本文主要是介绍【推荐算法代码实现】Deep Interest Network for Click-Through Rate Prediction代码实现和解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文解读见【推荐算法】深度学习推荐算法综述 Deep Learning based Recommender System: A Survey and New Perspectives第6.2小节。
一、数据处理
1.1 基础数据
论文中用的是Amazon Product Data数据,包含两个文件:reviews_Electronics_5.json, meta_Electronics.json
下载并解压:
wget -c http://snap.stanford.edu/data/amazon/productGraph/categoryFiles/reviews_Electronics_5.json.gz
gzip -d reviews_Electronics_5.json.gz
wget -c http://snap.stanford.edu/data/amazon/productGraph/categoryFiles/meta_Electronics.json.gz
gzip -d meta_Electronics.json.gz
其中reviews_Electronics_5.json主要是用户买了相关商品产生的上下文信息,包括商品id, 时间,评论等;
meta_Electronics文件是关于商品本身的信息,包括商品id, 名称,类别,买了还买等信息。
reviews某单个样本如下:
{"reviewerID": "A2SUAM1J3GNN3B","asin": "0000013714","reviewerName": "J. McDonald","helpful": [2, 3],"reviewText": "I bought this for my husband who plays the piano. He is having a wonderful time playing these old hymns. The music is at times hard to read because we think the book was published for singing from more than playing from. Great purchase though!","overall": 5.0,"summary": "Heavenly Highway Hymns","unixReviewTime": 1252800000,"reviewTime": "09 13, 2009"
}
各字段分别为:
reviewerID:用户ID;
asin: 物品ID;
reviewerName:用户姓名;
helpful :评论帮助程度,例如上述为2/3;
reviewText :文本信息;
overall :物品评分;
summary:评论总结
unixReviewTime :时间戳
reviewTime :时间
meta某样本如下:
{"asin": "0000031852","title": "Girls Ballet Tutu Zebra Hot Pink","price": 3.17,"imUrl": "http://ecx.images-amazon.com/images/I/51fAmVkTbyL._SY300_.jpg","related":{"also_bought": ["B00JHONN1S", "B002BZX8Z6", "B00D2K1M3O", "0000031909", "B00613WDTQ", "B00D0WDS9A", "B00D0GCI8S", "0000031895", "B003AVKOP2", "B003AVEU6G", "B003IEDM9Q", "B002R0FA24", "B00D23MC6W", "B00D2K0PA0", "B00538F5OK", "B00CEV86I6", "B002R0FABA", "B00D10CLVW", "B003AVNY6I", "B002GZGI4E", "B001T9NUFS", "B002R0F7FE", "B00E1YRI4C", "B008UBQZKU", "B00D103F8U", "B007R2RM8W"],"also_viewed": ["B002BZX8Z6", "B00JHONN1S", "B008F0SU0Y", "B00D23MC6W", "B00AFDOPDA", "B00E1YRI4C", "B002GZGI4E", "B003AVKOP2", "B00D9C1WBM", "B00CEV8366", "B00CEUX0D8", "B0079ME3KU", "B00CEUWY8K", "B004FOEEHC", "0000031895", "B00BC4GY9Y", "B003XRKA7A", "B00K18LKX2", "B00EM7KAG6", "B00AMQ17JA", "B00D9C32NI", "B002C3Y6WG", "B00JLL4L5Y", "B003AVNY6I", "B008UBQZKU", "B00D0WDS9A", "B00613WDTQ", "B00538F5OK", "B005C4Y4F6", "B004LHZ1NY", "B00CPHX76U", "B00CEUWUZC", "B00IJVASUE", "B00GOR07RE", "B00J2GTM0W", "B00JHNSNSM", "B003IEDM9Q", "B00CYBU84G", "B008VV8NSQ", "B00CYBULSO", "B00I2UHSZA", "B005F50FXC", "B007LCQI3S", "B00DP68AVW", "B009RXWNSI", "B003AVEU6G", "B00HSOJB9M", "B00EHAGZNA", "B0046W9T8C", "B00E79VW6Q", "B00D10CLVW", "B00B0AVO54", "B00E95LC8Q", "B00GOR92SO", "B007ZN5Y56", "B00AL2569W", "B00B608000", "B008F0SMUC", "B00BFXLZ8M"],"bought_together": ["B002BZX8Z6"]},"salesRank": {"Toys & Games": 211836},"brand": "Coxlures","categories": [["Sports & Outdoors", "Other Sports", "Dance"]]
}
各字段分别为:
asin :物品ID;
title :物品名称;
price :物品价格;
imUrl :物品图片的URL;
related :相关产品(也买,也看,一起买,看后再买);
salesRank: 销售排名信息;
brand :品牌名称;
categories :该物品属于的种类列表;
1.2 数据处理
1.2.1 utils/1_convert_pd.py
import pickle
import pandas as pddef to_df(file_path):"""转化为DataFrame结构:param file_path: 文件路径:return:"""with open(file_path, 'r') as fin:df = {}i = 0for line in fin:df[i] = eval(line)i += 1df = pd.DataFrame.from_dict(df, orient='index')return dfreviews_df = to_df('../raw_data/reviews_Electronics_5.json')# 可以直接调用pandas的read_json方法,但会改变列的顺序
# reviews2_df = pd.read_json('../raw_data/reviews_Electronics_5.json', lines=True)# 序列化保存
with open('../raw_data/reviews.pkl', 'wb') as f:pickle.dump(reviews_df, f, pickle.HIGHEST_PROTOCOL)meta_df = to_df('../raw_data/meta_Electronics.json')
# 只保留review_df出现过的广告
meta_df = meta_df[meta_df['asin'].isin(reviews_df['asin'].unique())]
meta_df = meta_df.reset_index(drop=True)with open('../raw_data/meta.pkl', 'wb') as f:pickle.dump(meta_df, f, pickle.HIGHEST_PROTOCOL)该程序:
- 将reviews_Electronics_5.json转换成dataframe,列分别为reviewID ,asin, reviewerName等;
- 将meta_Electronics.json转成dataframe,并且只保留在reviewes文件中出现过的商品,去重;
- 转换完的文件保存成pkl格式。
1.2.2 utils/2_remap_id.py
import random
import pickle
import numpy as nprandom.seed(1234)with open('../raw_data/reviews.pkl', 'rb') as f:reviews_df = pickle.load(f)reviews_df = reviews_df[['reviewerID', 'asin', 'unixReviewTime']]
with open('../raw_data/meta.pkl', 'rb') as f:meta_df = pickle.load(f)meta_df = meta_df[['asin', 'categories']]meta_df['categories'] = meta_df['categories'].map(lambda x: x[-1][-1])def build_map(df, col_name):"""制作一个映射,键为列名,值为序列数字:param df: reviews_df / meta_df:param col_name: 列名:return: 字典,键"""key = sorted(df[col_name].unique().tolist())m = dict(zip(key, range(len(key))))df[col_name] = df[col_name].map(lambda x: m[x])return m, key# reviews
reviews_df = pd.read_pickle('../raw_data/reviews.pkl')
reviews_df = reviews_df[['reviewerID', 'asin', 'unixReviewTime']]# meta
meta_df = pd.read_pickle('../raw_data/meta.pkl')
meta_df = meta_df[['asin', 'categories']]
# 类别只保留最后一个
meta_df['categories'] = meta_df['categories'].map(lambda x: x[-1][-1])# meta_df文件的物品ID映射
asin_map, asin_key = build_map(meta_df, 'asin')
# meta_df文件物品种类映射
cate_map, cate_key = build_map(meta_df, 'categories')
# reviews_df文件的用户ID映射
revi_map, revi_key = build_map(reviews_df, 'reviewerID')# user_count: 192403 item_count: 63001 cate_count: 801 example_count: 1689188
user_count, item_count, cate_count, example_count = \len(revi_map), len(asin_map), len(cate_map), reviews_df.shape[0]
# print('user_count: %d\titem_count: %d\tcate_count: %d\texample_count: %d' %
# (user_count, item_count, cate_count, example_count))# 按物品id排序,并重置索引
meta_df = meta_df.sort_values('asin')
meta_df = meta_df.reset_index(drop=True)# reviews_df文件物品id进行映射,并按照用户id、浏览时间进行排序,重置索引
reviews_df['asin'] = reviews_df['asin'].map(lambda x: asin_map[x])
reviews_df = reviews_df.sort_values(['reviewerID', 'unixReviewTime'])
reviews_df = reviews_df.reset_index(drop=True)
reviews_df = reviews_df[['reviewerID', 'asin', 'unixReviewTime']]# 各个物品对应的类别
cate_list = np.array(meta_df['categories'], dtype='int32')# 保存所需数据为pkl文件
with open('../raw_data/remap.pkl', 'wb') as f:pickle.dump(reviews_df, f, pickle.HIGHEST_PROTOCOL)pickle.dump(cate_list, f, pickle.HIGHEST_PROTOCOL)pickle.dump((user_count, item_count, cate_count, example_count),f, pickle.HIGHEST_PROTOCOL)pickle.dump((asin_key, cate_key, revi_key), f, pickle.HIGHEST_PROTOCOL)
该程序:
- 将reviews_df只保留reviewerID, asin, unixReviewTime三列;
- 将meta_df保留asin, categories列,并且类别列只保留三级类目;(至此,用到的数据只设计5列,(reviewerID, asin, unixReviewTime),(asin, categories));
- 用asin,categories,reviewerID分别生产三个map(asin_map, cate_map, revi_map),key为对应的原始信息,value为按key排序后的index(从0开始顺序排序),然后将原数据的对应列原始数据转换成key对应的index;各个map的示意图如下:

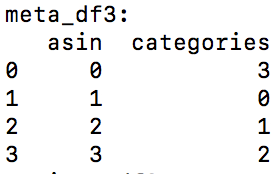
- 将meta_df按asin对应的index进行排序,如图:
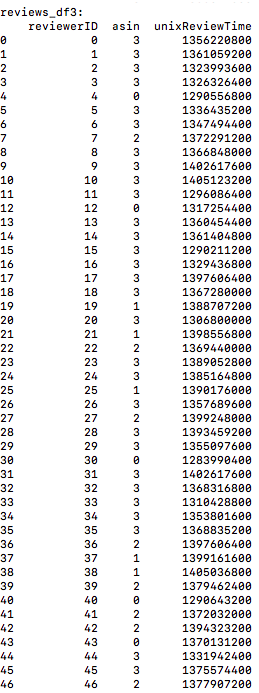
- 将reiviews_df中的asin转换成asin_map中asin对应的value值,并且按照reviewerID和时间排序。如图:
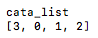
- 生成cate_list, 就是把meta_df的’categories’列取出来。
1.3 生成训练集和测试集
din/build_dataset.py
import random
import picklerandom.seed(1234)with open('raw_data/remap.pkl', 'rb') as f:reviews_df = pickle.load(f)cate_list = pickle.load(f)user_count, item_count, cate_count, example_count = pickle.load(f)train_set, test_set = [], []# 最大的序列长度
max_sl = 0"""
生成训练集、测试集,每个用户所有浏览的物品(共n个)前n-1个为训练集(正样本),并生成相应的负样本,每个用户
共有n-2个训练集(第1个无浏览历史),第n个作为测试集。
"""
for reviewerID, hist in reviews_df.groupby('reviewerID'):# 每个用户浏览过的物品,即为正样本pos_list = hist['asin'].tolist()max_sl = max(max_sl, len(pos_list))# 生成负样本def gen_neg():neg = pos_list[0]while neg in pos_list:neg = random.randint(0, item_count - 1)return neg# 正负样本比例1:1neg_list = [gen_neg() for i in range(len(pos_list))]for i in range(1, len(pos_list)):# 生成每一次的历史记录,即之前的浏览历史hist = pos_list[:i]sl = len(hist)if i != len(pos_list) - 1:# 保存正负样本,格式:用户ID,正/负物品id,浏览历史,浏览历史长度,标签(1/0)train_set.append((reviewerID, pos_list[i], hist, sl, 1))train_set.append((reviewerID, neg_list[i], hist, sl, 0))else:# 最后一次保存为测试集test_set.append((reviewerID, pos_list[i], hist, sl, 1))test_set.append((reviewerID, neg_list[i], hist, sl, 0))# 打乱顺序
random.shuffle(train_set)
random.shuffle(test_set)assert len(test_set) == user_count# 写入dataset.pkl文件
with open('dataset/dataset.pkl', 'wb') as f:pickle.dump(train_set, f, pickle.HIGHEST_PROTOCOL)pickle.dump(test_set, f, pickle.HIGHEST_PROTOCOL)pickle.dump(cate_list, f, pickle.HIGHEST_PROTOCOL)pickle.dump((user_count, item_count, cate_count, max_sl), f, pickle.HIGHEST_PROTOCOL)
该代码:
- 将reviews_df按reviewerID进行聚合
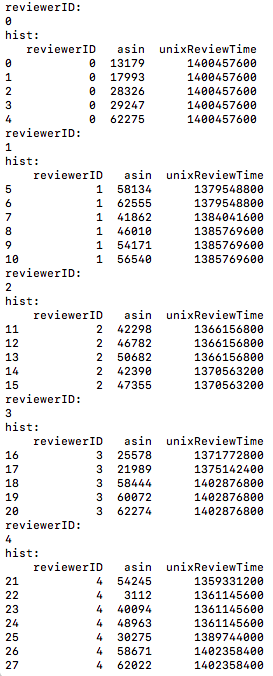
- 将hist的asin列作为每个reviewerID(也就是用户)的正样本列表(pos_list),注意这里的asin存的已经不是原始的item_id了,而是通过asin_map转换过来的index。负样本列表(neg_list)为在item_count范围内产生不在pos_list中的随机数列表。
- 得到pos_list后就开始构造训练集和测试集了。
训练集的构造方法:
如上图,例如对于reviewerID=0的用户,他的pos_list为[13179, 17993, 28326, 29247, 62275], 生成的训练集格式为(reviewerID, hist, pos_item, 1), (reviewerID, hist, neg_item, 0),这里需要注意hist并不包含pos_item, hist只包含在pos_item之前点击过的item,因为DIN采用类似attention的机制,只有历史的行为的attention才对后续的有影响,所以hist只包含pos_item之前点击的item才有意义。例如,对于reviewerID=0的用户,构造的训练集为:

测试集的构造方法:
对于每个pos_list和neg_list的最后一个item,用做生成测试集,测试集的格式为(reviewerID, hist, (pos_item, neg_item))

二、模型构建
2.1 DIN模型简介
相比于之前很多 “学术风” 的深度学习模型,阿里巴巴提出的 DIN 模型显然更具业务气息。它的应用场景是阿里巴巴的电商广告推荐,因此在计算一个用户是否点击一个广告 a 时,模型的输入特征自然分为两大部分:一部分是用户 u 的特征组,另一部分是候选广告 a 的特征组。无论是用户还是广告,都含有两个非常重要的特征:商品 id (good_id) 和商铺 id (shop_id)。用户特征里的商品 id 是一个序列,代表用户曾经点击过的商品集合,商铺 id 同理;而广告特征里的商品 id 和商铺 id 就是广告对应的商品 id 和商铺 id。
在原来的基础模型中,用户特征组中的商品序列和商铺序列经过简单的平均池化操作后就进入上层神经网络进行下一步训练,序列中的商品既没有区分重要程度,也和广告特征中的商品 id 没有关系。

然而事实上,广告特征和用户特征的关联程度是非常强的。假设广告中的商品是键盘,用户的点击商品序列中有几个不同的商品 id 分别是鼠标、T 恤和洗面奶。从常识出发,“鼠标” 这个历史商品 id 对预测 “键盘” 广告的点击率的重要程度应大于后两者。从模型的角度来说,在建模过程中投给不同特征的 “注意力” 理应有所不同,而且 “注意力得分” 的计算理应与广告特征有相关性。
将上述注意力的思想反映到模型中也是直观的,利用候选商品和历史行为商品之间的相关性计算出一个权重,这个权重就到表了注意力的强弱:


2.2 DIN代码结构概述
DIN代码是从train.py开始,在train.py中:
- 获取 训练数据 和 测试数据,这两个都是数据迭代器,用于数据的不断输入,定义在input.py中
- 生成相应的model,定义在model.py中
2.3 input.py
构建数据迭代器,用于训练数据和测试数据的不断输入
import numpy as npclass DataInput:def __init__(self, data, batch_size):self.batch_size = batch_sizeself.data = dataself.epoch_size = len(self.data) // self.batch_sizeif self.epoch_size * self.batch_size < len(self.data):self.epoch_size += 1self.i = 0def __iter__(self):return selfdef next(self):if self.i == self.epoch_size:raise StopIterationts = self.data[self.i * self.batch_size : min((self.i+1) * self.batch_size,len(self.data))]self.i += 1u, i, y, sl = [], [], [], []for t in ts:u.append(t[0])i.append(t[2])y.append(t[3])sl.append(len(t[1]))max_sl = max(sl)hist_i = np.zeros([len(ts), max_sl], np.int64)k = 0for t in ts:for l in range(len(t[1])):hist_i[k][l] = t[1][l]k += 1# u 是user_id, map后的# i 是item_id, map后的# y 是label, 1代表postive example, 0代表negtive example# hist_i 是用户的购买序列, 统一被填充成了max_sl(行为序列的最大长度)的长度# sl 是该用户的行为序列的长度return self.i, (u, i, y, hist_i, sl)class DataInputTest:def __init__(self, data, batch_size):self.batch_size = batch_sizeself.data = dataself.epoch_size = len(self.data) // self.batch_sizeif self.epoch_size * self.batch_size < len(self.data):self.epoch_size += 1self.i = 0def __iter__(self):return selfdef next(self):if self.i == self.epoch_size:raise StopIterationts = self.data[self.i * self.batch_size : min((self.i+1) * self.batch_size,len(self.data))]self.i += 1u, i, j, sl = [], [], [], []for t in ts:u.append(t[0])i.append(t[2][0])j.append(t[2][1])sl.append(len(t[1]))max_sl = max(sl)hist_i = np.zeros([len(ts), max_sl], np.int64)k = 0for t in ts:for l in range(len(t[1])):hist_i[k][l] = t[1][l]k += 1# u 是user_id, map后的# i 是positive item, map后的# j 是negtive item, map后的# hist_i 是用户的购买序列, 统一被填充成了max_sl(行为序列的最大长度)的长度# sl 是该用户的行为序列的长度return self.i, (u, i, j, hist_i, sl)
2.4 model.py
模型结构为:

import tensorflow as tf
from Dice import diceclass Model(object):def __init__(self,user_count,item_count,cate_count,cate_list):# shape: [B], user id。 (B:batch size)self.u = tf.placeholder(tf.int32, [None, ])# shape: [B] i: 正样本的itemself.i = tf.placeholder(tf.int32, [None, ])# shape: [B] j: 负样本的itemself.j = tf.placeholder(tf.int32, [None, ])# shape: [B], y: labelself.y = tf.placeholder(tf.float32, [None, ])# shape: [B, T] #用户行为特征(User Behavior)中的item序列。T为序列长度self.hist_i = tf.placeholder(tf.int32, [None, None])# shape: [B]; sl:sequence length,User Behavior中序列的真实序列长度(?)self.sl = tf.placeholder(tf.int32, [None, ])#learning rateself.lr = tf.placeholder(tf.float64, [])hidden_units = 128# shape: [U, H], user_id的embedding weight. U是user_id的hash bucket size# tf.get_variable函数的作用是创建新的tensorflow变量user_emb_w = tf.get_variable("user_emb_w", [user_count, hidden_units])# shape: [I, H//2], item_id的embedding weight. I是item_id的hash bucket sizeitem_emb_w = tf.get_variable("item_emb_w", [item_count, hidden_units // 2]) # [I, H//2]# shape: [I], biasitem_b = tf.get_variable("item_b", [item_count],initializer=tf.constant_initializer(0.0))# shape: [C, H//2], cate_id的embedding weight.cate_emb_w = tf.get_variable("cate_emb_w", [cate_count, hidden_units // 2])# shape: [C, H//2]cate_list = tf.convert_to_tensor(cate_list, dtype=tf.int64)# 从cate_list中取出正样本的cate# tf.gather是从params的axis维根据indices的参数值获取切片ic = tf.gather(cate_list, self.i)# 正样本的embedding,embedding由item_id和cate_id的embedding concat而成i_emb = tf.concat(values=[tf.nn.embedding_lookup(item_emb_w, self.i),tf.nn.embedding_lookup(cate_emb_w, ic),], axis=1)# 偏置bi_b = tf.gather(item_b, self.i)# 从cate_list中取出负样本的catejc = tf.gather(cate_list, self.j)# 负样本的embedding,embedding由item_id和cate_id的embedding concat而成j_emb = tf.concat([tf.nn.embedding_lookup(item_emb_w, self.j),tf.nn.embedding_lookup(cate_emb_w, jc),], axis=1)# 偏置bj_b = tf.gather(item_b, self.j)# 用户行为序列(User Behavior)中的cate序列hc = tf.gather(cate_list, self.hist_i)# 用户行为序列(User Behavior)的embedding,包括item序列和cate序列h_emb = tf.concat([tf.nn.embedding_lookup(item_emb_w, self.hist_i),tf.nn.embedding_lookup(cate_emb_w, hc),], axis=2)# attention操作hist_i = attention(i_emb, h_emb, self.sl) # -- attention end ---hist = tf.layers.batch_normalization(inputs=hist) hist = tf.reshape(hist,[-1,hidden_units])# (B, 1, H) -> (B, H)#添加一层全连接层,hist为输入,hidden_units为输出维数hist = tf.layers.dense(hist,hidden_units)u_emb = hist#下面两个全连接用来计算y',i为正样本,j为负样本# fcn begindin_i = tf.concat([u_emb, i_emb], axis=-1)din_i = tf.layers.batch_normalization(inputs=din_i, name='b1')d_layer_1_i = tf.layers.dense(din_i, 80, activation=None, name='f1')d_layer_1_i = dice(d_layer_1_i, name='dice_1_i')d_layer_2_i = tf.layers.dense(d_layer_1_i, 40, activation=None, name='f2')d_layer_2_i = dice(d_layer_2_i, name='dice_2_i')d_layer_3_i = tf.layers.dense(d_layer_2_i, 1, activation=None, name='f3')# (B, 1)din_j = tf.concat([u_emb, j_emb], axis=-1)din_j = tf.layers.batch_normalization(inputs=din_j, name='b1', reuse=True)d_layer_1_j = tf.layers.dense(din_j, 80, activation=None, name='f1', reuse=True)d_layer_1_j = dice(d_layer_1_j, name='dice_1_j')d_layer_2_j = tf.layers.dense(d_layer_1_j, 40, activation=None, name='f2', reuse=True)d_layer_2_j = dice(d_layer_2_j, name='dice_2_j')d_layer_3_j = tf.layers.dense(d_layer_2_j, 1, activation=None, name='f3', reuse=True)d_layer_3_i = tf.reshape(d_layer_3_i, [-1])d_layer_3_j = tf.reshape(d_layer_3_j, [-1])# (B,1) -> (B)#预测的(y正-y负)x = i_b - j_b + d_layer_3_i - d_layer_3_j # [B]#预测的(y正)self.logits = i_b + d_layer_3_i # (B)# i_b是偏置# train end# logits for all item:u_emb_all = tf.expand_dims(u_emb, 1)u_emb_all = tf.tile(u_emb_all, [1, item_count, 1])#将所有的除u_emb_all外的embedding,concat到一起all_emb = tf.concat([item_emb_w,tf.nn.embedding_lookup(cate_emb_w, cate_list)], axis=1)all_emb = tf.expand_dims(all_emb, 0)all_emb = tf.tile(all_emb, [512, 1, 1])# 将所有的embedding,concat到一起din_all = tf.concat([u_emb_all, all_emb], axis=-1)din_all = tf.layers.batch_normalization(inputs=din_all, name='b1', reuse=True)d_layer_1_all = tf.layers.dense(din_all, 80, activation=None, name='f1', reuse=True)d_layer_1_all = dice(d_layer_1_all, name='dice_1_all')d_layer_2_all = tf.layers.dense(d_layer_1_all, 40, activation=None, name='f2', reuse=True)d_layer_2_all = dice(d_layer_2_all, name='dice_2_all')d_layer_3_all = tf.layers.dense(d_layer_2_all, 1, activation=None, name='f3', reuse=True)d_layer_3_all = tf.reshape(d_layer_3_all, [-1, item_count])self.logits_all = tf.sigmoid(item_b + d_layer_3_all)# -- fcn end -------self.mf_auc = tf.reduce_mean(tf.to_float(x > 0))self.score_i = tf.sigmoid(i_b + d_layer_3_i)self.score_j = tf.sigmoid(j_b + d_layer_3_j)self.score_i = tf.reshape(self.score_i, [-1, 1])self.score_j = tf.reshape(self.score_j, [-1, 1])self.p_and_n = tf.concat([self.score_i, self.score_j], axis=-1)# Step variableself.global_step = tf.Variable(0, trainable=False, name='global_step')self.global_epoch_step = tf.Variable(0, trainable=False, name='global_epoch_step')self.global_epoch_step_op = tf.assign(self.global_epoch_step, self.global_epoch_step + 1)# loss and trainself.loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits,labels=self.y))trainable_params = tf.trainable_variables()self.train_op = tf.train.GradientDescentOptimizer(learning_rate=self.lr).minimize(self.loss)def train(self,sess,uij,l):loss,_ = sess.run([self.loss,self.train_op],feed_dict={#self.u : uij[0],self.i : uij[1],self.y : uij[2],self.hist_i : uij[3],self.sl : uij[4],self.lr : l})return lossdef eval(self, sess, uij):u_auc, socre_p_and_n = sess.run([self.mf_auc, self.p_and_n], feed_dict={#self.u: uij[0],self.i: uij[1],#正样本self.j: uij[2],#负样本self.hist_i: uij[3],self.sl: uij[4],})return u_auc, socre_p_and_ndef test(self, sess, uid, hist_i, sl):return sess.run(self.logits_all, feed_dict={self.u: uid,self.hist_i: hist_i,self.sl: sl,})def save(self, sess, path):saver = tf.train.Saver()saver.save(sess, save_path=path)def restore(self, sess, path):saver = tf.train.Saver()saver.restore(sess, save_path=path)def extract_axis_1(data, ind):batch_range = tf.range(tf.shape(data)[0])indices = tf.stack([batch_range, ind], axis=1)res = tf.gather_nd(data, indices)return res#item_embedding,history_behivior_embedding,sequence_length
def attention(queries,keys,keys_length):'''queries: [B, H] [batch_size,embedding_size]keys: [B, T, H] [batch_size,T,embedding_size]keys_length: [B] [batch_size]#T为历史行为序列长度'''#(?,32)->(None,32)->32# tile()函数是用来对张量(Tensor)进行扩展的,其特点是对当前张量内的数据进行一定规则的复制。最终的输出张量维度不变# tf.shape(keys)[1]==T# 对queries的维度进行reshape# (?,T,32)这里是为了让queries和keys的维度相同而做的操作# (?,T,128)把u和v以及u v的element wise差值向量合并起来作为输入,# 然后喂给全连接层,最后得出两个item embedding,比如u和v的权重,即g(Vi,Va)queries_hidden_units = queries.get_shape().as_list()[-1]queries = tf.tile(queries,[1,tf.shape(keys)[1]])queries = tf.reshape(queries,[-1,tf.shape(keys)[1],queries_hidden_units])din_all = tf.concat([queries,keys,queries-keys,queries * keys],axis=-1) # B*T*4H# 三层全链接(d_layer_3_all为训练出来的atteneion权重)d_layer_1_all = tf.layers.dense(din_all, 80, activation=tf.nn.sigmoid, name='f1_att')d_layer_2_all = tf.layers.dense(d_layer_1_all, 40, activation=tf.nn.sigmoid, name='f2_att')d_layer_3_all = tf.layers.dense(d_layer_2_all, 1, activation=None, name='f3_att') #B*T*1#为了让outputs维度和keys的维度一致outputs = tf.reshape(d_layer_3_all,[-1,1,tf.shape(keys)[1]]) #B*1*T# bool类型 tf.shape(keys)[1]为历史行为序列的最大长度,keys_length为人为设定的参数,# 如tf.sequence_mask(5,3) 即为array[True,True,True,False,False]# 函数的作用是为了后面补齐行为序列,获取等长的行为序列做铺垫key_masks = tf.sequence_mask(keys_length,tf.shape(keys)[1])#在第二维增加一维,也就是由B*T变成B*1*Tkey_masks = tf.expand_dims(key_masks,1) # B*1*T#tf.ones_like新建一个与output类型大小一致的tensor,设置填充值为一个很小的值,而不是0,padding的mask后补一个很小的负数,这样softmax之后就会接近0paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)#填充,获取等长的行为序列# tf.where(condition, x, y),condition是bool型值,True/False,返回值是对应元素,condition中元素为True的元素替换为x中的元素,为False的元素替换为y中对应元素#由于是替换,返回值的维度,和condition,x , y都是相等的。outputs = tf.where(key_masks,outputs,paddings) # B * 1 * T# Scale(缩放)outputs = outputs / (keys.get_shape().as_list()[-1] ** 0.5)# Activationoutputs = tf.nn.softmax(outputs) # B * 1 * T# Weighted Sum outputs=g(Vi,Va) keys=Vi#这步为公式中的g(Vi*Va)*Vioutputs = tf.matmul(outputs,keys) # B * 1 * H 三维矩阵相乘,相乘发生在后两维,即 B * (( 1 * T ) * ( T * H ))return outputs
2.5 train.py
import os
import time
import pickle
import random
import numpy as np
import tensorflow as tf
import sys
from input import DataInput, DataInputTest
from model import Modelos.environ['CUDA_VISIBLE_DEVICES'] = '1'
random.seed(1234)
np.random.seed(1234)
tf.set_random_seed(1234)train_batch_size = 32
test_batch_size = 512
predict_batch_size = 32
predict_users_num = 1000
predict_ads_num = 100with open('dataset.pkl', 'rb') as f:train_set = pickle.load(f)test_set = pickle.load(f)cate_list = pickle.load(f)user_count, item_count, cate_count = pickle.load(f)best_auc = 0.0
def calc_auc(raw_arr):"""SummaryArgs:raw_arr (TYPE): DescriptionReturns:TYPE: Description"""# sort by pred value, from small to bigarr = sorted(raw_arr, key=lambda d:d[2])auc = 0.0fp1, tp1, fp2, tp2 = 0.0, 0.0, 0.0, 0.0for record in arr:fp2 += record[0] # noclicktp2 += record[1] # clickauc += (fp2 - fp1) * (tp2 + tp1)fp1, tp1 = fp2, tp2# if all nonclick or click, disgardthreshold = len(arr) - 1e-3if tp2 > threshold or fp2 > threshold:return -0.5if tp2 * fp2 > 0.0: # normal aucreturn (1.0 - auc / (2.0 * tp2 * fp2))else:return Nonedef _auc_arr(score):score_p = score[:,0]score_n = score[:,1]#print "============== p ============="#print score_p#print "============== n ============="#print score_nscore_arr = []for s in score_p.tolist():score_arr.append([0, 1, s])for s in score_n.tolist():score_arr.append([1, 0, s])return score_arr
def _eval(sess, model):auc_sum = 0.0score_arr = []for _, uij in DataInputTest(test_set, test_batch_size):auc_, score_ = model.eval(sess, uij)score_arr += _auc_arr(score_)auc_sum += auc_ * len(uij[0])test_gauc = auc_sum / len(test_set)Auc = calc_auc(score_arr)global best_aucif best_auc < test_gauc:best_auc = test_gaucmodel.save(sess, 'save_path/ckpt')return test_gauc, Aucdef _test(sess, model):auc_sum = 0.0score_arr = []predicted_users_num = 0print "test sub items"for _, uij in DataInputTest(test_set, predict_batch_size):if predicted_users_num >= predict_users_num:breakscore_ = model.test(sess, uij)score_arr.append(score_)predicted_users_num += predict_batch_sizereturn score_[0]gpu_options = tf.GPUOptions(allow_growth=True)
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) as sess:model = Model(user_count, item_count, cate_count, cate_list, predict_batch_size, predict_ads_num)sess.run(tf.global_variables_initializer())sess.run(tf.local_variables_initializer())print('test_gauc: %.4f\t test_auc: %.4f' % _eval(sess, model))sys.stdout.flush()lr = 1.0start_time = time.time()for _ in range(50):random.shuffle(train_set)epoch_size = round(len(train_set) / train_batch_size)loss_sum = 0.0for _, uij in DataInput(train_set, train_batch_size):# 获取 训练数据 ,这是一个数据迭代器,用于数据的不断输入# uij是一个五元组 (u, i, y, hist_i, sl)# u 是user_id, map后的# i 是item_id, map后的# y 是label, 1代表postive example, 0代表negtive example# hist_i 是用户的购买序列, 统一被填充成了max_sl(行为序列的最大长度)的长度# sl 是该用户的行为序列的长度loss = model.train(sess, uij, lr)loss_sum += lossif model.global_step.eval() % 1000 == 0:test_gauc, Auc = _eval(sess, model)print('Epoch %d Global_step %d\tTrain_loss: %.4f\tEval_GAUC: %.4f\tEval_AUC: %.4f' %(model.global_epoch_step.eval(), model.global_step.eval(),loss_sum / 1000, test_gauc, Auc))sys.stdout.flush()loss_sum = 0.0if model.global_step.eval() % 336000 == 0:lr = 0.1print('Epoch %d DONE\tCost time: %.2f' %(model.global_epoch_step.eval(), time.time()-start_time))sys.stdout.flush()model.global_epoch_step_op.eval()print('best test_gauc:', best_auc)sys.stdout.flush()参考资料
- DIN论文官方实现解析
- 广告点击率预估模型—DIN的Tensorflow2.X代码分析
- 推荐系统之DIN代码详解
- DIN算法代码详细解读
这篇关于【推荐算法代码实现】Deep Interest Network for Click-Through Rate Prediction代码实现和解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




