本文主要是介绍云智慧联合北航提出智能运维(AIOps)大语言模型及评测基准,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着各行业数字化转型需求的不断提高,人工智能、云计算、大数据等新技术的应用已不仅仅是一个趋势。各行业企业和组织纷纷投入大量资源,以满足日益挑剔的市场需求,追求可持续性和竞争力,这也让运维行业迎来了前所未有的挑战和机遇。
如何将LLM的强大特性与特定领域的需求相结合,成为了学术界和工业界密切关注的焦点。近日,云智慧智能研究院与北航合作,共同推出了首个专为运维领域定制的大语言模型——“Owl”,有效提高了IT相关任务在细分领域中的高效性、准确性和理解能力,相关微调和benchmark数据的开源更是为智能运维领域的专属大模型开源发展奠定了坚实基础。

背景介绍
随着IT业务的快速发展,,海量数据有效分析和管理在企业实际业务应用中变得变得日益关键。自然语言处理(NLP)技术已在命名实体识别、机器翻译等任务中显示出非凡的能力,大型语言模型(LLM)在各种 NLP 下游任务中更是取得了显著的改进。此时,基于Owl-Instruct 数据训练而成的大型语言模型——Owl 正好填补了智能运维(AIOps)对专属 LLM 的需求。研究提出了Mixture-of-Adapter strategy策略,以提高不同子领域或任务的微调效果。此外,由于缺乏智能运维领域的大语言模型的Benchmark,本次研究建立了 Owl-Bench 测评基准,同时在Owl-bench和其他运维相关的基准上进行了评估。实验表明,Owl 的性能超过了现有开源模型。
本次研究的主要贡献:
- 提出了Mixture-of-Adapter strategy策略,以提高不同子领域或任务的微调效果。
- 构建了智能运维领域的大语言模型的Benchmark:Owl-Bench 测评基准。
- 实验结果表明,Owl 的性能超过了现有开源模型。
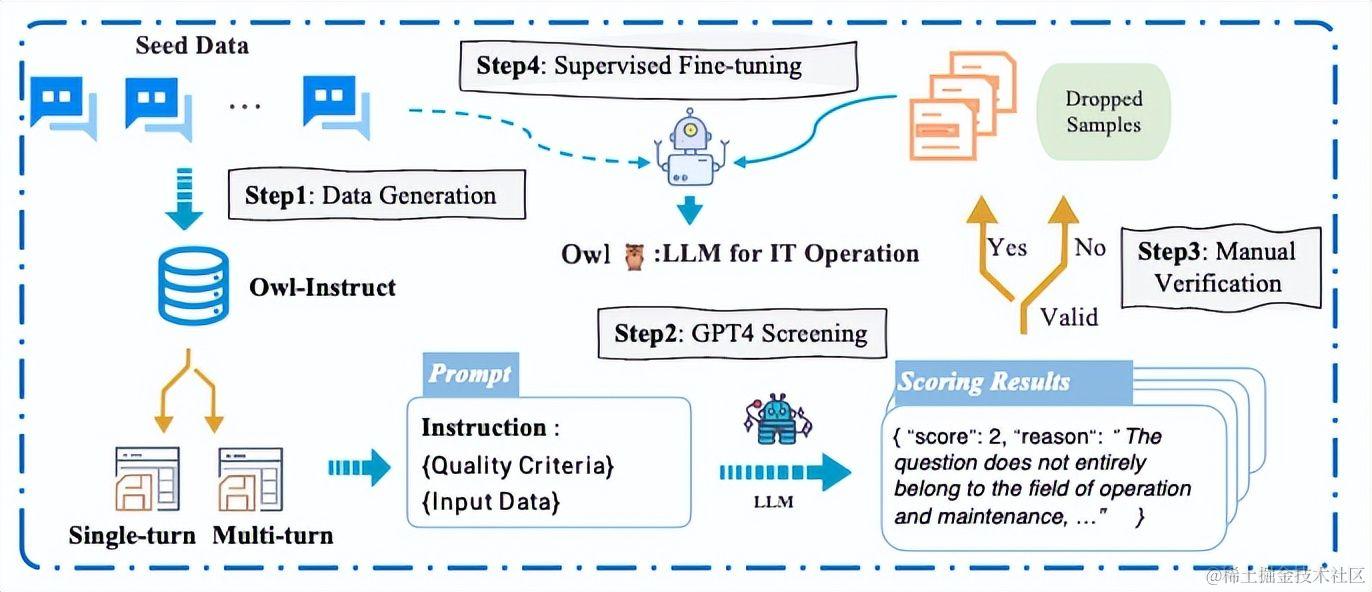
图1: Owl-Instruct数据构建和Owl训练流程
数据收集
第一步:种子数据搜集
基于云智慧智能运维专家丰富的运维经验,精心设计模型微调的数据样例和标注说明,涵盖了信息安全、应用程序、系统架构、软件架构、中间件、网络、操作系统、基础设施和数据库9个运维领域常见数据。在每个领域中,Owl-instruct都包含了不同的任务,例如运维知识问答、部署、监控、故障诊断、性能优化、日志分析、脚本编写、备份和恢复等。最终得到了一个由 2,000 个单轮和 1,000 个多轮对话的种子数据实例组成的语料库。
第二步:数据扩充
对于单轮数据,借鉴Self-Instruct的方法,最终产生了 9118 条数据。对于多轮对话数据,采用 Baize中阐明的方法,最终得到8,740条多轮对话数据。
第三步:数据质量
为了保持严格的数据质量标准,基于扩充的数据,在利用 GPT-4 对标注数据进行评分的同时,组织云智慧智能运维专家进行细致的人工验证。这种双重验证流程可确保生成数据的完整性和可靠性,同时提高数据的整体质量。在利用 GPT-4 进行评分时,针对数据集精心设计了特定的提示(prompt)。这些提示使 GPT-4 能够根据预定义的质量标准对生成的数据进行评估和评分,能够迅速识别并过滤低质量的数据实例。与此同时,数据还经过了由云智慧各智能运维专家组成的审核团的严格人工验证,审核团队会对每个数据条目进行深入评估,这一人工检查过程需要对内容、连贯性以及与特定领域知识的一致性进行彻底检查。
运维评测数据集Owl-Bench 构建
当前,运维领域评估大型语言模型性能的基准仍存在严重不足。为了弥补这一不足,云智慧构建了一个双语基准——Owl-Bench。Owl-Bench由两个不同的部分组成:317 个条目组成的问答部分和 1000 个问题组成的多选部分,涵盖了该领域的众多真实业务场景,确保Owl-Bench能够展现出多样性。测评集的收集过程包括信息安全、应用、系统架构、软件架构、中间件、网络、操作系统、基础设施和数据库9个不同的子领域。

图2: 根据词频生成的词云
实验结果
Owl-Bench实验结果
Owl-bench的实验结果包括问答题和选择题的结果,实验结果都证明了Owl相关能力的领先性。

图3: 问答题pairwise的结果, 以GPT4作为评测
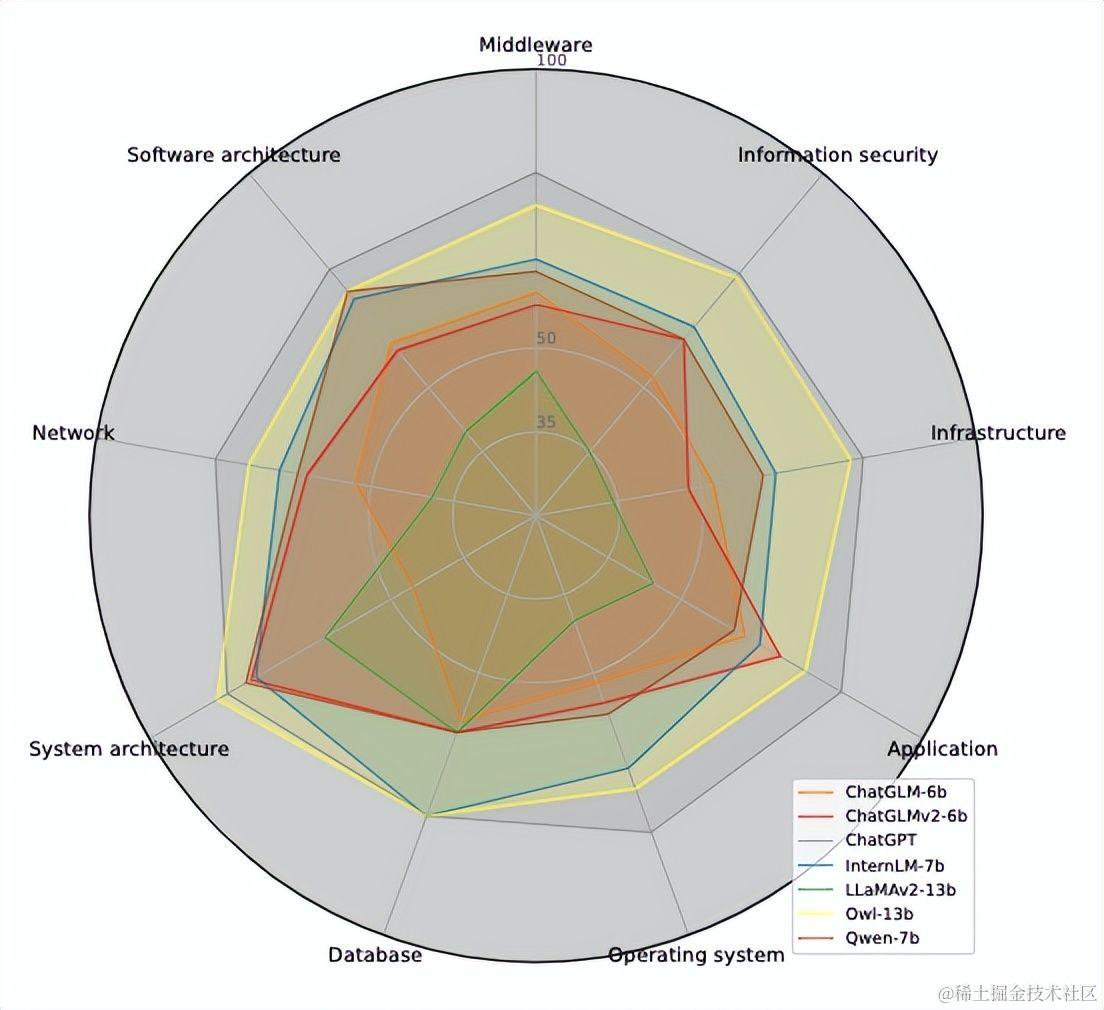
图4: 选择题zero-shot得分雷达图
运维领域下游任务
为了验证Owl在运维领域的泛化性,在运维相关下游任务进行了测试,选取了日志解析、日志异常检测两个典型任务进行了测试。对于这两个典型任务,设计了特定的prompt,相关实验证实了Owl的有效性。
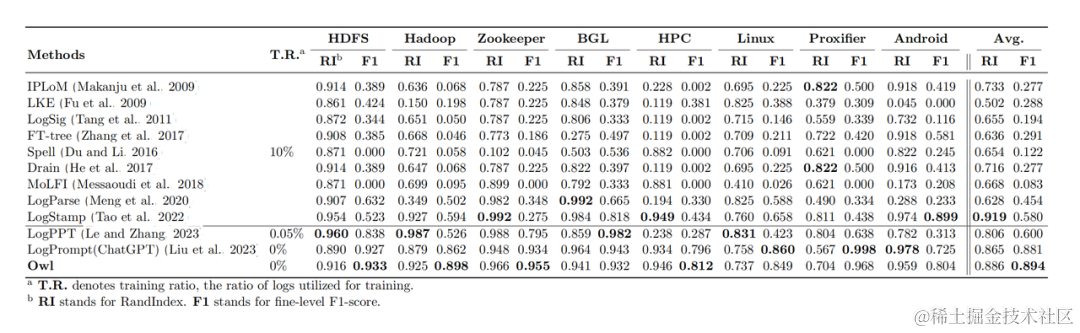
图5: 日志解析基准测试结果
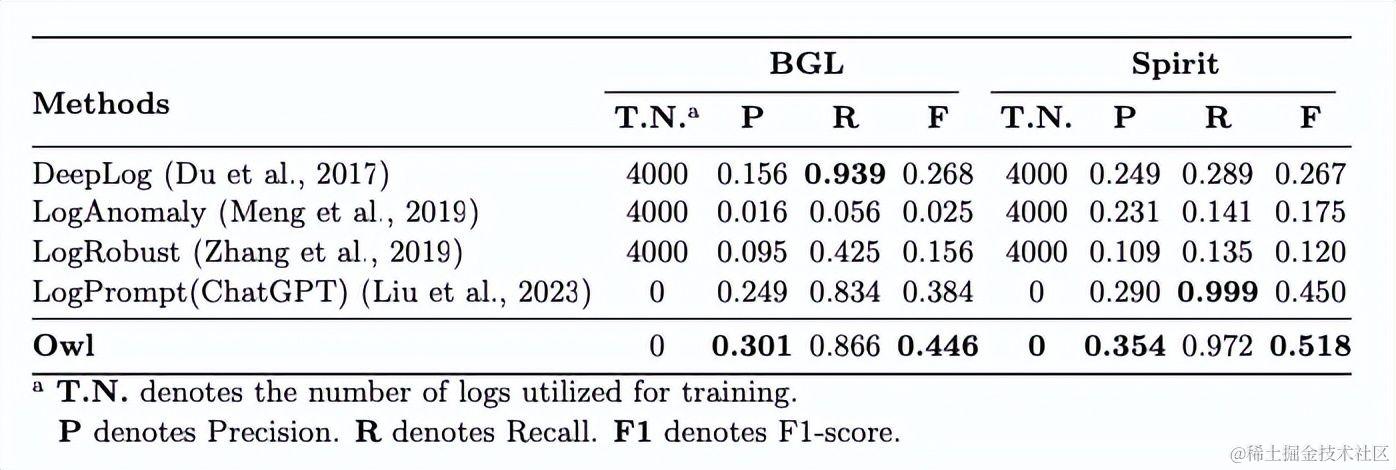
图6: 日志异常检测基准测试结果
结语
智能运维专属大模型“Owl”的问世将会成为智能运维行业发展的一个新转折点。随着各类新兴技术的应用,云智慧也将会为智能运维领域带来更多的突破和创新,进一步为各类企业提供创新的运维解决方案,提升企业的IT运维效能,促进数字化转型的成功实施。与此同时,“Owl”相关微调和benchmark数据的开源,将为智能运维领域的全生态开放发展贡献更多的研究和应用潜力。
论文链接:https://arxiv.org/abs/2309.09298 Owl : A Large Language Model for IT Operations(猫头鹰:用于 IT 运维的大型语言模型) 友情链接: https://mp.weixin.qq.com/s/LVFp8iYFCg0FouTUWVtFIw
这篇关于云智慧联合北航提出智能运维(AIOps)大语言模型及评测基准的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







