agilitypack专题

C#中使用HtmlAgilityPack对html进行解析
xpath一般使用在xml的解析上比较多,实际上html是xml的一个子集。在.Net中为了方便我们对html进行操作微软为我们提供了一个轻量级并且开源的类库HtmlAgilityPack(点击下载)。比如我们想截取网页上某一部分文字获取其他元素的时候我们一般都是使用正则表达式一步一步的来进行处理的,这个过程相当的繁琐特别是对正则表达式不熟悉的情况,通过HtmlAgilityPack这个
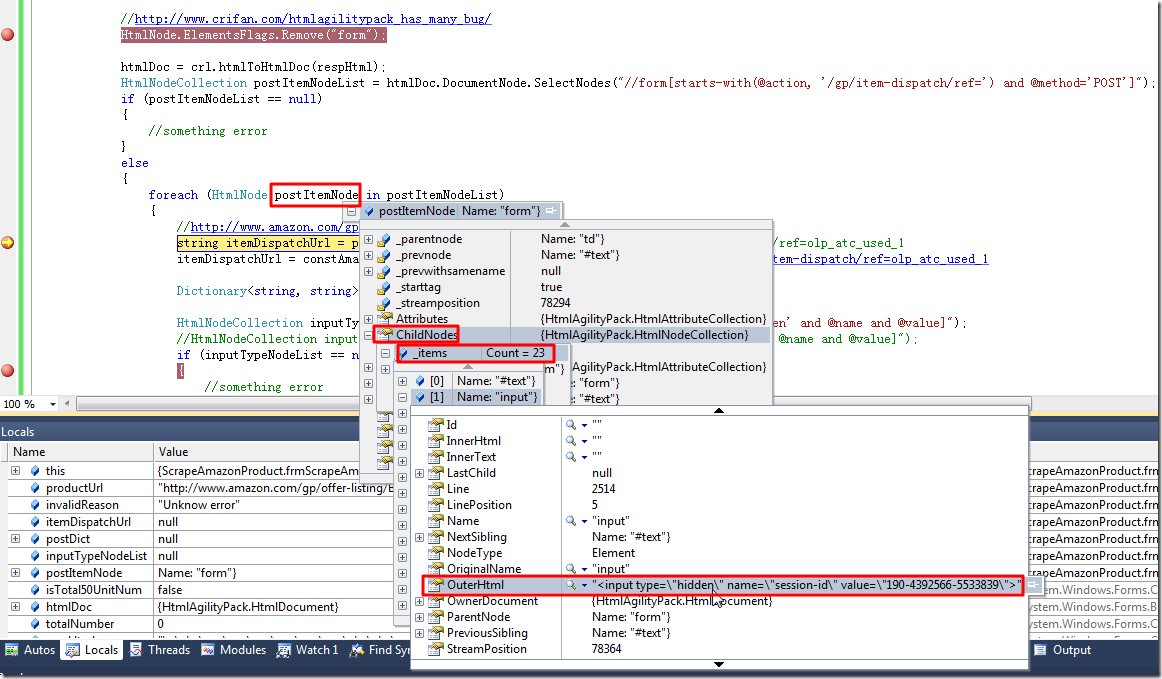
HtmlAgilityPack中通过sibling才能得到对应的InnerText和form,option等tag的子节点
转自:http://www.crifan.com/htmlagilitypack_html_tag_form_option_no_child_via_sibling_get_innertext/ 最近在用HtmlAgilityPack解析HTML文件,用到的很奇怪的问题,这篇文章给了很详细解释和标准答案,收藏一下! 【背景】 之前使用HtmlAgilityPack期

C#通过HtmlAgilityPack轻松解析HTML
(时间紧张,任务繁重,未完待续……有时间我就回来继续翻译) 这是一篇译文,你没看错,走过路过不要错过,一个英语渣的心塞翻译。 原文在这里Easily Parse HTML Documents in C# C#轻松解析HTML通过HtmlAgilityPack原文 Easily Parse HTML Documents in C#. HtmlAgilityPackBasic Pars
C# 使用HtmlAgilityPack解析提取HTML内容
写在前面 HtmlAgilityPack是一个HTML解析类库,日常用法就是爬虫获取到内容后,先用XPath获取目标节点,再用正则进行匹配;使用XPath的目的主要是将目标节点或内容限定在一个较小的范围,如果一上来就用正则那效率肯定不行,因为正则的规则设计耗时较长;而XPath直接可以用浏览器F12开发者工具窗口,鼠标右键复制XPath获得,非常方便。但在微观内容的操作上XPath就显得太粗
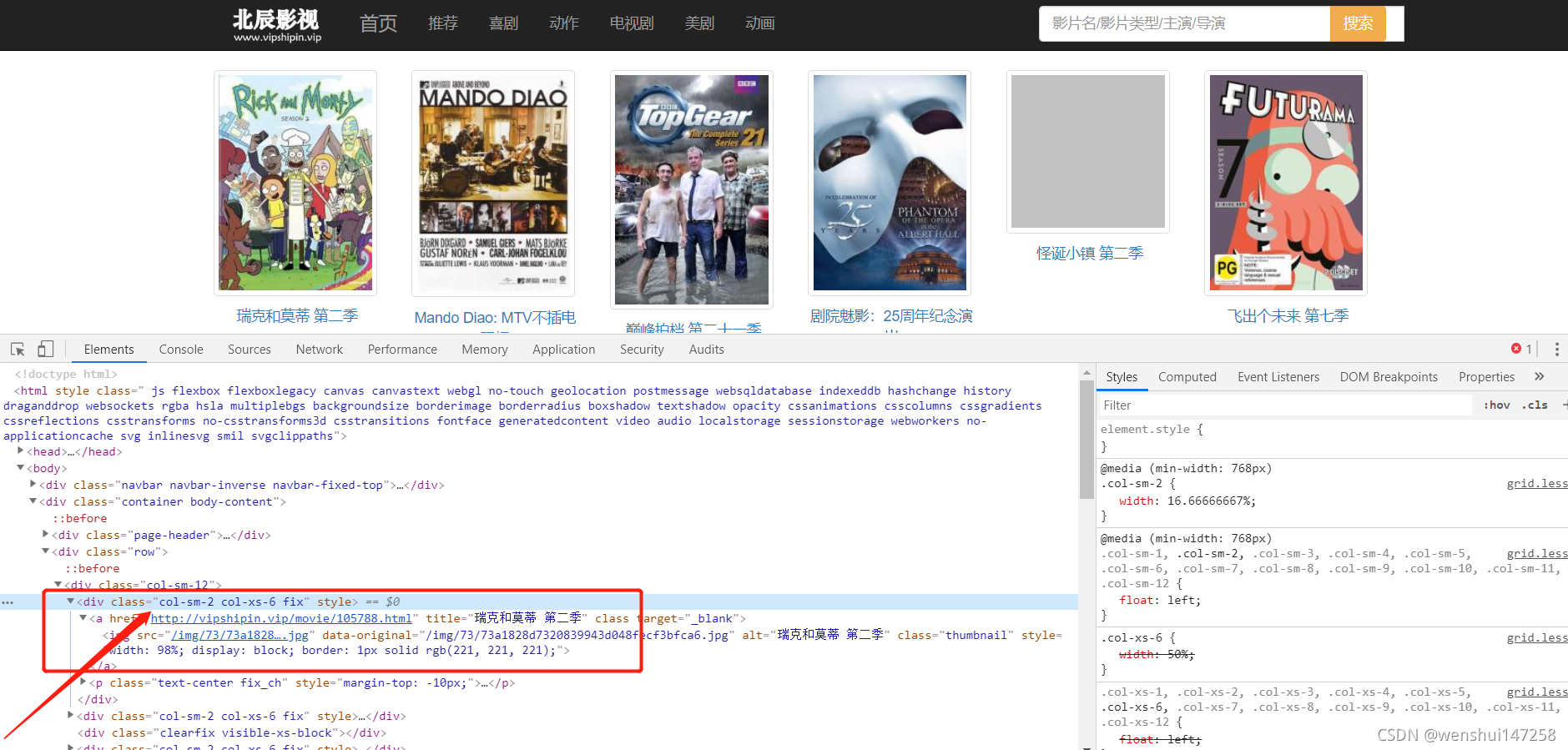
.net爬虫使用HtmlAgilityPack爬取网络数据
文章目录 前言一、HtmlAgilityPack是什么?二、使用步骤 1.引入库2.HtmlAgilityPack语法总结 前言 最近在研究python爬虫,发现没有网上传的那么神奇,其实也只是python中爬虫类库比较丰富,其中的的request、json、selenium这些爬虫类库,.net也是有的,并且实现也不是很困难(本人还是很倾向C#/net的毕竟开发启蒙语言是这个
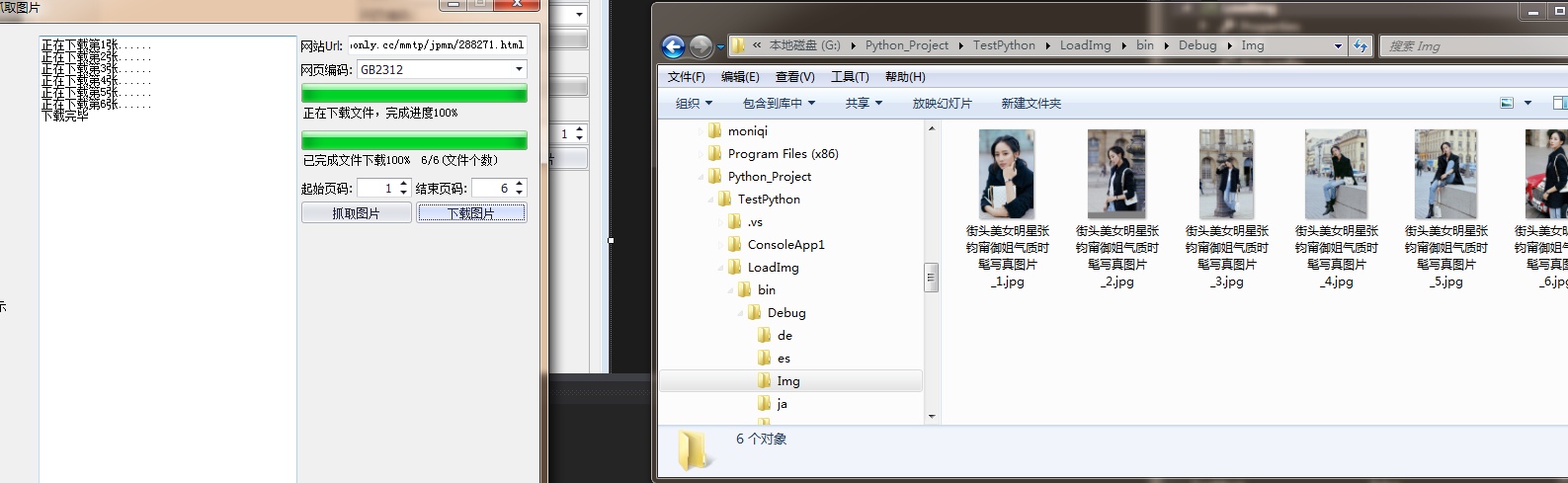
利用HtmlAgilityPack插件写的一个抓取指定网页的图片 第一次写 很乱 随便看看就行...
public partial class Form1 : Form { /// <summary> /// 存放图片地址 /// </summary> List<string> ImgList = new List<string>(); /// <summary> /// 当前下载文件 /// </summary> int _loadFile = 0; //图片标题 string title
HtmlAgilityPack使用(二)【爬取每日一文】
Program.cs代码: using HtmlAgilityPack;using System;using System.IO;using System.Linq;namespace MyDemo{class Program{static void Main(string[] args){for (int i = 0; i < 100; i++){var url = "https: