本文主要是介绍入门级数据挖掘比赛——二手车交易价格预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
题目背景
初期工作
数据分析和特征选择
模型选择
总结
最近参加了天池的一个入门级数据挖掘比赛:二手车交易预测。昨天比赛结束,从参赛到结束也就10天,正经投入时间大概有5天吧,虽然是入门级比赛,看起来是很简单的回归预测,但是想冲进前13名(前13名有奖励)还是非常不容易的。2746组中最终排名48,对比投入时间和所做的工作,这个名次也没啥好说的。现在结束了,排名在前的队伍应该最近会写比赛分享,到时候再好好学习一下,看看自己到底是哪里还有待提高吧。为了给自己有个交代,简单总结一下自己在这次比赛中的工作吧。

题目背景
赛题以预测二手车的交易价格为任务,数据集报名后可见并可下载,该数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏。
评价标准为MAE(Mean Absolute Error)。
MAE越小,说明模型预测得越准确。
初期工作
为了让自己快速进入状态,首先看到了举办方发布的baseline方案,通过copy代码,上传成绩得到了baseline分数:680.31。通过baseline代码,我快速掌握了数据读取,模型预测保存成提交文件的方式。通过对baseline的方案的阅读,我知道baseline方案是选择了31列特征的18个作为模型输入特征,选择xgboost和lgb两个模型进行预测,最后两个预测结果进行加权平均得到提交结果的。数据挖掘比赛往往会经过这么几个阶段:数据分析和预处理——特征选择——模型选择——集成学习,显然baseline的18个特征只是一个简单的示例。所以下一步就开始好好分析一下数据情况了。
数据分析和特征选择
查看缺失值情况,如下包含model, bodyType, fuelType,gearbox, 其中fuelType缺失值较多,达到5.79%。缺失值的处理方式有:补为-1,填充中位数,填充众数,填充上下条的数据,填充KNN,插值,填充均值,这里我选择了一个最简单的:补为-1。

然后,开始考虑31个特征选择哪些作为模型的输入特征,经分析和单个特征与交易价格的趋势可视化观察,排除了:saleID(唯一标识), name(经过数据分析,15W个数据中,出现99662个值,快达到唯一标识了,所以我选择去掉这个特征,ps:后来发现这个决定是错误的,很多前排队伍都说这个特征很重要,当时我是自我感觉不重要也没做趋势分析直接pass了),saller(15W数据只有1个不同case),offerType(15W数据此特征全部一样值)。所以一共选了26个特征,并且对regDate,createDate进行了处理,因为这两个特征是时间值,我就按照时间先后,进行了等值替换,如regDate的时间范围是19910001到20151212,我就把1992年之前的重标为0,1992-1993年的数据重标为1,每隔一年一次类推直到2015年之后标记为24。
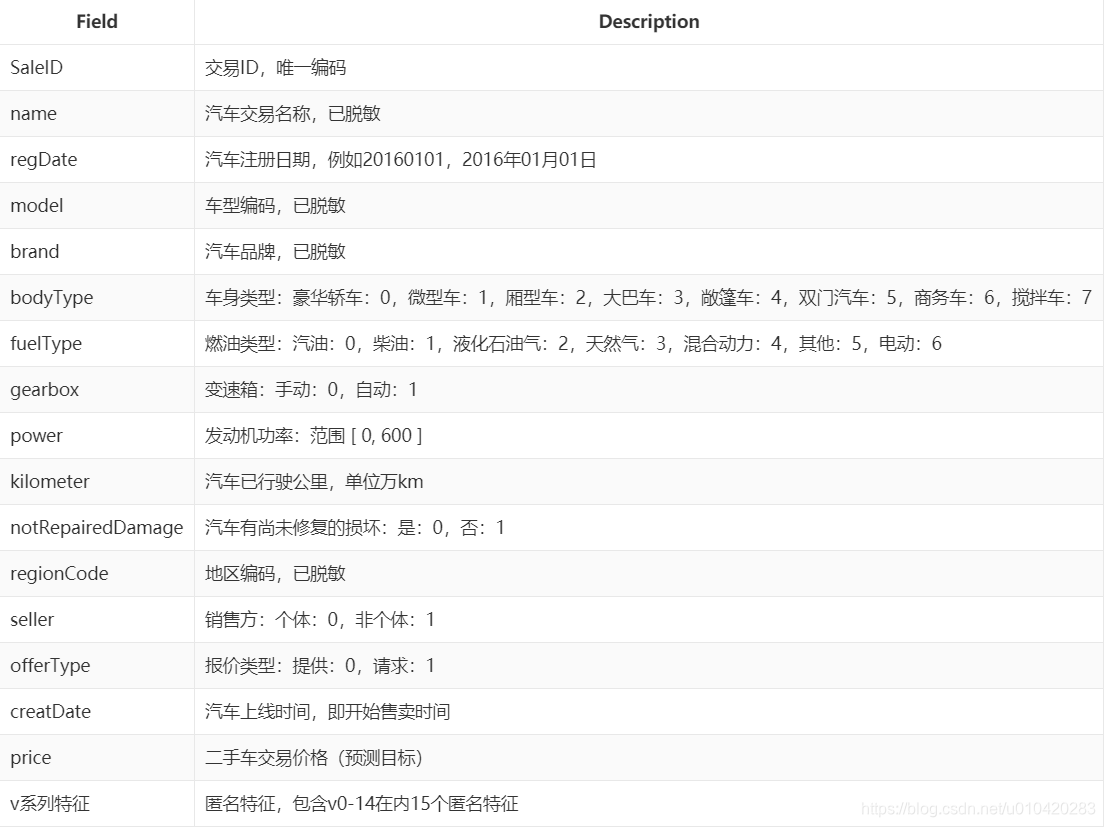
其它特征,如model, regionCode, createDate通过它们编码和price的趋势观察,发现具有相关性,所以要加入这些特征,如下图可以看到不同model,regionCode, createDate编码与价格具有明显分层效果。

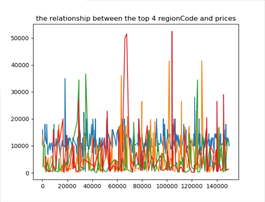
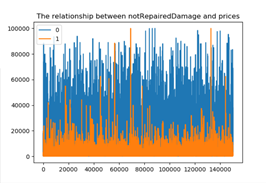
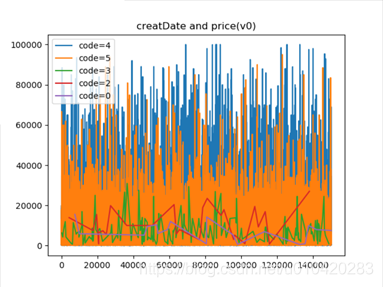
其中左下是notRepairedDamage的数据,0标识汽车有尚未修复的损坏,结果售价却普遍高于没有损坏的,优点违背常识,不知道是不是举办方做过处理(还有regData的时间编码月份居然是从0-12的,一年有13个月吗?有点奇怪)。
经过增加模型输入特征到26个,最终线上分数为569.50。
模型选择
接着我觉得特征选择和数据处理的工作算是结束了,我找到了很多做回归的模型进行选择,包含:linearegression,DecisionTreeRegressor, RandomForestRegressor,GradientBoostingRegressor,MLPRegressor,Bagging, XBGRession,LGBMRegressor,最终发现较好的是随机森林,XGB,LGB。因为是直接调用,使用默认参数,接着我又网上搜了一大堆的随机深林,XGB,LGB的调参技巧,希望通过一个合适的参数得到比baseline更好的效果,最终发现很多参数调节用处不大,暴力增加n_estimators的个数效果有了明显的提升。因为随机深林即使调参后与xgb和lgb的mae还是差了接近100,所以我最终还是使用的baseline方案xgb,lgb,把评估器的个数设置分别设置为了5000,30000。最终线上效果达到495.78。然后对数据进行了归一化处理等一些小的操作,线上达到487.86就不行了。
至此,我的比赛陷入了瓶颈期,我尝试用MLP进行训练,但是mae还是在600左右徘徊。然后把这个比赛放了两天后,看到又大佬分享了一个简单的keras实现的神经网络案例,称效果达到450,我马上复现了一下,然而mae只能到470左右,但是比我的MLP好了很多(我觉得可能是我的MLP没有加Relu激活函数的原因),线上成绩达到471.08,我通过对这个keras进行调超参,如优化器,神经元个数,网络层数等,线上成绩465.63。
至此,我的线上成绩一直没有排进前100名(天池显示前100队伍),我觉得自己已经尝试了我所能想到的所有,比赛还有2天结束,我想最后把xgb+lgb和keras的提交结果加权平均一下,就当结束了,结果在线mae居然降到了436.87,进入了50多名,这可真实山穷水复无疑路,柳暗花明又一村呢,好高兴。
最后我看到keras训练的神经网络模型训练集mae能降到300,但是测试集总是460左右,想着按照防止过拟合的方向每一层加入了l2正则以及dropout层,只要解决了过拟合就能在线上达到400的mae,这样就能进入前13名了,但是理想很美好,现实很残酷。然后因为神经网络每次初始权重随机初始化的方式,导致模型性能不变,但是预测结果会有出入,所以我进行了6个模型预测结果的集成取平均,然后再和xgb+lgb的集成取平均,提交在线mae:428.51。最终排名48。
总结
总体来说,并没有投入很多精力,在数据分析,特征选择模块还有很多没有做好的地方,模型选择的话,大家基本都是用xgboost和lgb,这块不用花费过多时间。最后结果集成特别重要。可以选择成绩相同,模型不同的结果进行取平均等的集成,这样可能会带来很大的提升。比如本次比赛中神经网络模型和决策树模型的集成结果,远远超越它们各自的成绩。
后面等前排大佬分享了比赛经验,我再补充一下自己的不足吧。
这篇关于入门级数据挖掘比赛——二手车交易价格预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







