本文主要是介绍SAP COPA 获利能力分析深度解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、获利分析配置及相关值概述
二、配置:组织结构
2.1 定义经营范围-KEP8
2.2 维护经营关注点-KEA0
2.3 获利能力分析类型解析
2.4 控制范围分配给经营范围-KEKK
三、配置:数据结构-KEA0
3.1 特征字段
3.1.1 特征字段类别
3.1.2 维护特征字段-KEA5
3.1.3 分配特征字段到数据结构-KEA0
3.1.4 特征字段取值
3.2 值字段
3.2.1 值字段类别
3.2.2 维护值字段-KEA6
3.2.3 分配值字段到数据结构-KEA0
四、激活获利能力分析-KEKE
五、业务实践
5.1 特征字段和值字段的强制命名规则
5.2 特征字段如何规划
5.3 值字段如何规划
一、获利分析配置及相关值概述
获利分析模块(COPA)中主要的配置项包括两大类:
组织结构
数据结构
获利分析模块配置相关值主要指的是数据结构下的两种值类型:
特征字段(Characteristics Field)
值字段(Value Field)
二、配置:组织结构
SAP中每种业务模型都要基于一定的架构,这个架构就是组织结构。
如:FI模块的组织结构核心是公司代码,CO模块的组织结构核心是控制范围。
COPA模块的组织结构核心即经营范围(Operating Concern)。
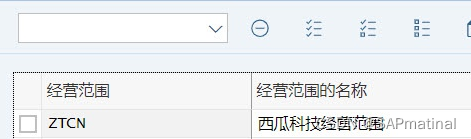
2.1 定义经营范围-KEP8
经营范围是指对组织盈利情况进行分析的范围。
相同的经营范围内,各组织使用相同的数据结构记录收入、成本、费用的数据,使用相同的方式获取和传送业务数据,采用同一套报表体系。
T-CODE: KEP8
或
路径:IMG->企业结构->定义->控制->创建经营组织
此T-CODE或路径只是定义经营范围的编码和描述。
点击“新条目”,维护如下信息
2.2 维护经营关注点-KEA0
T-CODE: KEA0
或
路径:IMG->控制->获利能力分析->结构->定义经营范围->维护经营关注点
此T-CODE或路径维护经营范围的详细信息。
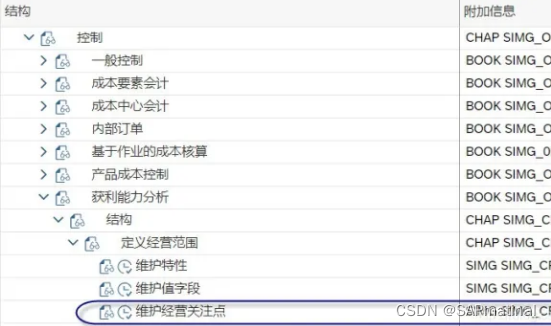
“数据结构”视图:设置经营范围的类型是基于成本核算的还是基于科目的、设置经营范围的数据结构。关于数据结构定义后文详细介绍。

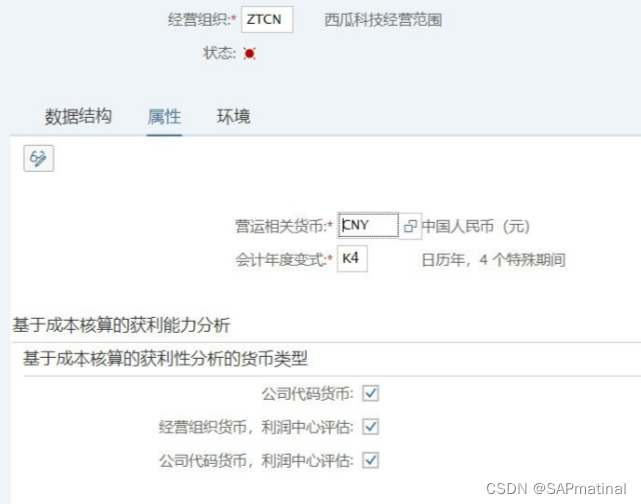
“属性”视图:定义了经营范围的货币和会计年度变式等。
“环境”视图:显示经营范围在当前client和跨client的设置状态是否正确。

通过光标选定客户往来部分和指定客户部分,然后F1,官方解释如下:
【客户往来部分】即cross-client part,跨client部分。经营范围在跨client的环境方面(程序、表结构、界面等)状态是否正确。
【指定客户部分】即client-specific part,特定client部分。经营范围在当前client的环境方面(经营范围的获利分析凭证编号范围、控制表里的数据等)是否正确。

【注意】上述两项都是绿灯才表示状态完全正确,该经营范围才可用。如果有一项不是绿灯,该经营范围就不可使用。
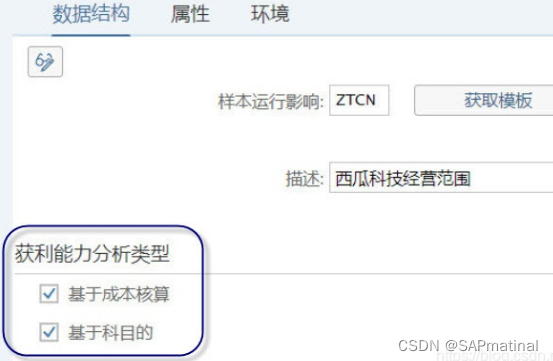
2.3 获利能力分析类型解析
T-CODE: KEA0 数据结构视图下的获利能力分析类型
2.4 控制范围分配给经营范围-KEKK
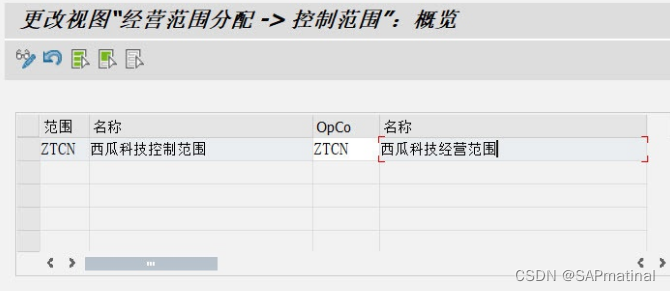
执行控制范围分配给经营范围的前提:经营范围的状态必须为绿色,即完全可用,否则会报错。

经营范围与控制范围是一对多的关系,即一个经营范围下可以有多个控制范围。
控制范围和公司代码是一对多的关系,即一个控制范围下可以有多个公司代码。
综上所述:经营范围和公司代码也是一对多的关系,即一个经营范围下可以有多个公司代码。
T-CODE: KEKK
或
路径:IMG->企业结构->分配->控制->把控制范围分配给经营范围
完成经营范围相关设置后,即经营范围完全可用状态时,重新分配
三、配置:数据结构-KEA0
获利分析的数据结构,包括特征字段和值字段。
配置路径同:“2.2 维护经营关注点-KEA0”
T-CODE: KEA0
或
路径:IMG->控制->获利能力分析->结构->定义经营范围->维护经营关注点

点击“创建”,初始状态如下:
特征字段
3.1 特征字段
以公司销售产品为例,公司代码、销售组织、销售渠道、产品、产品组、区域等作为获利分析的维度,每一个分析的值都是基于这些维度得出的。这些维度即称之为特征,而这些维度在系统中对应的字段即称之为特征字段。
获利能力段(profitability segment):特征字段的组合。
【注意】
获利能力段不是字段,而且多个特征字段的组合。
特征字段必须事先定义,然后才可以被分配到经营范围的数据结构中
3.1.2 维护特征字段-KEA5
根据业务实践,项目实施过程中,标准的特征字段基本无法满足实际需求,就需要通过自定义的方式增加特征字段。
如:销售的产品是哪个产品线,这个产品线就属于必须要自定义的特征字段。
【注意】自定义的特征,没有数据来源,而是用户根据分析的需要建立的特征。这类特征字段必须使用WW开头。
T-CODE: KEA5
或
路径:IMG->控制->获利能力分析->结构->定义经营范围->维护特性
点击“创建”
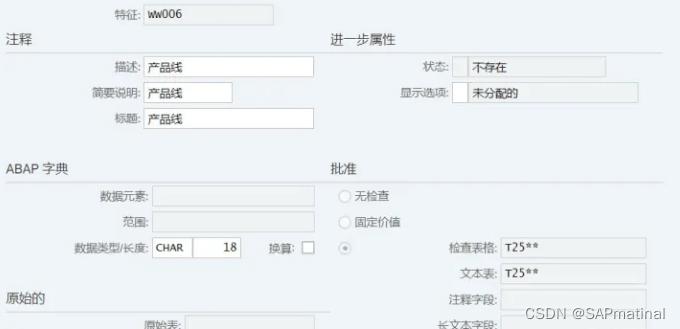
维护完成相关的信息,保存、激活
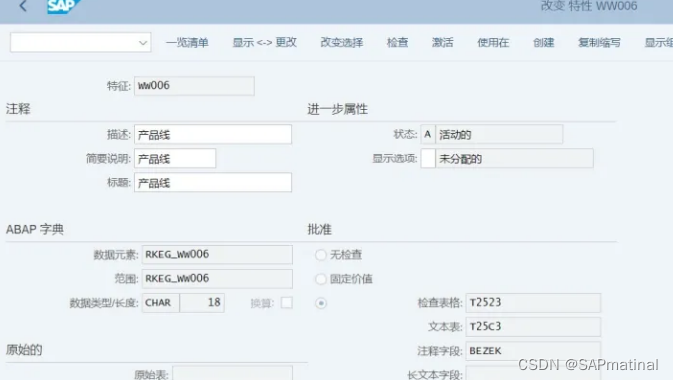
对比下 标准-预定义特征字段

根据官方文档解释:特征的原始表和原始字段信息表示该特征的初始值是从哪个表的哪个字段中提取的。
3.1.3 分配特征字段到数据结构-KEA0
根据实际业务需求,分配特征字段,包括:系统预定义、自定义特征字段等
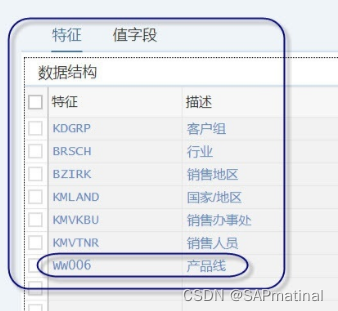
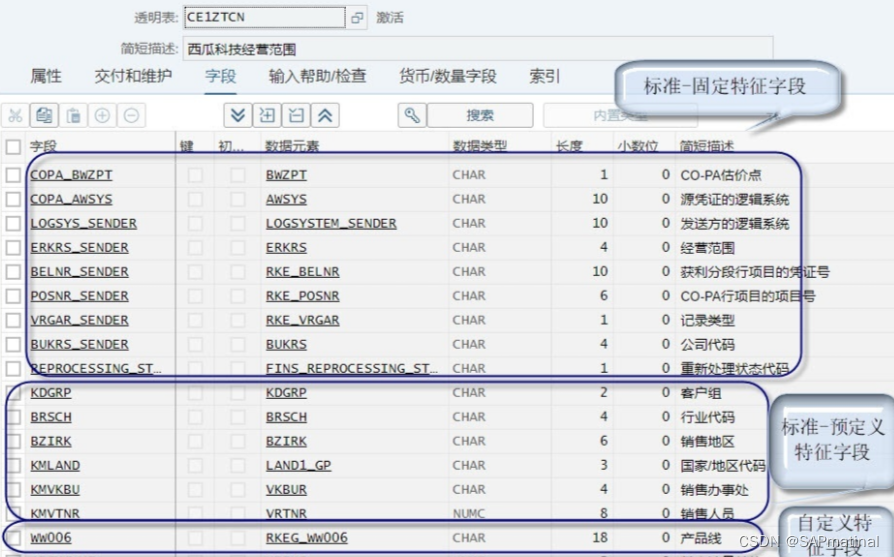
保存,激活
后台自动产生相关后台表,其中几张常用的表CE1XXXX~CE4XXXX(XXXX表示经营范围的代码)
CE1XXXX 实际行项目
CE2XXXX 计划行项目
CE3XXXX 部门盈利汇总记录
CE4XXXX 盈利能力组定义

3.1.4 特征字段取值
特征字段的值来源主要包括如下两个方面:
1、在实际业务中获利分析特征字段的取值,可以来自业务数据对应的原始数据,如销售订单客户的主数据中定义的客户组、销售地区、销售办公室等
2、依据一定的派生规则获得
关于派生规则的配置参考如下链接:
CO-PA: 获利能力分析之特征值派生 - KEDR / KEDB
3.2 值字段
以公司销售产品为例,销售数量、收入、成本等是获利分析的具体值的字段。这些字段即值字段。
值字段包括如下2种
金额字段(基于某种货币、某个产品、某个客户等)
数量字段(每一个数量字段都有自己的计量单位,否则将没有任何意义)
3.2.1 值字段类别
值字段类型比较简单,主要如下两个类别:
预定义了一些值字段,如销售数量、收入、运费等
用户根据自己需求自定义值字段。
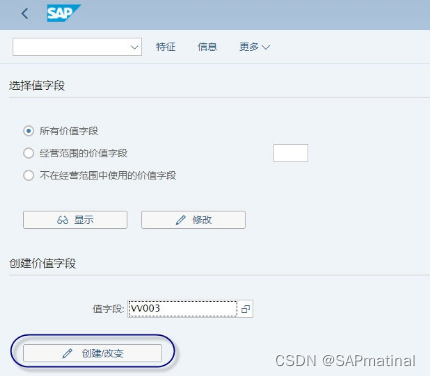
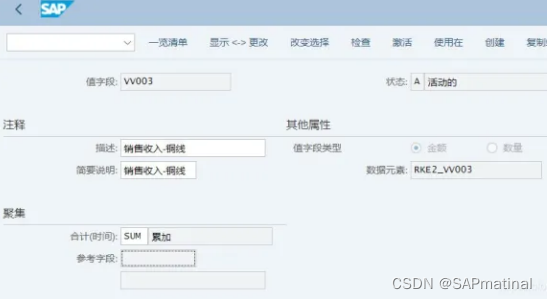
3.2.2 维护值字段-KEA6
根据业务实践,项目实施过程中,预定义的值字段无法满足实际需求,通过自定义的方式增加值字段。
如:某一个产品的销售收入等。
【注意】自定义的值字段,没有数据来源,而是用户根据分析的需要建立的值字段。这类值字段必须使用VV开头。
T-CODE: KEA6
或
路径:IMG->控制->获利能力分析->结构->定义经营范围->维护值字段
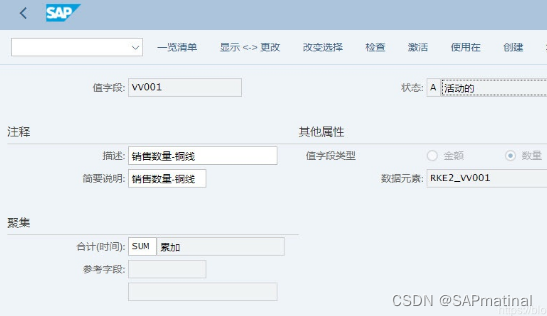
四、激活获利能力分析-KEKE
完成了COPA相关的配置之后,需要激活。

激活之前,查看经营范围分配的控制范围状态
T-CODE: OKKP
T-CODE: KEKE
或
IMG->控制->获利能力分析->实际值流水->激活获利能力分析
保存。
查看控制范围状态
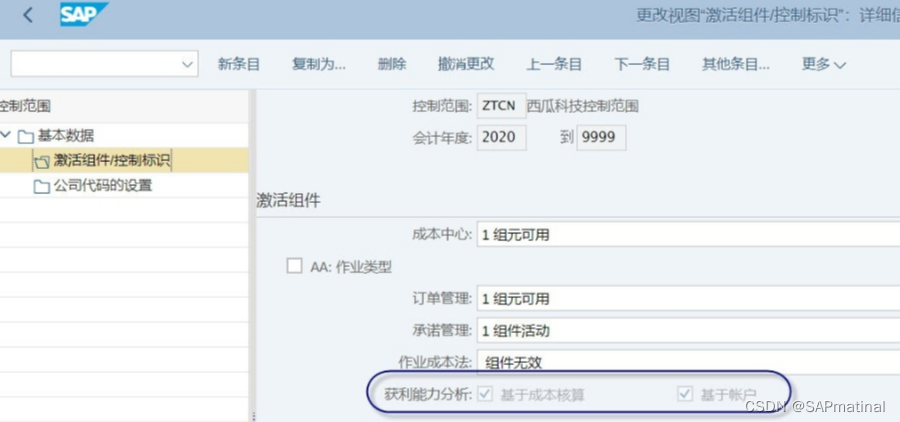
五、业务实践
根据业务实践,项目实施中,主要包括如下:
特征字段和值字段的强制命名规则
特征字段如何规划
值字段如何规划
5.1 特征字段和值字段的强制命名规则
根据SAP规则
自定义特征字段必须以WW开头,如:WW001
自定义的值字段必须以VV开头,如VV001
5.2 特征字段如何规划
【设计原则】设计特征字段时,事先要做好充分规划,最大可能的避免后续补充、更改或删除。
【系统运行规则】SAP中,激活经营范围,发生实际业务数据后,特征字段无法删除和缩短字段长度(可以增加长度),只可增加特征字段。对于有存量数据的情况下,增加特征字段,会衍生出另外一个问题,存量数量不会更新新增特征字段的值,可能导致出具的相关报表不准确。
【如何规则】
根据业务实践,采用分类逐步细分的方式,尽可能的考虑到更多的特征。
从如下几个角度:
企业端组织架构、销售端组织架构、销售干系人、客户 、产品、相关单据。
并将其细分
5.3 值字段如何规划
值字段的规划和特征字段一样,事先要做好充分规划,最大可能的避免后续补充、更改或删除。
一种项目实践:
大类:实际量、标准量
小类:数量、收入、成本、销售费用、管理费用、财务费用
细分:销售数量(实际)、销售成本-料/工/费(实际)、销售成本-料(标准)、销售收入(实际)等
这篇关于SAP COPA 获利能力分析深度解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





