本文主要是介绍回炉整理《数据分析实战45讲》之基础篇 -- 11.数据清洗(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上篇补了 “完全合一” 中的“完整性”这个部分掌柜觉得需要了解的知识点,接下来继续看全面性。还是回到服装店会员数据表那里,掌柜觉得这里的“全面性”指的是数据要规范:即大小写要统一、有单位的要统一单位、数据长度也要一致(小数点后面是几位都要统一)、数据名称保持一致等。
- 那么再看这里的表格可以发现出现了单位不统一以及之前对均值填充的时候小数点位数变多的情况,只需要统一单位和小数点位数即可。这里把年龄的小数点位数都统一为之前的一位、单位都统一为千克(kgs):
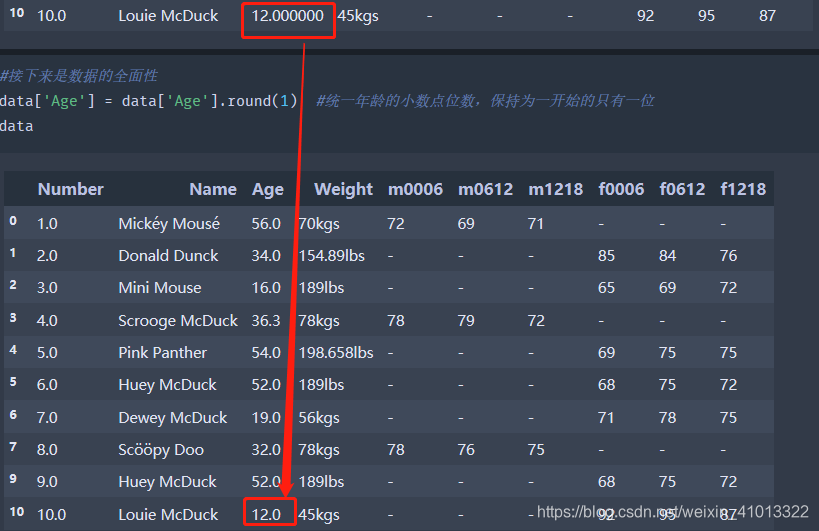
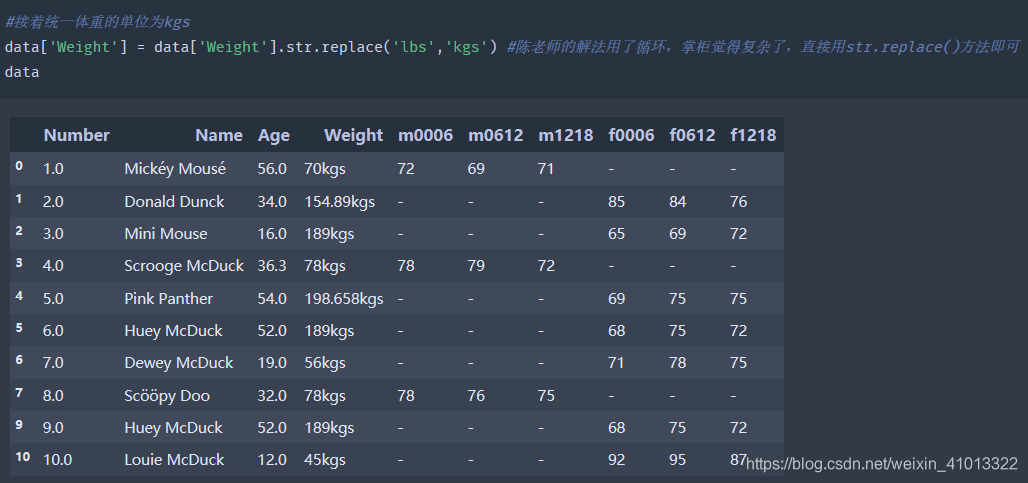
- 上面的没有补充的,接着来到 “合法性”,简单来讲就是数据要合乎常理,不会出现异常的情况,比如年龄是负数?性别未知?数据类型出现非ASCII字符等。
(小小了解一下:所谓的ASCII,通俗来讲就是用一套统一规定的用来表示现代英语字符 同计算机中二进制数之间关系的编码规则。而这套规则又是当时美国的组织提出来的,所以又叫做 美国信息互换标准码(American Standard Code for Information Interchange)。(这里就不再多拓展了,因为这也是一个一挖就很深的点😂,有兴趣的朋友可以私下多面向谷歌了解)
再回到这里,这个原始会员信息表出现了非ASCII字符(以语感来说是法语),所以这里进行删除或者替换操作:
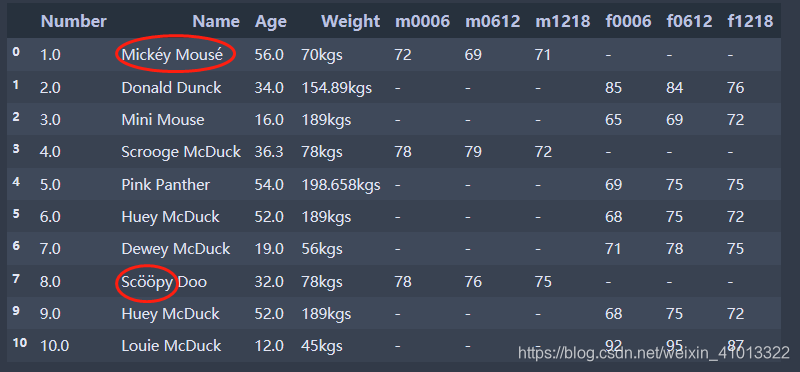
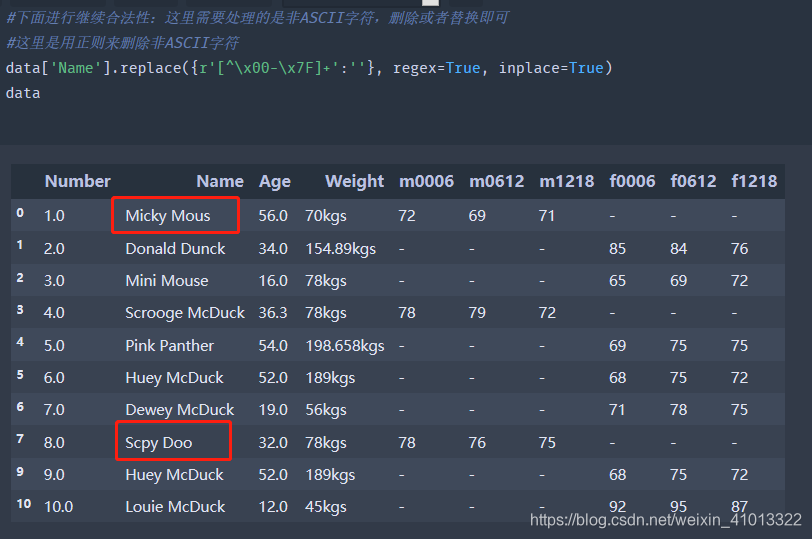
这里用的是正则匹配ASCII字符,然后再进行删除,可以发现第0行和第7行的非ASCII字符被删除了。
那如果不想删除非ASCII字符改变原样本,就想直接替换呢?
补充第三点👉:pandas中如何替换非ASCII字符? 可以使用下面这个方法:
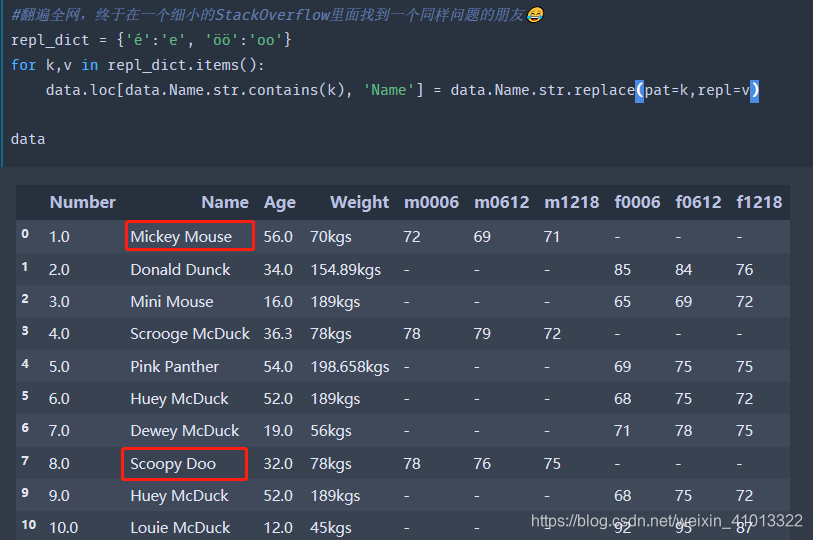
先创建替换的对应字典,然后使用pandas的字符串替换方法即可!
- 补充第四点👉:如何处理异常值?* 有三种解决办法:
- 删除异常值;
- 把它当作缺失值,用缺失值的方法来处理;
- 不处理。
PS:同样,异常值的处理还是要考虑实际情况,有时候不处理可以发现数据集的其他隐藏信息,比如医学检测的时候。
- 最后来看唯一性,即数据要唯一,不存在重复、一对多的情况。所以这里存在两个问题:
-
一个是Name列包含两个参数First Name 和Last Name,一般不这样操作。所以需要进行一列变多列的拆分:
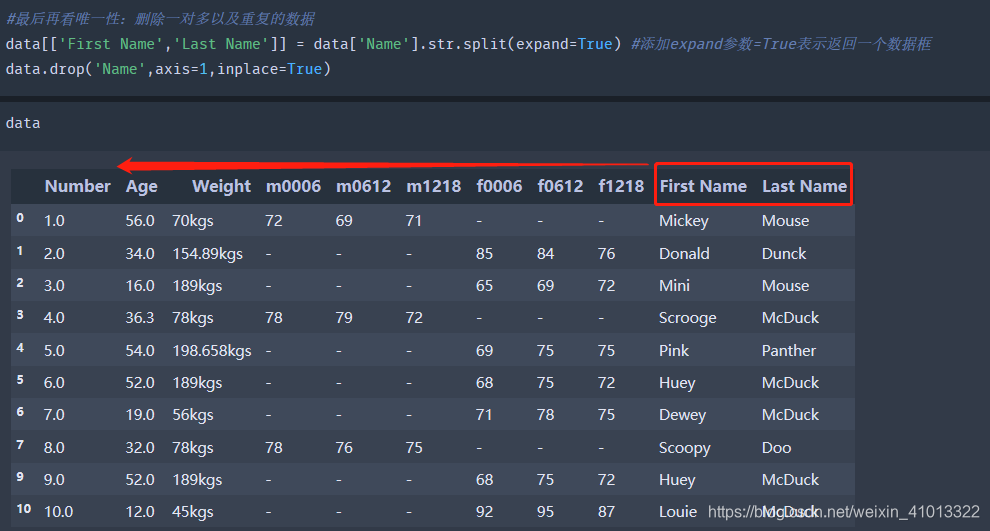
但是发现没,拆分的新数据列跑到最后去了,所以需要再处理一下:
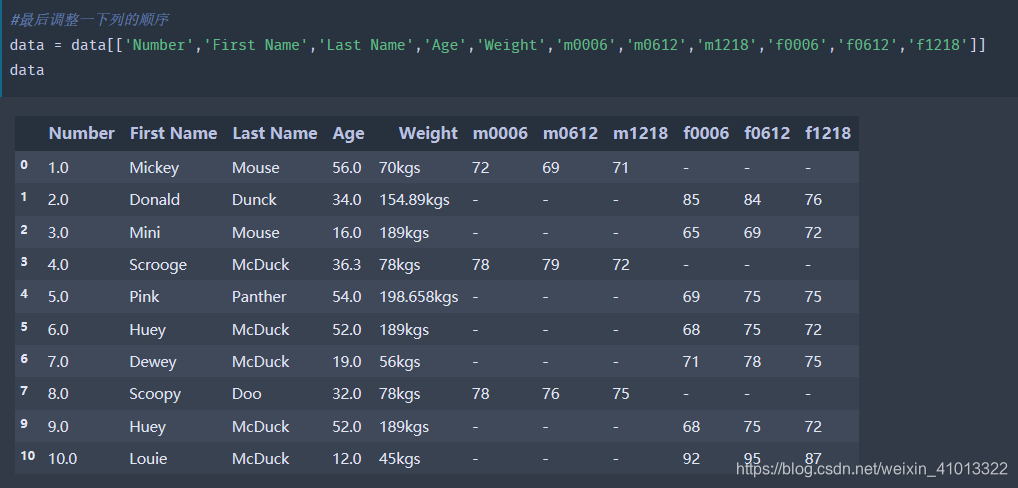
-
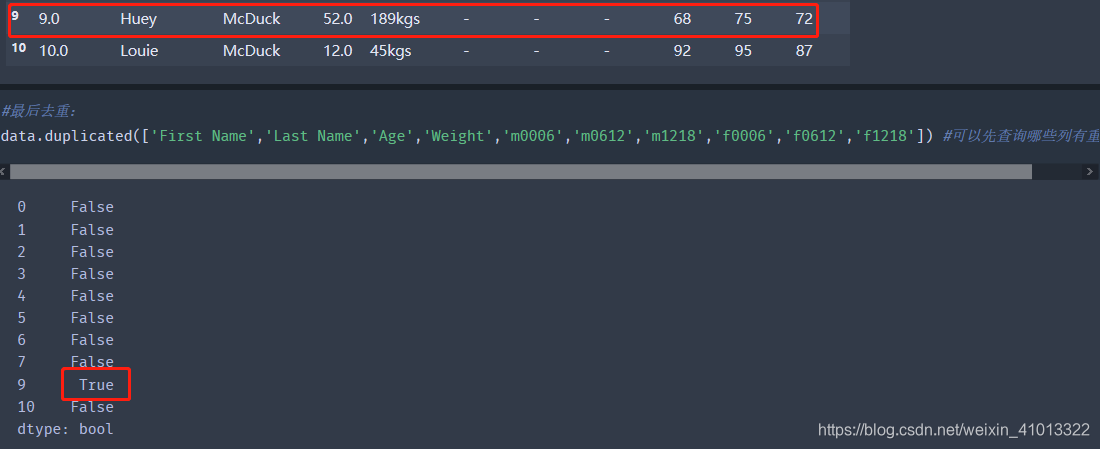
最后处理重复数据,用duplicated()查询重复数据,再用drop_duplicates()方法删除重复数据:
(PPS: 关于数据去重掌柜这里就不补充了,因为之前的博文写过一次,还对比了三种工具去重的方法,可以移步👉数据去重的各种方法汇总)
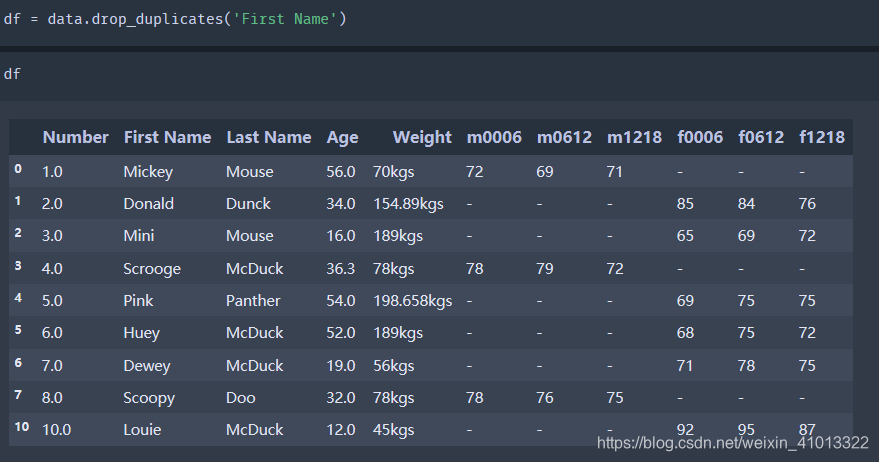
最后再把处理干净的表存储到Excel中:
总算把第十一章要补的知识点搞定了,才发现一章就可以整理好多出来😂,最后脑图和代码掌柜都一并打包到GitHub去了,请自取👇:
GitHub
然后十一章还留了一个练习题:
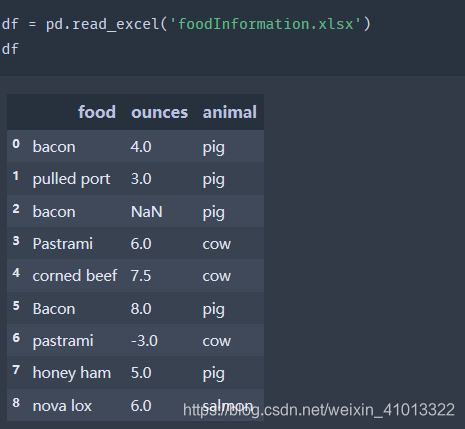
想要练习和参考答案的可以一并去GitHub上面查看,喜欢可以关注,谢谢!😄
参考资料:
Pandas替换非ASCII字符
这篇关于回炉整理《数据分析实战45讲》之基础篇 -- 11.数据清洗(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




