本文主要是介绍python离群点检测_包会!手把手教你机器学习(零基础)之异常点检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Hello everyone ~ 我是GeoHey的周同学,近段时间呢我负责设计一个检测数据是否异常的模型,刚开始构思的时候还天真般的想用逻辑判断来实现,可是我后来发现不同的数据流有不同的特点,于是乎找到了一个比较好的解决方法,那就是Python机器学习框架 sklearn。

http://scikit-learn.org/stable/
这篇 blog 只要你懂一点python语法,稍微认真一点,你就能看懂。
OK ! 言归正传,我将为大家介绍 OneClassSVM 异常检测模型的使用。OneClassSVM 基于无监督学习算法,用于新奇点检测,并将新数据分类。通俗的说(讲人话)就是说如果新来的数据不在正常范围之内就判定为异常数据。
我们来举个通俗易懂的例子。
假设周同学是在三里屯卖烧饼的,每个月正常收入在8000-9000元,每个月正常支出在3000-4000元,我们现在要设计一个模型,即收入或者支出不在其正常范围,我们就认为是异常。下面上代码 !(文末有整体代码,饥渴难耐的同学可以一口闷)有效代码还不到50行,不要畏惧,看到这里你已经成功90%了。

首先导入需要使用的包。
import random
import numpy as np
from sklearn import svm
import matplotlib.pyplot as plt
import matplotlib.font_manager
random 是python自带的随机函数的库。
numpy 是python用于矩阵运算的库。
svm 是机器学习的类型。
matplotlib.pyplot 是作图用的。
matplotlib.font_manager用于管理图像的字体。
我们继续
xx, yy = np.meshgrid(np.linspace(0, 150, 150), np.linspace(0, 150, 150))
-----------------------分割线----------------------
这段代码用于之后的作图,和机器学习没有任何关系,它可以生成x,y都为150,内部均匀分布150*150个点的正方形栅格。
紧接着
n1 = [random.randint(80,90) for i in range(1000) ]
n2 = [random.randint(30,40) for i in range(1000) ]
l_train = list(zip(n1,n2))
X_train = np.array(l_train)
-----------------------分割线----------------------
(为了节省计算时间,我们默认单位为100元,即 80 为 8000 元收入)
n1 模拟生成 1000 次每月正常收入的python列表
n2 模拟生成 1000 次每月正常支出的python列表
l_train = list(zip(n1,n2))
将两列表压在一起,成为能显示每月 收入、支出 的列表,==比如:[(8200,3300), (8800,3200), ...... ] ==
随后
X_train = np.array(l_train)
将普通Python列表转化为用于矩阵运算的 Numpy array 所以 X_train 就是我们需要的训练数据。
同理,我们再生成一些测试数据:
n3 = [random.randint(70,90) for i in range(100) ]
n4 = [random.randint(30,50) for i in range(100) ]
l_test = list(zip(n3,n4))
X_test = np.array(l_test)
-----------------------分割线----------------------
随机生成100组数据,月收入在7000-1000,月支出在3500-5000
然后我们进行训练与测试
clf = svm.OneClassSVM(nu=0.05, kernel='rbf', gamma=0.01)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
-----------------------分割线----------------------
clf = svm.OneClassSVM(nu=0.05, kernel='rbf', gamma=0.01)
这行代码创建OneClassSVM模型对象,即clf,参数== nu == 为训练错误率,我们控制在 5% 左右, kernel 为该模型使用算法,'rbf'为默认算法。 gamma为rbf算法的一个系数,经实际反复使用推荐设置为0.01-0.001之间。
clf.fit(X_train)
``` 将训练数据填入进行训练。 这里我们创建的模型会以==X_train==为数据基础进行训练,推算出数据合理范围。如下图所示:

######进行预测
```python
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
分别对训练数据与测试数据进行预测
得出结果
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
这两行代码分别给出了 训练数据和测试数据异常的数量,其中==-1==表示数据异常。
打印结果
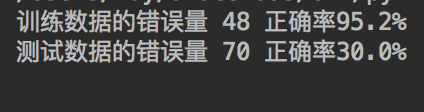
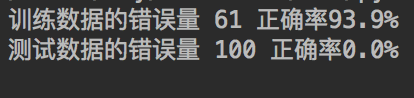
print('训练数据的错误量',n_error_train,'正确率{}%'.format((len(X_train)-n_error_train)*100/len(X_train)))
print('测试数据的错误量',n_error_test,'正确率{}%'.format((len(X_test)-n_error_test)*100/len(X_test)))
这两句print语句是方便查看预测结果,以下是我某次的运行结果:
其实到这里,机器学习的部分就已经结束啦,怎么样,是不是很简单,
你是不是感觉,还没开始就已经结束了?
从数据创建,模型创建,模型训练,数据预测才不到 20 行代码就完成了。难怪:
==Life is short, I use Python. ==
接下来是数据上图代码
各位伙伴如果不了解matplotlib可以去它的官网搜一下关键字
https://matplotlib.org/index.html 查询一下,其实都是一些图片属性设置。照着敲就可以了,我们主要是看看结果图。

# 画图部分
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 设置图片标题
plt.title('Output / Input')
# 设置图标类型为Blues_r
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap=plt.cm.Blues_r)
# 设置边界线颜色为红色
a = plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='red')
# 设置有效区域颜色为橘黄色
plt.contourf(xx, yy, Z, levels=[0, Z.max()], colors='orange')
# 设置X轴Y轴表示内容, X为收入 Y为支出
b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c='white')
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c='green')
plt.axis('tight')
# 设置坐标显示范围
plt.xlim((60, 120))
plt.ylim((0, 80))
# 设置图片属性说明(边界,训练点,测试点),以及显示在图片左上角
plt.legend([a.collections[0], b1, b2 ],
["normal boundary", "train income/consume ","test income/consume "
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11))
# 设置x轴说明
plt.xlabel(
"error train: %d/1000 ; errors test: %d/100 ; "
% (n_error_train, n_error_test, ))
# 显示图片
plt.show()
print('程序执行完毕')
以下是不同参数下的测试结果:
修改测试参数:
n3 = [random.randint(80,100) for i in range(100) ]
n4 = [random.randint(30,40) for i in range(100) ]
只需要更改收入范围【上面的(80,100)】与支出范围【上面的(30,40)】即可。
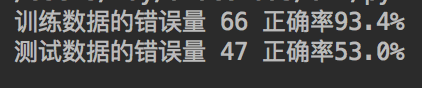
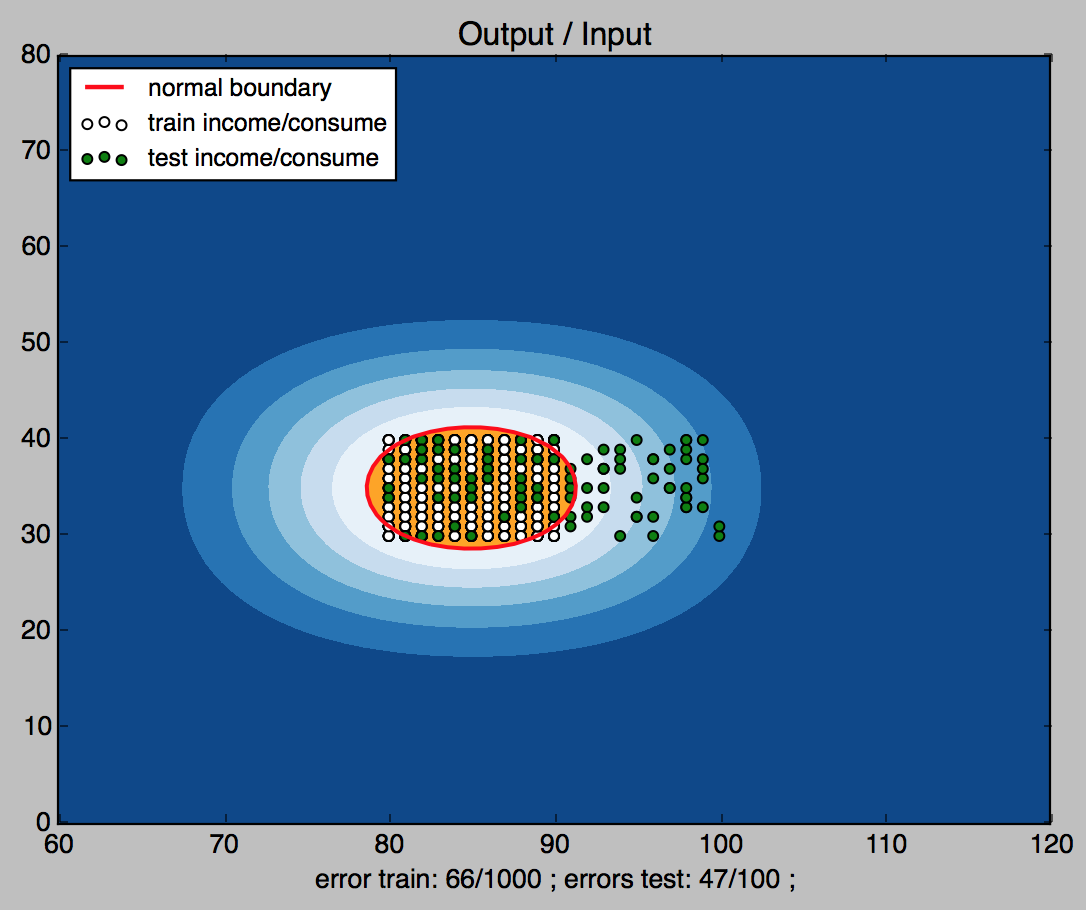
正常范围同时满足 收入80-90 支出30-40。
x轴为收入,y轴为支出,单位 100元。
---------------------分割线---------------------
随机生成 收入范围:80-100 支出范围:30-40
---------------------分割线---------------------
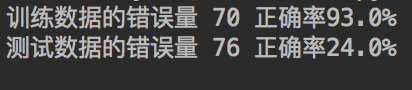
随机生成 收入范围:70-100 支出范围:30-50
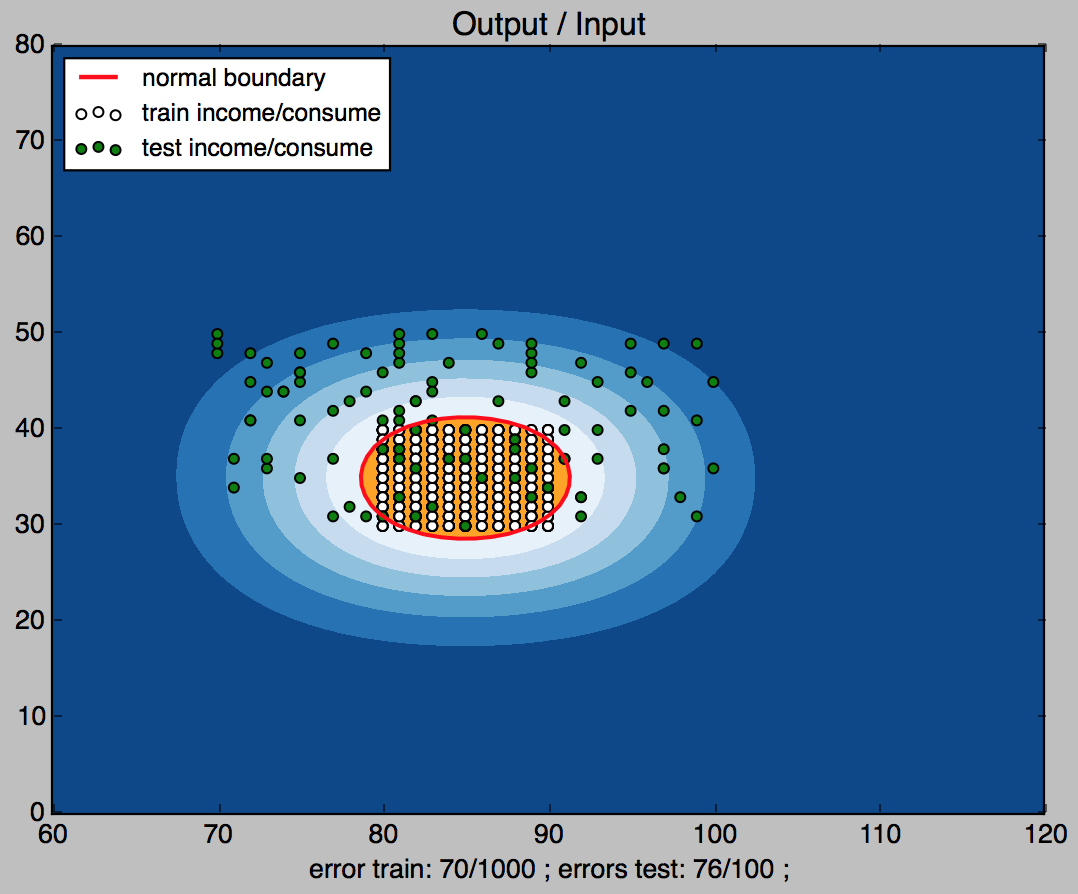
---------------------分割线---------------------
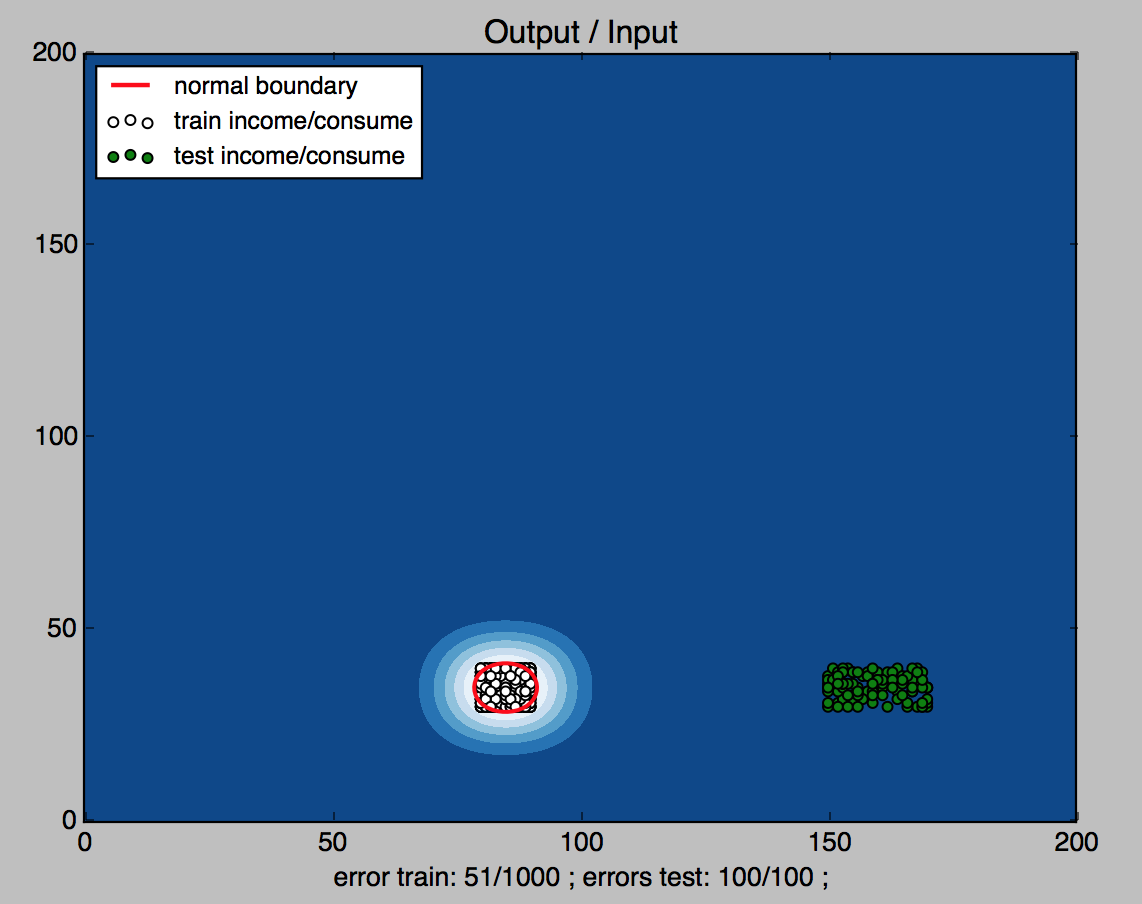
最后这组数据收入明显全部高于正常范围,同时也表达了作者对美好生活的向往。
随机生成 收入范围:150-170 支出范围:60-80
这里需要将前面的xx, yy 参数改为 (0, 200, 200)为了背景栅格能更大的显示
xx, yy = np.meshgrid(np.linspace(0, 200, 200), np.linspace(0, 200, 200))
plt.xlim((60, 120))
plt.ylim((0, 80))
表示x,y轴显示范围,把他们调大一点到
==plt.xlim(0,200) plt.ylim(0,200)==这样图片能正常显示
---------------------分割线---------------------
这次的内容就这些啦,sklearn还有许多即拿即用的机器学习包,有兴趣的伙伴可以去官网
http://scikit-learn.org/stable/ 学习更多的模型哦。
如有疑问可发邮件至 zhoudy@geohey.com
下次见,白白👋。

附(整体代码,可直接运行)
import random
import numpy as np
from sklearn import svm
import matplotlib.pyplot as plt
import matplotlib.font_manager
# 生成正方形栅格点,作图使用
xx, yy = np.meshgrid(np.linspace(0, 150, 150), np.linspace(0, 150, 150))
# 生成训练数据
n1 = [random.randint(80,90) for i in range(1000) ]
n2 = [random.randint(30,40) for i in range(1000) ]
l_train = list(zip(n1,n2))
X_train = np.array(l_train)
# 生成测试数据
n3 = [random.randint(80,100) for i in range(100) ]
n4 = [random.randint(30,40) for i in range(100) ]
l_test = list(zip(n3,n4))
X_test = np.array(l_test)
# 创建训练模型对象
clf = svm.OneClassSVM(nu=0.05, kernel='rbf', gamma=0.01)
# 训练数据
clf.fit(X_train)
# 预测训练数据
y_pred_train = clf.predict(X_train)
# 预测测试数据
y_pred_test = clf.predict(X_test)
# 输出错误数量
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
print('训练数据的错误量',n_error_train,'正确率{}%'.format((len(X_train)-n_error_train)*100/len(X_train)))
print('测试数据的错误量',n_error_test,'正确率{}%'.format((len(X_test)-n_error_test)*100/len(X_test)))
# 画图部分
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 设置图片标题
plt.title('Output / Input')
# 设置图标类型为Blues_r
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap=plt.cm.Blues_r)
# 设置边界线颜色为红色
a = plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='red')
# 设置有效区域颜色为橘黄色
plt.contourf(xx, yy, Z, levels=[0, Z.max()], colors='orange')
# 设置X轴Y轴表示内容, X为收入 Y为支出
b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c='white')
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c='green')
plt.axis('tight')
# 设置坐标显示范围
plt.xlim((60, 120))
plt.ylim((0, 80))
# 设置图片属性说明(边界,训练点,测试点),以及显示在图片左上角
plt.legend([a.collections[0], b1, b2 ],
["normal boundary", "train income/consume ","test income/consume "
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11))
# 设置x轴说明
plt.xlabel(
"error train: %d/1000 ; errors test: %d/100 ; "
% (n_error_train, n_error_test, ))
# 显示图片
plt.show()
print('程序执行完毕')
这篇关于python离群点检测_包会!手把手教你机器学习(零基础)之异常点检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




