本文主要是介绍Multi-Source Domain Adaptation for Text Classification via DistanceNet-Bandits论文学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 摘要
目标域上的学习算法的域适应性能是其源域的误差和两个域的数据分布的散度度量。我们在NLP任务的上下文任务中研究了各种基于距离的方法,根据样本估计来描述域之间的差异。我们首先进行了分析实验来展示哪种距离度量方法可以最好地区分样本来自相同领域还是不同领域,和实际结果相关。接下来,我们研究了一种叫做DistanceNet的模型,这个模型使用这些距离度量的方法,或者将这些度量方法混合,作为一种额外的损失函数来和任务的损失函数一起进行优化,是以为了获得更好的无监督域适应。最后,我们扩展这个模型。变成了一个新型的距离网络多臂老虎机,使用多臂老虎机控制器来在多资源域中进行动态切换,允许模型学习一种最优的轨迹和域混合转移到低资源的目标域 - 关于域适应的几种 方法
通过在不同阶段进行领域自适应,研究者提出了三种不同的领域自适应方法:1)样本自适应,对源域样本进行加权重采样,从而逼近目标域的分布。2)特征层面自适应,将源域和目标域投影到公共特征子空间。3)模型层面自适应,对源域误差函数进行修改,考虑目标域的误差。 - 介绍
在大规模标签数据可用的情况下,监督学习算法已经在NLP挑战中取得了显著的进展。大部分监督学习算法依赖的假设是数据分布在训练和测试时是一样的。然而,在很多真实生活场景中,在测试时间的数据分布可能和训练不一样,由于金钱和时间的限制,收集新数据的过程是不可度量的。因此,域适应的目的是构造一个算法,当给定从源域上的观察样本时,能够适应其表现在目标域上,目标域的数据分布通常是不一样的。在域适应领域中主要包括两种方法,监督域适应和非监督域适应。前者的方法是,目标域中有限的训练数据可以为信号提供监督,然而,后者只有未标记的目标域数据是可用的。在这篇文章中,我们关注非监督域适应,并且表明域适应的性能被三个因素影响。第一个是源任务的模型性能,受益于最近神经模型的进步,并且与我们的重点是正交的。第二个因素是跨域标记函数的差异,这是属性所固有的数据集在实践中可能很小(Ben-David et al.2010)。第三个因素代表了对数据分布散度的度量——如果源域和目标域之间的数据分布相似,我们可以合理地期望在源域上训练的模型在目标域上表现良好。我们的工作主要集中在最后一个因素上,目的是在NLP的背景下研究以下两个问题:如何准确地估计一对域(第3节和第6节)之间的差异,以及如何利用这些域的差异度量来改进域适应学习。
最后,我们首先提供了几种于距离度量的详细的研究(对比,模型和分析),以可伸缩性(易于计算)、可微性(可最小化)和可解释性(以一种简单的分析形式,具有经过充分研究的特性)为目标。我们首先在第3节中定义这些距离度量,并在第6节中提供一组分析来评估它们:(1)这些距离度量分隔域的能力,以及(2)这些距离度量与实证结果之间的相关性。从这些分析中,我们注意到不存在一个适合所有的最佳距离度量,并且每个度量提供了一个可以互补的域距离估计值(例如,基于差异和类分离)。因此,我们也建议使用混合的距离测量,其中我们额外引入了一个无监督的标准来选择最佳的距离测量,以减少混合时额外的超参数的重量。基于差异和类分离)。在上述分析的激励下,我们继续提出一个简单的“DistanceNet”模型(见第4节),该模型将这些度量集成到训练优化中。特别是,我们增加了一个额外的距离测量分类任务损失函数。通过最小化来自源和目标域的特征之间的表示距离,该模型可以更好地学习与域无关的特征。最后,当来自多个源域的数据存在时,我们学习这些域的动态调度在不训练的情况下,最大限度地提高学习效果目标任务通过将动态域选择问题构建为一个多臂老虎机问题,其中每个支臂代表一个候选源域 - 相关工作
- 域距离度量方法
在第一部分,我们阐明了域适应性能和域距离或相似度有关。我们首先介绍单独的距离度量方法,然后再描述我们对这些方法的混合。距离度量方法的目的是估计两个域有多么不同,我们将会介绍5中方法:L2距离,cosine距离,最大均值差异,线性判别分析和关系对齐。
符号表示
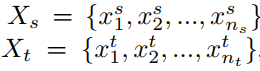
-
L2距离 描述源域和目标域样本的欧几里得距离;
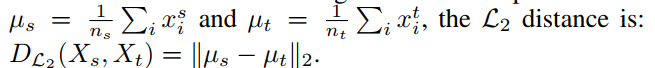
算出各自域的均值,再使用二范式 -
cosine距离 计算二者的相似性后计算差异1-s
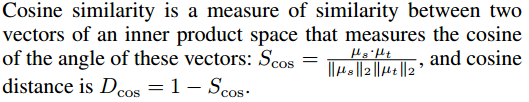
-
最大均值差异(MMD)
原假设和备择假设

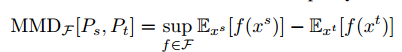
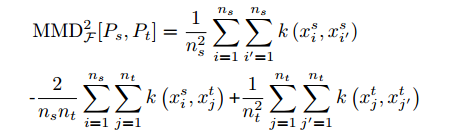
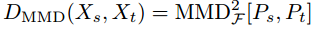
-
线性判别分析(FLD)
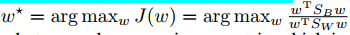
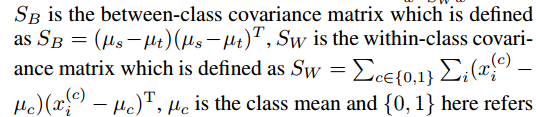
-
关系对齐
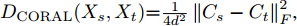
- 模型

1.基础模型
LSTM+FC
给定一个单词序列,我们首先将其嵌入到向量表示中,hT是LSTM的输出,之后用一个全连接层得出预测标签,分类的损失是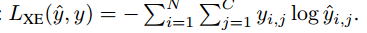
2.距离网络
总的损失函数 = 分类的交叉熵损失 + 距离度量
距离度量 指的是上面几种度量方法
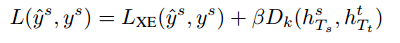
3. 使用多臂老虎机的动态多源的距离网络
当我们有大量的额外资源时,我们需要一个更好的方式来利用这些资源,一种比较简单的方法是将这些多资源看成是一个大的资源。这里使用的方法是多臂老虎机,

t是迭代次数,Nt(a)代表这个动作被选择的次数,A代表候选动作,Q(a)代表动作的值。
在本文中,动作指的大源中的一个个小源域。
在验证集上的损失函数作为多臂老虎机的奖励,用于调整源域选择的权重

这篇关于Multi-Source Domain Adaptation for Text Classification via DistanceNet-Bandits论文学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







