本文主要是介绍[实体关系抽取|顶刊论文]QIDN:Query-based Instance Discrimination Network for Relational Tri,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Query-based Instance Discrimination Network for Relational Triple Extraction
Zhejiang University, Tsinghua University|EMNLP 2022|2022.11.3|原文连接
想法简述
过去的方法都可以用上图来表述:
H c o n t e x t H_{context} Hcontext:句子表示, R p o t e n t i a l R_{potential} Rpotential:潜在类型的关系向量映射。要么从立体的角度考虑提取【立体透视图】的方法,要么学到每种关系的独立分类器。
如:PRGC首先过滤不太可能的关系,然后学习潜在关系的特定关系标记。
近年的研究,都是从立体的角度考虑三重关系抽取,尽管有比较好的效果,但仍存在以下问题:
- 对于先识别主体,后抽取三元组中,第一阶段难免会出现错误。如上图中PRGC先选取潜在关系标记关系特定的实体,但正确的可能会被过滤掉
- 存在关系冗余的问题,对于CasCade、TPLinker的方法,它们对所有关系进行三元组组装,产生了大量的无效操作,标签稀疏,收敛速度低
- 过去的方法独立处理每个关系类型的三元组,没有考虑到他们之间的高级全局链接:(哈尔滨,国家,北京)已经被确定后,”北京“就不应该出现在诸如夫妻的家庭关系的三元组之中。
对于以上问题,作者提出基于查询的实例识别网络(QIDN)。
如上图:
- 使用一组类型无关的 Query Embeddings从预训练的模型中获取上下文信息。
- 通过比较Query Embeddings和Token Embeddings的度量,一步提取所有关系的三元组,消除了误差传播【基于简单的相似性度量,一步抽取所有关系三元组】
- 使用Query Embedding查询最可信的关系类型,解决了关系冗余的问题。
- 设立两个训练目标:(1)同一类内的实例对的相似性大于不同类间的实例。(2)实例表示更接近他们的相应关系。以建立三元组之间的全局链接。【使用了对比学习】
Query-based methods:
该方法最初被运用于DETR:End-to-End Object Detection with Transformers中,其实本文也是DETR在NLP中的应用.该查询是类型无关的,因此可以在不同规模的对象间建立全局依赖关系,故将其用于构造实例级表示,在不同类型中构建全局链接
Contrastive relation learning:
通过比较含相同实体对的句子,从而提取关系语义,在后续的研究中,又被改进用于区分两种关系类型是否语义相似。在作者的方法中使用Query Embeddings构造实例级的三重表示,同时考虑了实体与关系
QIDN模型
在经过Sentence Encoder编码后, 结合Query在Decoder中完成Triple Prediction. 此外, 使用Instance Discriminator在空间中用对比学习约束预测头得到的三元组表示.
制定任务
$X\ =\ x_ { 1 } , x _ { 2 } , \dots,x _ { n } \ $:输入的句子
$ \varepsilon = (x_i, x_j, t_e) : : :x_i 和 和 和y_j 表 表 表{\gamma}_e 中预定义的实体类型 中预定义的实体类型 中预定义的实体类型t_e$的实体的左右标记
$ {\mathcal{R}} = \left({\mathcal{e}}{1},,{\mathcal{e}}{2},,t_{r}\right), :表为关系集, :表为关系集, :表为关系集,e_1,e_2 为主客实体, 为主客实体, 为主客实体,t_r 为预定义集合 为预定义集合 为预定义集合{\gamma}_r$中的关系类型
L { \mathcal { L } } L:在两个预定义集合中的标签,表为未识别的实体/关系。
句子编码器
使用BERT直接编码后,将token输入到BiLSTM中,最后的句子标识形式为 H ⊂ R n × d {\cal H}\ \subset\mathbb{R}^{n\times d} H ⊂Rn×d:n为句子的长度、d为隐藏中间层的大小
双向编码器-解码器LSTM (BiLSTM)模块进行实体抽取,然后将实体上下文信息传递给CNN模块进行关系抽取。该方法考虑了实体之间的长程关系,但存在一些被忽略的关系,需要进一步研究以提高召回率。
三元组的预测
作者使用 M M M个Instance Level Query Q = R M × d Q\mathrm { ~ } =\mathrm{ ~ } \mathbb { R } ^ { M\times d } Q = RM×d来查询句子中所包含的所有三元组
由于RTE任务需要抽取出关系特定下的头尾实体, 这意味着每个Query Embedding不但能指出对应的头尾实体, 还有头尾实体间关系, 所以在这个模块中作者需要构建对实体和关系的两种Query.
RTE(Recognizing Textual Entailment)任务目标位判断给定的两个文本片段之间的逻辑关系
使用与DETR相同的实例查询,记为 Q = R M × d . \textstyle\mathrm { ~ } Q\mathrm { ~ } =\mathrm{ ~ } \mathbb { R } ^ { M\times d } . Q = RM×d..每个查询(大小为d的向量)负责提取一个三元组,查询向量是随机初始化的。为了区分关系和实体的特征,而查询的数量 M \mathrm{M} M是预先指定的
在DETR中,每个查询用于每个目标上,而该文就被用于每个三元组之中
Transformer-based Decoder:
解码器由L层的transformer组成
- Attention的计算方式如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V \mathrm{Attention} \; (Q,K,V) = \mathrm{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
Q,K,V为Query、Key、Value矩阵, 1 d k \frac{1}{\sqrt{d_{k}}} dk1为缩放因子。
- Transforer的堆叠方式如下:
D e c o d e r ( Θ , H ′ ) = A t t e n t i o n ( Θ , H ′ , H ′ ) \mathrm{Decoder}(\Theta,H^{\prime})=\mathrm{Attention}(\Theta,\,H^{\prime},\,H^{\prime}) Decoder(Θ,H′)=Attention(Θ,H′,H′)
在DETR的架构中, Decoder端的Query便是Query Embedding, Key和Value则是原图信息.
在QIDN的交叉注意力机制中,不直接将句子编码器的H作为key与value,而是构造Span Level获取每层的语义信息。 S ⟶ ‾ s 1 s 2 , … , s n s {\boldsymbol{S}}\,\underline{{{\longrightarrow}}}~s_{1}\,s_{2},\ldots,s_{n_{s}} S⟶ s1s2,…,sns为句子 X \mathrm{X} X中所有的Span,对于任意一Span,其span表示 H i s p a n H_i^span Hispan为 H \mathrm{H} H中的Span边界标识与长度Embedding的拼接。
H i S p a n → [ H s t a r t ( i ) ⋅ H e n d ( i ) ⋅ ϕ ( s i ) ] \begin{array}{c}{{H_{\mathrm{i}}^{S p a n}\rightarrow\ [H_{\mathrm{start}}(\mathrm{i})\cdot H_{\mathrm{end}}(\mathrm{i})\cdot\phi\left(s_{\mathrm{i}}\right)]}}\end{array} HiSpan→ [Hstart(i)⋅Hend(i)⋅ϕ(si)]
- H s t a r t ⋅ H e n d H_{\mathrm{start}}\cdot H_{\mathrm{end}} Hstart⋅Hend:表示为起始/结束Token
- ϕ ( s i ) \phi\left(s_{\mathrm{i}}\right) ϕ(si):为NER中Span based方法常用的长度Embedding,可以加入Span的长度信息,
- 最终Span Level的表示为 H s p a n ∈ R n s × d {\cal H}^{s p a n}\in\mathbb{R}^{n_{s}\times d} Hspan∈Rns×d
同时,Query需要同时抽取关系和实体,因此Query需要兵分两路。变为realation query/entity query,其中 W r , W e ⊆ R d × d W_{r},{W}_{e}\subseteq\mathrm{\R}^{d\times d} Wr,We⊆Rd×d 为可训练参数
[ ( Q r ; Q e ) ] = D e c o d e r ( [ ( Q W r ; Q W e ] , H s p a n ) [(\mathcal{Q}_{r};\mathcal{Q}_{e})]=\mathrm{\cal{D}}\mathrm{ecoder}\,(\left[(\mathcal{Q}\mathcal { W }_{r};\mathcal { Q } \mathcal { W } _{ e }\right],H^{s p a n}) [(Qr;Qe)]=Decoder([(QWr;QWe],Hspan)
Span level通常指文本处理任务中处理的最小单位,即文本片段或子串。这个片段通常由一连串的字符组成,可以是单词、短语、句子或其他语言单元。可能会获得大量的负样本,有利于对比学习
有了以上的过程,有了成对儿的 Q r , Q e Q_r, Q_e Qr,Qe,可以用简单的预测头将每个Q所对应的三元组预测出来
解码器的详细结构:
Relation Head
对于 Q r Q_r Qr,将其输入到一个FFN(Feed Forward Networks,FFN),以预测它们对应的三元组的类别,第i个查询属于c类型的概率表示为:
P i c t = exp ( Q r i W t c + b t c ) ∑ c ′ ∣ γ r ∣ exp ( Q r i W t c ′ + b t c ′ ) P_{i c}^{t}=\frac{\exp\left(Q_{r}^{i}W_{t}^{c}+b_{t}^{c}\right)}{\sum_{c^{\prime}}^{|\gamma_r|}\exp\left(Q_{r}^{i}W_{t}^{c^{\prime}}+b_{t}^{c^{\prime}}\right)} Pict=∑c′∣γr∣exp(QriWtc′+btc′)exp(QriWtc+btc)
W t ∈ R ∣ V r ∣ × d L b t ∈ R ∣ V r ∣ W_{t}\,\in\,\mathbb{R}^{|\mathcal{V}_{r}|\times d_{\mathcal{L}}}\,b_{t}\,\in\,\mathbb{R}^{|\mathcal{V}_{r}|} Wt∈R∣Vr∣×dLbt∈R∣Vr∣为可训练参数
Entity Head
- 为预测三元组中实体的边界, Q e Q_e Qe和token表示 H \mathrm{H} H经过FFN变换。
H s = H W s {{H_{s}=H W_{s}}} Hs=HWs
l c r E δ = Q e W δ {l c r}{{E_{\delta}=Q_{e}W_{\delta}}} lcrEδ=QeWδ
-
其中 δ ∈ C → { l s u b , r s u b , l o b j , r o b j } \delta\in C\to\{l_{s u b},r_{s u b},l_{o b j},r_{o b j}\} δ∈C→{lsub,rsub,lobj,robj}标识为宾语和主语的左右边界, W δ , W s ⊆ R d × d {\mathcal{W}}_{\delta,}\mathcal{W}_{s}\subseteq\mathrm{\mathbb{R}}^{d\times d} Wδ,Ws⊆Rd×d为可训练参数。
-
用余弦相似度 S ( ⋅ ) S(·) S(⋅)衡量Entity Query生成的新表示 E δ E_\delta Eδ和原文表示 H s H_s Hs之间的相似得分:
S ( v i , v j ) = v i ∣ v i ∣ ⋅ v j ∣ v j ∣ S\left(\mathbf{v}_{i},\mathbf{v}_{j}\right)={\frac{\mathbf{v}_{i}}{\left|\mathbf{v}_{i}\right|}}\cdot{\frac{\mathbf{v}_{j}}{\left|\mathbf{v}_{j}\right|}} S(vi,vj)=∣vi∣vi⋅∣vj∣vj -
根据得分,使用Softmax就得到第i个Entity Query对应的边界Token是第j个Token的概率: P i j δ = exp S ( E δ i , H s j ) ∑ j ′ exp S ( E δ i , H s j ′ ) n P_{i j}^{\delta}=\frac{\exp S\left(E_{\delta}^{i},H_{s}^{j}\right)}{\sum^n_{j^{\prime}\exp S\left(E_{\delta}^{i},H_{s}^{j^{\prime}}\right)}} Pijδ=∑j′expS(Eδi,Hsj′)nexpS(Eδi,Hsj),n为Token的数量
通过Relation Head可以获得Instance Query Q对应的三元组关系类型C,通过Entity Head可以用相似度得到三元组中Subject和Object的左右边界,确定Query对应的三元组
Instance Discriminator
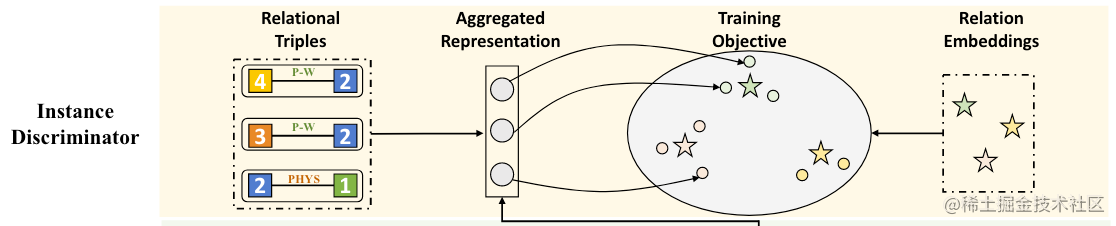
在Instance Discriminator中, 作者希望把预测头中得到的表示进一步聚合, 当做最初的三元组表示, 并在空间中使这些三元组表示满足某种约束, 来建立三元组之间的全局链接, 并且让它们具有类别语义信息.
Aggregation
用关系头表示 Q r Q_r Qr,然后相加到一起,聚合成三元组的初始表示: v = Q r W + ∑ δ ∈ C E δ \displaystyle\mathbf{v}=Q_{r}W+\sum_{\delta\in C}E_{\delta} v=QrW+δ∈C∑Eδ.
对 Q r Q_r Qr做变换是为了和Entity Head对其,因为 E δ E_\delta Eδ是由 Q e Q_e Qe变换一次得来的
Traning Objective
对于关系集 R = { r 1 , … , r ∣ γ r ∣ } \mathrm{R} = \{r_1, \dots,r_{|\gamma_r|} \} R={r1,…,r∣γr∣},对每个关系都随机初始化的Realation Type Embedding,作为关系的表示。
作者希望三元组实例和关系嵌入在空间中满足下述两个特点:
- 对于三元组实例和实例之间, 应满足同关系内更近, 不同关系的更远.
- 对于三元组实例和关系之间, 应满足三元组和自身关系对应的关系嵌入更近.
对比学习就是做这个的, 所以作者使用InfoNCE来建模上述两个要求.
对于第一个特点, 同关系三元组更近, 不同关系三元组更远:
其中 ( v i c , v j c ) (v_i^c,v_j^c) (vic,vjc)表同种关系类型c下的实例对。
与之类似的, 第二个特点要求三元组和自身对应的关系更近:
其中 v j c v_j^c vjc是关系c的三元组实例, r c ∈ R r_c\in\mathrm{R} rc∈R是关系c对应的Relation Embedding。
综上,建立了关系之间的语义信息,而不是让不同关系独立学习,使得不同关系之间具有全局链接
Training and Inference
Training
记三元组预测 Loss L t r i L_{t r i}\; Ltri为每个Instance Query自身岁对应的最优匹配三元组的关系类型预测交叉熵和头尾实体左右边界和交叉熵之和:
M为Query的数量, σ \sigma σ为最优匹配的三元组。
最终的Loss为前面提到的对比学习的Loss和三元组预测Loss之和:
Inference
在推理时:

Experiments
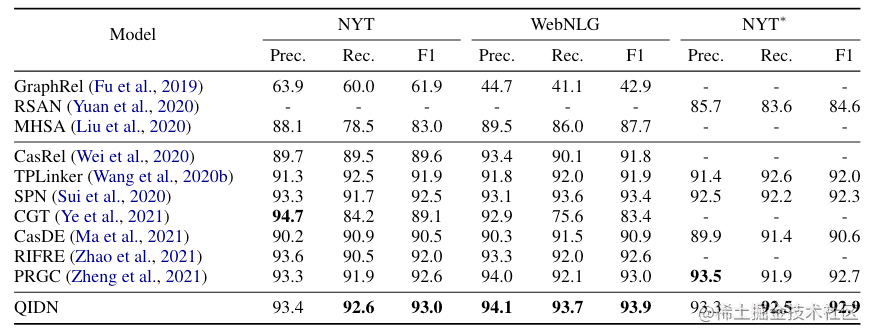
QIDN在RTE三个数据集NYT, WebNLG*, NYT* 上结果如下:
QIDN在NYT*和WebNLG*复杂场景表现如下:
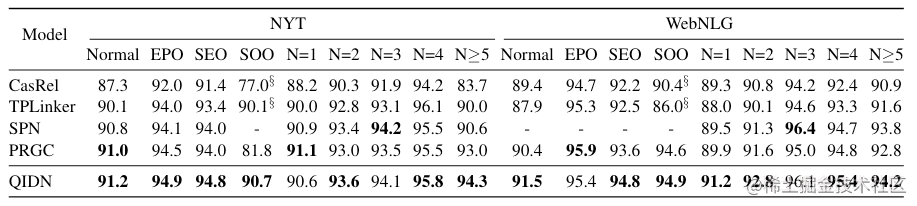
根据Baseline来看, QIDN对于三元组数量比较多的情况似乎比较擅长, 有比较明显的提升, 对于一般三元组的情况抽取进步也比较大.
总结心得
使用CV中的DETR的query embeddings的思想用于NLP之中,在全局的角度上,把各个关系之间的含义链接了起来,最后,将实例归类,每个类之间的三元组雷同。
参考文章
- QIDN: Query-based Instance Discrimination Network for Relational Triple Extraction | DaNing的博客 (adaning.github.io)
- 深度学习基础-基于Numpy的前馈神经网络(FFN)的构建和反向传播训练 - LeonYi - 博客园 (cnblogs.com)
- 一文读懂Embedding的概念,以及它和深度学习的关系 - 知乎 (zhihu.com)
- ChatGPT | OpenAI
这篇关于[实体关系抽取|顶刊论文]QIDN:Query-based Instance Discrimination Network for Relational Tri的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




