本文主要是介绍论文阅读:(ICIP 2021)LATENT-SPACE SCALABILITY FOR MULTI-TASK COLLABORATIVE INTELLIGENCE,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LATENT-SPACE SCALABILITY FOR MULTI-TASK COLLABORATIVE INTELLIGENCE (ICIP 2021)
2022/8/1: 学校终于解封了,终于能出门吃螺狮粉了呜呜呜。
Abstract
研究了多任务协同智能的潜在空间可扩展性,其中一个任务是目标检测,另一个任务是输入重构。在我们提出的方法中,可以有选择地解码部分潜在空间以支持目标检测,而在需要输入重构时可以解码其余的潜在空间。当只需要对象检测时,这种方法允许减少计算资源,并且可以在不重构输入像素的情况下实现。通过改变训练损失函数中各项的比例因子,可以训练系统在目标检测精度和输入重构质量之间实现各种权衡。通过与相关基准相比的实验,验证了可调系统在两个任务上的性能。
1. Introduction
基于人工智能(AI)的应用程序的快速部署正在给从手持设备到大规模云计算系统等多个系统的计算资源带来压力。最近的研究[1,2]通过拆分AI模型,确立了协同智能(CI)的概念,作为应对此类挑战的一种方法(例如,深度神经网络,DNN)之间的边缘和云。在这样的框架中,由模型前端产生的中间特性从边缘发送到云端。因此,中间特征的压缩成为人们关注的话题。相关的标准化活动包括视频编码机器(VCM)[3]和JPEG-AI [4]。
例如,[5-9]已经证明编码中间特征可以导致显著的压缩增益,而任务准确性的损失最小。这些研究基于现成的单任务DNN模型。在我们早期的工作[10]中,开发了一个多任务CI模型,该模型支持对象检测和输入重构,使用中间特征的近乎无损编码。针对不同的多任务模型,提出了利用有损特征压缩的相关方法[11,12]。与这些方法不同的是,在这些方法中,一个特性张量被编码为支持多个后端任务,最近的提案[13,14]关注可扩展编码以支持多任务例如,[14]提出了一种可扩展的编码方法,支持人脸地标检测和生成输入人脸重建。虽然生成解码器在人脸重建方面效果很好,但在重建输入图像的非人脸细节方面可能不太成功。在本文中,我们提出了一个利用潜在空间可扩展性来支持目标检测和输入图像重建的CI系统。其中,部分潜在空间(基础层)用于目标检测(基础任务),而整个潜在空间用于输入重构。未用于基本任务的潜在空间的部分可以解释为增强层。这种表示也可以用于其他多任务模型(例如,基本任务可以是对象检测以外的东西),并允许对输入进行高效、可扩展的学习表示。第2节简要回顾了中间特征压缩的相关方法。第3节描述了所提出的方法。第4节给出实验结果,第5节给出结论。
2. Related Work
早期的特征压缩方法[5 - 9]侧重于从单任务DNN编码单个特征张量,任务是图像分类[6,7]或目标检测[5]。在这些工作中,一种流行的编码特征张量的方法是将张量平铺到图像中,应用预量化(比如,每个张量元素8位),然后使用传统的图像编解码器进行压缩。为了进一步提高张量编码效率,[8,9]提出了张量信道预测、数据裁剪等附加方法。
由于图像/视频分析中经常需要执行多个任务[13,15],另一组方法主要针对多任务dnn进行特征压缩[10-12]。虽然这些工作验证了从单个压缩特征张量进行多任务分析是可行的,但没有进一步研究如何有效地组织多任务的潜在空间。特别地,在这些方法中,需要重建整个张量来完成任意任务。最近,[14]提出了一种可扩展的人脸图像编码特征表示。具体地说,人脸地标检测所需的边缘映射构成基础层,附加的颜色信息构成增强层。仅利用基础层信息即可实现人脸地标检测,而利用生成译码器可以同时利用基础层和增强层实现人脸图像的重构。虽然[14]的主要思想非常吸引人,但目前还不清楚这种方法如何扩展到更一般的(例如,非人脸)图像编码场景。
3. Method
3.1 Motivation
本文研究的CI系统的马尔可夫链模型如图1所示。输入图像X经过边缘子模型f1处理,产生特征Y,在云端,子模型f2从特征Y重建一个输入图像X的近似 X ^ \hat{\textbf{X}} X^,子模型f3进行对象检测,生成集合T,包含包围块和对象类。

流程链 X → Y → X ^ \textbf{X} \to \mathcal{Y} \to \hat{\textbf{X}} X→Y→X^作为一个端到端编解码器。注意,还可以对解码后的图像 X ^ \hat{\textbf{X}} X^进行对象检测,使用现成的对象检测器,如YOLO[16]或SSD[17],如图1中f4所示。事实上,这种从解码图像(而不是原始图像)进行对象检测是常见的做法,因为对象检测数据集(如COCO[18]和ImageNet[19])包含的是jpeg压缩的图像,而不是原始图像。将数据处理不等式[20]应用于马尔可夫链 Y → X ^ → T \mathcal{Y} \to \hat{\textbf{X}} \to T Y→X^→T,我们有

其中 I ( ⋅ , ⋅ ) I(\cdot,\cdot) I(⋅,⋅)表示互信息。这表明,中间特征 Y \mathcal{Y} Y携带的对象检测(T)信息比它们携带的输入重建(Xb)信息要少。这种观察激发了我们的方法——我们构造特征Y,这样Y只有一部分用于对象检测,而Y的整个用于输入重建。图2展示了我们的CI系统架构。系统中的许多模块都是基于[21]的,下面将更详细地讨论新提出的模块。

3.2 Analysis Encoder and Synthesis Decoder
大多数的端到端学习图像压缩方法[21-23]都是针对RGB输入图像而设计的,本系统是针对YUV420输入格式设计的,而YUV420输入格式在视频编码中更为常见。具体地说,输入图像X包括亮度通道 X L ∈ R 1 × H × W X_L \in R^{1×H×W} XL∈R1×H×W和色度通道 X C ∈ R 2 × H / 2 × W / 2 X_C \in R^{2×H/2×W/2} XC∈R2×H/2×W/2,其中 H × W H ×W H×W为输入分辨率。相应的分析编码器和合成解码器如图3所示。分析编码器包括许多卷积层(’ CONV ')(5 × 5滤波器)和广义区分归一化(GDN)[24]层。亮度分支的降采样通过与stride 2的卷积实现。Synthesis Decoder是Analysis Encoder的镜像,用转置卷积替换卷积(用’表示),用逆GDN (IGDN)层替换GDN层。在合成解码器的输出处,重构输入 X ^ \hat{\textbf{X}} X^由亮度重构 X L ^ \hat{\textbf{X}_L} XL^和色度重构 X C ^ \hat{\textbf{X}_C} XC^组成。

3.3 Latent-space Scalability
本系统的隐空间特征张量维数为 Y ∈ R N × H / 16 × W / 16 Y \in R^{N×H/16×W/16} Y∈RN×H/16×W/16由N = 192个通道组成: Y = { Y 1 , Y 2 , . . . , Y N } Y = \{Y_1,Y_2,...,Y_N\} Y={Y1,Y2,...,YN},我们讲张量分割为两个部分, Y b a s e = { Y 1 , Y 2 , . . . , Y j } Y_{base} = \{Y_1,Y_2,...,Y_j\} Ybase={Y1,Y2,...,Yj}表示为基础级特征,其中 j < N j < N j<N; Y e n h = { Y j + 1 , Y j + 2 , . . . , Y N } Y_{enh}= \{Y_{j+1},Y_{j+2},...,Y_N\} Yenh={Yj+1,Yj+2,...,YN},表示含有 N − j N-j N−j个通道的增强级特征。在我们的实验中,我们使用 j = 128 j=128 j=128。在解码器上,如果只需要检测对象,则只需要重构 Y b a s e Y_{base} Ybase。如果需要重建输入图像,则需要重建整个Y。
一个显而易见的问题是——我们如何知道与目标检测相关的信息集中在Y的前j个通道中?这是通过从头训练图2中的整个模型来实现的,如3.5节所述。通过对各种损失项进行基于梯度的更新,该模型学会将与目标检测相关的信息导入,同时学习使用整个Y来重建输入图像。
3.4 Latent Space Transform
在我们的系统中,我们使用YOLOv3[16]的预训练后端进行对象检测,特别是从l = 12层的批处理归一化输入到模型输出的部分。此时,YOLOv3期望一个特征张量 F ( l ) ∈ R 256 × H / 8 × W / 8 F^{(l)} \in \R^{256×H/8×W/8} F(l)∈R256×H/8×W/8,而我们重建的基本特征是 Y ^ b a s e ∈ R 128 × H / 16 × W / 16 \hat{Y}_{base} \in \R ^{128×H/16 \times W/16} Y^base∈R128×H/16×W/16。因此,需要从一个潜在空间转换到另一个潜在空间。潜空间变换模块的结构如图4所示;它包括一个转置卷积层,其目的是匹配目标潜在空间的空间分辨率,和一个IGDN层和卷积层序列。在输出端,产生了目标潜在空间中的特征张量 F ~ ( l ) \tilde{\mathcal{F}}^{(l)} F~(l)。一旦计算出 F ~ ( l ) \tilde{\mathcal{F}}^{(l)} F~(l),将其送入批处理归一化YOLOv3的层 l = 12 l = 12 l=12的 B ( l ) B^{(l)} B(l),然后是LeakyReLU的激活 σ ( ⋅ ) σ(·) σ(⋅),从而产生对层l = 13的输入。

3.5 Training
我们的损失函数是速率失真拉格朗日函数的形式

其中R为速率估计,D为输入重构和目标检测的组合失真,λ为拉格朗日乘子。因为我们的编码引擎是基于[21]上,位流由编码潜在数据的主位流和编码超先验的侧位流组成。基于[21],这两个比特流的速率估计是

其中 x x x表示输入数据, x ^ \hat{x} x^表示潜在数据, z ^ \hat{z} z^表示超先验。失真度D计算为

其中α和β是用于实现各种权衡的尺度因子,MSE是均方误差,MS-SSIM是多尺度结构相似性指数度量[25]。
公式(4)中的第一项鼓励准确地重建输入图像,而第三项鼓励其感知质量。第二项是YOLOv3的l = 12层输出处的地面真值特征张量与我们的基特征Ybase导出的对应特征张量之间的MSE。因为这一项只依赖于Ybase,而不是Yenh,从它派生的梯度将更新模型,以这样一种方式,目标检测相关信息转向Ybase。同时,Ybase和Yenh都对输入重构有贡献,因此由(4)中的第一项和第三项导出的梯度将在Ybase和Yenh中分布与输入重构相关的信息。图2中的系统训练是使用一组图像X和这些图像在YOLOv3层l = 12的输出处对应的地面真值特征张量从无到有进行训练的。
4. Experiments
我们的模型是在CLIC[26]和JPEG-AI[27]数据集上训练的。JPEG-AI数据集的图像被调整为
1920×1080使用Lanczos过滤器。在CLIC数据集中,只使用了分辨率为320×320或更大的图像。使用大小为的随机窗口裁剪图像,训练时256 × 256。对所有训练图像生成YOLOv3第12层的ground truth特征张量,用于计算(4)中的第二项。在训练过程中,这些张量被裁剪为256 × 32 × 32,以匹配输入图像中随机256 × 256窗口的位置。学习率为10−4的Adam优化器被用于在GeForce RTX 2080 GPU与11 GB RAM上训练网络2M epoch 。与[21]相似,对每个 λ ∈ { 0.005 , 0.01 , 0.02 , 0.05 , 0.1 , 0.2 } λ \in \{0.005, 0.01, 0.02, 0.05, 0.1,0.2\} λ∈{0.005,0.01,0.02,0.05,0.1,0.2}训练一个模型。

由于我们的模型支持两个任务,我们将其与每个任务的相关基准进行比较。对于目标检测,模型在COCO 2014验证数据集上进行评估,该数据集包括大约5K的jpeg压缩图像。这些JPEG图像的平均文件大小约为1260kbits,并且现成的YOLOv3实现了平均精度(mAP)为55.85%。 如图5中的红色方块所示。当使用HEVC-Intra编码平铺时,YOLOv3第12层的8位预量子化张量,得到图5中的棕色曲线。黄色曲线显示了我们最近的工作[8],我们认为它是编写YOLOv3特性张量的最先进的。为了评估所提出的模型,输入图像首先使用ffmpeg转换到YUV420,然后输入模型。(4)中几个α和β值的性能曲线如图5中红色、绿色和蓝色所示。请注意,正如(4)所预期的那样,增加α可以提高目标检测性能。在α = 20的情况下,可以在非常低的比特率下实现卓越的目标检测性能,与默认的YOLOv3相比,mAP损失不到1%。即使α较低,该模型在低比特率下也能与[8]相媲美。图5中的阴影区域显示了通过改变α可以实现的操作范围。
当使用输入重构时,我们的模型充当端到端图像编解码器,因此我们将其与原始YUV420 HEVC通用测试序列[28]的相关基准进行比较。一个基准是HEVC (HM-16.20)[29],具有所有Intra配置[28]。由于我们的模型的主干是基于[21]的,所以我们使用来自[21]的模型作为第二个基准。使用[21]对YUV420输入进行编码,采用最近邻插值法对色度通道进行上采样,然后使用ffmpeg将色度通道转换为RGB。
使用ffmpeg将RGB输出转换回YUV420。
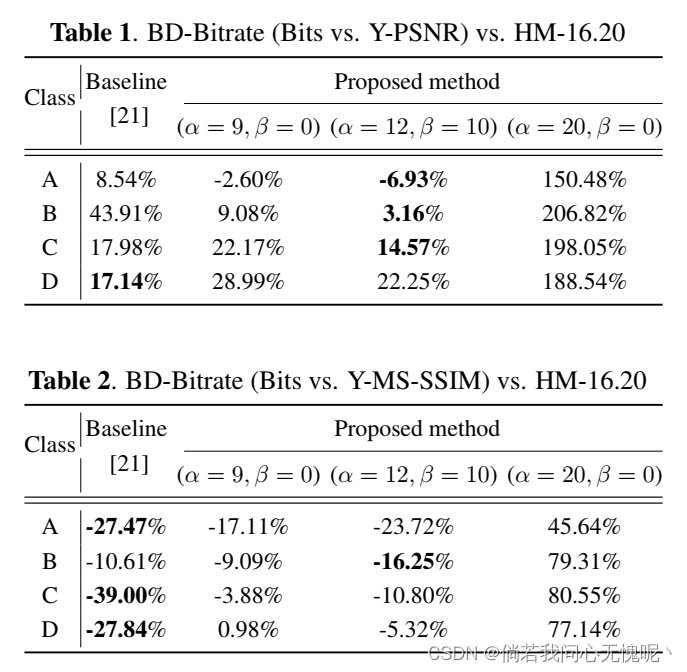
表1显示了对HEVC的平均bd -比特率,通过Y-PSNR与比特曲线计算。我们的模型与(α;β)= (12;10)在A、B、C类序列上的性能优于[21],在A类中甚至优于HEVC。这可以从(4)中得到预期,因为较小的α加上较大的β不强调目标检测性能,反过来促进输入重建。与此同时,设置(α;β)= (20;0)会导致输入重构效率的相当大的损失,但反过来又能获得出色的目标检测性能,如图5所示。
表2显示了通过Y-MS-SSIM与比特曲线计算的HEVC的平均bd -比特率。众所周知,基于深度模型的端到端图像编解码器在MS-SSIM上性能良好,这在表2中确实很明显。在这里,[21]的模型在所有序列类上都优于HEVC,我们的模型带有(α;β)= (12;10)也这样做。我们的模型在类B中比[21]做得更好,而在其他类中,[21]提供了更好的性能。我们的模型在(α;β)= (20;0)现在比MS-SSIM小得多。
综上所述,本文提出的模型在作为端到端图像编解码器时,压缩效率可与[21]相媲美,且优于HEVC,在重构时使用的是MS-SSIM时。在此基础上,我们的模型提供了从潜在空间子集执行对象检测的可伸缩性,这是[21]和HEVC(以及任何其他编解码器,据我们所知)目前都不能提供的。因此,我们认为这将是对这一领域未来研究和标准化活动的有益贡献。
5. Conclusion
我们引入了多任务协同智能的潜在空间可扩展性,并在一个支持对象检测和输入重构的系统上进行了测试。其中一部分潜在空间用于目标检测,而整个潜在空间用于输入重构。适当选择的损失项允许在模型训练时将相关信息转向潜在空间的不同部分。通过改变各种损失项的比例因子,演示了两个任务之间的不同权衡,并与相关基准进行了比较。
这篇关于论文阅读:(ICIP 2021)LATENT-SPACE SCALABILITY FOR MULTI-TASK COLLABORATIVE INTELLIGENCE的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






