本文主要是介绍.net爬虫使用HtmlAgilityPack爬取网络数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、HtmlAgilityPack是什么?
- 二、使用步骤
- 1.引入库
- 2.HtmlAgilityPack语法
- 总结
前言
最近在研究python爬虫,发现没有网上传的那么神奇,其实也只是python中爬虫类库比较丰富,其中的的request、json、selenium这些爬虫类库,.net也是有的,并且实现也不是很困难(本人还是很倾向C#/net的毕竟开发启蒙语言是这个)所以本文简单介绍下.net爬虫。这里在开始之前先看下我用爬虫爬取电影数据后做的网站
爬取数据后的演示地址:北辰
使用工具及框架
开发工具:VS2019
框架:简单三层:Model,BLL,DAL
一、HtmlAgilityPack是什么?
HtmlAgilityPack是.net下开源的免费类库,他的优点是可以将html文档解析成可以用xpath语法(即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力),简单点说就是可以像操作xml文档那样操作html。
二、使用步骤
1.引入库
首先在VS2019中安装HtmlAgilityPack
工具--》NuGet--》下载HtmlAgilityPack
2.HtmlAgilityPack语法
1、获取网页title:doc.DocumentNode.SelectSingleNode("//title").InnerText; 解释:XPath中“//title”表示所有title节点。SelectSingleNode用于获取满足条件的唯一的节点。
2、获取所有的超链接:doc.DocumentNode.Descendants("a")
3、获取name为kw的input,也就是相当于getElementsByName():
var kwBox = doc.DocumentNode.SelectSingleNode("//input[@name='kw']");
解释:"//input[@name='kw']"也是XPath的语法,表示:name属性等于kw的input标签。
//li/h3/a[@href]:所有li下面的h3包含a超级链接有href属性才符合。有的a可能是支持的js事件
//div[starts-with(@class,'content_single')]:所有符合条件的div,并且它的class是由字符串content_single 开头的
注意路径里"//"表示从根节点开始查找,两个斜杠‘//’表示查找所有childnodes;一个斜杠'/'表示只查找第一层的childnodes(即不查找grandchild);点斜杠"./"表示从当前结点而不是根结点开始查找
3.开始代码
//因为要用到HttpRequest请求页面,所以这里设置了请求的头部信息useragents,可以让服务器以为这是浏览器发起的请求。
private readonly string[] usersagents = new string[] {"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","JUC (Linux; U; 2.3.7; zh-cn; MB200; 320*480) UCWEB7.9.3.103/139/999","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:7.0a1) Gecko/20110623 Firefox/7.0a1 Fennec/7.0a1","Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10","Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13","Mozilla/5.0 (iPhone; U; CPU iPhone OS 3_0 like Mac OS X; en-us) AppleWebKit/420.1 (KHTML, like Gecko) Version/3.0 Mobile/1A542a Safari/419.3","Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_0 like Mac OS X; en-us) AppleWebKit/532.9 (KHTML, like Gecko) Version/4.0.5 Mobile/8A293 Safari/6531.22.7","Mozilla/5.0 (iPad; U; CPU OS 3_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Version/4.0.4 Mobile/7B334b Safari/531.21.10","Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+","Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0","Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124","Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36","Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10","Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER) ","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36","Mozilla/5.0 (Linux; U; Android 2.2.1; zh-cn; HTC_Wildfire_A3333 Build/FRG83D) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+","Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)","Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999","Openwave/ UCWEB7.0.2.37/28/999","NOKIA5700/ UCWEB7.0.2.37/28/999","UCWEB7.0.2.37/28/999","Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0","Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13","Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10","Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",};private void btn_TestConnect_Click(object sender, EventArgs e){//这里使用委托的方式防止阻塞UI线程Action<int> downImg = DownAllPageImg;downImg.BeginInvoke(int.Parse(numStartPage.Value.ToString()), null, null);}
public void DownAllPageImg(int StartPage){int i = StartPage;int continueNum = 1;//我这里使用的是WinForm模式开发的,这句话意思是可以跨线程访问,即当前线程可以访问UI线程。CheckForIllegalCrossThreadCalls = false;while (true){//设置从第几页开始爬取txtBeginPage.Text = i.ToString();i++;try{HttpWebRequest request = null;HttpWebResponse response = null;Stream stream = null;StreamReader reader = null;var url = string.Empty;string result = string.Empty;Encoding encoding = Encoding.Default;if (i == 1){url = "http://vipshipin.vip/";}else{url = "http://vipshipin.vip/index/" + i;}//请求地址request = (HttpWebRequest)WebRequest.Create(url);//随机使用一个useragentsvar randomNumber = random.Next(0, usersagents.Length);request.UserAgent = usersagents[randomNumber];request.Timeout = 30000;request.ServicePoint.Expect100Continue = false;request.KeepAlive = false;response = (HttpWebResponse)request.GetResponse();if (response.StatusCode == HttpStatusCode.OK){using (stream = response.GetResponseStream()){reader = new StreamReader(stream);result = reader.ReadToEnd();stream.Close();//这里就使用HtmlAgilityPack来解析request请求返回的HTMLHtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();doc.LoadHtml(result);//这里的意思是获取所有div的class='col-sm-2 col-xs-6 fix'的节点var node = doc.DocumentNode.SelectNodes("//div[@class='col-sm-2 col-xs-6 fix']");if (node == null){continueNum++;if (continueNum > 3){break;}continue;}//查询node节点div所有子节点var titleA0 = node.Select(x => x.ChildNodes);//集合中的每一个都返回第一个符合条件的 此处返回所有a标签的属性var ttc = titleA0.Select(x => x.First(z => z.Name == "a"));List<movies_tb> moviesList = new List<movies_tb>();List<string> imgList = new List<string>();foreach (var item in ttc){var title = item.Attributes.Where(x => x.Name == "title").FirstOrDefault().Value;var oldidstr = item.Attributes.Where(x => x.Name == "href").FirstOrDefault().Value;//两段字符之间的id号例如:https://www.vipshipin.vip/156466.html 获取156466var oldidint = int.Parse(oldidstr.Substring(oldidstr.LastIndexOf('/') + 1, oldidstr.LastIndexOf('.') - oldidstr.LastIndexOf('/') - 1));//简单三层判断id是否存在,若存在则跳过if (bllMovie.ExistsOldId(oldidint)){continue;}else{var imgsrc = "http:" + item.SelectNodes("img").FirstOrDefault().Attributes.Where(x => x.Name == "data-original").FirstOrDefault().Value;//这里添加图片var by02= ImgPath(imgsrc);moviesList.Add(new movies_tb { title = title, oldid = oldidint, imgsrc = imgsrc,by_02= by02 });imgList.Add(imgsrc);FileStream fs = new FileStream(noimglog, FileMode.Append);StreamWriter sw = new StreamWriter(fs);sw.WriteLine("page"+i);sw.Close();}}List<CommandInfo> cmdList = Common.GetAllSQLWithParamers(moviesList);SpiderFormMovieSite.BLL.movies_tb moviesBll = new SpiderFormMovieSite.BLL.movies_tb();//开启线程工程,创建线程,第一个是执行sql插入从中,第二个是下载所有图片,下载图片的方法也是用HttpRequest请求下载地址然后保存图片Task.WaitAll(new Task[] {Task.Factory.StartNew(() => moviesBll.ExecuteSqlTran(cmdList)),Task.Factory.StartNew(() => DownLoadAllImg(imgList))});//Thread.Sleep(5000);reader.Close();stream.Close();response.Close();}response.Close();}}catch (Exception){throw;}}}上面代码中的下面几句,就是利用HtmlAgilityPack将html文档实例化成htmlDom
//这里就使用HtmlAgilityPack来解析request请求返回的HTML
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(result);
//这里的意思是获取所有div的class='col-sm-2 col-xs-6 fix'的节点
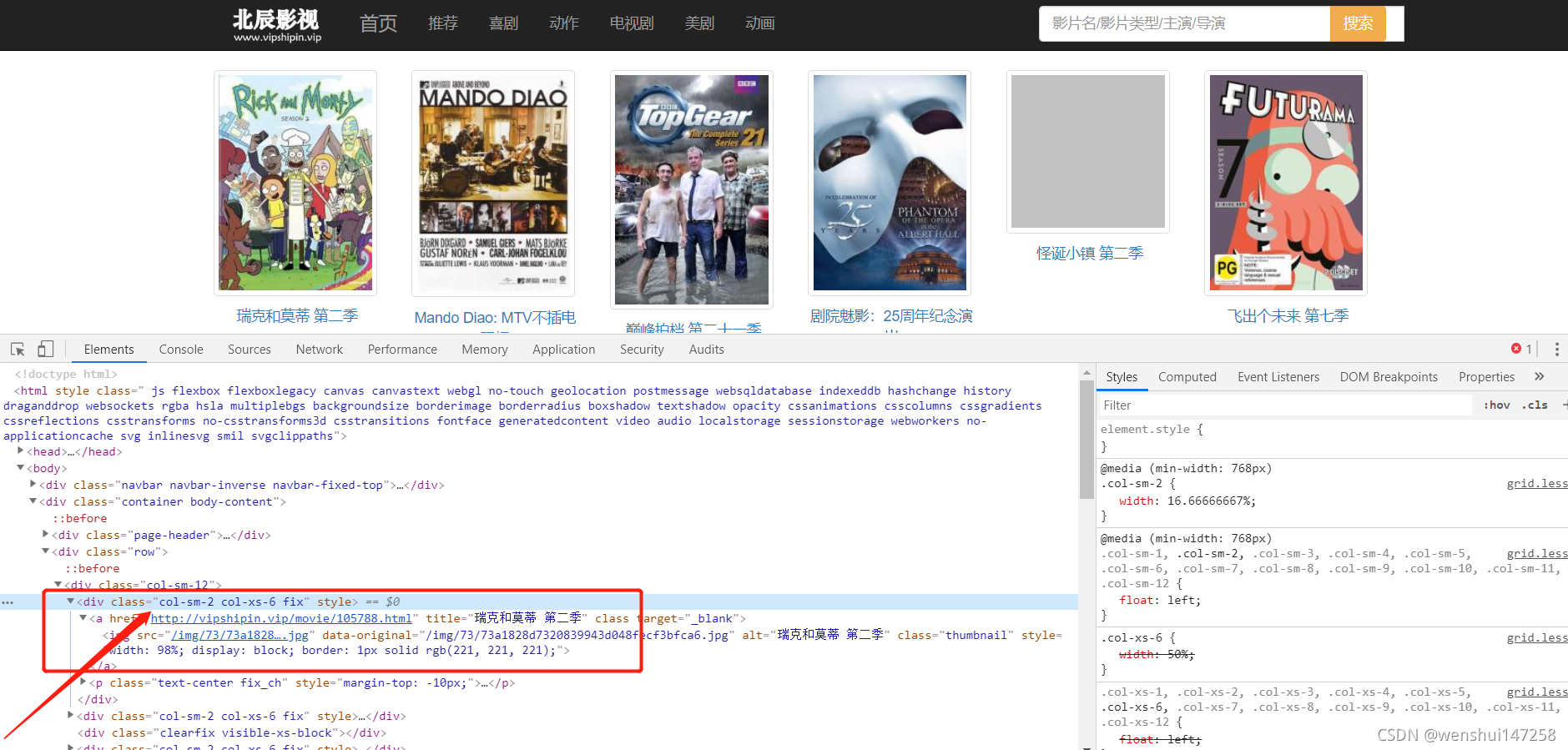
var node = doc.DocumentNode.SelectNodes("//div[@class='col-sm-2 col-xs-6 fix']");var node = doc.DocumentNode.SelectNodes("//div[@class='col-sm-2 col-xs-6 fix']");
这句话的意思就是从html根目录下找到所有div 中class='col-sm-2 col-xs-6 fix' 的节点即为下面的图片:
这样页面中所有的链接和图片资源都可以找到了
//获取标题
var title = item.Attributes.Where(x => x.Name == "title").FirstOrDefault().Value;
然后将获取的数据进行提取,将所需的电影名称和图片保存到本地:
//开启线程工程,创建线程,第一个是执行sql插入从中,第二个是下载所有图片,下载图片的方法也是用HttpRequest请求下载地址然后保存图片Task.WaitAll(new Task[] {Task.Factory.StartNew(() => moviesBll.ExecuteSqlTran(cmdList)),Task.Factory.StartNew(() => DownLoadAllImg(imgList))});这里创建线程一个去执行将所有字段插入数据库,第二个执行DownLoadAllImg就是下载当前页面所有的图片保存到本地的操作,这个方法也是先用HttpRequest将图片地址请求到,然后用文件流将文件保存到本地。
1.利用HttpRequest先请求网站,获取返回后的html
2.利用HtmlAgilityPack将html变成和操作xpath语法一样的操作,基本操作为:
2.1、获取网页title:doc.DocumentNode.SelectSingleNode("//title").InnerText; 解释:XPath中“//title”表示所有title节点。SelectSingleNode用于获取满足条件的唯一的节点。
2.2、获取所有的超链接:doc.DocumentNode.Descendants("a")
2.3、获取name为kw的input,也就是相当于getElementsByName(): var kwBox = doc.DocumentNode.SelectSingleNode("//input[@name='kw']");
解释:"//input[@name='kw']"也是XPath的语法,表示:name属性等于kw的input标签。
//li/h3/a[@href]:所有li下面的h3包含a超级链接有href属性才符合。有的a可能是支持的js事件
//div[starts-with(@class,'content_single')]:所有符合条件的div,并且它的class是由字符串content_single 开头的
/Articles/Article[1]:选取属于Articles子元素的第一个Article元素。
/Articles/Article[last()]:选取属于Articles子元素的最后一个Article元素。
/Articles/Article[last()-1]:选取属于Articles子元素的倒数第二个Article元素。
/Articles/Article[position()<3]:选取最前面的两个属于 bookstore 元素的子元素的Article元素。
//title[@lang]:选取所有拥有名为lang的属性的title元素。
//CreateAt[@type='zh-cn']:选取所有CreateAt元素,且这些元素拥有值为zh-cn的type属性。
/Articles/Article[Order>2]:选取Articles元素的所有Article元素,且其中的Order元素的值须大于2。
/Articles/Article[Order<3]/Title:选取Articles元素中的Article元素的所有Title元素,且其中的Order元素的值须小于3。
3.插入数据,保存图片。
这篇关于.net爬虫使用HtmlAgilityPack爬取网络数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







