本文主要是介绍中文电子病例命名实体识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
中文电子病例命名实体识别
CCKS2017中文电子病例命名实体识别项目,主要实现使用了基于字向量的四层双向LSTM与CRF模型的网络.该项目提供了原始训练数据样本(一般醒目,出院情况,病史情况,病史特点,诊疗经过)与转换版本,训练脚本,预训练模型,可用于序列标注研究.
电子病历结构化是让计算机理解病历、应用病历的基础。基于对病历的结构化,可以计算出症状、疾病、药品、检查检验等多个知识点之间的关系及其概率,构建医疗领域的知识图谱,进一步优化医生的工作. CCKS2018的电子病历命名实体识别的评测任务,是对于给定的一组电子病历纯文本文档,识别并抽取出其中与医学临床相关的实体,并将它们归类到预先定义好的类别中。组委会针对这个评测任务,提供了600份标注好的电子病历文本,共需识别含解剖部位、独立症状、症状描述、手术和药物五类实体。 领域命名实体识别问题自然语言处理中经典的序列标注问题, 本项目是运用深度学习方法进行命名实体识别的一个尝试.
实验数据:
一, 目标序列标记集合 O非实体部分,TREATMENT治疗方式, BODY身体部位, SIGN疾病症状, CHECK医学检查, DISEASE疾病实体
二, 序列标记方法 采用BIO三元标记
三, 数据转换 评测方提供了四个目录(一般项目, 出院项目, 病史特点, 诊疗经过),四个目录下有txtoriginal文件和txt标注文件
模型搭建:
本模型使用预训练字向量,作为embedding层输入,然后经过两个双向LSTM层进行编码,编码后加入dense层,最后送入CRF层进行序列标注.
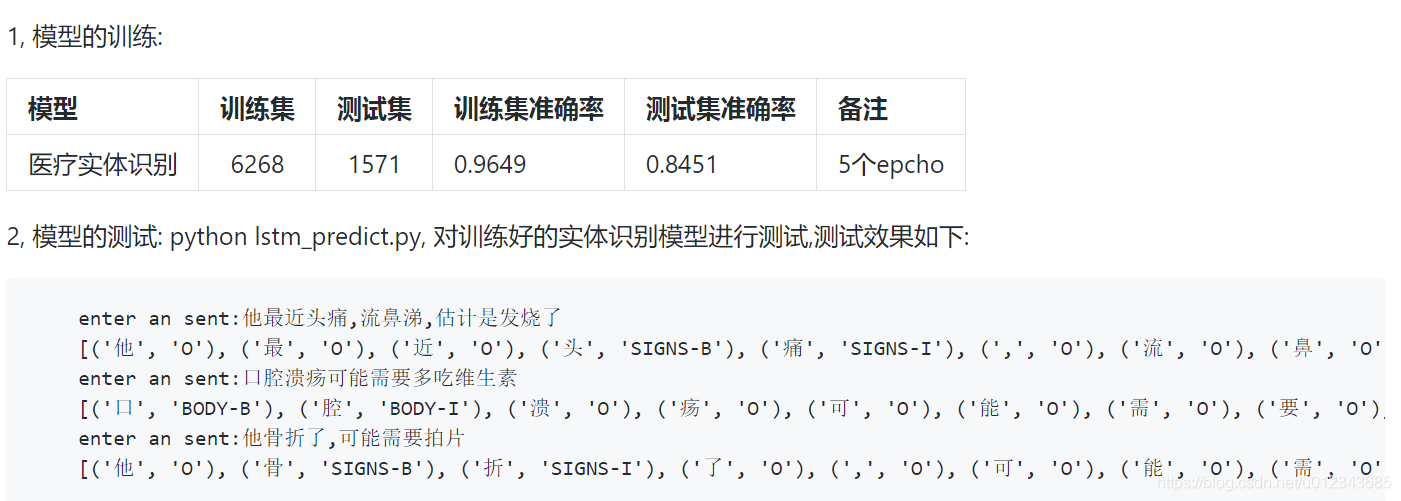
模型效果:
总结:
1,本项目针对中文电子病例命名实体任务,实现了一个基于Bilstm+CRF的命名实体识别模型
2,本项目使用charembedding作为原始特征,训练集准确率为0.9649,测试集准确达到0.8451
3,命名实体识别可以加入更多的特征进行训练,后期将逐步实验其他方式.
这篇关于中文电子病例命名实体识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






