本文主要是介绍基于 NGram 分词,优化 Es 搜索逻辑,并深入理解了 matchPhraseQuery 与 termQuery,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于 NGram 分词,优化 Es 搜索逻辑,并深入理解了 matchPhraseQuery 与 termQuery
- 前言
- 问题描述
- 排查索引库分词(发现问题)
- 如何去解决这个问题?
- IK 分词器
- NGram 分词器使用
- 替换 NGram 分词器后进行测试
- matchPhraseQuery 查询原理
- termQuery 查询原理
- 总结
前言
之前不是写过一个全局搜索的功能吗,用户在使用的时候,搜(进出口)关键字,说搜不到数据,但是 Es 中确实是有一条标题为 (202009 进出口)的数据的,按道理来说,这确实要命中的,于是我开始回想我当时是如何写的这段搜索逻辑的代码!!!!
问题描述
之前所有检索的字段全是用的 matchPhraseQuery 查询,matchPhraseQuery 命中的条件其一就是,搜索字段所有的分词都要被 Es 词库命中,其二就是命中的分词在词库中的顺序要紧挨着的。不然就没法查出数据。接下来举例帮助大家理解。
if (StringUtils.isNotEmpty(articleRequest.getKeyword())) {for (int i = 0; i < articleRequest.getKeys().length; i++) {boolQuery.should(QueryBuilders.matchPhraseQuery(articleRequest.getKeys()[i], articleRequest.getKeyword()));}}
使用 kibana 控制台,编写一条 DLS语句,由于 Es 默认使用的分词器是用的 standard,于是查看一下查(进出口)关键字,是被分词成了(进,出,口)
POST _analyze
{"analyzer": "standard","text": "进出口"
}
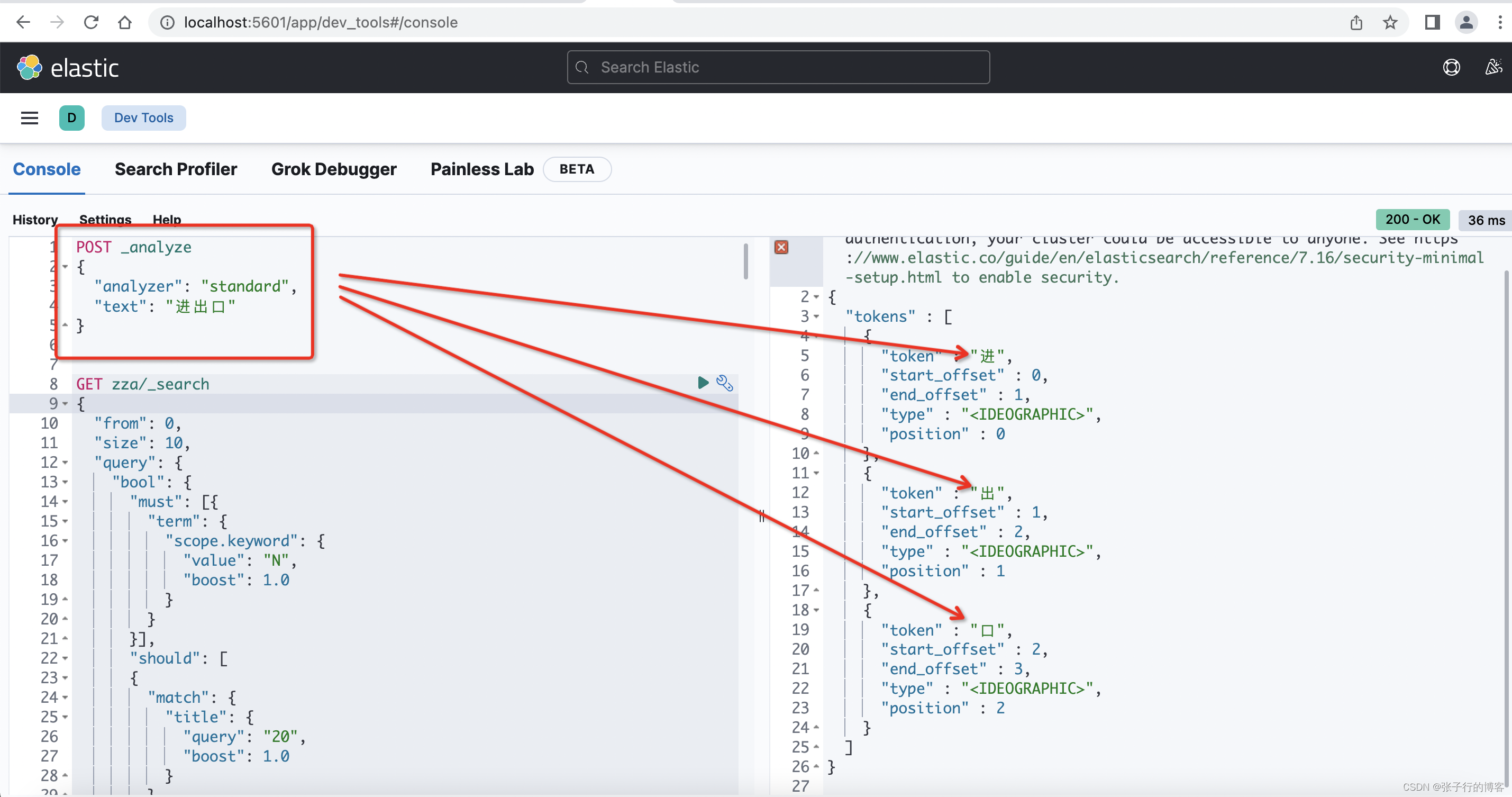
一开始建索引的时候,所有字段都没有指定分词器,都是用的默认的 standard 分词器,因此在使用 matchPhraseQuery 的时候,无论是 title 含有(进出口)还是 body 含有(进出口)关键字的数据都能够被正常检索出来,原因就是词库也是按照(进,出,口)存储的,查的关键字也是被分词成(进,出,口)进行匹配词库查询的,所有分词:位置紧挨着、顺序一致、且完全被包含。

但是后来遇到一个问题就是,搜字母或者是数字,搜不到数据,例如:搜 20 ,但是明明有标题为 (202009 进出口数据 33)的数据,就搜不出来。到这里你会怎么去排查问题?接下来说下我的整个排查问题的流程。
排查索引库分词(发现问题)
基于默认的 standar 分词器查看一下, title 为 (202009 进出口数据33)是如何被分词存到词库中的
POST _analyze
{"analyzer": "standard","text": "202009 进出口数据33"
}
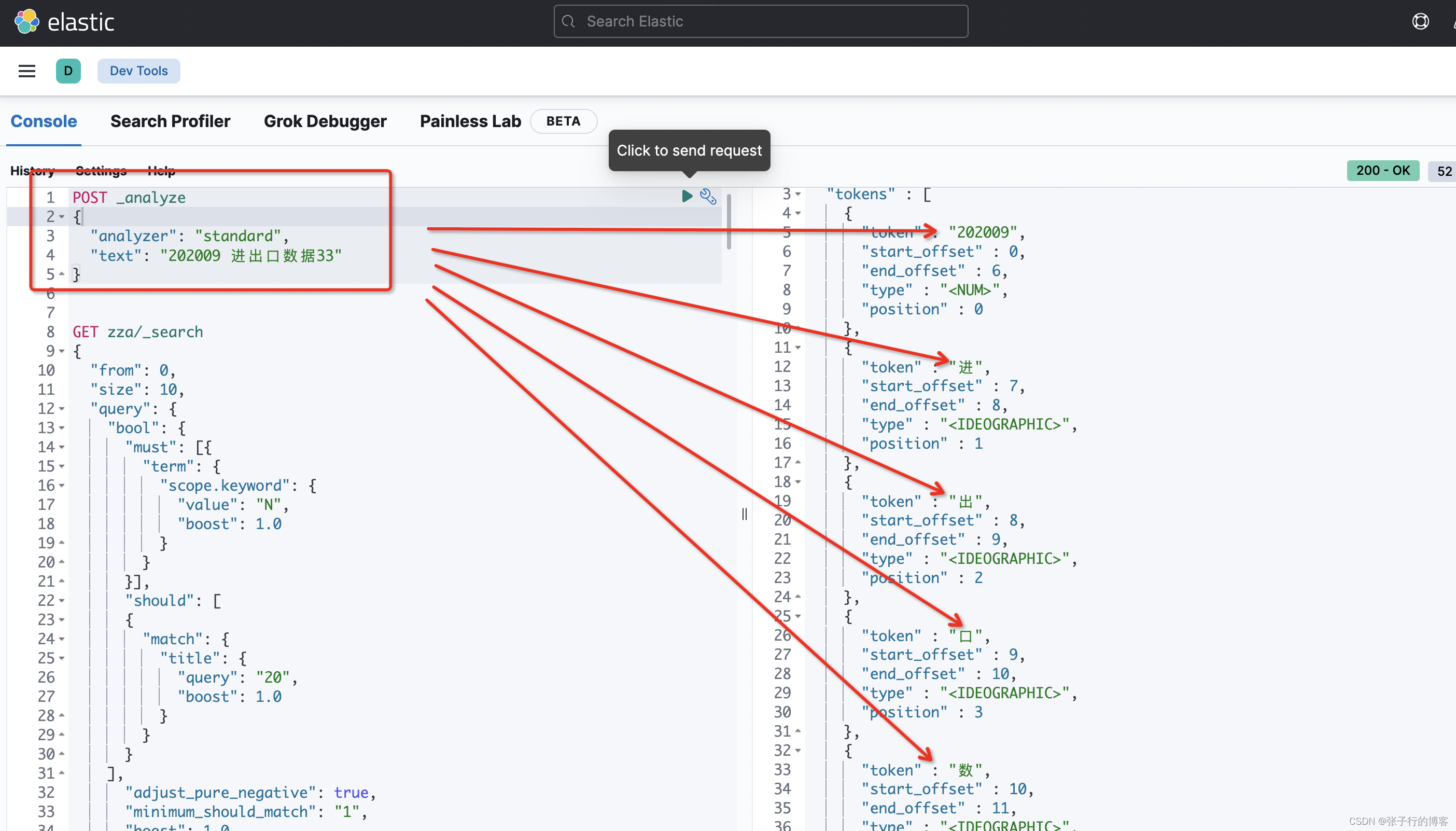
看了一下 202009 居然没有被分词,而是被当做了一个整体,当我们搜 20 的时候,是按照 20 的这个分词进行查询的,但是索引库中并没有 20 的分词,即不满足查询分词都要被词库包含的关系,更不满足分词顺序和词库保持一致,更不满足命中词库中的分词是紧挨着的条件,三大条件都不满足,能查到才怪呢?怎么去优化搜索逻辑?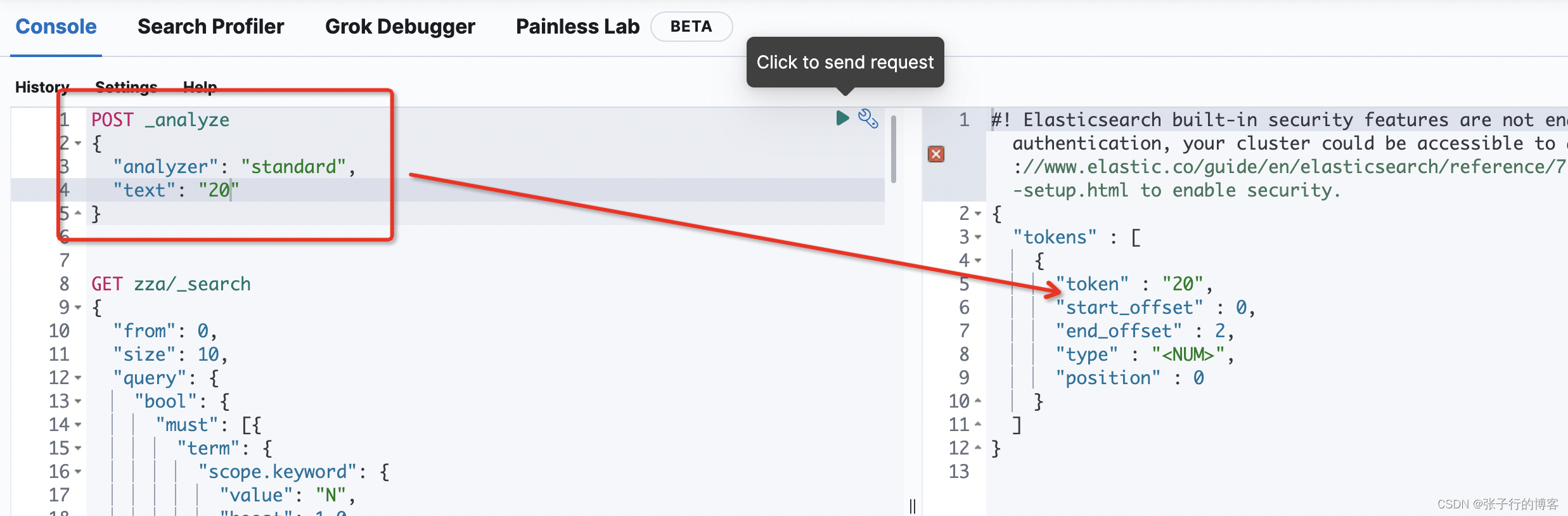
如何去解决这个问题?
接下来肯定就是优化索引库中存储的分词结构了,让 title 为( 202009 进出口数据 33) 的这条数据,存储的分词包含 (20),而不是粗略的包含一个(202009),当然你也可以使用 Es 的 模糊查询 wildcard 或者 fuzzy ,考虑到数据量过大,查询性能不咋地,决定优化索引结构,用空间换时间!!!!为什么是空间换时间?存的分词粒度都变细了,意味着存的索引体积变大,这些数据都要硬件来存储的,可不是空间换时间嘛。接下来用主流的 IK 分词器去分下词看满不满足我们的需求
IK 分词器
编写 DLS 语句,对目标数据分词,看到还是没有(20)的分词出现,直接 Pass
POST _analyze
{"analyzer": "ik_max_word","text": "202009进出口数据 33"
}
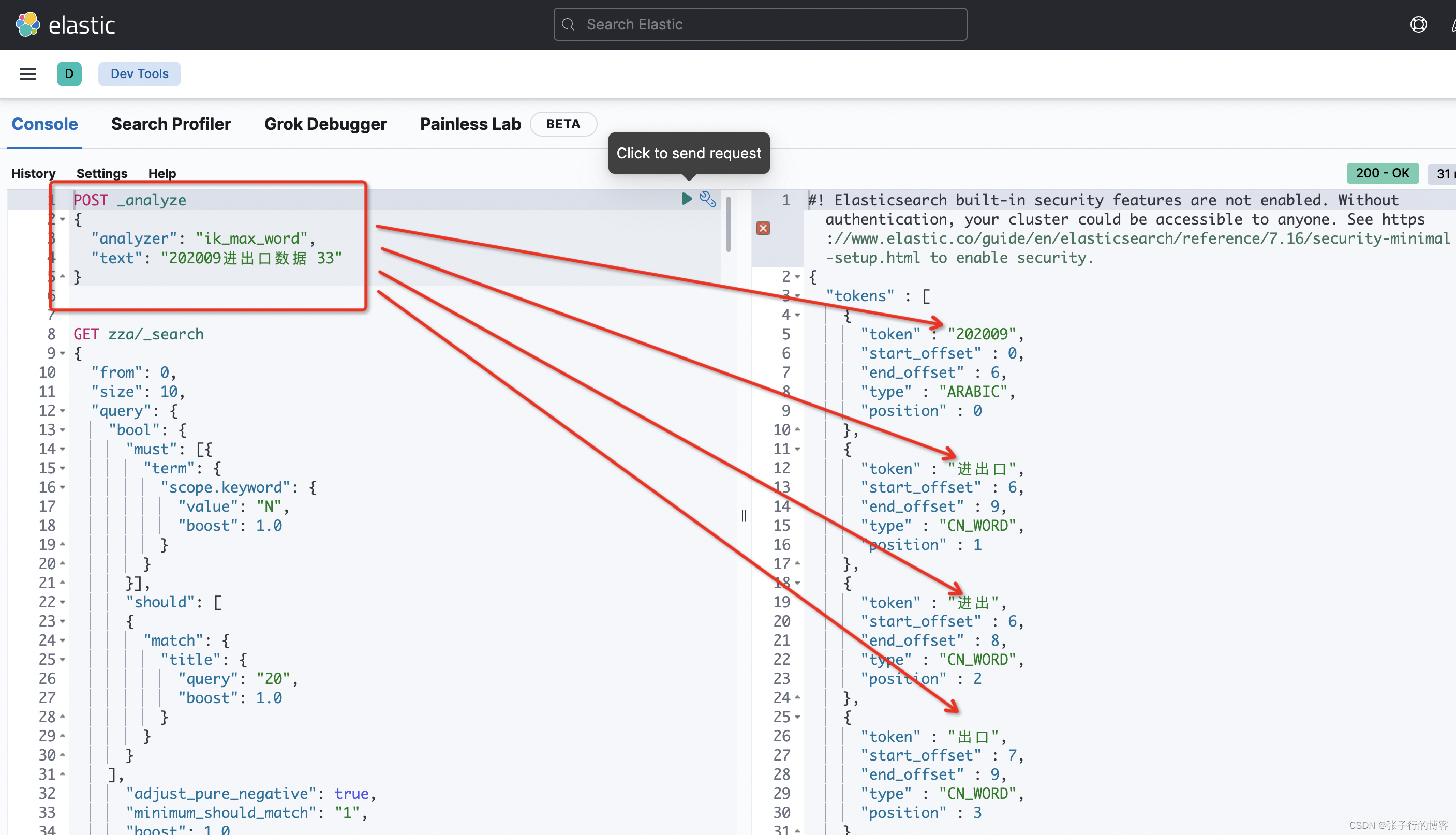
对字母分词一样,粒度不满足我们的需求,直接 Pass
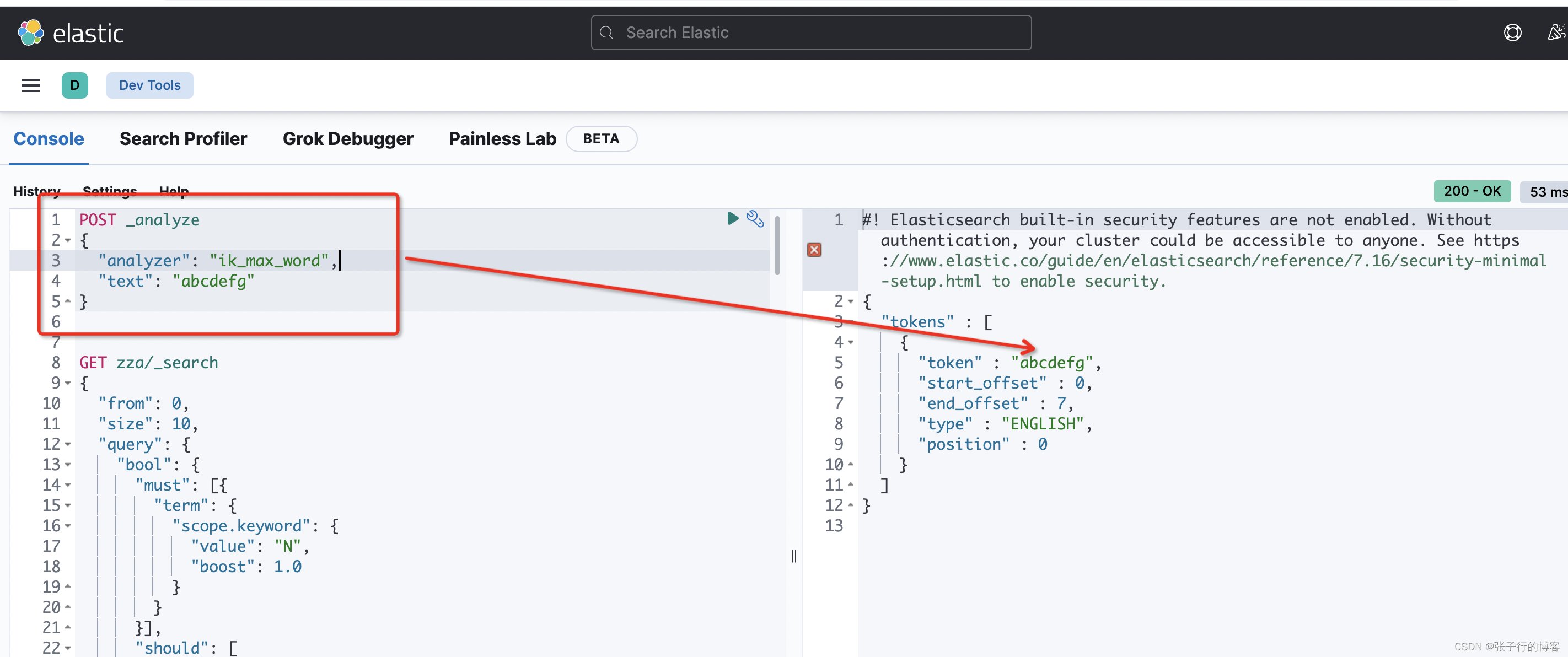
NGram 分词器使用
接下来说本文的主角 NGram 分词器,分词的粒度可以由我们自己控制。在建索引的时候设置一下 Setting 代码都是固定的就好像你使用 Java Api一样,需要注意的是里面的 min_gram 指定最小分词粒度,max_gram 指定最大分词粒度。自定义分词器名字为:my_ngram_analyzer 接来举例说明,这个自定义分词器是干啥的!!!
private static String defaultIndexSetting = "{\n" +" \"index.max_ngram_diff\":10,\n" +" \"analysis\": {\n" +" \"analyzer\": {\n" +" \"my_ngram_analyzer\": {\n" +" \"tokenizer\": \"my_ngram_tokenizer\"\n" +" }\n" +" },\n" +" \"tokenizer\": {\n" +" \"my_ngram_tokenizer\": {\n" +" \"type\": \"ngram\",\n" +" \"min_gram\": 1,\n" +" \"max_gram\": 10,\n" +" \"token_chars\": [\n" +" \"letter\",\n" +" \"digit\"\n" +" ]\n" +" }\n" +" }\n" +" }\n" +" }";
由于我只对 title 字段设置了自定义分词器,mapping 如下。
private static String defaultIndexMapping = "{\n" +"\t\"properties\": {\n" +"\t\t\"author\": {\n" +"\t\t\t\"type\": \"text\",\n" +"\t\t\t\"boost\": \"3\",\n" +"\t\t\t\"fields\": {\n" +"\t\t\t\t\"keyword\": {\n" +"\t\t\t\t\t\"type\": \"keyword\",\n" +"\t\t\t\t\t\"ignore_above\": 256\n" +"\t\t\t\t}\n" +"\t\t\t}\n" +"\t\t},\n" +"\t\t\"body\": {\n" +"\t\t\t\"type\": \"text\",\n" +"\t\t\t\"fields\": {\n" +"\t\t\t\t\"keyword\": {\n" +"\t\t\t\t\t\"type\": \"keyword\",\n" +"\t\t\t\t\t\"ignore_above\": 256\n" +"\t\t\t\t}\n" +"\t\t\t}\n" +"\t\t},\n" +"\t\t\"title\": {\n" +"\t\t\t\"boost\": \"10000\",\n" +"\t\t\t\"type\": \"text\",\n" +"\t\t\t\t\t\t \"analyzer\": \"my_ngram_analyzer\",\n" +"\t\t\t\"fields\": {\n" +"\t\t\t\t\"keyword\": {\n" +"\t\t\t\t\t\"type\": \"keyword\",\n" +"\t\t\t\t\t\"ignore_above\": 256\n" +"\t\t\t\t}\n" +"\t\t\t}\n" +"\t\t},\n" +"\t\t\"createtime\": {\n" +"\t\t\t\"type\": \"date\",\n" +"\t\t\t\"format\": \"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd\"\n" +"\t\t}\n" +"\t}\n" +"}\n";
接下来根据最新的 Setting、Mapping 配置替换之前的旧的索引,然后进行测试
log.info("create index mapping: " + tabIndex.getMapping());CreateIndexRequest indexRequest = new CreateIndexRequest(tabIndex.getIndexName().trim()).settings(tabIndex.getSetting(), XContentType.JSON).mapping("_doc", tabIndex.getMapping(), XContentType.JSON);CreateIndexResponse response = null;try {response = restHighLevelClient.indices().create(indexRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();tabIndexService.delete(new EntityWrapper<TabIndex>().eq("index_name", tabIndex.getIndexName()));return JsonData.buildError("失败" + e.getMessage());}if (response != null) return JsonData.buildSuccess(response.isAcknowledged());else return JsonData.buildError("失败");
替换 NGram 分词器后进行测试
输入关键字:20,发现 title 为 (202009 进出口数据 33) 的这条数据还是查不到???????what fa,再次检查索引库分词,编写 DLS 语句看看,由于创建的新索引的名称是 zza,这里对 zza 索引下面标题包含 (202009 进出口数据 33)的数据进行分词,看看 Es 是如何存的!!!
POST /zza/_analyze
{"field": "title","text": "202009 进出口数据 33"
}
可以看到此时的分词存储了 (2,20,202…)按道理来说查 2 或者 20 或者 202 等等都可以查到这条数据的。难道见鬼啦?于是我决定将代码的生成的 DLS 语句直接 Copy 到 kibana 中跑一下,看到底是代码 Api 的 Bug 还是其他问题。

于是我就这个 DLS 语句运行了一下,其实不是见鬼了,是我们需要理解一下 termQuery 与 matchPhraseQuery 的查询原理!!!
matchPhraseQuery 查询原理
会将搜索关键字进行分词(这个根据索引用到的分词器一致),然后与词库中的分词进行匹配。例如,现在有一条 title 为(202009 进出口数据 33)的数据,当我们搜 20 的时候,会根据(2,20,0)去匹配词库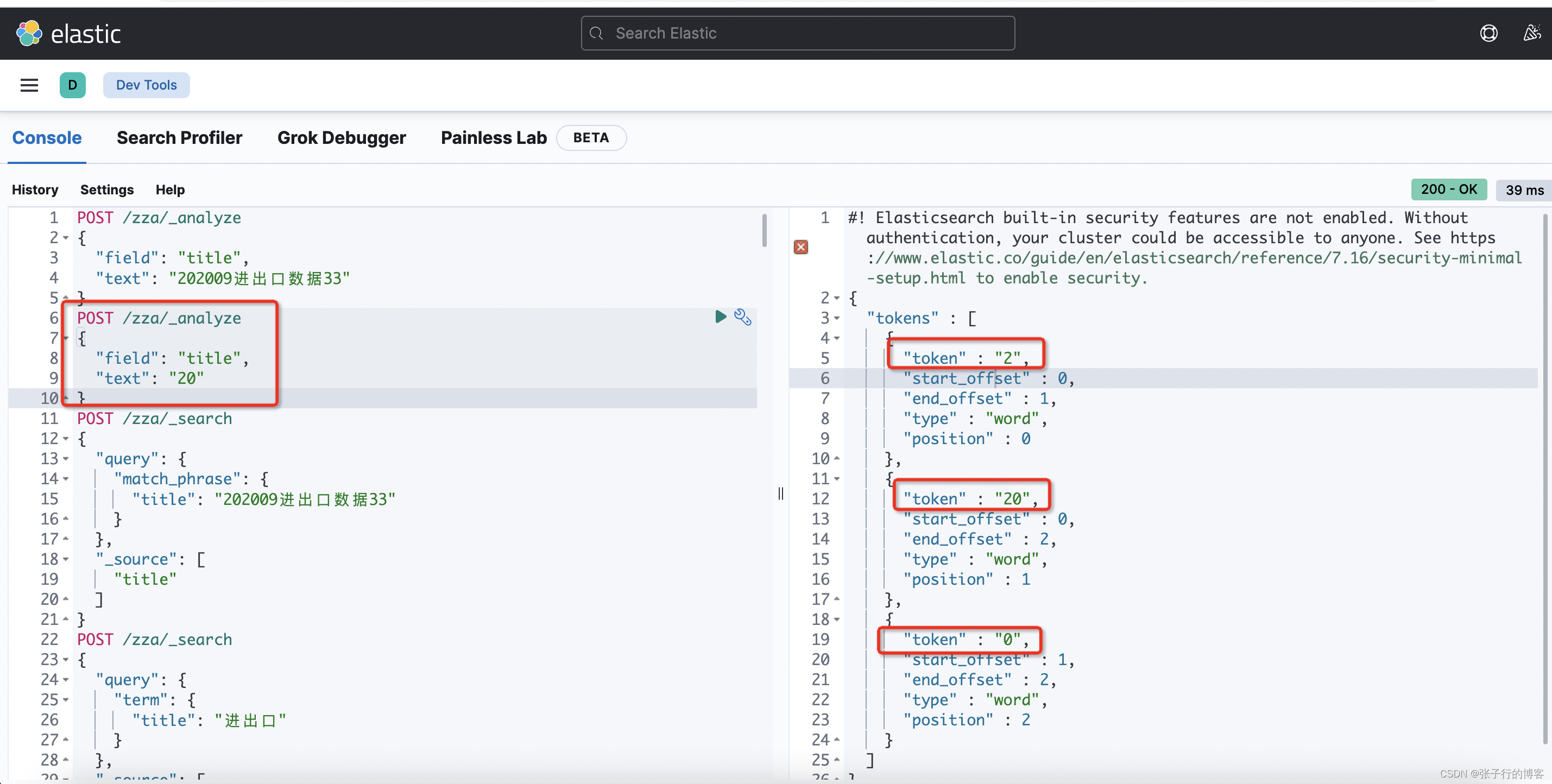
但是此时词库是按照(2,20,202…0)这个顺序存的。
再来回顾一下 matchPhraseQuery 命中索引的三大条件
- 搜索关键字分词要被词库存的分词完全包含
- 在点一的基础上,搜索分词顺序要和词库保持一致
- 在前俩点都满足的情况下,词库中匹配到的分词顺序要紧挨着
我们搜关键字 20 时,满足了上述点 1,2。但是不满足点 3,因此使用 matchPhraseQuery 搜不到 title 为(202009 进出口数据 33)的这条数据。那么有什么办法解决吗?答案是有的。就是指定 slop 参数。指定分词紧挨着的最大单位,默认是 1,通过调大这个参数也可以查出来指定数据
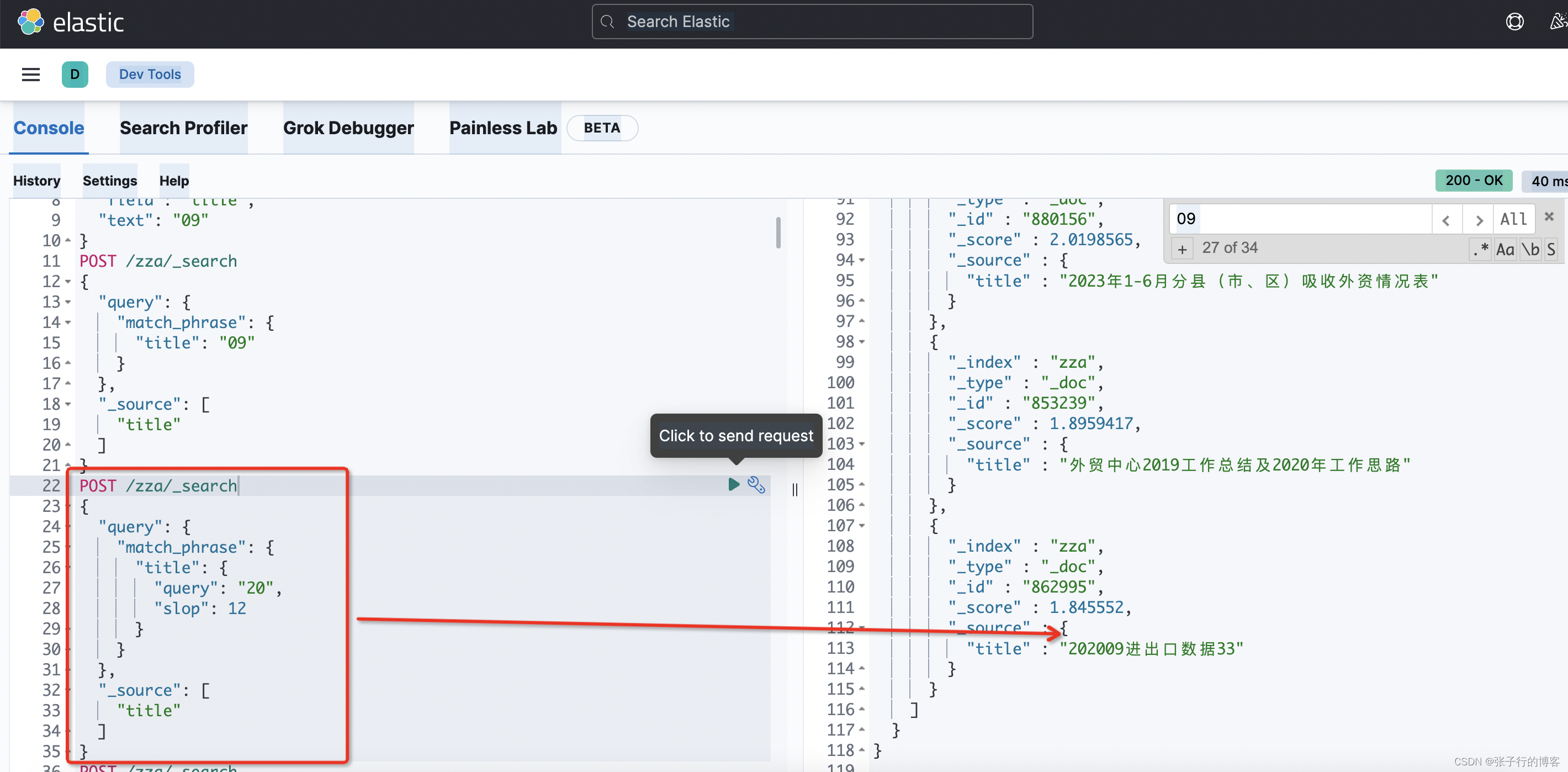
不指定 slop 的情况下查不到数据,但是我现在的需求只要是关键字中包含 20 的数据都要被查到,调 slop 也不是办法,因此 title 字段的搜索不用 matchPhraseQuery,改用 termQuery
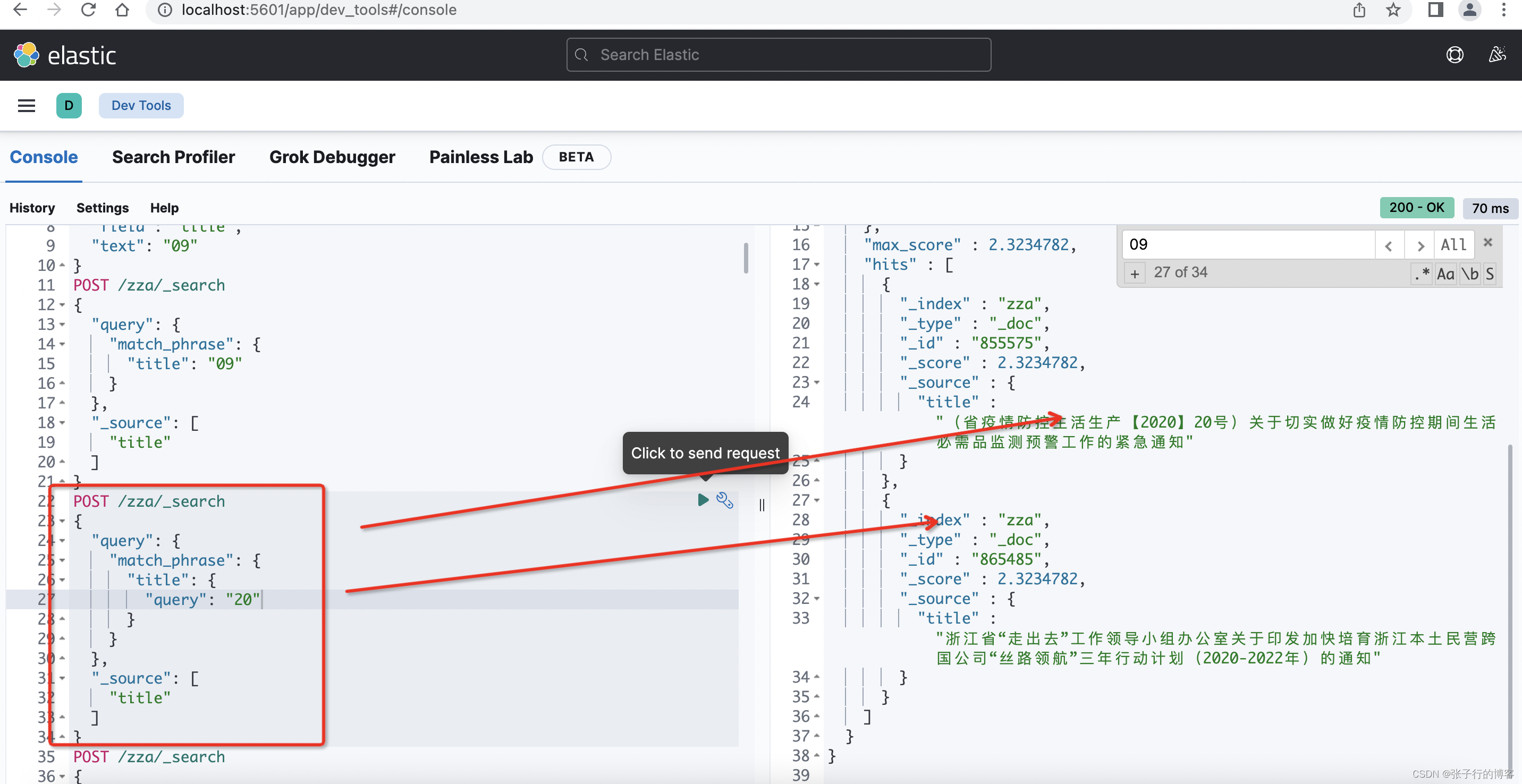
termQuery 查询原理
搜索的关键字不会进行分词去匹配词库,搜 20 就会以 20 去匹配,命中词库中的一个分词即可,例如;现在有一条 title 为(202009 进出口数据 33)的数据,搜关键字 20 即可查出数据,满足现有的业务需求。

因此最后还改造了一下业务代码逻辑大概是这样,title 字段用 termQuery,其他字段用 matchPhraseQuery。就可以了。
if (StringUtils.isNotEmpty(articleRequest.getKeyword())) {for (int i = 0; i < articleRequest.getKeys().length; i++) {if ("title".equals(articleRequest.getKeys()[i]))boolQuery.should(QueryBuilders.termQuery(articleRequest.getKeys()[i], articleRequest.getKeyword()));elseboolQuery.should(QueryBuilders.matchPhraseQuery(articleRequest.getKeys()[i], articleRequest.getKeyword()));}boolQuery.minimumShouldMatch(1);
}
总结
matchPhraseQuery 命中条件
- 搜索关键字分词要被词库存的分词完全包含
- 在点一的基础上,搜索分词顺序要和词库保持一致
- 在前俩点都满足的情况下,词库中匹配到的分词顺序要紧挨着
matchPhraseQuery 在查询前会对关键字进行分词,用到的分词器和索引中该字段指定的分词器一致,例如本文的 title 用到了 NGram 分词器,那么使用如下代码,检索 title 字段时,用到的分词器也是用的 Ngram
QueryBuilders.termQuery("title", articleRequest.getKeyword())

这篇关于基于 NGram 分词,优化 Es 搜索逻辑,并深入理解了 matchPhraseQuery 与 termQuery的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







