本文主要是介绍Investigating Neural Network based Query-by-Example Keyword Spotting Approach for Personalized Wake-,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Investigating Neural Network based Query-by-Example Keyword Spotting Approach for Personalized Wake-up Word Detection in Mandarin Chinese
基于神经网络的示例查询关键词识别方法在普通话个性化唤醒词检测中的研究
Abstract
我们使用示例查询关键字查找(QbyE-KWS)方法来解决针对占地空间小,计算成本低的设备应用的个性化唤醒单词检测问题。 QbyE-KWS将关键字作为模板,并通过DTW在音频流中匹配模板,以查看是否包含关键字。在本文中,我们使用神经网络作为声学模型来提取DNN / LSTM音素的后验特征和LSTM嵌入特征。具体来说,我们研究了LSTM嵌入特征提取器,用于普通话中不同的建模单元,从音素到单词。我们还研究了两种流行的DTW方法的性能:S-DTW和SLN-DTW。 SLN-DTW无需在S-DTW方法中使用分段过程,就可以准确有效地搜索长音频流中的关键字。我们的研究表明,与S-DTW方法相比,DNN音素后验加SLN-DTW方法实现了最高的计算效率和最新性能,相对丢失率降低了78%。字级LSTM嵌入功能显示出比其他嵌入单元更高的性能。
索引词:关键字发现,唤醒词检测,DTW,示例查询,DNN,LSTM
1. Introduction
近年来,随着语音识别的飞速发展,出现了具有语音接口的各种应用,例如直接语音输入,移动助手和智能扬声器等。作为激活这些语音接口的第一步,唤醒单词检测旨在使用特定的单词来唤醒具有完全免提体验的自动语音识别(ASR)模块。此外,作为关键字发现(KWS)技术,它还可以用于命令和控制功能。例如,某些智能手机具有通过语音关键字启用的语音控制摄像头。
根据关键字是预先设置还是可以由用户定义,唤醒词检测或关键字发现可分为两类:固定KWS和个性化KWS。前者使用预定义的关键字来激活设备。例如,Amazon Echo使用“ Alexa”来激活其语音助手,而Google使用“ Okay Google”来访问语音服务。后者支持用户自定义自己的关键字或为不同的设备设置不同的唤醒词。用户可以通过说几次来注册自己的唤醒词,然后使用它来激活自己的设备。随着智能设备的普及,个性化的KWS由于其灵活性和个性化而具有许多潜在的应用。
在上述语音支持的应用程序中,
唤醒模块必须在嵌入式或移动设备上持续监听。因此,迫切需要一种适用于设备上应用的小内存占用空间和低计算成本的解决方案。为了有效地将个性化关键字用于设备上的应用程序,可以优先考虑使用QbyE-KWS系统。作为典型的解决方案,QbyE-KWS将关键字作为模板,并通过动态时间规整(DTW)在音频流中匹配模板,以查看关键字是否包含在内。
在过去的几年中,神经网络已成为声学建模[1,2]和功能学习[3,4]的强大工具。最近,在基于DTW的QbyE-KWS中,建议将深度神经网络(DNN)作为特殊的特征提取器[5,6,7,8]。例如,测试音频中的关键字和段可以分别由DNN生成的音素后序表示,而DTW的滑动变体–分段DTW(S-DTW)[9]用于测量音频。他们之间的距离。最近,Chen等。使用带有长短期记忆(LSTM)单元的递归神经网络(RNN)作为序列特征提取器,将关键词嵌入和将音频片段测试成固定尺寸的矢量表示。使用固定尺寸的向量,可以通过典型的距离度量(例如余弦)轻松绕过耗时的DTW计算来轻松测量关键词与测试音频之间的相似度。他们特别指出,由于LSTM具有很长的上下文建模能力,因此将整个单词用作嵌入目标可以在个性化唤醒单词检测中实现出色的性能。
在本文中,我们提供了基于神经网络的QbyE-KWS方法的系统研究,该方法用于普通话中的个性化唤醒单词检测。具体来说,我们使用神经网络来提取特征,其中包括LSTM嵌入特征[5]和DNN / LSTM音素后验特征。我们还研究了两种流行的DTW方法的QbyE-KWS性能:S-DTW和分段局部归一化DTW(SLN-DTW)。我们的贡献如下。
•我们研究了普通话中不同建模单元的LSTM嵌入功能提取器。 众所周知,汉语有多个语音和语言单元:音调/非音调,音调/非音调,字符和单词。 我们希望看到哪个单元在基于LSTM功能提取器的个性化唤醒字检测中提供了最佳性能。
•我们在基于QbyE-KWS的唤醒字检测中引入了SLN-DTW [10、11、12、6]。 SLN-DTW可以准确而有效地搜索长音频流中的关键字,而无需使用S-DTW方法中使用的分段过程。
我们的研究表明,后验DNN音素加SLN-DTW方法具有最高的计算效率,并且在0.005的误报率下以0.029的最低遗漏率实现了最新的性能。 字级LSTM嵌入功能显示出比其他嵌入单元更高的性能。
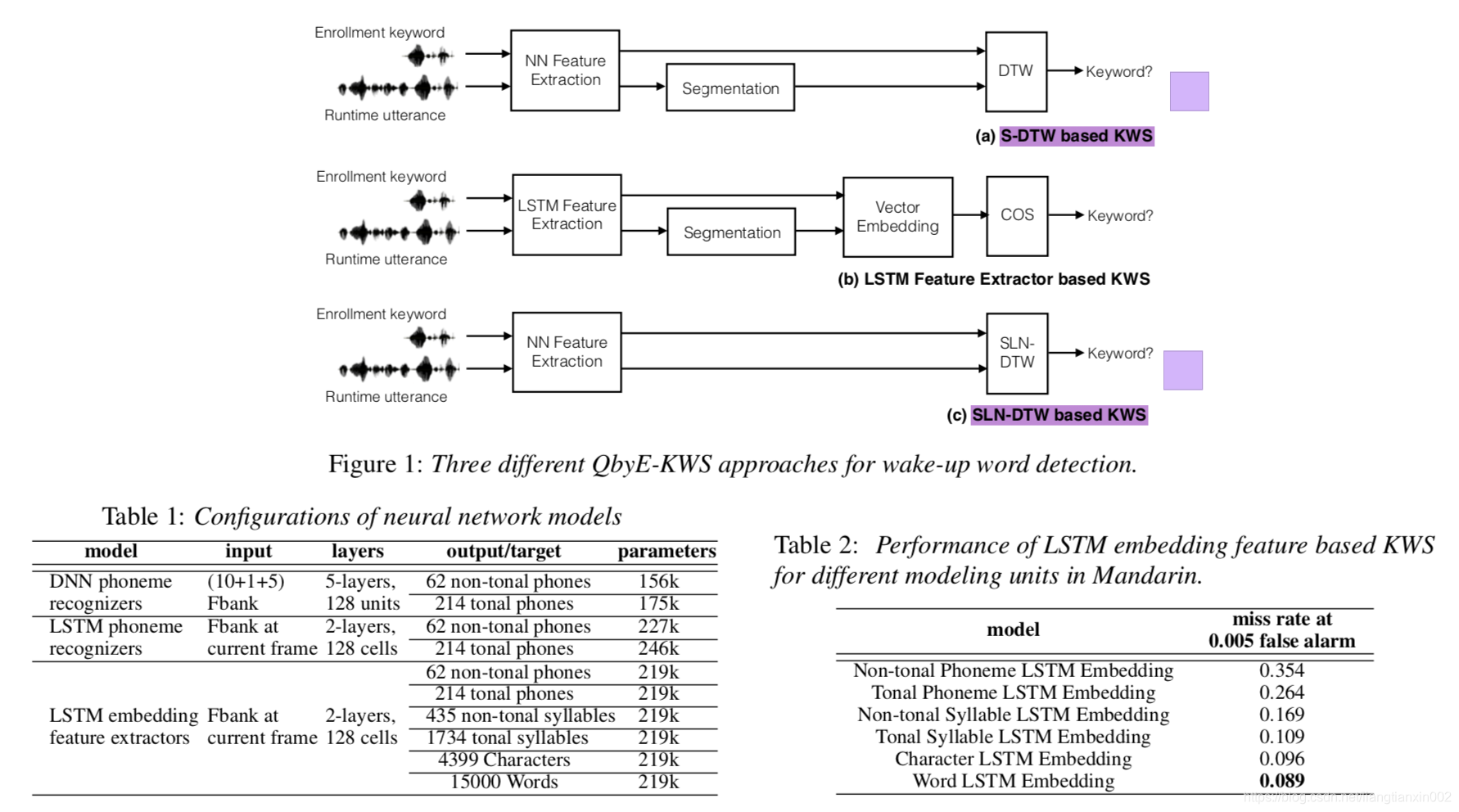
2. Neural Network based QByE KWS
如图1所示,典型的QbyE-KWS系统由两个模块组成-特征提取和关键字搜索。 代表性功能对于关键字搜索的性能至关重要。 尽管可以直接使用流行的声学特征,例如MFCC,FBank,PLP,但是基于模型的特征,例如音素和高斯后验[13,9],显示出对声学特征的更多判别能力,因此导致超音速。 -表现出色。 特别是在深度神经网络的主导下,DNN后代[13]和瓶颈特性[6、7、8]等DNN衍生的功能在QbyE-KWS中实现了卓越的性能。 同时,使用LSTM模型将音频序列嵌入到固定长度的表示中[5]。 在第二个模块中,距离度量用于关键字搜索,该关键字将关键字模板与测试音频进行比较。 基于所使用的特征表示,在匹配中通常采用DTW或一些常用距离,例如余弦。
2.1. Segmental DTW based KWS
我们无法使用普通的DTW直接测量注册关键字和测试音频之间的相似性。这是因为为唤醒应用程序设计的KWS系统需要连续收听输入声音。张等。 [9]提出使用滑动窗口将测试音频流划分为片段。在每个细分上,DTW用于通过关键字模板测量其距离。如果匹配分数超过预设阈值,则认为关键词被发现。实际上,段长度设置为关键字模板的长度。这种方法简称为分段DTW或S-DTW。请注意,为了使关键字的遗漏率最小化,通常使用段重叠。
如图1(a)所示,enrollment关键字和运行时语音首先经过NN特征提取器,从而得到帧级NN音素后验特征。在帧级NN音素后向量中表示的运行时话语被切成关键字大小的片段,并计算出关键字与每个片段之间的距离矩阵。然后从DTW对齐成本中计算出置信度得分。当费用超过某个阈值时,将考虑检测关键字。请注意,可以使用不同的NN模型,例如前馈深层神经网络和递归神经网络(RNN)。
2.2. LSTM FeatureExtractor based KWS
由于LSTM具有长序列建模能力,Chen等人。 [5]提出了一种LSTM特征提取器,将长度不同的音频片段嵌入到固定尺寸的表示中。因此,可以使用一个简单的距离(如余弦)直接测量两个序列的相似性。给定输入序列X = {x1,x2,...,xn},LSTM隐藏层和最后一层的输出为H = {h1,h2,...,hn}和Y = {y1,y2,。。 ..,yn}。由于LSTM的记忆机制,可以认为输出H * = {hn-k + 1,hn-k + 2,...,hn}的最后k帧,而Y * = {yn- k + 1,yn−k + 2,...,yn}包含序列X的大多数信息。如果我们选择相同的k帧作为特征向量,则
通过改变序列的长度,我们可以获得这些序列的LSTM嵌入表示。
如图1(b)所示,在注册阶段,我们堆叠LSTM RNN的最后一个隐藏层激活的最后k帧作为关键字的嵌入表示。实际上,如果每个关键字使用多个模板,例如,用户多次说出关键字来注册到系统,我们将使用基于DTW的模板平均值[10,5]来获得该关键字的新嵌入表示。注册关键字。请注意,注册是一个脱机过程。
在运行时阶段,类似地,我们提取LSTM嵌入特征以用于运行时话语,然后使用滑动窗口对测试音频进行分段。滑动窗口的大小通常设置为k帧,因此我们可以使用关键字和运行时语音段之间的堆叠向量的余弦距离来测量关键字和运行时语音之间的相似性。
2.3。基于分段局部归一化DTW的KWS
上面的KWS系统都需要一个滑动窗口来分割运行时语音。此外,窗口大小和移动大小通常是凭经验确定的,如果设置不当会影响KWS的性能。相反,分段局部标准化DTW(SLN-DTW)[10、14、15]可以有效地在没有分段过程的情况下,在长音频流中有效地搜索关键字。
给定从DNN特征提取器提取的两个特征向量序列,Q = {q1,q2,...,qn}和S = {s1,s2,...,sm},对应于注册关键字和测试发音计算余弦或其他距离矩阵dist,其中dist(i,j)表示关键字的框架i与测试发音的框架j之间的距离。 SLN-DTW的目的是在距离矩阵dist中找到从(1,s)到(n,e)(其中1≤b≤e≤m)的路径,从而将平均累计距离成本(i, j)= a(i,j)/ l(i,j),其中a(i,j)是从(1,s)到(i,j)的累积距离,而l(i,j)是路径(1,s)到(i,j)的长度。如下所述,使用动态编程算法来找到最佳匹配分数。

3. Experimental Setup
3.1。特征提取器的培训
表1中显示了我们训练的神经网络。我们首先训练了具有音调和非音调音素目标的前馈DNN音素识别器和LSTM音素识别器。它们用于基于S-DTW和SLN-DTW的KWS实验。 LSTM嵌入特征提取器与LSTM音素识别器保持相同的输入和网络结构。与[5]不同,在普通话中,我们尝试了不同的嵌入单元,即音调/非音调音调,音调/非音调音节,字符和单词。
我们使用一个25ms的窗口以及一个10ms的偏移量来提取帧级40维对数滤波器组(FBank)的能量,作为频谱特征,用作神经网络输入。以上所有的NN模型均使用Kaldi [16]在普通话语系中进行了训练,并从4000多个说话者那里录制了1115小时的语音(采样率:16KHz)。使用带有动量参数的随机梯度下降准则来优化模型。
3.2。唤醒词检测测试
我们的唤醒词检测评估数据集由225位扬声器记录。我们选择2个关键字作为个性化的唤醒词,长度范围为2到4个词。每个演讲者在1-5秒的句子中嵌入的每个关键字被录制了10次。其中两个用于注册模板,其余8个用于评估。评估阳性样本由包含已记录关键字的语音组成,而阴性样本则没有。与[5]相同,我们的实验装置中没有交叉扬声器测试。对于一个注册关键词,所有正样本和负样本都来自同一说话者。总计,对于每个唤醒词,我们从所有说话者中获得1753个正样本和7200个负样本。修改后的ROC曲线[5]用于显示KWS性能。我们还选择误报率为0.005的未命中率来定量表示性能。

4. Results
4.1. LSTMFeatureExtractors
表2显示了针对普通话中不同嵌入单元训练的LSTM特征提取器的性能。 我们可以清楚地看到,随嵌入单元的增加,未命中率会大大降低。 遗漏率保持在
表3:基于S-DTW的KWS的性能
模型
DNN音调音素的后代DNN非音调音素的后代LSTM音调音素的后代LSTM非音调音素的后代
未命中率为0.005虚警
0.137
0.129
0.148 0.139
音调/非音调音素和非音调音节单元的高级音调。 LSTM特征提取器一词可实现最低的未命中率(0.089)。 我们认为,字级特征提取器的良好性能归因于LSTM能够对长上下文进行建模。
4.2. S-DTWKWS
如表3所示,与使用LSTM嵌入特征提取器的KWS系统(表2)相比,无论使用DNN音素后验还是LSTM音素后验,基于S-DTW的KWS系统均显示出较差的结果。 这个结论与[5]中的结论是一致的,在L5中,LSTM特征提取器也以英语流行。
4.3. EffectsofWindowShiftingSize
基于S-DTW的KWS和基于LSTM嵌入特征提取器的KWS都需要沿测试音频流移动窗口。 因此,我们调查了不同窗口移位大小的影响。 如图2所示,随着移位大小的增加,未命中率急剧上升。 因此,在实际应用中,我们需要选择较小的移位大小以维持合理的丢失率,但要以大量增加计算为代价。
4.4. SLN-DTWKWS
表4显示了基于SLN-DTW的KWS系统的结果。与LSTM嵌入功能提取器(表2)和基于S-DTW的KWS(表3)相比,我们可以看到SLN-DTW将未命中率降低到一个新的水平。具有SLN-DTW的非音素音素DNN后部功能实现了0.029的最低遗漏率。与基于LSTM嵌入特征提取器的KWS相比,该SLN-DTW系统实现了67%的相对丢失率降低。与基于S-DTW的KWS相比,该SLN-DTW系统实现了78%的相对丢失率降低。我们还注意到,基于LSTM的SLN-DTW不能超过基于DNN的SLN-DTW,但LSTM的错误率与DNN相似。如[10,5]所示,使用多次注册的平均关键字模板可以提高性能。同样,我们遵循[10,5]在具有多个注册的KWS上进行额外的实验。通过为每个关键字使用2个注册条目,结果(表4中)显示未命中率达到0.007。图3显示了几种典型QbyE-KWS系统的ROC曲线。

4.5. EfficiencyTest
我们根据经验比较服务器上不同型号(CPU:Intel Xeon E5-2643,96G RAM)的运行效率,表5总结了实时比率(处理语音的时间/语音持续时间)。该比率是所有关键字的评估样本的平均值。结果表明,后方DNN音素加SLN-DTW方法的运行效率最高,比S-DTW方法运行得更快。但是提速并不比预期的要明显。这是因为基于神经网络的特征提取需要大量的计算时间。当我们比较LSTM和DNN时,我们发现DNN方法比LSTM方法快得多。比较这两种LSTM方法,LSTM嵌入特征方法一词的运行速度更快。这是因为在这种方法中相似性度量是余弦。请注意,效率测试中不考虑任何优化策略。在实际的设备上使用中,可以使用一些实用的优化策略来进一步提高计算效率。
5. RelatedWork
已经对KWS进行了固定或个性化关键字应用的研究。关键字填充HMM方法[17、18、19、20、21]多年来一直是主要方法。但是随着深度神经网络的快速发展,已提出使用它们来解决KWS问题[22,23,24]。在[24]中,提出了一种流行的小足迹KWS方法,其中训练了DNN以预测关键字目标和垃圾目标。以上基于HMM和DNN的解决方案仅适用于固定关键字。
可以考虑个性化的另一种解决方案
KWS依靠大型词汇连续语音识别器(LVCSR)。它将音频解码为符号表示形式,例如音素/单词序列或点阵[25、26、27、28、29、30],然后使用文本检索技术或符号搜索[31、11]来检测关键字。如果涉及关键字注册阶段,则LVCSR需要对关键字和测试音频进行解码。如果对资源没有限制,那么这种KWS解决方案可能是一个很好的解决方案。但是LVCSR需要大量的计算资源,因此不适合我们的设备上应用程序。
如第1节所述,基于DTW的QbyE-KWS是设备上个性化关键字检测的合适解决方案[9、10、11、12、6]。因为关键字模板通常比运行时话语要短得多,所以使用诸如S-DTW [9]和SLN-DTW [10、11、12、6]之类的策略来解决此问题。 Chen等。 [5]提出了一种LSTM特征提取器方法,将长度不同的音频片段嵌入到固定尺寸的表示中。因此,可以使用简单的距离(例如,余弦)直接测量两个序列的相似度,而无需耗时的DTW计算。
6. Conclusion
我们研究了基于神经网络的基于示例的关键词查询(QbyE-KWS)查询方法,用于汉语普通话的个性化唤醒词检测。 特别地,我们研究了基于神经网络的特征和两种不同的DWS DTW算法。 唤醒词检测实验表明,DNN音素后部加上SLN-DTW方法已实现了最先进的性能,并具有最高的运行时效率。 与其他嵌入单元(如音素,音节和字符)相比,字级LSTM嵌入功能显示出更高的性能。 但是,用作嵌入特征提取器或后期特征提取器的LSTM网络不能胜过前馈网络。 这可能是因为LSTM可能需要更多的参数调整和训练技巧。 作为我们未来的工作,我们将对基于LSTM的特征提取器进行进一步的研究。
这篇关于Investigating Neural Network based Query-by-Example Keyword Spotting Approach for Personalized Wake-的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





