本文主要是介绍【博弈】非完全信息博弈基础与CFR算法简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
非完全信息博弈基础
0 非完全信息扩展式博弈
信息集:玩家无法区分的博弈状态集合,在这些状态下可选择的动作必须遵循同一分布。
有限的非完全信息扩展式博弈 < N , H , P , f c , I i , u i > <N, H, P, f_{c}, I_{i}, u_{i}> <N,H,P,fc,Ii,ui>
- 参与者集合 N N N: N = { c , 1 , 2 , … , n } N=\{\mathrm{c}, 1,2, \ldots, \mathrm{n}\} N={c,1,2,…,n}, c c c 为机会玩家,其余为普通玩家。
- 博弈状态集合 H H H:每个博弈状态 h ∈ 𝐻 ℎ∈𝐻 h∈H 由动作的历史序列组成,即从根节点到当前决策节点的路径中经过的决策的序列(有序集)。在根节点处序列为空,ℎ的所有前缀序列也属于 𝐻 𝐻 H。 𝑍 ⊆ 𝐻 𝑍⊆𝐻 Z⊆H 是博弈终止状态集合,代表博弈结束胜负已分。 A ( h ) = a : h . a ∈ H A(h)={a:h.a∈H} A(h)=a:h.a∈H 为在非终止状态 h ∈ 𝐻 ℎ∈𝐻 h∈H 处可供选择的合法动作集合,其中, h . 𝑎 ℎ.𝑎 h.a 代表在 h ℎ h 状态处选择动作 𝑎 𝑎 a 后能到达的状态。显然,在 𝑍 𝑍 Z 处没有可选择的动作。
- 决策者函数 P P P:函数 𝑃 𝑃 P 为每个非终止状态分配一个决策玩家。 P ( h ) = i P(h)=i P(h)=i 代表在博弈状态 h ℎ h 处做出决策的玩家为 𝑖 𝑖 i。如果 P ( h ) = c P(h)=c P(h)=c,此时在博弈状态 h ℎ h 处做出决策的玩家为机会玩家。
- 机会概率分布 f c f_c fc:如果状态 h h h 处做出决策的玩家是机会玩家 c c c,那么 c c c 选择的动作的概率分布服从于 f c f_c fc。
- 信息集 I i I_i Ii:一个信息集是 H H H 的子集,当其他玩家通过观测历史 h h h 时,只知道玩家处于集合 I I I 上,但是并不清楚该玩家具体在 I I I 的哪一个状态上。每个玩家的所有信息集组成一个信息分割。对于每个玩家 i ∈ N i \in N i∈N 都存在一个信息分割, I i = { I i ∣ I i ⊂ H , P ( I i ) = i } \mathcal{I}_{i}=\left\{I_{i}\right.\left.\mid I_{i} \subset H, P\left(I_{i}\right)=i\right\} Ii={Ii∣Ii⊂H,P(Ii)=i}。信息集 I i I_i Ii 中的状态 h , h ′ ∈ I i h,h^{'} \in I_i h,h′∈Ii 是不可区分的,且有 A ( h ) = A ( h ′ ) A(h) = A(h^{'}) A(h)=A(h′)。
- 收益函数 μ i \mu_i μi:对于玩家 i ∈ N i \in N i∈N,收益函数 μ i : Z → R \mu_i :Z \rightarrow R μi:Z→R 在终止状态 Z Z Z 处根据结局输赢为玩家 { 1 , 2 , … , N } \{1,2, \ldots, N\} {1,2,…,N} 分配各自的收益。
1 博弈策略
在完全信息博弈中,策略是限制在博弈状态中的,它规定了在每个博弈状态下玩家选择合法动作的概率;在非完全信息博弈中,策略与信息集有关,玩家在不同信息集上进行决策。
定义:对于玩家 i i i 来说,当他处于信息集 I i I_i Ii 时,他在动作集合 A ( I i ) A(I_i) A(Ii) 中选择的动作的概率分布遵循策略 σ i \sigma_i σi。用 ∑ i \sum_{i} ∑i 来表示玩家 i i i 的策略空间。一个策略组 σ \sigma σ 包含了每个玩家的策略, σ = { σ 1 , σ 2 , … , σ n } \sigma = \left\{\sigma_{1}, \sigma_{2}, \ldots, \sigma_{n}\right\} σ={σ1,σ2,…,σn}。 σ − i \sigma_{-i} σ−i 表示策略组中除了策略 σ i \sigma_i σi 之外的所有策略。
令 π σ ( h ) \pi^{\sigma}(h) πσ(h) 表示如果所有玩家根据策略组 Font metrics not found for font: . 来选择动作,能到达状态 h ℎ h 处的概率。可将 π σ ( h ) \pi^{\sigma}(h) πσ(h) 分解为每个玩家对于能够到达状态 h h h 处所做的贡献,即 π i σ ( h ) = ∏ i ∈ N ∪ { c } π i σ ( h ) \pi_{i}^{\sigma}(h)=\prod_{i \in N \cup\{c\}} \pi_{i}^{\sigma}(h) πiσ(h)=∏i∈N∪{c}πiσ(h)。用 Font metrics not found for font: . 来表示当所有玩家都根据策略组 Font metrics not found for font: . 来行动时,在已经到达状态 𝑔 𝑔 g 的前提下,到达状态 h ℎ h 处的概率。由此得到,玩家 𝑖 𝑖 i 在依据策略组 Font metrics not found for font: . 来行动时,在终止节点处所得到的的整体收益为 u i ( σ ) = ∑ h ∈ Z u i ( h ) π σ ( h ) u_{i}(\sigma)=\sum_{h \in Z} u_{i}(h) \pi^{\sigma}(h) ui(σ)=∑h∈Zui(h)πσ(h)。
平均策略:假定在 T T T 次博弈过程中,参与者 i i i 在第 t t t 次博弈所使用的策略为 σ i t \sigma_i^t σit,那么平均策略 σ ˉ i T = 1 T ∑ t = 1 T σ i t \bar{\sigma}_{i}^{T}=\frac{1}{T} \sum_{t=1}^{T} \sigma_{i}^{t} σˉiT=T1∑t=1Tσit 是策略 σ i 1 , σ i 2 , … , σ i T \sigma_{i}^{1}, \sigma_{i}^{2}, \ldots, \sigma_{i}^{T} σi1,σi2,…,σiT 在每个信息集 I I I 上概率 σ i t ( I ) \sigma_{i}^{t}(I) σit(I) 的简单加权平均。
最佳反应(best response,BR)策略:如果玩家 i i i 的对手策略组保持不变,那么玩家 i i i 可以在策略空间 ∑ i \sum_{i} ∑i 中寻找一个最大化自身收益的策略。给定一个策略组 σ = ( σ 1 , σ 2 , … , σ n ) \sigma=\left(\sigma_{1}, \sigma_{2}, \ldots, \sigma_{n}\right) σ=(σ1,σ2,…,σn), μ i ( σ ) \mu_i(\sigma) μi(σ) 表示在策略组 σ \sigma σ 下参与者 i i i 的期望收益,当对手策略组是 σ − i \sigma_{-i} σ−i 时,参与者 i i i 为应对 σ − i \sigma_{-i} σ−i 所选择的最佳反应策略 B R ( σ − i ) BR(\sigma_{-i}) BR(σ−i) 为:
B R ( σ − i ) = argmax σ i ′ u i ( σ i ′ , σ − i ) B R\left(\sigma_{-i}\right)=\operatorname{argmax}_{\sigma_{i}^{\prime}} u_{i}\left(\sigma_{i}^{\prime}, \sigma_{-i}\right) BR(σ−i)=argmaxσi′ui(σi′,σ−i)
纳什均衡:对于所有博弈方而言,只要其他人不做出改变,那么每个博弈方都不可能通过改变己方当前所选择的策略,而达到比现在更高的收益目标。纳什均衡是当所有参与者的策略都是最佳反应策略时的策略组 σ i ∗ \sigma_i^* σi∗:
∀ i , u i ( σ i ∗ , σ − i ∗ ) = max σ i ′ ∈ Σ i u i ( σ i ′ , σ − i ∗ ) \forall i, u_{i}\left(\sigma_{i}^{*}, \sigma_{-i}^{*}\right)=\max _{\sigma_{i}^{\prime} \in \Sigma_{i}} u_{i}\left(\sigma_{i}^{\prime}, \sigma_{-i}^{*}\right) ∀i,ui(σi∗,σ−i∗)=σi′∈Σimaxui(σi′,σ−i∗)
可利用度(Exploitability):衡量某一个策略与纳什均衡策略的偏离程度。在二人零和博弈中,策略 σ i \sigma_i σi 的可利用度 e ( σ i ) e(\sigma_i) e(σi) 指当对手的策略是最佳反应策略 B R ( σ − i ) BR(\sigma_{-i}) BR(σ−i) 时,策略 σ i \sigma_i σi 跟纳什均衡策略相比,其劣势有多少:
e ( σ i ) = u i ( σ i ∗ , B R ( σ − i ∗ ) ) − u i ( σ i , B R ( σ − i ) ) e\left(\sigma_{i}\right)=u_{i}\left(\sigma_{i}^{*}, B R\left(\sigma_{-i}^{*}\right)\right)-u_{i}\left(\sigma_{i}, B R\left(\sigma_{-i}\right)\right) e(σi)=ui(σi∗,BR(σ−i∗))−ui(σi,BR(σ−i))
一个策略组的平均可利用度为 e ( σ ) / ∣ N ∣ e(\sigma) /|N| e(σ)/∣N∣。若 e ( σ ) / ∣ N ∣ < ϵ e(\sigma) /|N|<\epsilon e(σ)/∣N∣<ϵ,则称 σ \sigma σ 为 ϵ − 纳 什 均 衡 \epsilon-纳什均衡 ϵ−纳什均衡。
2 遗憾最小化与遗憾值匹配
根据对过去博弈中行为动作的遗憾程度来对将来动作进行选择
遗憾值:考虑 T T T 次重复博弈,令 σ i t \sigma_i^t σit 表示参与者 i i i 在第 t t t 次博弈过程中使用的策略,参与者 i i i 在第 T T T 次博弈后的 平均总体遗憾值 为:
R i T = 1 T max σ i ∗ ∈ Σ i ∑ t = 1 T ( u i ( σ i ∗ , σ − i t ) − u i ( σ t ) ) R_{i}^{T}=\frac{1}{T} \max _{\sigma_{i}^{*} \in \Sigma_{i}} \sum_{t=1}^{T}\left(u_{i}\left(\sigma_{i}^{*}, \sigma_{-i}^{t}\right)-u_{i}\left(\sigma_{t}\right)\right) RiT=T1σi∗∈Σimaxt=1∑T(ui(σi∗,σ−it)−ui(σt))
上式中, u u u 为收益函数。单次博弈的遗憾值是最佳应对策略与实际策略的收益的差值,它反应了没有采取最佳应对策略的遗憾程度。令 R i T , + = max ( 0 , R i T ) R_{i}^{T,+}=\max \left(0, \mathrm{R}_{i}^{T}\right) RiT,+=max(0,RiT),随着博弈次数 T T T 趋近于无穷大,若 R i T , + R_{i}^{T,+} RiT,+ 趋近于0,称之为 遗憾值最小化。
当一个算法通过选择策略 σ i t \sigma_i^t σit 使得参与者的平均总体遗憾值随着博弈次数 T T T 的增长而趋近于 0 时,称该算法为遗憾值最小化算法。在二人零和扩展式博弈问题中,使用遗憾值最小化算法并进行自我博弈,最终可以求解出近似的纳什均衡。
遗憾值匹配:正则博弈中的遗憾匹配是使遗憾最小化的简单的迭代过程。首先,我们随机选择策略 σ 1 \sigma^1 σ1,对于可选动作集 A i A_i Ai 中的每一个动作 a a a,我们计算并存储其遗憾值:
R i T ( a ) = ∑ t = 1 T ( μ i ( a , σ − i t ) − μ i ( σ i t , σ − i t ) ) R_{i}^{T}(a)=\sum_{t=1}^{T}\left(\mu_{i}\left(a, \sigma_{-i}^{t}\right)-\mu_{i}\left(\sigma_{i}^{t}, \sigma_{-i}^{t}\right)\right) RiT(a)=t=1∑T(μi(a,σ−it)−μi(σit,σ−it))
下一次迭代时候,我们采取的策略通过下式计算出:
σ i T + 1 ( a ) = R i T , + ( a ) ∑ b ∈ A i R i T , + ( b ) \sigma_{i}^{T+1}(a)=\frac{R_{i}^{T,+}(a)}{\sum_{b \in A_{i}} R_{i}^{T,+}(b)} σiT+1(a)=∑b∈AiRiT,+(b)RiT,+(a)
当分母为0时,随机选择下一个动作。最直观的理解就是我们会选择过去最让自己感到遗憾(后悔没有选的)动作。遗憾值匹配算法的流程图:
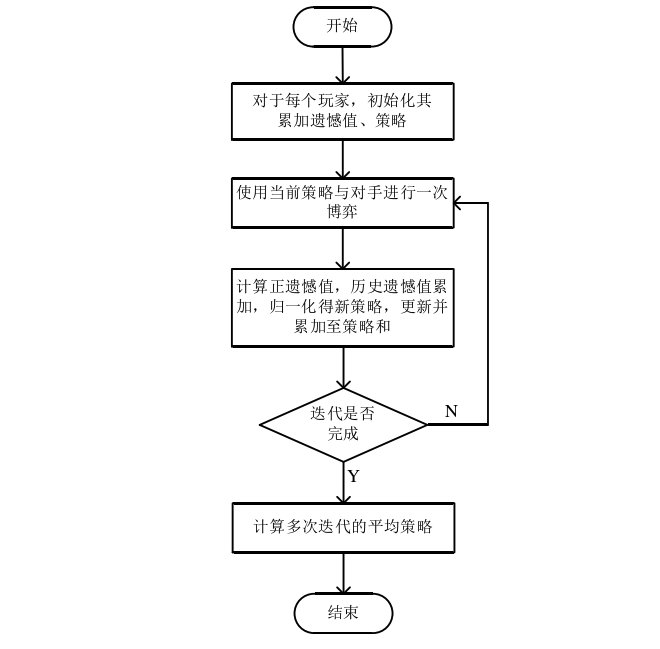
遗憾值最小化技术是通过计算平均 整体 最小遗憾(average overall regret)得到游戏中的行为策略,因此该技术 只致力于解决正则博弈游戏。在扩展式博弈游戏中,游戏状态是呈指数增长的,如最简单的2人限制性德州扑克扩展式游戏,都有着多达 1 0 17 10^{17} 1017 的游戏状态。首先要计算如此规模博弈树的整体最小遗憾是不切实际的,而且扩展式博弈是按次序做动作的,因而通过遗憾值最小化技术不能立即得到下一动作的可选策略。所以在扩展式博弈中Martin Zinkevich等人引进了虚拟遗憾(counterfactual regret)的概念。
3 虚拟遗憾最小化(CFR)
反事实遗憾,即虚拟遗憾,指故意地使玩家 i i i 的策略被限定在信息集 I i I_i Ii。CFR 算法通过多次迭代,将整体遗憾分解到各个独立的信息集中计算局部最小遗憾值。CFR 算法的形式化定义如下:
Z Z Z 表示博弈树中所有的叶子结点, z ∈ Z z \in Z z∈Z, h h h 表示博弈树中的非叶子结点, μ i ( z ) \mu_i(z) μi(z) 表示玩家 i i i 在叶子结点 z z z 的效用。定义在非叶子节点 h h h 处的 虚拟价值(counterfacter value):
v i ( σ , h ) = ∑ z ∈ Z , h ∉ z π − i σ ( h ) π σ ( h , z ) u i ( z ) v_{i}(\sigma, h)=\sum_{z \in Z, h \notin z} \pi_{-i}^{\sigma}(h) \pi^{\sigma}(h, z) u_{i}(z) vi(σ,h)=z∈Z,h∈/z∑π−iσ(h)πσ(h,z)ui(z)
在节点 h h h 处采用动作 a a a 的 虚拟遗憾值(counterfactual regret):
r ( h , a ) = v i ( σ I → a , h ) − v i ( σ , h ) r(h, a)=v_{i}\left(\sigma_{I \rightarrow a}, h\right)-v_{i}(\sigma, h) r(h,a)=vi(σI→a,h)−vi(σ,h)
在信息集 I I I 处采取动作 a a a 的虚拟遗憾值:
r ( I , a ) = ∑ h ∈ I r ( h , a ) r(I, a)=\sum_{h \in I} r(h, a) r(I,a)=h∈I∑r(h,a)
在 T T T 次迭代中累加的虚拟遗憾值:
R i T ( I , a ) = ∑ t = 1 T r i t ( I , a ) R_{i}^{T}(I, a)=\sum_{t=1}^{T} r_{i}^{t}(I, a) RiT(I,a)=t=1∑Trit(I,a)
则对于信息集 I i I_i Ii,通过遗憾匹配得到当前的策略:
σ i T + 1 ( I , a ) = { R i T , + ( I , a ) ∑ a ∈ A ( I ) R i T , + ( I , a ) if ∑ a ∈ A ( I ) R i T , + ( I , a ) > 0 1 ∣ A ( I ) ∣ otherwise. \sigma_{i}^{T+1}(I, a)=\left\{\begin{array}{cc} \frac{R_{i}^{T,+}(I, a)}{\sum_{a \in A(I)} R_{i}^{T,+}(I, a)} & \text { if } \sum_{a \in A(I)} R_{i}^{T,+}(I, a)>0 \\ \frac{1}{|A(I)|} & \text { otherwise. } \end{array}\right. σiT+1(I,a)=⎩⎨⎧∑a∈A(I)RiT,+(I,a)RiT,+(I,a)∣A(I)∣1 if ∑a∈A(I)RiT,+(I,a)>0 otherwise.
CFR 通过一次迭代,在被访问到的每个信息集上计算虚拟价值和虚拟遗憾值,当下一次迭代开始时,将会带入上次迭代的结果通过遗憾匹配计算新的策略。
这篇关于【博弈】非完全信息博弈基础与CFR算法简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




