本文主要是介绍【OpenPCDet】稀疏卷积SPConv-v1.2代码解读(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【3D卷积】
以下左图展示了一个2D卷积,使用一个3x3的卷积核,在单通道图像上进行卷积,其中Padding为1,得到输出。右图为一个单通道的3D卷积,与2D卷积不同之处在于,输入图像多了一个 depth 维度,卷积核也多了一个depth维度,之前2D卷积上3x3的卷积核现在变成了3x3x3。这里的3D不是通道导致的,而是深度(多层切片,多帧视频),因此,虽然输入和卷积核和输出都是3D的,但都可以是单通道的。
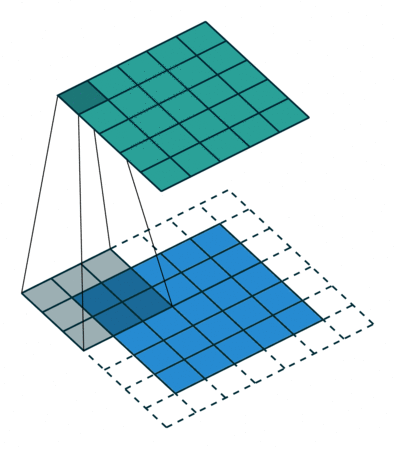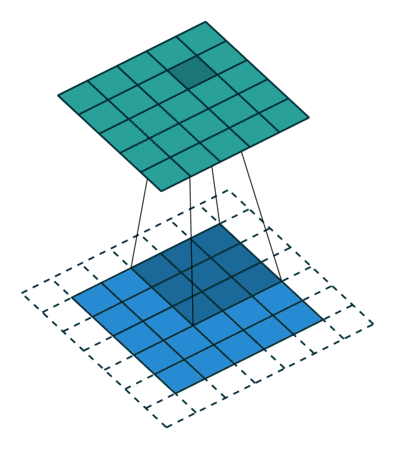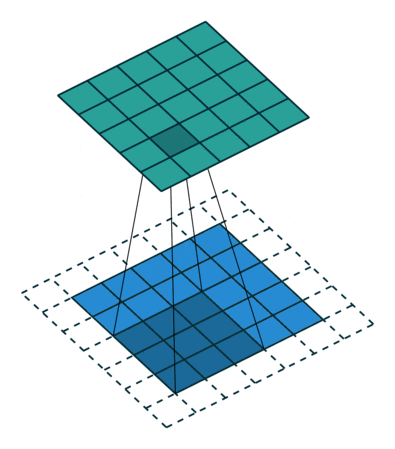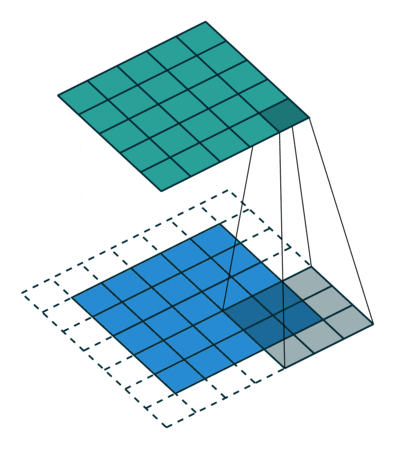

【3D稀疏卷积】
标准的3D卷积直接用于类似3D点云检测/分割等3D任务时,因为该类场景中输入特征的稀疏性,会带来严重的冗余计算量。所以,面对稀疏场景发展除了3D稀疏卷积。当然,2D也有稀疏卷积。

对于稀疏卷积有两种:
一种是Spatially Sparse Convolution ,在spconv中为SparseConv3d。就像普通的卷积一样,只要kernel 覆盖一个 active input site,就可以计算出output site。
另一种是Submanifold Sparse Convolution, 在spconv中为SubMConv3d。只有当kernel的中心覆盖一个 active input site时,卷积输出才会被计算。
【Second引入3D稀疏卷积】
Second论文中,作者在VoxleNet论文的基础上作了进一步的发展。考虑到VoxleNet模型中3D卷积运算量较大,速度不佳。作者引入了稀疏3D卷积来代替,在检测速度和内存使用方面都做了优化。作和开源了3D稀疏卷积的实现:GitHub - traveller59/spconv: Spatial Sparse Convolution Library。
截止目前已更新至spconv 2.x版本。我这里作代码解读仍然时基于早期的1.2版本,对于理解思想来说,问题不大。不得不佩服作者强大的代码工程能力!
【Second网络结构中的3D稀疏卷积】
分析OpenPCDet中Second的网络结构,3D稀疏卷积使用在3D骨干网模块:VoxelBackBone8x中。它接收MeanVFE模块的结果,经过精心设计好的3D稀疏卷积和3D稀疏子流卷积的有效组合,得到输出特征,并送入HeightCompression作深度方向的压缩,后面就是我们熟悉的2D检测网络的结构:2D骨干网络-->RPN-->分类/回归-->后处理。
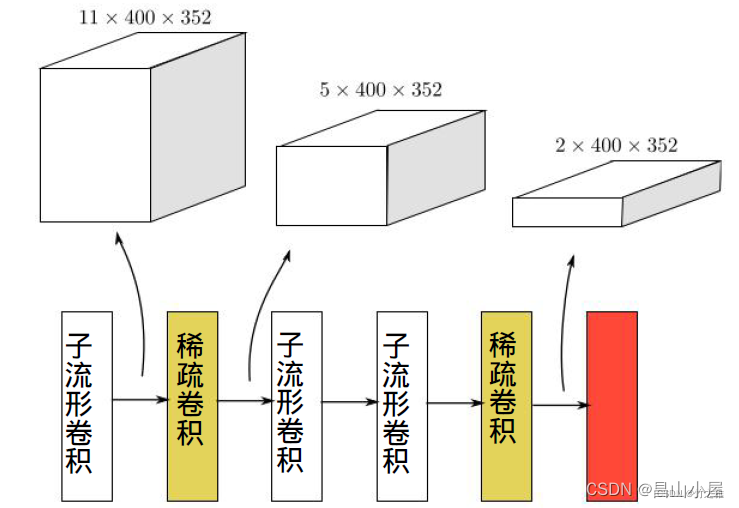
在Second原始论文中给出了BACKBONE_3D部分的示意图,但是这与OpenPCDet中Second具体的网络参数有所差异,注意区分。下图是Second中BACKBONE_3D部分的表示。
OpenPCDet中的Second我们可以参考具体的代码实现。
class VoxelBackBone8x(nn.Module):def __init__(self, model_cfg, input_channels, grid_size, **kwargs):super().__init__()self.model_cfg = model_cfgnorm_fn = partial(nn.BatchNorm1d, eps=1e-3, momentum=0.01)self.sparse_shape = grid_size[::-1] + [1, 0, 0] #e.g. array([ 41, 1600, 1408])self.conv_input = spconv.SparseSequential(spconv.SubMConv3d(input_channels, 16, 3, padding=1, bias=False, indice_key='subm1'),norm_fn(16),nn.ReLU(),)block = post_act_blockself.conv1 = spconv.SparseSequential(block(16, 16, 3, norm_fn=norm_fn, padding=1, indice_key='subm1'),)self.conv2 = spconv.SparseSequential(# [1600, 1408, 41] -> [800, 704, 21]block(16, 32, 3, norm_fn=norm_fn, stride=2, padding=1, indice_key='spconv2', conv_type='spconv'),block(32, 32, 3, norm_fn=norm_fn, padding=1, indice_key='subm2'),block(32, 32, 3, norm_fn=norm_fn, padding=1, indice_key='subm2'),)self.conv3 = spconv.SparseSequential(# [800, 704, 21] -> [400, 352, 11]block(32, 64, 3, norm_fn=norm_fn, stride=2, padding=1, indice_key='spconv3', conv_type='spconv'),block(64, 64, 3, norm_fn=norm_fn, padding=1, indice_key='subm3'),block(64, 64, 3, norm_fn=norm_fn, padding=1, indice_key='subm3'),)self.conv4 = spconv.SparseSequential(# [400, 352, 11] -> [200, 176, 5]block(64, 64, 3, norm_fn=norm_fn, stride=2, padding=(0, 1, 1), indice_key='spconv4', conv_type='spconv'),block(64, 64, 3, norm_fn=norm_fn, padding=1, indice_key='subm4'),block(64, 64, 3, norm_fn=norm_fn, padding=1, indice_key='subm4'),)last_pad = 0last_pad = self.model_cfg.get('last_pad', last_pad)self.conv_out = spconv.SparseSequential(# [200, 150, 5] -> [200, 150, 2]spconv.SparseConv3d(64, 128, (3, 1, 1), stride=(2, 1, 1), padding=last_pad,bias=False, indice_key='spconv_down2'),norm_fn(128),nn.ReLU(),)self.num_point_features = 128....def forward(self, batch_dict):"""Args:batch_dict:batch_size: intvfe_features: (num_voxels, C)voxel_coords: (num_voxels, 4), [batch_idx, z_idx, y_idx, x_idx]Returns:batch_dict:encoded_spconv_tensor: sparse tensor"""voxel_features, voxel_coords = batch_dict['voxel_features'], batch_dict['voxel_coords']pdb.set_trace()batch_size = batch_dict['batch_size']input_sp_tensor = spconv.SparseConvTensor(features=voxel_features, #e.g. torch.Size([16000, 4])indices=voxel_coords.int(), #e.g. torch.Size([16000, 4]) spatial_shape=self.sparse_shape, #e.g. array([41, 1600, 1408])batch_size=batch_size)x = self.conv_input(input_sp_tensor)x_conv1 = self.conv1(x)x_conv2 = self.conv2(x_conv1) #stride 2,downsamplex_conv3 = self.conv3(x_conv2) #stride 2,downsamplex_conv4 = self.conv4(x_conv3) #stride 2,downsample# for detection head# [200, 176, 5] -> [200, 176, 2]out = self.conv_out(x_conv4)....
对于VoxelBackbone8x模块的前向推理(forward)部分,其输入字典中最重要的内容为voxel_features和voxel_coords。他们分别表示有效的输入特征,以及这些有效特征的空间位置。voxel_features的size为(N,4),通常不同帧点云的有效特征的数量是不同的,N表示当前batch中总的有效输入特征的数量。可见,就VoxelBackBone8x模块来说,输入feature map其实是不固定的。具体到无论是3D标准稀疏卷积还是3D子流形卷积,其输入特征也是可变的。这会给我们做进一步做spconv的部署带来挑战。就我们常用的TensorRT推理引擎来说,它就要求输入特征是固定的。注意,这里说的固定跟TensorRT中的dynamic shape不是一回事。
【spconv模块】
在Second中spconv是作为Pytorch的一个自定义扩展模块在使用。对于一般的操作,我们扩展Pytorch模块很容易,只用使用Python来扩展即可。只需要继承torch.nn.Module并实现其__init__,forward等方法,求导的函数是不需要设置的,会自动按照求导规则求导师。像Second代码中的HeightCompression模块就是这样一个例子。这种扩展方式即插即用,不需要编译。
class HeightCompression(nn.Module):def __init__(self, model_cfg, **kwargs):super().__init__()self.model_cfg = model_cfgself.num_bev_features = self.model_cfg.NUM_BEV_FEATURESdef forward(self, batch_dict):"""Args:batch_dict:encoded_spconv_tensor: sparse tensorReturns:batch_dict:spatial_features:"""encoded_spconv_tensor = batch_dict['encoded_spconv_tensor']spatial_features = encoded_spconv_tensor.dense()N, C, D, H, W = spatial_features.shape #e.g. torch.Size([1, 128, 2, 200, 176])spatial_features = spatial_features.view(N, C * D, H, W)batch_dict['spatial_features'] = spatial_featuresbatch_dict['spatial_features_stride'] = batch_dict['encoded_spconv_tensor_stride']return batch_dict但是对于像对3D稀疏卷积这样复杂的操作进行优化,实现其扩展模块,单纯靠Pytorch已实现的operator的组合已经无法做到。正如spconv的实现,它采用C++和CUDA来扩展自定义模块。在 PyTorch 中直接扩展底层C++算子主要有三种方式,native_functions.yaml、C++ extension方式、OP register方式。spconv中使用了OP register这种方式。spconv代码主要分为python部分代码和c++/cuda部分代码两部分,对于其中重要内容后文我们做详细分析。
python部分目录
├── setup.py
├── spconv
│ ├── conv.py
│ ├── functional.py
│ ├── identity.py
│ ├── __init__.py
│ ├── modules.py
│ ├── ops.py
│ ├── pool.py
│ ├── tables.py
│ ├── test_utils.py
│ └── utils
│ ├── __init__.py
│ └── __pycache__
c++/cuda部分目录
├── include
│ ├── cuhash
│ ├── paramsgrid.h
│ ├── spconv
│ ├── tensorview
│ ├── torch_utils.h
│ └── utility
│ └── timer.h
├── src
│ ├── cuhash
│ ├── spconv
│ │ ├── all.cc
│ │ ├── CMakeLists.txt
│ │ ├── cublas_gemm.cc
│ │ ├── indice.cc
│ │ ├── indice.cu
│ │ ├── maxpool.cc
│ │ ├── maxpool.cu
│ │ ├── pillar_scatter.cu
│ │ ├── pool_ops.cc
│ │ ├── reordering.cc
│ │ ├── reordering.cu
│ │ └── spconv_ops.cc
│ └── utils
│ ├── all.cc
│ ├── CMakeLists.txt
└── third_party
【参考文献】
稀疏卷积 Sparse Convolution Net - 知乎
PyTorch扩展自定义PyThon/C++(CUDA)算子的若干方法总结 - 知乎
这可能是关于Pytorch底层算子扩展最详细的总结了! - 知乎
PyTorch算子底层源码解读--Op Registration - 知乎
通俗易懂的解释Sparse Convolution过程 - 知乎
Spconv代码解读 - 知乎
这篇关于【OpenPCDet】稀疏卷积SPConv-v1.2代码解读(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







