本文主要是介绍磁盘物理结构介绍(磁头,扇区),chs寻址,如何读写,磁盘io消耗时间;线性抽象结构,lba寻址,分区引入,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
磁盘文件
引入
看待角度
磁盘
介绍
物理结构
俯视图
立体图
磁头
扇区
如何找到一个扇区 -- CHS寻址
如何读写
磁盘io消耗时间
抽象结构 -- 线性
引入
介绍 -- LBA寻址
分区
引入
介绍
磁盘文件
引入
文件分为两种
- 被打开的文件(主要讨论与进程之间的联系)
- 没有被打开的文件(存放在磁盘上)
我们这里来介绍磁盘级别的文件
看待角度
- 从单个文件角度:文件具体存放在哪里,如何存储,大小是多少,属性有哪些
- 从系统角度:一共有多少个文件,内容和属性存放在哪里,如何快速找到指定的文件和对应的数据
为了了解磁盘文件,我们得先来认识磁盘是什么
磁盘
介绍
- 内存--掉点易失存储介质
- 磁盘--永久性存储介质(eg: ssd,u盘,flash卡,光盘,磁带)
- 磁盘属于冯诺依曼模型中的外设,是一种机械设备(所以它io速度很慢)
物理结构
俯视图
- 工作时,磁盘进行高速旋转(有不同的转速)
- 磁头会左右摇摆,进行寻址(数据其实就在磁盘上)

立体图

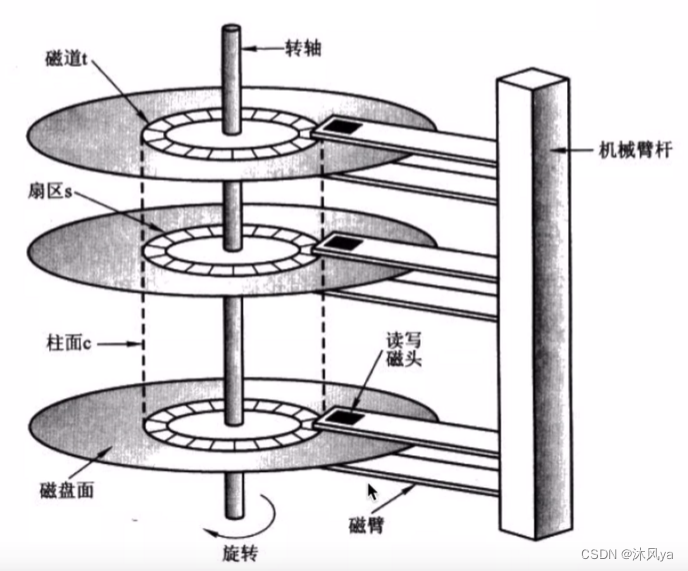
磁头
- 可以看到,磁盘并不是只有一片,它其实是多个磁盘叠放在一起的
- 磁盘的两面都可以存放数据,所以一个磁盘对应两个磁头
- 磁头并不是紧挨着磁盘,他俩中间有一定的距离
- 因为两者都会旋转
- 如果挨着,磁盘表面肯定会有一定程度的磨损,而数据也可能随之丢失
- 虽然他俩有距离,但其实距离很小
- 所以,一旦在磁盘工作过程中,电脑磕了碰了啥的,都可能会引起磁头和磁盘的接触,就可能磨损磁盘,数据就可能会丢失
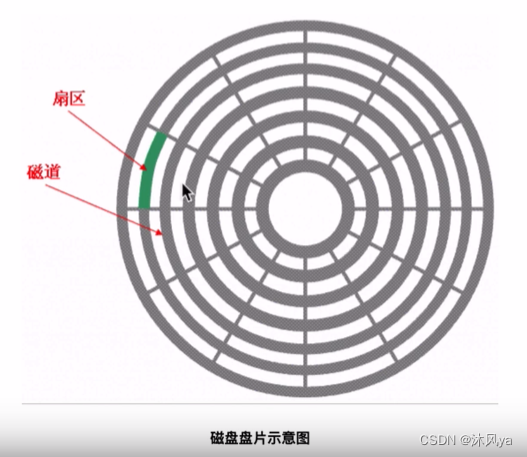
扇区
扇区是磁盘存储数据的基本单位,一个扇区一般占512字节
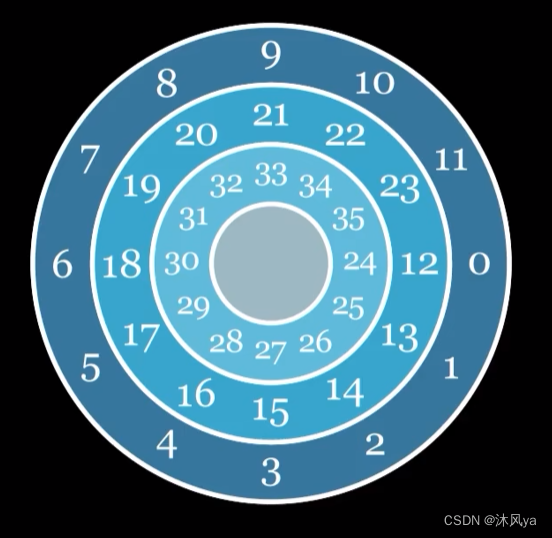
如何找到一个扇区 -- CHS寻址
因为存储数据的基本单位是扇区,那么我们进行读写的前提是找到扇区
- 首先确定在哪一个柱面
- 每个柱面对应磁头的一个位置,柱面由多个半径相同的磁道组成
- 然后移动磁头到对应的磁道上
- 再确定要找的扇区在哪个扇面上(也就是具体对应哪个磁头)
- 然后就可以找到对应的扇区了

如何读写
由于计算机只认识二进制,而数据都在盘面上,所以盘面上就存储了大量的二进制
类比于磁铁的正负极,盘面是通过磁性来区分0,1的
- 读取操作时,磁头感应磁性场盘面上的磁变化,并将其转换为对应的数据
- 写入操作时,磁头改变磁场的极性,将数据写入磁性盘面
磁盘io消耗时间

抽象结构 -- 线性
引入
- 随着磁盘容量的增加和计算机系统的发展,CHS寻址方式面临容量限制、复杂性和效率等问题
- 为了克服CHS寻址方式的限制,磁盘驱动器制造商引入了逻辑块寻址(LBA)方式
- LBA寻址方式将磁盘的物理位置抽象为一系列逻辑块,每个逻辑块都有唯一的逻辑块地址(LBA)
- 类比磁带,它看似是圆形结构,实际上圆盘是由非常长的线性磁带环绕而成
- 因此我们也可以将磁盘的盘片想象成线性的结构

介绍 -- LBA寻址
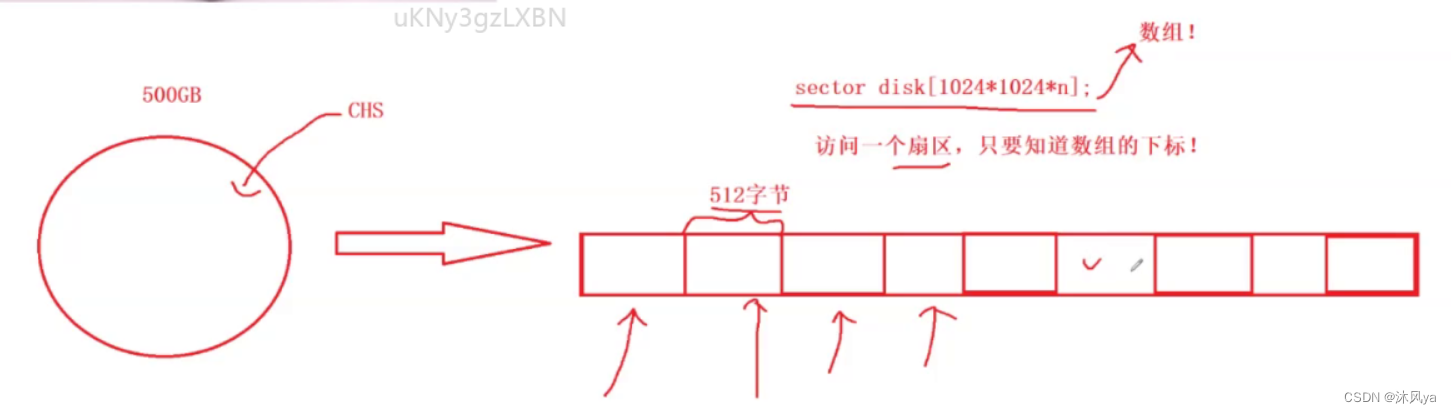
- 像上面那样抽象成线性结构,每一个扇区就变成了一个块状结构
- 如果平铺下来,是不是很像数组:
- 所以,访问扇区,只需要知道它所在的下标即可
- 这样的寻址方式就叫做LBA寻址
- 最终将LBA找到的扇区,转换为CHS上的物理结构即可
分区
引入
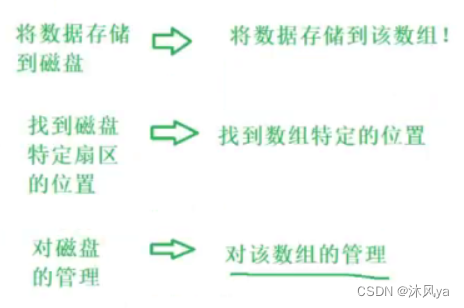
通过上面的抽象,我们对磁盘的操作,就变成了对数组的操作:
但是,磁盘通常容量很大,几百g甚至t,若将其看作一个整体,则太过于庞大
于是我们可以将它进行分区,这些分区以统一的视角去看待,就可以将大的问题简单化
介绍
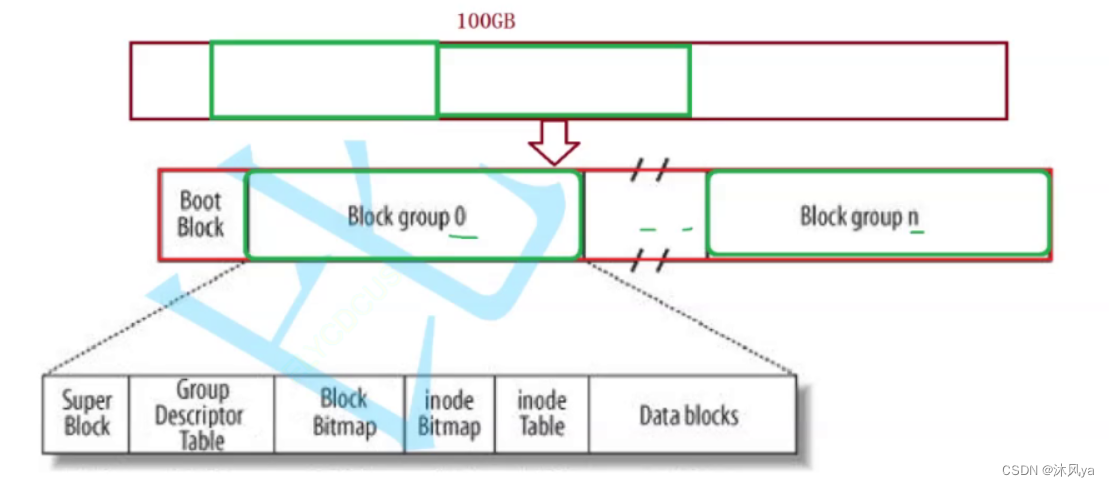
先将非常大容量的磁盘分区:
但是,这样分下来,每个区还是很大,不好管理
所以每个分区里面再进行分区:
不断分区...最终以块组为单位,组成磁盘
一个很大的磁盘 -> 多个分区 -> 很多个块组
所以只要管理好块组,分区就管理好了,分区管理好了,磁盘也就管理好噜~

这篇关于磁盘物理结构介绍(磁头,扇区),chs寻址,如何读写,磁盘io消耗时间;线性抽象结构,lba寻址,分区引入的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




