本文主要是介绍学习笔记|多独立样本秩和检验|克鲁斯卡尔-沃利斯检验|多个组间的多重比较|规范表达|《小白爱上SPSS》课程:SPSS第十四讲 | 多独立样本秩和检验如何做?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 学习目的
- 软件版本
- 原始文档
- 多独立样本秩和检验
- 一、实战案例
- 读数据:
- 二、统计策略
- 三、SPSS操作
- 1、正态性检验
- 2、多个独立样本的秩和检验
- 3、多个组间的多重比较
- 四、结果解读
- 第一,描述性统计结果。
- 第二 ,给出的是不同训练年限各自的样本量和平均秩。
- 第三,给出的是Kruskal-Wallis H检验的统计量、自由度、和渐进显著性。
- 第四,表4分别进行6次多重比较
- 五、规范报告
- 1、规范表格
- 2、规范文字
- 六、划重点
学习目的
SPSS第十四讲 | 多独立样本秩和检验如何做?
软件版本
IBM SPSS Statistics 26。
原始文档
《小白爱上SPSS》课程
#统计原理
多独立样本秩和检验
之前学习了多组连续型数据的差异性比较,当独立数据且呈正态分布、方差齐时采用F检验。如果数据是非正态分布,就不能使用F检验。此时,可采用两种统计策略:一是将数据转化为正态分布数据;二是使用多样本秩和检验即Kruskal-Wallis H 检验。
多个独立样本秩和检验与两样本秩和检验一样,都是非参数检验。这种检验方法对数据正态性和方差齐性没有要求,他们主要探讨数据总体分布位置有无差异,而非总体均数。
一、实战案例
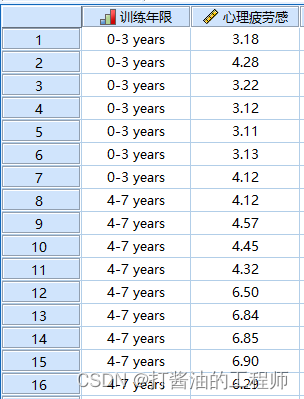
小白想考察训练年限对大侠们心理疲劳感的影响。他随机抽取32名大侠,根据训练年限,研究对象被分为4组:0-3年、4-7年、8-10年、>10年。利用Likert量表调查的心理疲劳感,分数越高,心理疲劳感越强。
问:训练年限是否会影响心理疲劳感?
读数据:
GETFILE='E:\E盘备份\recent\小白爱上SPSS\小白数据\第十四讲:多独立样本Kruskal-Wallis H检验.sav'.
二、统计策略
统计分析策略口诀“目的引导设计,变量确定方法”.
针对上述案例,扪心六问。
Q1:本案例研究目的是什么?
A:比较差异。
Q2:比较的组数是多少呢?
A:四组数据。
Q3:本案例属于什么研究设计?
A:观察性研究。
Q4:有几个变量?
A:有两个变量。训练年限为分组变量,心理疲劳感是结局变量
Q5:结局变量属于什么类型变量?
A:连续型变量
Q6:数据服从正态分布么?
A:需要检验。
若服从,采用单因素方差分析;若不服从正态,可采用多独立样本秩和检验即Kruskal-Wallis H 检。
概括而言,如果数据满足以下条件,则采用多独立样本秩和检验。
三、SPSS操作
1、正态性检验
本案例需要对四组数据都进行正态性检验。
正态性检验命令行:
EXAMINE VARIABLES=心理疲劳感 BY 训练年限/PLOT HISTOGRAM NPPLOT /*若无此行,则不输出正态性检验表*//COMPARE GROUPS /STATISTICS DESCRIPTIVES /CINTERVAL 95 /MISSING LISTWISE /NOTOTAL.
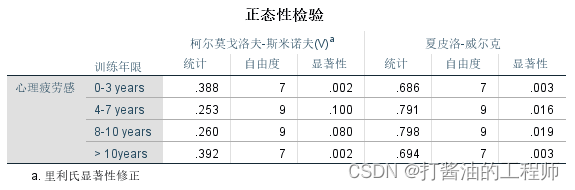
经S-W(夏皮洛-威尔克)检验,四组不同训练年限心理疲劳感的p值分别为0.003、0.016、0.019和0.003,均小于0.05,有统计学意义,不支持原假设,可认为四组数据不符合正态分布。因此,比较四组数据,采用非参数检验中的多个独立样本的秩和检验。
2、多个独立样本的秩和检验
Step1: 点击分析—非参数检验—旧对话框—K个独立样本
Step2: 将"心理疲劳感"选入检验变量列表 将"训练年限"选入分组变量
Step3:点击【定义范围】,此处填写该分组变量在数据库赋值中的最小值“1"和最大值“4”。
Step4:点击【选项】,勾选“描述和四分位数”,点击继续。
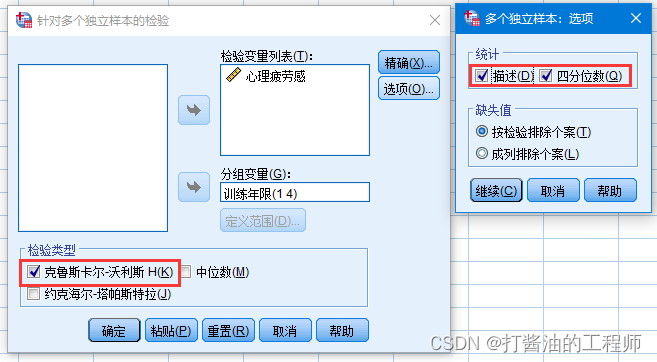
Step5:在检验类型中,选择克鲁斯卡尔-沃利斯检验方法。
Step6: 点击确定,输出结果。
命令行:
NPAR TESTS /K-W=心理疲劳感 BY 训练年限(1 4) /STATISTICS DESCRIPTIVES QUARTILES /MISSING ANALYSIS.
3、多个组间的多重比较
此时需要多样本秩和检验的第二种操作方法
多个独立样本秩和检验的结果,当p<0.05时,可以进行多个组间的多重比较。可以采用两样本秩和检验,SPSS带的Bonfereoni方法等。
Step1: 依次点击分析–非参数检验–独立样本;
Step2: 点击“字段”,选择“心理疲劳感”到“检验字段”框中,选择“训练年限”到“组”框中;
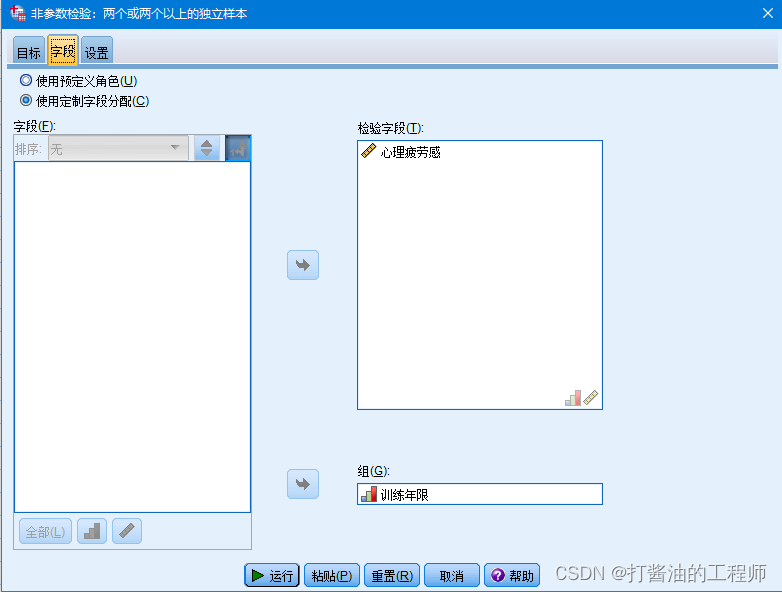
Step3:点击“设置”,在界面中选择“定制检验”,选择“克鲁斯卡尔-沃利斯单因素分析”,多重比较选择“全部成对”,点击“运行”。
对于SPSS25版本:
Step4: 得到多样本秩和检验分析结果,双击该结果。
Step5: 点击右下方选项框,选择成对比较,输出结果。
Step6: 点击确定,输出结果。
注意:以上操作是SPSS25版本,如果是SPSS26以上版本,则可不用操作Step4和Step5。
命令行:
*Nonparametric Tests: Independent Samples.
NPTESTS /INDEPENDENT TEST (心理疲劳感) GROUP (训练年限) KRUSKAL_WALLIS(COMPARE=PAIRWISE) /MISSING SCOPE=ANALYSIS USERMISSING=EXCLUDE /CRITERIA ALPHA=0.05 CILEVEL=95.
四、结果解读
Kruskal-Wallis H 检验检验结果有三张表格。
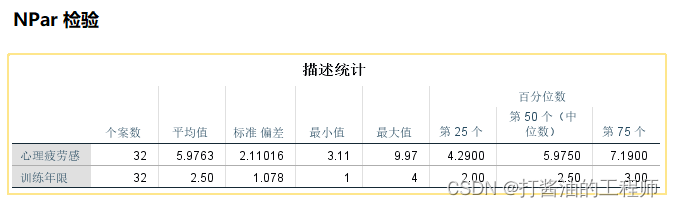
第一,描述性统计结果。
分别为样本量、均数、标准差、最小值、最大值、第25,50,75百分位数。
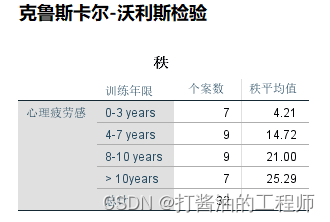
第二 ,给出的是不同训练年限各自的样本量和平均秩。
第三,给出的是Kruskal-Wallis H检验的统计量、自由度、和渐进显著性。
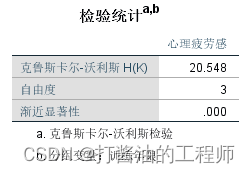
从表中可知,H=20.548,p<0.001。
第四,表4分别进行6次多重比较
显示各次比较的统计量、标准误、p值和校正p值

从表中可知,0-3years与8-10years的疲劳感之间有显著性差异,p=0.002;
0-3years与>10years的疲劳感之间有显著性差异, p<0.001。其他各组之间无显著性差异。
五、规范报告
规范报告有多种方式,本公众号只提供一种方式供参考。
1、规范表格

注:图中采用显著性字母标注法。如果两组之间有共同字母,则表明无显著性差异;若没有相同字母,则表示有显著性差异。
如0-3年组与4-7年组,有共同字母a,表明无显著性差异;而0-3年与8-10年组无共同字母,则表明有显著性差异。
2、规范文字
由于数据不服从正态分布,故采用多样本的即Kruskal-Wallis H 检验。
结果显示,不同训练年限的疲劳感存在着统计学差异(H=20.548,p<0.001)。
Bonferroni多重均数比较结果显示,训练0-3年与训练8-10年的疲劳感有显著性差异(p=0.002);训练0-3年与训练年限>10年的疲劳感有显著性差异(p<0.001),其他各组之间的疲劳感无显著性差异。
六、划重点
1、多组连续型数据的比较一般方法有两种,一种是F检验,一种是非参数秩和检验。
2、多组数据如果不符合正态分布,或者数据为次序数据,采用多样本秩和检验,即Kruskal-Wallis 检验。
3、Kruskal-Wallis H检验对连续型数据分布没有要求,不要求正态性和方差齐性。
这篇关于学习笔记|多独立样本秩和检验|克鲁斯卡尔-沃利斯检验|多个组间的多重比较|规范表达|《小白爱上SPSS》课程:SPSS第十四讲 | 多独立样本秩和检验如何做?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




