像中。其中,通过对原图像进行缩放、调整新背景图中违禁品注入位置的两种方式,保证违禁品能完全存放到背包行李中;为保证图像的多样性,还对原图像进行了翻转操作。
二、违禁品的标注
图像中违禁品的标注采用labelme软件。如图1所示。labelme是一个用于在线图像标注的Javascript 标注工具。与传统图像标注工具相比,它帮助我们标注图像,不需要在电脑中安装或复制大型数据集。

(1)点击左侧Open Dir选择需要标注的数据文件夹。
(2)点击左侧的create polygons,用鼠标画出图像中违禁品的轮廓,完成标注后会形成一个标注区域,同时弹出labelme的框,键入标签名字,点击 OK完成标注。采用如上的方法,对图像中的所有违禁品进行标注。
(3)标注完一张图片,点击左侧的save,保存生成JSON文件。依次标注文件夹中的20张图片。
二、违禁品的提取和融入新背景
1.JSON文件的转换
在命令行中输入labelme_json_to_dataset name.json,可以将json文件转换为一个包含原始图像、label图像、label_viz图像和标注文本的文件夹。如图2所示。

2.将违禁品注入新背景
(1)注入前的准备
首先,需要使用的图像有3张,导入的分别是原始图像、label图像和新背景图像。
然后,对三个图像进行缩放,确保原始图像中的违禁品注入到新背景图中不会超出图像边界。在缩放过程中,为了保证遍历算法中原始图像和label像素点的一一对应,要将原始图像和label图像按着同比例缩放。
最后,对原始图像和label图像进行翻转操作,包括水平翻转、垂直翻转和垂直水平翻转,以增加融合图像的随机性和复杂性。
(2)注入新背景
观察图2可得,label图像的背景均为黑色,被标注的危险品为其他颜色;而且原始img图像和label图像的大小完全相同,像素点一一对应。因此可以采用遍历label图像像素点的方式,若label图像的像素点不为黑色,表明该像素点代表违禁品,则将对应的原图像的该像素点注入到新背景图中,否则不注入。这样就可以将原始图像中的违禁品全部放到新背景图。算法的流程图如图4所示。
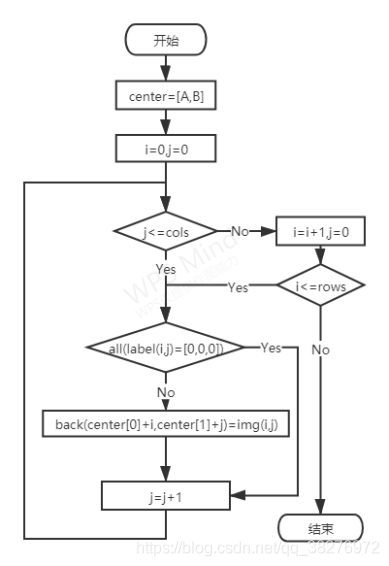
在上述算法中,img为原始图像,label为label图像,back为背景图像,cols是原始图片像素点的列数,rows是原始图片像素点的行数,[0,0,0]代表该像素点为黑色。center=[A,B]用来调整违禁品在新背景图中的位置。
该项目的困难点是要保证违禁品能完全注入到新背景的行李箱背包中,为解决该问题,本文总共采取了调整原始图片缩放比例和设置注入位置的两种方法。根据违禁品的注入情况,灵活调整原始图片的缩放比例,灵活调整违禁品注入的位置,最终可以找到违禁品注入的最佳效果。
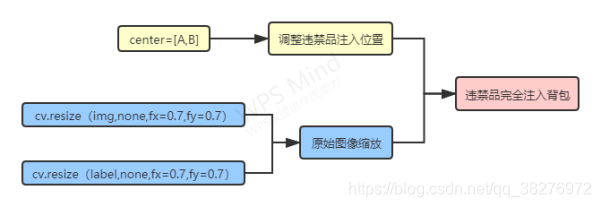
下面可通过对比,明显看出两种方法的作用。对比结果如图5所示。


图5 未缩放、未调整注入位置 图6 原始图像x,y缩放70%,调整注入位置center=[0,80]
三、融合结果展示
原图 背景图 违禁品注入后的图
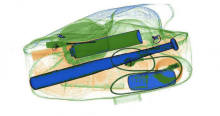

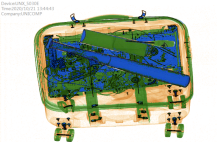
程序:
import cv2
import numpy as np# 导入图片
img=cv2.imread('C:/Users/xiaobin/Desktop/25/092248080_json/img.png')
img_back=cv2.imread('C:/Users/xiaobin/Desktop/background/1.jpg')
img_label=cv2.imread('C:/Users/xiaobin/Desktop/25/092248080_json/label.png')# 缩放
img_back=cv2.resize(img_back,None,fx=1,fy=1)
cv2.imshow('img_back',img_back)
img=cv2.resize(img,None,fx=0.7,fy=0.7)
cv2.imshow('img',img)
img = cv2.flip(img,1) # 原图图像翻转
img_label=cv2.resize(img_label,None,fx=0.7,fy=0.7)
cv2.imshow('label',img_label)
img_label = cv2.flip(img_label,1) # label图像翻转
rows,cols,channels = img_label.shape #rows,cols是前景图片的,后面遍历图片需要用#遍历替换
center=[0,50] #用于调整违禁品在新背景图片中的位置
for i in range(rows):for j in range(cols):if all(img_label[i,j]==[0,0,0]):#0代表黑色的点passelse:img_back[center[0]+i,center[1]+j]=img[i,j] #此处对新背景图替换颜色,
#注入违禁品
cv2.imshow('res',img_back)
cv2.waitKey(0)
cv2.destroyAllWindows()
这篇关于基于labelme和python的图像违禁品提取和注入新背景图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







