本文主要是介绍Adaptive Distributed RDF Graph Fragmentation and Allocation based on Query Workload,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文由学者Peng Peng,Lei Zou,Lei Chen和Dongyan Zhao于2019.4在《IEEE Transactions on Knowledge and Data Engineering》联合发表
原文下载链接文末自取
在《Query Workload-based RDF Graph Fragmentation and Allocation》中研究了分段和分配策略,本文自适应地维护频繁访问模式(FAP)反映工作负载的特征,同时确保数据完整性和近似比。由于评估SPARQL查询有较强局部性的子图(同态)匹配,提出了基于局部模式的碎片化策略,首先,在查询工作负载中挖掘和选择频繁子图模式(频繁访问模式FAPs),然后提出三种分段策略:垂直,水平和混合分段,满足不同类型的查询处理目标的同时划分RDF图。分段后,再在平衡碎片的同时将碎片分配到各个站点。
分段和分配
工作重点是RDF存储库的“数据碎片和分配”,而提议的碎片是基于挖掘的频繁模式。通过利用分布式关系数据库设计的经验,分开分布式设计,更好处理问题。
分段:

分配:给定碎片F,然后在不同的站点间分配碎片。 
给定RDF图G,查询工作负载Q和由站点S组成的分布式系统,目标是首先将G分解为碎片F,然后找到F到S的分配A。大多数SPARQL查询都使用一些频繁的RDF属性,所有属性分为以下两类:

在不同站点之间划分具有频繁属性的边,可提高查询性能。收集RDF图中所有不频繁边形成冷图。任何现有方法均用于冷图,但此研究仅在评估SPARQL查询时才使用冷图,如图为系统架构:

离线阶段:在工作负载中挖掘和选择一些FAP。 还要维护和更新选定的FAP集,适应工作量的变化。 然后,基于选择FAP,提出三种碎片策略:VF、HF和MF。片段分布在不同的站点间,同时在分段和分配过程中维护元数据。
在线阶段:将查询分解为不同片段上的几个子查询,并生成有效的执行计划。 为了有效地评估子查询,提出了推动交叉碎片连接优化方法和用于生成有效执行计划的成本模型。最后,执行计划并返回结果。
频率访问模式定义、方法和访问频率值以及FAP集早前已经说明,不重复阐述。
FAP选择:考虑频繁模式p。如果从由模式p匹配引起的图生成的一个片段,则通过使用该片段可以加快对包含该模式所有查询的评估。 FAP命中的查询越多,在查询处理过程中收益越大。定义一个函数是选择模式p时p命中的查询数量。据实验观察结果表明,较大FAP更好被选为构建碎片。
将系统的存储容量标准化为值SC,SC=Disk_Space/Avg_Triple_Size,其中“Disk_Space”是系统存储的磁盘空间,“Avg_Triple_Size”是一个三元组的平均字节数。 所以约束为:
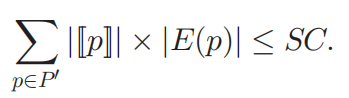
优化目标:在存储约束下最大化利益
由于在受存储约束下,找到一组具有最大效益的FAP是NP-hard,具体处理算法阅读原文。
频率访问模式的存储和维护
选择FAP后,基于DFS提出了基于树的结构,维护它们并处理新输入的查询。
-
DFS编码:DFS通过执行DFS将图转换为唯一的边序列。 在DFS搜索中,顶点按发现时间下标。 前边是DFS树的边,后边是其余的边。 按如下顺序排列后边。 顶点v的所有后边出现在指向v的前边后。有Vi,其带有两条后边Vk和Vj,如果k>j,则ViVj在ViVk之前,然后形成完整的边序列,即DFS代码。
-
FAP树:使用DFS代码,建立FAP树,记录所有FAP,如图为FAP树,其中每个节点代表工作负载中的模式:
 在FAP树,每个FAP映射到一个节点,并且当且仅当n映射到的FAP的DFS代码是n’映射到的DFS代码的前缀时,节点n才是节点n’的先辈。根据DFS代码的属性,n映射到的FAP是n’映射到模式的超图。给定映射到模式p和p的变量集var§的节点, 与FAP树中的节点相关联的信息如下:
在FAP树,每个FAP映射到一个节点,并且当且仅当n映射到的FAP的DFS代码是n’映射到的DFS代码的前缀时,节点n才是节点n’的先辈。根据DFS代码的属性,n映射到的FAP是n’映射到模式的超图。给定映射到模式p和p的变量集var§的节点, 与FAP树中的节点相关联的信息如下:

基于FAP树和统计信息,分解输入查询并优化查询评估。FAP树记录了只比FAPs多一条频繁属性边的不频繁模式。将这些频繁的模式插入到FAP树中作为叶节点,用于检测查询工作负载变化时的频繁模式更新。由于FAP满足先验规则,并且不频繁模式的超图不频繁,所以叶节点映射到的模式是最小不频繁模式。当工作负载变化时,必须从叶节点映射到的模式中生成新的频繁模式。由于输入新的查询,找到新的FAP,所选FAP的好处也相应变化。通过输入新查询时改变模式的数量衡量FAP树的有效性。 通过实验研究,发现少量的更新操作不会明显改变工作负载数量的分布,因此只需为每个插入或删除更新相关FAP的ID列表。当存在许多FAP改变时,则FAP树质量降低,有两种类型的更改: -
更改一:首先,FAP树中的某些FAP很少出现。其次,新的时间窗口中有一些新的FAP。因为我们总是在FAP树中维护包含FAP的查询的ID,所以很容易检测到第一个类型。如果列表中的查询数量小于阈值minSup,则相应的模式变得不常见。
-
更改二:为了检测第二种类型的更改,执行以下方法。由于每个新时间窗口内挖掘所有FAP检测新模式损耗过大。所以在新时间窗口,如果有新FAPp,则p必须映射到FAP树中的叶节点l或者p是叶子节点l的超图。根据FAP的先验属性,通过检查l的查询图列表来检测到叶节点l更改为FAP。后续内容有兴趣请自行阅读。
本论文中介绍了三种碎片策略,在《Query Workload-based RDF Graph Fragmentation and Allocation》中已经对垂直和水平策略有所了解,所以这两种碎片策略阐述省略,结合两者优势设计出MF策略:
给定SPARQL查询工作负载中的一组频繁模式,VF基于每个选定的频繁模式p,HF基于结构性最小谓词mp。HF提供了细粒度的分区,设P表示所有选择的频繁模式。在MF中,为垂直分区保留部分频繁模式(Pv),而为HF设计其他模式(Ph)。然后,需要确定模式p属于Pv或Ph:给定频繁的模式p,M§表示从模式p派生的所有结构最小谓词。分类策略基于FAP的访问频率和相应的结构minterm谓词。M(p)分为两个子集:一组访问频率大于minSup的结构minterm谓词;一组结构minterm谓词的访问频率小于minSup,定义如下:
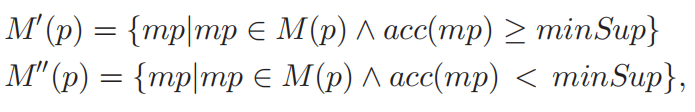
如果M’’(p)的总访问频率大于minSup,则可从p生成的垂直片段评估的许多查询,这种情况下,基于模式p执行VF。 如果M’’§的总访问频率小于minSup,则根据结构谓词M’(p)水平划分RDF图。 依据频繁结构最小谓词M’(p)操作HF,混合碎片策略如下:

分配:
对RDF图分段后,然后将所有分段分配在几个站点上。 由于分段会一起访问某些FAP或结构最小谓词,所以将其相应的片段放在一个站点中,避免分布式连接。此外,还产生了评估片段间的紧密相关性的定义:
根据亲和度大小可以判别片段间的紧密关系。如果两个片段的关联度较大,说明同一查询涉及两个片段,如此相关的片段应将它们放在一起减少跨站点连接的数量。分配的目的是尽可能频繁地在同一站点的片段中进行相同的查询。 同一站点的每两个片段应一起访问。本研究将PNN扩展为将所有片段聚类为分配A={A1,A2,… ,An},同一群集的所有片段都放置在一个站点。首先,如下构建分配图:
分配将所有片段聚集在m个群集中,并且群集中所有片段都在AG中连接,扩展AG密度的定义,如下所示:
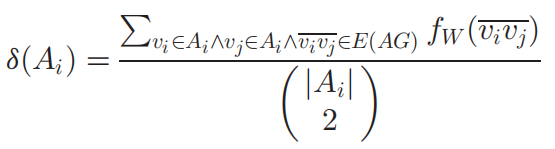
其中分子是Ai中所有边的权重之和,而分母是Ai中连接任意两个顶点的边数。
分配算法的目的是在确保平衡的同时搜索具有最高密度的m个AG子图,提出了PNN变体的分配算法,并且在每个步骤中选择合并AG中两个顶点的局部最优选择,该算法会贪婪选择局部最优选择。
查询分解:
给定查询Q,基于FAP树的统计信息,将查询Q分解为几个子查询,子查询映射到不同的片段。 由于基于FAP划分RDF图,所以将查询图Q分解为与FAP同构的子查询。 如果查询涉及不频繁的属性,则查询中每个仅包含不频繁属性的子图对应一个子查询,查询分解定义如下:

给定查询Q,可能存在多个查询分解。为了找到优化的查询计划,提出一种成本模型查询分解方法找到成本最小的有效查询分解方法。分解成本是连接D和每个子查询所有匹配的成本,并且每对子查询的匹配可联合。查询分解后,qi映射到片段Fi,所以通过查找FAP树,得到Fi中的匹配数,而一个SPARQL查询包含的边缘不超过10个。使用查询分解算法,首先初始化单个边的所有子查询的分解。然后,枚举所有子查询,直到FAP的最大为止,并将它们放在FAP树中。我们将每个子查询q转换为DFS代码,并使用DFS代码对FAP树自顶向下搜索。如果q的DFS代码等于FAP树中选定FAP的DFS代码,则递归查找的所有有效分解并将q插入这些分解中。遍历所有Q子查询的步骤之后,可确定Q的所有有效分解。最后计算所有有效分解的成本并选择最佳分解。对于扩展的System-R算法已经了解,不再叙述。
推送跨片段联接:
给定SPARQL查询Q,最终分解通常包含具有高选择性的子查询和具有低选择性的子查询。 提出推动跨片段连接的策略仅生成用于选择子查询的中间结果。推动跨片段连接限制了无法与其他站点中其他子查询的任何匹配连接的中间结果,但以不同方式减少了中间结果的数量。半联接技术需要在半联接后进行额外的内部联接操作,而推动跨片段连接通过删除片段的不相关部分降低查询评估的成本。推动交叉片段联接可避免为非选择子查询生成许多不必要的中间匹配,原因是使用从预测结果开始的图遍历找最终结果。
成本评估:
提供成本模型评估优化技术的成本,优化重点是总执行时间。依靠成本模型来进行集中的RDF查询评估,查询查询的总时间=本地处理时间(I / O + CPU时间)+通信时间。具体方法须阅读原文理解。
查询执行:
查询优化后,在不同的联接运算符的情况下确定了分布式执行计划。 然后,我们执行分布式执行以得出最终结果。 加入策略,当考虑不同的联接运算符的情况下确定分布式执行计划时,需要会同时考虑自然联接,半联接和推动跨片段联接。使用成本模型来估算三种类型的联接的成本,并选择成本最小的联接技术。子查询处理,每个子查询在相应的站点中执行,每个子查询的优化都使用现有的集中式RDF数据库系统。
余下部分是实验内容,不再赘述。
原文下载链接
这篇关于Adaptive Distributed RDF Graph Fragmentation and Allocation based on Query Workload的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





