本文主要是介绍拓端tecdat|R语言贝叶斯线性回归和多元线性回归构建工资预测模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我们被客户要求撰写关于贝叶斯线性回归的研究报告,包括一些图形和统计输出。
视频:线性回归中的贝叶斯推断与R语言预测工人工资数据案例
贝叶斯推断线性回归与R语言预测工人工资数据
,时长09:58
工资模型
在劳动经济学领域,收入和工资的研究为从性别歧视到高等教育等问题提供了见解。在本文中,我们将分析横断面工资数据,以期在实践中使用贝叶斯方法,如BIC和贝叶斯模型来构建工资的预测模型。
加载包
在本实验中,我们将使用dplyr包探索数据,并使用ggplot2包进行数据可视化。我们也可以在其中一个练习中使用MASS包来实现逐步线性回归。
我们将在实验室稍后使用此软件包中使用BAS.LM来实现贝叶斯模型。
数据
本实验室将使用的数据是在全国935名受访者中随机抽取的。
| 变量 | 描述 |
|---|---|
wage | 周收入 |
hours | 每周平均工作时间 |
IQ | 智商得分 |
kww | 工作知识分数 |
educ | 受教育年限 |
exper | 工作经验 |
tenure | 在现任雇主工作多年 |
age | 年龄 |
married | = 1,如果已婚 |
black | = 1(如果为黑人) |
south | = 1,如果住在南部 |
urban | = 1,如果居住在都市中 |
sibs | 兄弟姐妹数 |
brthord | 出生顺序 |
meduc | 母亲的教育程度 |
feduc | 父亲的学历 |
lwage | 工资的自然对数 |
这是观察研究还是实验?
- 观察研究
探索数据
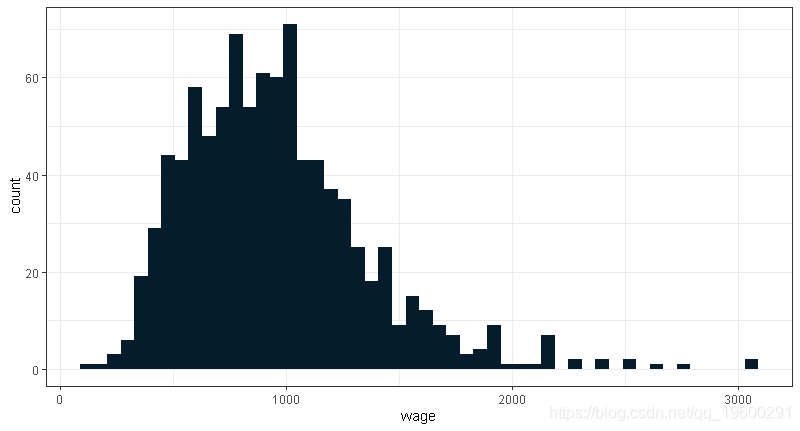
与任何新数据集一样,标准的探索性数据分析是一个好的开始。我们将从工资变量开始,因为它是我们模型中的因变量。
- 关于工资问题,下列哪种说法是错误的?
- 7名受访者每周收入低于300元
summary(wage)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 115.0 669.0 905.0 957.9 1160.0 3078.0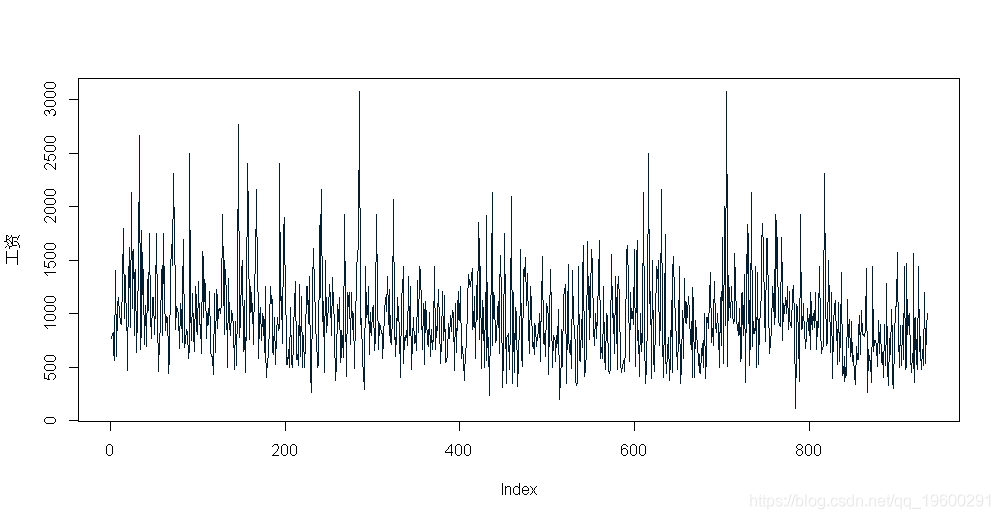
由于工资是我们的因变量,我们想探讨其他变量之间的关系作为预测。
练习:排除工资和工龄,选择另外两个你认为可以很好预测工资的变量。使用适当的图来形象化他们与工资的关系。
受教育程度和工作小时数似乎是工人工资的良好预测因素。
ggplot(data = wage, aes(y=wage, x=exper))+geom_point()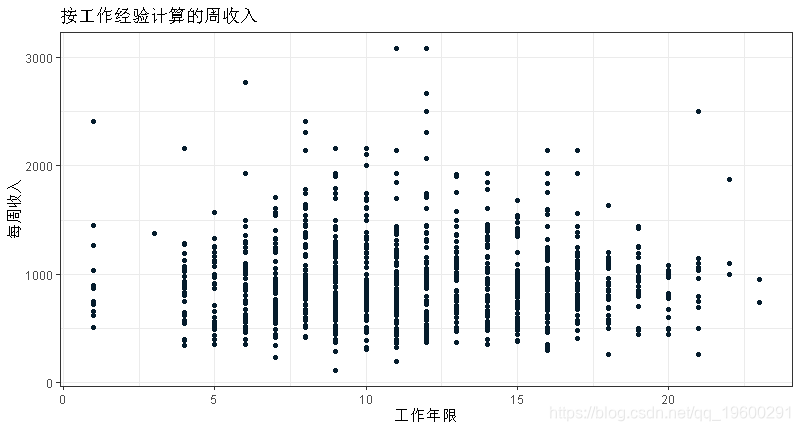
ggplot(data = wage, aes(y=wage, x=educ))+geom_point()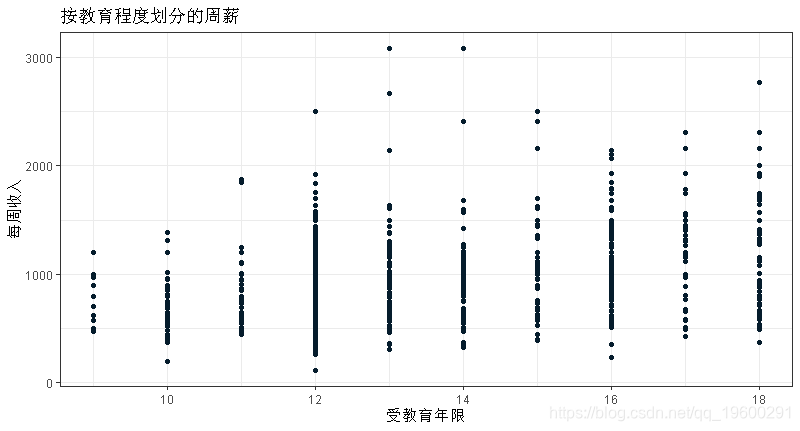
简单的线性回归
对于我们在数据中看到的工资差异,一个可能的解释是,更聪明的人赚更多的钱。下图显示了周工资和智商得分之间的散点图。
ggplot(data = wage, aes(x = iq, y = wage)) +geom_point()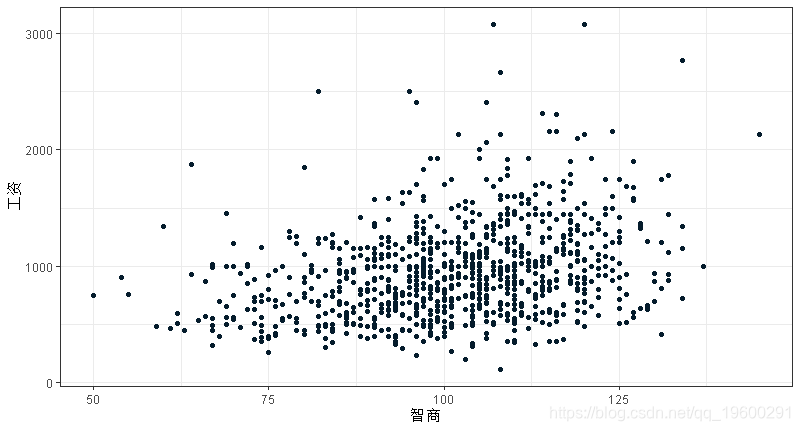
这个图是相当杂乱的。虽然智商分数和工资之间可能存在轻微的正线性关系,但智商充其量只是一个粗略的工资预测指标。我们可以通过拟合一个简单的线性回归来量化这一点。
m_wage_iq$coefficients## (Intercept) iq
## 116.991565 8.303064## [1] 384.7667回想一下,在模型下
![]()
如果使用 ![]() 和参考先验
和参考先验 ![]() ,然后贝叶斯后验均值和标准差分别等于频数估计和标准差。
,然后贝叶斯后验均值和标准差分别等于频数估计和标准差。
贝叶斯模型规范假设误差正态分布且方差为常数。与频率法一样,我们通过检查模型的残差分布来检验这一假设。如果残差是高度非正态或偏态的,则违反了假设,任何随后的推断都是无效的。
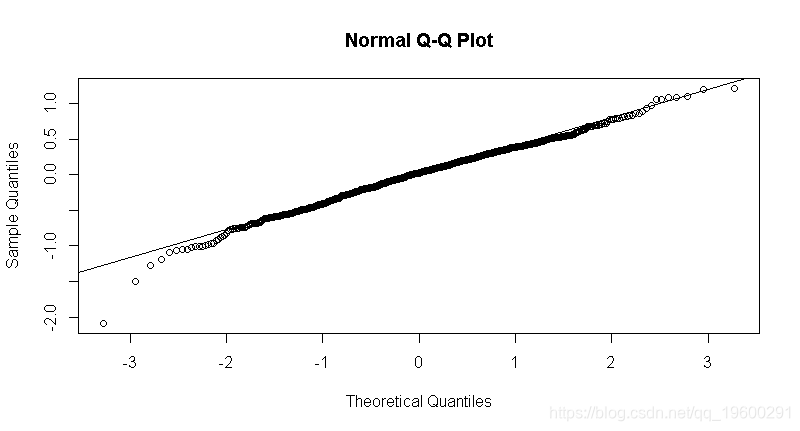
- 检验m_wage_iq的残差。正态分布误差的假设有效吗?
- 不,因为模型的残差分布是右偏的。
qqnorm(m_wage_iq$residuals)
qqline(m_wage_iq$residuals)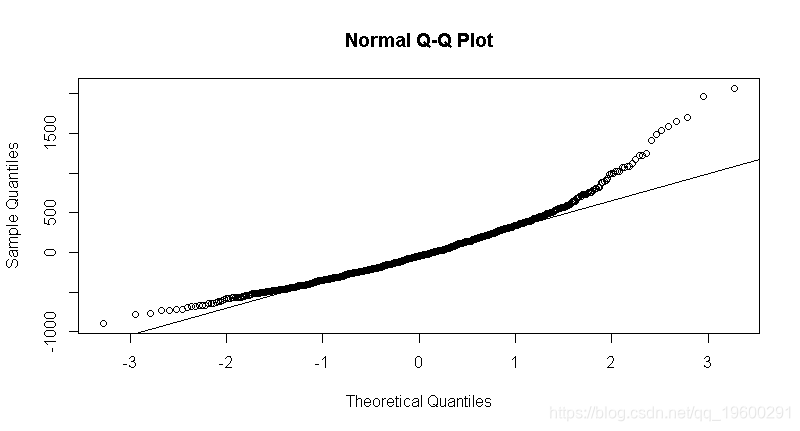
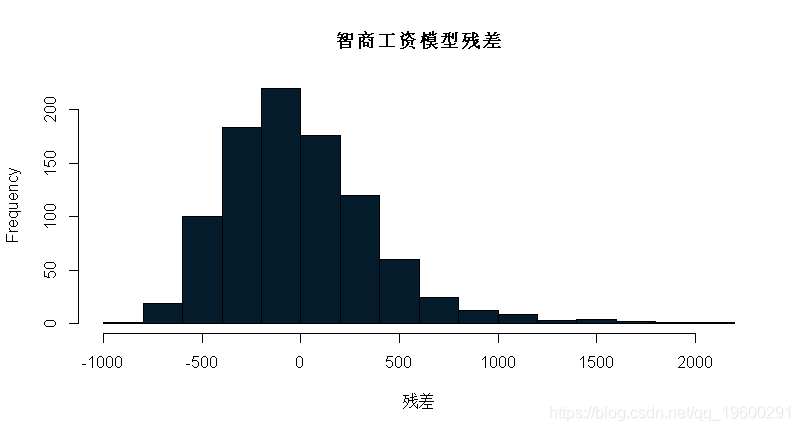
练习:重新调整模型,这次使用educ(教育)作为自变量。你对上一个练习的回答有变化吗?
## (Intercept) educ
## 146.95244 60.21428summary(m_wage_educ)$sigma## [1] 382.3203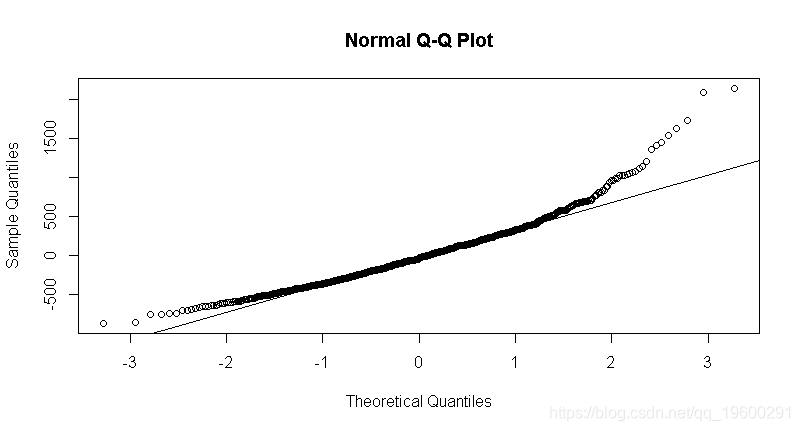
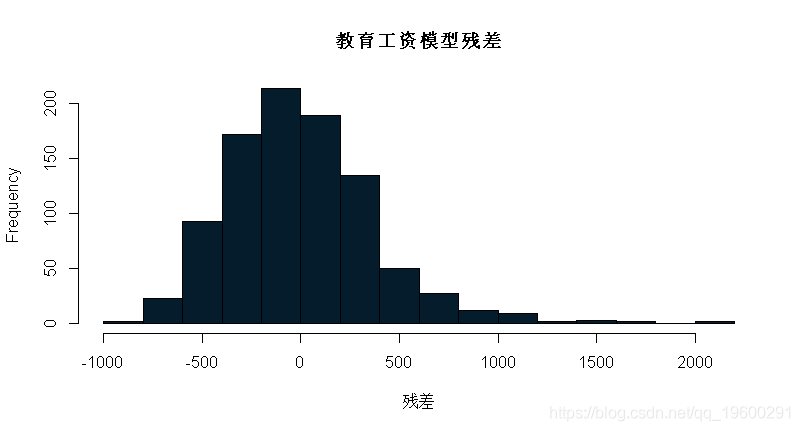
同样的结论是,该线性模型的残差与ϵi∼N(0,σ2)近似正态分布,因此可以在该线性模型的基础上进行进一步的推断。
变量转换
适应数据右偏的一种方法是(自然)对数变换因变量。请注意,这仅在变量严格为正时才可能,因为没有定义负值的对数,并且log(0)=−∞。我们试着用对数工资作为因变量来拟合一个线性模型。问题4将基于这个对数转换模型。
m_lwage_iq = lm(lwage ~ iq, data = wage)练习:检查该模型的残差。假设正态分布的残差合理吗?
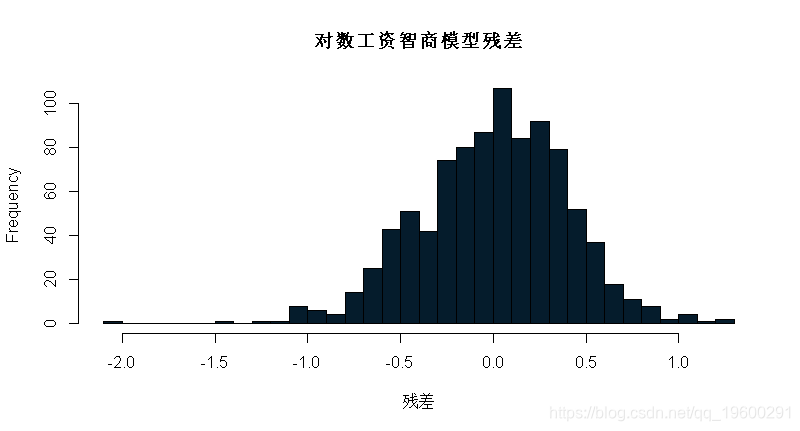
基于上述残差图,可以假定对数工资线性模型与iq的正态分布。
回想一下,给定σ2的α和β的后验分布是正态的,但略微遵循一个具有n−p−1自由度的t分布。在这种情况下,p=1,因为智商是我们模型中唯一的对数工资预测因子。因此,α和β的后验概率都遵循933自由度的t分布,因为df非常大,这些分布实际上是近似正态的。
- 在参考先验p(α,β,σ2)∞1/σ2下,给出β的95%后验置信区间,即IQ系数。
- (0.00709, 0.01050)
# 从线性模型m_lwage_iq中提取系数值qnorm(c(0.025, 0.975), mean = iq_mean_estimate, sd=iq_sd)## [1] 0.007103173 0.010511141练习:智商系数很小,这是意料之中的,因为智商分数提高一分很难对工资产生很高的倍增效应。使系数更易于解释的一种方法是在将智商放入模型之前将其标准化。从这个新模型来看,智商提高1个标准差(15分)估计工资会增加多少百分比?
智商是用scale函数标准化的,智商提高15分会引起工资的提高
coef(summary(m_lwage_scaled_iq))["siq", "Estimate"]*15+coef(summary(m_lwage_scaled_iq))["(Intercept)", "Estimate"]## [1] 8.767568多元线性回归
很明显,工资可以用很多预测因素来解释,比如经验、教育程度和智商。我们可以在回归模型中包含所有相关的协变量,试图尽可能多地解释工资变化。
lm中的.的使用告诉R在模型中包含所有协变量,然后用-wage进一步修改,然后从模型中排除工资变量。
默认情况下,lm函数执行完整的案例分析,因此它会删除一个或多个预测变量中缺少(NA)值的观察值。
由于这些缺失的值,我们必须做一个额外的假设,以便我们的推论是有效的。换句话说,我们的数据必须是随机缺失的。例如,如果所有第一个出生的孩子没有报告他们的出生顺序,数据就不会随机丢失。在没有任何额外信息的情况下,我们将假设这是合理的,并使用663个完整的观测值(与原来的935个相反)来拟合模型。Bayesian和frequentist方法都存在于处理缺失数据的数据集上,但是它们超出了本课程的范围。
- 从这个模型来看,谁赚得更多:已婚的黑人还是单身的非黑人?
- 已婚黑人
与单一非黑人男子相比,所有其他平等的,已婚的黑人将获得以下乘数。
married_black <- married_coef*1+black_coef*1married_black## [1] 0.09561888从线性模型的快速总结中可以看出,自变量的许多系数在统计上并不显著。您可以根据调整后的R2选择变量。本文引入了贝叶斯信息准则(BIC),这是一种可用于模型选择的度量。BIC基于模型拟合,同时根据样本大小按比例惩罚参数个数。我们可以使用以下命令计算全线性模型的BIC:
BIC(m_lwage_full)## [1] 586.3732我们可以比较完整模型和简化模型的BIC。让我们试着从模型中删除出生顺序。为了确保观测值保持不变,可以将数据集指定为na.omit(wage),它只包含没有缺失值的观测值。
m_lwage_nobrthord = lm(lwage ~ . -wage -brthord, data = na.omit(wage))
## [1] 582.4815如您所见,从回归中删除出生顺序会减少BIC,我们试图通过选择模型来最小化BIC。
- 从完整模型中消除哪个变量得到最低的BIC?
feduc
BIC(m_lwage_sibs)## [1] 581.4031BIC(m_lwage_feduc)## [1] 580.9743BIC(m_lwage_meduc)## [1] 582.3722练习:R有一个函数stepAIC,它将在模型空间中向后运行,删除变量直到BIC不再降低。它以一个完整的模型和一个惩罚参数k作为输入。根据BIC(在这种情况下k=log(n)k=log(n))找到最佳模型。
#对于AIC,惩罚因子是一个接触值k。对于step BIC,我们将使用stepAIC函数并将k设置为log(n)step(m_lwage_full1, direction = "backward", k=log(n))
## Residuals:
## Min 1Q Median 3Q Max
## -172.57 -63.43 -35.43 23.39 1065.78
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -5546.2382 84.7839 -65.416 < 2e-16 ***
## hours 1.9072 0.6548 2.913 0.0037 **
## tenure -4.1285 0.9372 -4.405 1.23e-05 ***
## lwage 951.0113 11.5041 82.667 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 120.1 on 659 degrees of freedom
## Multiple R-squared: 0.9131, Adjusted R-squared: 0.9127
## F-statistic: 2307 on 3 and 659 DF, p-value: < 2.2e-16贝叶斯模型平均
通常,几个模型都是同样可信的,只选择一个模型忽略了选择模型中包含的变量所涉及的固有不确定性。解决这一问题的一种方法是实现贝叶斯模型平均(Bayesian model averaging,BMA),即对多个模型进行平均,从新数据中获得系数的后验值和预测值。我们可以使用它来实现BMA或选择模型。我们首先将BMA应用于工资数据。
bma(lwage ~ . -wage, data = wage_no_na,prior = "BIC", modelprior = uniform())
##
## Marginal Posterior Inclusion Probabilities:
## Intercept hours iq kww educ exper
## 1.00000 0.85540 0.89732 0.34790 0.99887 0.70999
## tenure age married1 black1 south1 urban1
## 0.70389 0.52468 0.99894 0.34636 0.32029 1.00000
## sibs brthord meduc feduc
## 0.04152 0.12241 0.57339 0.23274summary(bma_lwage)## P(B != 0 | Y) model 1 model 2 model 3
## Intercept 1.00000000 1.0000 1.0000000 1.0000000
## hours 0.85540453 1.0000 1.0000000 1.0000000
## iq 0.89732383 1.0000 1.0000000 1.0000000
## kww 0.34789688 0.0000 0.0000000 0.0000000
## educ 0.99887165 1.0000 1.0000000 1.0000000
## exper 0.70999255 0.0000 1.0000000 1.0000000
## tenure 0.70388781 1.0000 1.0000000 1.0000000
## age 0.52467710 1.0000 1.0000000 0.0000000
## married1 0.99894488 1.0000 1.0000000 1.0000000
## black1 0.34636467 0.0000 0.0000000 0.0000000
## south1 0.32028825 0.0000 0.0000000 0.0000000
## urban1 0.99999983 1.0000 1.0000000 1.0000000
## sibs 0.04152242 0.0000 0.0000000 0.0000000
## brthord 0.12241286 0.0000 0.0000000 0.0000000
## meduc 0.57339302 1.0000 1.0000000 1.0000000
## feduc 0.23274084 0.0000 0.0000000 0.0000000
## BF NA 1.0000 0.5219483 0.5182769
## PostProbs NA 0.0455 0.0237000 0.0236000
## R2 NA 0.2710 0.2767000 0.2696000
## dim NA 9.0000 10.0000000 9.0000000
## logmarg NA -1490.0530 -1490.7032349 -1490.7102938
## model 4 model 5
## Intercept 1.0000000 1.0000000
## hours 1.0000000 1.0000000
## iq 1.0000000 1.0000000
## kww 1.0000000 0.0000000
## educ 1.0000000 1.0000000
## exper 1.0000000 0.0000000
## tenure 1.0000000 1.0000000
## age 0.0000000 1.0000000
## married1 1.0000000 1.0000000
## black1 0.0000000 1.0000000
## south1 0.0000000 0.0000000
## urban1 1.0000000 1.0000000
## sibs 0.0000000 0.0000000
## brthord 0.0000000 0.0000000
## meduc 1.0000000 1.0000000
## feduc 0.0000000 0.0000000
## BF 0.4414346 0.4126565
## PostProbs 0.0201000 0.0188000
## R2 0.2763000 0.2762000
## dim 10.0000000 10.0000000
## logmarg -1490.8707736 -1490.9381880输出model对象和summary命令为我们提供了每个变量的后验模型包含概率和最可能的模型。例如,模型中包含小时数的后验概率为0.855。此外,后验概率为0.0455的最可能模型包括截距、工作时间、智商、教育程度、年龄、婚姻状况、城市生活状况和母亲教育程度。虽然0.0455的后验概率听起来很小,但它比分配给它的统一先验概率大得多,因为有216个可能的模型。
在模型平均法下,还可以可视化系数的后验分布。我们将智商系数的后验分布绘制如下。
plot(coef_lwage, subset = c(3,13), ask=FALSE)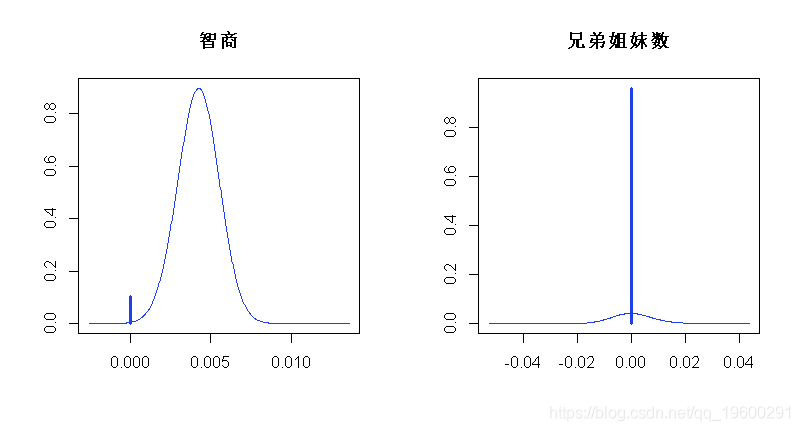
我们还可以为这些系数提供95%的置信区间:
## 2.5% 97.5% beta
## Intercept 6.787648e+00 6.841901e+00 6.8142970694
## hours -9.213871e-03 0.000000e+00 -0.0053079979
## iq 0.000000e+00 6.259498e-03 0.0037983313
## kww 0.000000e+00 8.290187e-03 0.0019605787
## educ 2.247901e-02 6.512858e-02 0.0440707549
## exper 0.000000e+00 2.100097e-02 0.0100264057
## tenure 0.000000e+00 1.288251e-02 0.0059357058
## age 0.000000e+00 2.541561e-02 0.0089659753
## married1 1.173088e-01 3.015797e-01 0.2092940731
## black1 -1.900452e-01 0.000000e+00 -0.0441863361
## south1 -1.021332e-01 1.296992e-05 -0.0221757978
## urban1 1.374767e-01 2.621311e-01 0.1981221313
## sibs 0.000000e+00 0.000000e+00 0.0000218455
## brthord -2.072393e-02 0.000000e+00 -0.0019470674
## meduc 0.000000e+00 2.279918e-02 0.0086717156
## feduc -7.996880e-06 1.558576e-02 0.0025125930
## attr(,"Probability")
## [1] 0.95
## attr(,"class")
## [1] "confint.bas"对于问题7-8,我们将使用简化的数据集,其中不包括兄弟姐妹数量、出生顺序和父母教育。
wage_red = wage %>% dplyr::select(-sibs, -brthord, -meduc, -feduc)- 基于这个简化的数据集,根据贝叶斯模型平均,下列哪一个变量的边际后验包含概率最低?
- 年龄
##
## Call:
##
##
## Marginal Posterior Inclusion Probabilities:
## Intercept hours iq kww educ exper
## 1.0000 0.8692 0.9172 0.3217 1.0000 0.9335
## tenure age married1 black1 south1 urban1
## 0.9980 0.1786 0.9999 0.9761 0.8149 1.0000## P(B != 0 | Y) model 1 model 2 model 3
## Intercept 1.0000000 1.0000 1.0000000 1.0000000
## hours 0.8691891 1.0000 1.0000000 1.0000000
## iq 0.9171607 1.0000 1.0000000 1.0000000
## kww 0.3216992 0.0000 1.0000000 0.0000000
## educ 1.0000000 1.0000 1.0000000 1.0000000
## exper 0.9334844 1.0000 1.0000000 1.0000000
## tenure 0.9980015 1.0000 1.0000000 1.0000000
## age 0.1786252 0.0000 0.0000000 0.0000000
## married1 0.9999368 1.0000 1.0000000 1.0000000
## black1 0.9761347 1.0000 1.0000000 1.0000000
## south1 0.8148861 1.0000 1.0000000 0.0000000
## urban1 1.0000000 1.0000 1.0000000 1.0000000
## BF NA 1.0000 0.5089209 0.2629789
## PostProbs NA 0.3311 0.1685000 0.0871000
## R2 NA 0.2708 0.2751000 0.2634000
## dim NA 10.0000 11.0000000 9.0000000
## logmarg NA -2275.4209 -2276.0963811 -2276.7565998
## model 4 model 5
## Intercept 1.0000000 1.0000000
## hours 1.0000000 0.0000000
## iq 1.0000000 1.0000000
## kww 0.0000000 0.0000000
## educ 1.0000000 1.0000000
## exper 1.0000000 1.0000000
## tenure 1.0000000 1.0000000
## age 1.0000000 0.0000000
## married1 1.0000000 1.0000000
## black1 1.0000000 1.0000000
## south1 1.0000000 1.0000000
## urban1 1.0000000 1.0000000
## BF 0.2032217 0.1823138
## PostProbs 0.0673000 0.0604000
## R2 0.2737000 0.2628000
## dim 11.0000000 9.0000000
## logmarg -2277.0143763 -2277.1229445- 判断:包含所有变量的朴素模型的后验概率大于0.5。(系数使用Zellner-Siow零先验,模型使用β二项(1,1)先验)
- 真的
bma_lwage_full##
## Call:
##
##
## Marginal Posterior Inclusion Probabilities:
## Intercept hours iq kww educ exper
## 1.0000 0.9792 0.9505 0.6671 0.9998 0.8951
## tenure age married1 black1 south1 urban1
## 0.9040 0.7093 0.9998 0.7160 0.6904 1.0000
## sibs brthord meduc feduc
## 0.3939 0.5329 0.7575 0.5360## P(B != 0 | Y) model 1 model 2 model 3 model 4
## Intercept 1.0000000 1.00000000 1.00000000 1.00000000 1.0000
## hours 0.9791805 1.00000000 1.00000000 1.00000000 1.0000
## iq 0.9504649 1.00000000 1.00000000 1.00000000 1.0000
## kww 0.6670580 1.00000000 1.00000000 1.00000000 1.0000
## educ 0.9998424 1.00000000 1.00000000 1.00000000 1.0000
## exper 0.8950911 1.00000000 1.00000000 1.00000000 1.0000
## tenure 0.9040156 1.00000000 1.00000000 1.00000000 1.0000
## age 0.7092839 1.00000000 1.00000000 1.00000000 1.0000
## married1 0.9997881 1.00000000 1.00000000 1.00000000 1.0000
## black1 0.7160065 1.00000000 1.00000000 1.00000000 1.0000
## south1 0.6903763 1.00000000 1.00000000 1.00000000 1.0000
## urban1 1.0000000 1.00000000 1.00000000 1.00000000 1.0000
## sibs 0.3938833 1.00000000 1.00000000 0.00000000 0.0000
## brthord 0.5329258 1.00000000 1.00000000 1.00000000 0.0000
## meduc 0.7575462 1.00000000 1.00000000 1.00000000 1.0000
## feduc 0.5359832 1.00000000 0.00000000 1.00000000 0.0000
## BF NA 0.01282537 0.06040366 0.04899546 1.0000
## PostProbs NA 0.07380000 0.02320000 0.01880000 0.0126
## R2 NA 0.29250000 0.29140000 0.29090000 0.2882
## dim NA 16.00000000 15.00000000 15.00000000 13.0000
## logmarg NA 76.00726935 77.55689364 77.34757164 80.3636
## model 5
## Intercept 1.000000
## hours 1.000000
## iq 1.000000
## kww 1.000000
## educ 1.000000
## exper 1.000000
## tenure 1.000000
## age 1.000000
## married1 1.000000
## black1 1.000000
## south1 1.000000
## urban1 1.000000
## sibs 0.000000
## brthord 1.000000
## meduc 1.000000
## feduc 0.000000
## BF 0.227823
## PostProbs 0.012500
## R2 0.289600
## dim 14.000000
## logmarg 78.884413练习:用数据集绘制年龄系数的后验分布图。
plot(coef_bma_wage_red, ask = FALSE)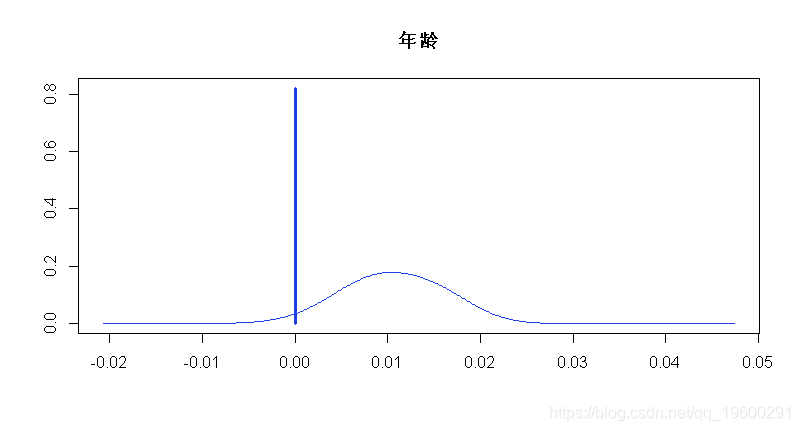
预测
贝叶斯统计的一个主要优点是预测和预测的概率解释。大部分贝叶斯预测都是使用模拟技术来完成的。这通常应用于回归建模中,尽管我们将通过一个仅包含截距项的示例来进行分析。
假设你观察到y的四个数值观测值,分别为2、2、0和0,样本均值y′=1,样本方差s2=4/3。假设y∼N(μ,σ2),在参考先验p(μ,σ2)∼1/σ2下,我们的后验概率变为
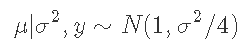
以样本均值为中心
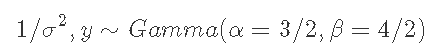
其中a=(n-1)/2和b=s2(n-1)/2=2。
为了得到y5的预测分布,我们可以先从σ2的后验点模拟,然后再从μ模拟y5。我们对y5年的预测结果将来自一项新的观测结果的后验预测分布。下面的示例从y5的后验预测分布中提取100,000次。
set.seed(314)
N = 100000y_5 = rnorm(N, mu, sqrt(sigma2))我们可以通过观察模拟数据直方图的平滑版本,查看预测分布的估计值。
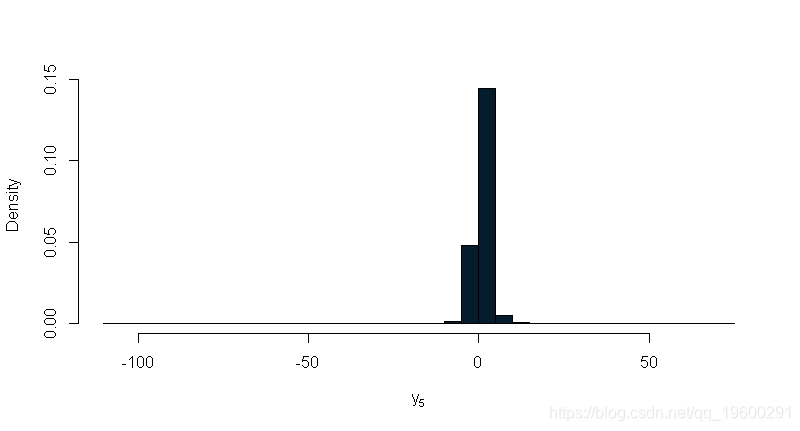
新观测的95%中心置信区间为在这种情况下,L是0.025分位数,U是0.975分位数。我们可以使用分位数函数来获得这些值,从而找到tracy5的0.025和0.975的样本分位数。
- 估计一个新的观测y595%置信区间
- (-3.11, 5.13)
quantile(y_5, probs = c(0.025, 0.975))## 2.5% 97.5%
## -3.109585 5.132511练习:在上面的简单例子中,可以使用积分来分析计算后验预测值。在这种情况下,它是一个具有3个自由度(n−1)的t分布。绘制y的经验密度和t分布的实际密度。它们之间有什么比较?
plot(den_of_y)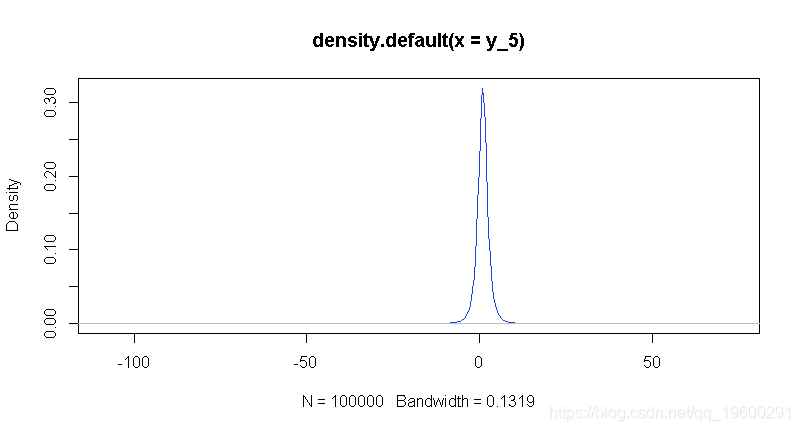
BAS预测
在BAS中,用贝叶斯模型平均法构造预测区间是通过仿真实现的,而在模型选择的情况下,用预测区间进行精确推理往往是可行的。
回到工资数据集,让我们找到最佳预测模型下的预测值,即预测值最接近BMA和相应的后验标准差的模型。
predict(bma_lwage, estimator="BPM")
## [1] "Intercept" "hours" "iq" "kww" "educ"
## [6] "exper" "tenure" "age" "married1" "urban1"
## [11] "meduc"我们可以将其与我们之前发现的最高概率模型和中位概率模型(MPM)进行比较
predict(bma_lwage, estimator="MPM")
## [1] "Intercept" "hours" "iq" "educ" "exper"
## [6] "tenure" "age" "married1" "urban1" "meduc"MPM除了包含HPM的所有变量外,还包含exper,而BPM除了MPM中的所有变量外,还包含kwh。
练习:使用简化数据,最佳预测模型、中位概率模型和最高后验概率模型中包含哪些协变量?
让我们来看看BPM模型中哪些特征会影响最高工资。
## [,1]
## wage "1586"
## hours "40"
## iq "127"
## kww "48"
## educ "16"
## exper "16"
## tenure "12"
## age "37"
## married "1"
## black "0"
## south "0"
## urban "1"
## sibs "4"
## brthord "4"
## meduc "16"
## feduc "16"
## lwage "7.36897"可以得到预测对数工资的95%可信区间
## 2.5% 97.5% pred
## 6.661869 8.056452 7.359160换算成工资,我们可以将区间指数化。
## 2.5% 97.5% pred
## 782.0108 3154.0780 1570.5169获得一个95%的预测区间的工资。
如果使用BMA,区间是
## 2.5% 97.5% pred
## 733.3446 2989.2076 1494.9899练习:使用简化后的数据,为BPM下预测工资最高的个人构建95%的预测区间。
参考文献
Wooldridge, Jeffrey. 2000. Introductory Econometrics- A Modern Approach. South-Western College Publishing.

这篇关于拓端tecdat|R语言贝叶斯线性回归和多元线性回归构建工资预测模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






