本文主要是介绍【43k字】双语理解Large Vision Model:Segment Anything,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:猛码Memmat
目录
- Abstract
- 1. Introduction
- Task
- Model
- Data engine
- Dataset
- Responsible AI
- Experiments
- Release
- 2. Segment Anything Task
- Task
- Pre-training
- Zero-shot transfer
- Related tasks
- Discussion
- 3. Segment Anything Model
- Image encoder
- Prompt encoder
- Mask decoder
- Resolving ambiguity
- Efficiency
- Losses and training
- 4. Segment Anything Data Engine
- Assisted-manual stage
- Semi-automatic stage
- Fully automatic stage
- 5. Segment Anything Dataset
- Images
- Masks
- Mask quality
- Mask properties.
- 6. Segment Anything RAI Analysis
- Geographic and income representation
- Fairness in segmenting people
- 7. Zero-Shot Transfer Experiments
- Implementation
- 7.1 Zero-Shot Single Point Valid Mask Evaluation
- Task
- Datasets
- Results
- 7.2 Zero-Shot Edge Detection
- Approach
- Results
- 7.3 Zero-Shot Object Proposals
- Approach
- Results
- 7.4 Zero-Shot Instance Segmentation
- Approach
- Results
- 7.5 Zero-Shot Text-to-Mask
- Approach
- Results
- 7.6 Ablations
- 8. Discussion
- Foundation models
- Compositionality
- Limitations
- Conclusion
- Acknowledgments
- References
- Appendix
- A. Segment Anything Model and Task Details
- Image encoder
- Prompt encoder
- Lightweight mask decoder
- Making the model ambiguity-aware
- Losses
- Training algorithm
- Training recipe
- B. Automatic Mask Generation Details
- Cropping
- Filtering
- Postprocessing
- Automatic mask generation model
- SA-1B examples
- C. RAI Additional Details
- Inferring geographic information for SA-1B
- Inferring geographic information for COCO and Open Images.
- Inferring income information
- Fairness in segmenting people
- Fairness in segmenting clothing
- D. Experiment Implementation Details
- D.1. Zero-Shot Single Point Valid Mask Evaluation
- Datasets
- Point sampling
- Evaluation
- Baselines
- Single point ambiguity and oracle evaluation
- D.2. Zero-Shot Edge Detection
- Dataset and metrics
- Method
- Visualizations
- D.3. Zero-Shot Object Proposals
- Dataset and metrics
- Baseline
- Method
- D.4. Zero-Shot Instance Segmentation
- Method
- D.5. Zero-Shot Text-to-Mask
- Model and training
- Generating training prompts
- Inference
- D.6. Probing the Latent Space of SAM
- E. Human Study Experimental Design
- Models
- Datasets
- Methodology
- Results
- F. Dataset, Annotation, and Model Cards
- F.1. Dataset Card for SA-1B
- F.2. Data Annotation Card
- G. Annotation Guidelines
- 文献来源
- 项目链接

Abstract

the largest segmentation dataset to date (by far)
我们介绍了Segment Anything (SA)项目:一个用于图像分割的新任务、模型和数据集。在数据收集循环中使用我们高效的模型,我们构建了迄今为止(到目前为止)最大的分割数据集,在1100万张授权和隐私尊重的图像上拥有超过10亿个面具。该模型被设计和训练为可提示的,因此它可以将zero-shot转移到新的图像分布和任务。我们评估了它在许多任务上的能力,发现它的零镜头表现令人印象深刻——经常与之前的完全监督结果竞争,甚至更好。我们在https://segment-anything.com上发布了片段任何模型(SAM)和对应的1B掩模和11M图像数据集(SA-1B),以促进对计算机视觉基础模型的研究。
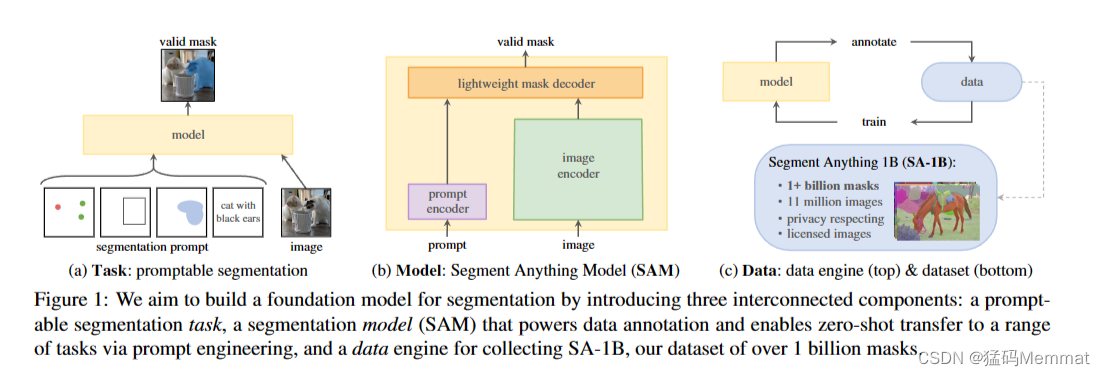
我们的目标是通过引入三个相互连接的组件来构建一个分割的基础模型:一个提示分割任务,一个分割模型(SAM),它为数据注释提供动力,并通过提示工程实现零镜头传输到一系列任务,以及一个用于收集SA-1B的数据引擎,我们的数据集超过10亿个mask。
1. Introduction



在网络规模的数据集上预训练的大型语言模型正在以强大的零次和少次泛化彻底改变NLP。这些“基础模型”[8]可以泛化到训练过程中看不到的任务和数据分布。这种功能通常通过提示工程实现,在提示工程中,使用手工制作的文本提示语言模型为手头的任务生成有效的文本响应。当使用来自网络的丰富文本语料库进行缩放和训练时,这些模型的零镜头和少镜头性能与相比惊人地好(甚至在某些情况下匹配)微调模型[10,21]。经验趋势表明,这种行为随着模型规模、数据集大小和总训练计算而改善[56,10,21,51]。
基础模型也在计算机视觉中进行了探索,尽管程度较轻。也许最突出的插图是对齐来自网络的配对文本和图像。例如,CLIP[82]和ALIGN[55]使用对比学习来训练对齐两种模式的文本和图像编码器。经过训练后,经过设计的文本提示可以实现对新颖视觉概念和数据分布的零概率泛化。这样的编码器还可以有效地与其他模块组合以实现下游任务,例如图像生成(例如DALL·E[83])。虽然在视觉和语言编码器方面已经取得了很大的进展,但计算机视觉包括了超出这一范围的广泛问题,并且对于其中许多问题,不存在丰富的训练数据。
在这项工作中,我们的目标是建立一个图像分割的基础模型。也就是说,我们寻求开发一个可提示的模型,并使用支持强大泛化的任务在广泛的数据集上对其进行预训练。有了这个模型,我们的目标是用快速工程解决一系列新的数据分布上的下游分割问题。
该计划的成功取决于三个组成部分:任务、模型和数据。为了开发它们,我们解决了以下关于图像分割的问题:
- 什么任务可以实现零射击泛化?
- 相应的模型架构是什么?
- 哪些数据可以支持这个任务和模型?
这些问题错综复杂,需要全面解决。我们首先定义一个可提示的分割任务,它足够普遍,可以提供强大的预训练目标,并支持广泛的下游应用。这项任务需要一个支持灵活提示的模型,并可以在提示时实时输出分割掩码,以允许交互式使用。为了训练我们的模型,我们需要一个多样化的、大规模的数据源。不幸的是,没有网络规模的数据源进行分割;为了解决这个问题,我们构建了一个“数据引擎”,即在使用我们的高效模型来辅助数据收集和使用新收集的数据来改进模型之间进行迭代。接下来,我们将介绍每个相互连接的组件,然后是我们创建的数据集和证明我们方法有效性的实验。
Task

在NLP和最近的计算机视觉中,基础模型是一个有前途的发展,它可以通过使用“提示”技术对新数据集和任务执行零次和少次学习。受此工作的启发,我们提出了可提示分割任务,其目标是在给定任何分割提示时返回有效的分割掩码(见图1a)。提示符简单地指定要在图像中分割什么,例如,提示符可以包括标识对象的空间或文本信息。有效输出掩码的要求意味着,即使提示符是模糊的,并且可能指向多个对象(例如,衬衫上的一个点可能表示衬衫或穿衬衫的人),输出也应该是这些对象中至少一个的合理掩码。我们使用提示分割任务作为预训练目标,并通过提示工程解决一般的下游分割任务。
Model

可提示的分割任务和实际使用的目标对模型体系结构施加了约束。特别是,该模型必须支持灵活的提示,需要实时平摊计算掩码以允许交互使用,并且必须能够识别歧义。令人惊讶的是,我们发现一个简单的设计满足了所有三个约束:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后将两个信息源组合在一个轻量级的掩码解码器中,预测分割掩码。我们把这个模型称为分段任意模型(Segment Anything model),或SAM(见图1b)。通过将SAM分离为图像编码器和快速提示编码器/掩码解码器,可以使用不同的提示重用相同的图像嵌入(及其成本摊销)。给定图像嵌入,提示编码器和掩码解码器在网络浏览器中从提示符中预测掩码,时间为~ 50ms。我们主要关注点、框和掩码提示,并使用自由形式的文本提示来呈现初始结果。为了使SAM能够识别歧义,我们将其设计为为单个提示预测多个掩码,允许SAM自然地处理歧义,例如衬衫vs.人的示例。
Data engine

为了实现对新数据分布的强泛化,我们发现有必要在一个大而多样的掩码集上训练SAM,而不是任何已经存在的分割数据集。虽然基础模型的典型方法是在线获取数据[82],但掩码自然并不丰富,因此我们需要一种替代策略。我们的解决方案是构建一个“数据引擎”,即我们与模型在循环数据集注释共同开发我们的模型(见图1c)。我们的数据引擎有三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM帮助注释者注释掩码,类似于经典的交互式分割设置。在第二阶段,SAM可以自动为对象的一个子集生成掩码,方法是提示它可能的对象位置,而注释器则专注于注释剩余的对象,这有助于增加掩码的多样性。在最后阶段,我们用前景点的规则网格提示SAM,平均每张图像产生约100个高质量蒙版。
Dataset

我们最终的数据集SA-1B,包括来自11M个许可和隐私保护图像的超过1b个掩码(见图2)。SA-1B,使用我们的数据引擎的最后阶段完全自动收集,比任何现有的分割数据集[66,44,117,60]拥有400倍多的掩码,并且我们广泛验证,掩码具有高质量和多样性。我们希望SA-1B能够成为一种有价值的资源,用于建立新的基础模型。
Responsible AI

在使用SA-1B和SAM时,我们研究并报告潜在的公平性问题和偏见。SA-1B中的图像跨越了地理和经济上不同的国家,我们发现SAM在不同人群中的表现相似。总之,我们希望这将使我们的工作在现实用例中更加公平。我们在附录中提供了模型和数据集卡。
Experiments

我们广泛地评估SAM。首先,使用不同的23个分割数据集的新套件,我们发现SAM从单个前景点生成高质量的掩码,通常仅略低于手动注释的地面真相。其次,我们在使用提示工程的零镜头传输协议下的各种下游任务上发现了持续强大的定量和定性结果,包括边缘检测、对象建议生成、实例分割和文本到掩码预测的初步探索。这些结果表明,SAM可以在即时工程中开箱即用,解决涉及SAM训练数据之外的对象和图像分布的各种任务。然而,正如我们在§8中所讨论的,改进的空间仍然存在。
Release

我们将发布SA-1B数据集用于研究目的,并在https://segment-anything.com上允许开放许可证(Apache 2.0)下提供SAM。我们还通过在线演示展示了SAM的功能。
这篇关于【43k字】双语理解Large Vision Model:Segment Anything的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





