本文主要是介绍A Dependency-Based Neural Network for Relation Classification(DepNN,2015)论文阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景
SVM(2010)
MV-RNN(2012)
CNN(2014)
FCM(2014)
DT-RNN(2014)
DT-RNN使用RNN建模依赖树后,通过线性组合的方式将节点的词嵌入与其子节点的词嵌入结合起来。而本文则是利用子树结合词嵌入,再使用CNN捕捉特征,F1值大幅提高。
以往的关系分类研究已经验证了使用依赖最短路径或子树进行关系分类的有效性。二者具有不同的功能。本文提出了一种新的结构:Augmented Dependency Path(ADP,增强依赖路径),将两个实体间的最短依赖路径和与最短依赖路径相连的子树结合起来:使用递归神经网络建模子树,将生成的依赖子树的表示附加到最短依赖路径上的单词上,从而使最短依赖路径上的单词获得新的词嵌入,然后使用卷积神经网络捕捉最短依赖路径上的关键特征。
传统的依赖解析树:

本文提出的ADP结构:

加粗部分为句子的最短依赖路径。从图二中可以看出,具有相似最短依赖路径的两个句子却具有不同的relation,表明只使用最短依赖路径具有局限性,同时使用子树后则可以辨别两者的区别。
二、模型

1.词嵌入
首先,句子中的每个word和最短依赖路径中的每个dependency relation都被映射成向量xw,xr,二者维度相同

2.使用RNN对依赖子树进行建模
对于最短依赖路径中的每个word,使用一个递归神经网络,从其叶节点到根节点(即这个word本身),自上而下地生成一个subtree embedding: cw

如果一个词是根节点,将其subtree embedding表示为cLEAF。
每对父节点与子节点之间都存在一个依赖关系r,设置一个变换矩阵Wr,在训练过程中学习

从而得到 **cw**的计算公式:

其中R(w,q)表示词w和其子节点词q之间的依赖关系。
计算过程举例可以参考帖子:https://blog.csdn.net/appleml/article/details/78778555
3.使用CNN对最短依赖路径进行建模
经上述步骤后,我们得到了最短依赖路径上的word的表示pq(维度为dim+dimc) 和dependency relation的表示xr(维度为dim)

应用window processing,当窗口大小k=3时,得到的n个窗口表示为(n为句子长度):

s表示start,e表示end
将每个窗口内的k个向量拼接,得到

nw是窗口内word的个数,Xi 表示第i个窗口的拼接向量
随后设置一个含有l个卷积核的filter:
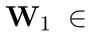
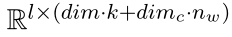
将filter应用于每一个窗口Xi ,得到

最后应用一个最大池化操作:

L是一个l维向量,与句子长度n无关
4.分类
可以对L添加一些外部特征(如NER和WordNet上义词):

经过一个全连接层后,送入softmax分类器分类:

采用交叉熵损失,反向传播训练。
依赖树生成采用:Stanford Parser (Klein and Manning, 2003) with the collapsed option.
三、实验结果


待解决的疑问:
1.dependency relation的嵌入**xr**是预先训练好的还是随机初始化的?
2.本文中的最短依赖路径相当短(甚至只有3个词),而SDP-LSTM(2015)中的最短依赖路径却比较长(也许是使用了不同版本的Stanford parser???)
这篇关于A Dependency-Based Neural Network for Relation Classification(DepNN,2015)论文阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







