本文主要是介绍Learn Flink:Data Pipelines ETL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Data Pipelines & ETL (数据管道和ETL)
One very common use case for Apache Flink is to implement ETL (extract, transform, load) pipelines that take data from one or more sources, perform some transformations and/or enrichments, and then store the results somewhere.
In this section we are going to look at how to use Flink’s DataStream API to implement this kind of application.
Apache Flink的一个非常常见的用例是实现ETL(提取、转换、加载)管道,该管道从一个或多个sources获取数据,执行一些转换和(或)丰富,然后将结果存储在某处。
在本节中,我们将了解如何使用Flink的DataStream API来实现这种应用程序
Note that Flink’s Table and SQL APIs are well suited for many ETL use cases.
But regardless of whether you ultimately use the DataStream API directly, or not, having a solid understanding the basics presented here will prove valuable.
注意,Flink的Table和SQL API非常适合许多ETL用例。
但是,无论您最终是否直接使用DataStream API,深入理解本文介绍的基础知识将证明是有价值的。
Stateless Transformations (无状态的转换)
This section covers map() and flatmap(), the basic operations used to implement stateless transformations.
The examples in this section assume you are familiar with the Taxi Ride data used in the hands-on exercises in the flink-training-repo .
本节介绍map()和flatmap(),这是用于实现无状态转换的基本操作。
本节中的示例假设您熟悉flink-training-repo的动手练习中使用的出租车乘坐数据。
map()
In the first exercise you filtered a stream of taxi ride events.
In that same code base there’s a GeoUtils class that provides a static method GeoUtils.mapToGridCell(float lon, float lat) which maps a location (longitude, latitude) to a grid cell that refers to an area that is approximately 100x100 meters in size.
在第一个练习中,您过滤了一系列出租车乘坐事件。
在同一个代码库中,有一个GeoUtils类,它提供了一个静态方法GeoUtils.mapToGridCell(float lon, float lat),将位置(经度、纬度)映射到网格单元,网格单元指的是尺寸约为100x100米的区域。
Now let’s enrich our stream of taxi ride objects by adding startCell and endCell fields to each event.
You can create an EnrichedRide object that extends TaxiRide, adding these fields:
现在,让我们通过向每个事件添加startCell和endCell字段来丰富出租车乘坐对象流。
您可以创建一个继承TaxiRide的EnrichedRide对象,添加以下字段:
public static class EnrichedRide extends TaxiRide {public int startCell;public int endCell;public EnrichedRide() {}public EnrichedRide(TaxiRide ride) {this.rideId = ride.rideId;this.isStart = ride.isStart;...this.startCell = GeoUtils.mapToGridCell(ride.startLon, ride.startLat);this.endCell = GeoUtils.mapToGridCell(ride.endLon, ride.endLat);}public String toString() {return super.toString() + "," +Integer.toString(this.startCell) + "," +Integer.toString(this.endCell);}
}
You can then create an application that transforms the stream
然后,您可以创建一个应用程序来转换流
DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...));DataStream<EnrichedRide> enrichedNYCRides = rides.filter(new RideCleansingSolution.NYCFilter()).map(new Enrichment());enrichedNYCRides.print();
with this MapFunction:
用如下的MapFunction
public static class Enrichment implements MapFunction<TaxiRide, EnrichedRide> {@Overridepublic EnrichedRide map(TaxiRide taxiRide) throws Exception {return new EnrichedRide(taxiRide);}
}
flatmap()
A MapFunction is suitable only when performing a one-to-one transformation: for each and every stream element coming in, map() will emit one transformed element. Otherwise, you will want to use flatmap()
MapFunction仅在执行一对一转换时适用:对于传入的每个流元素,map()将产出一个经过转换后的元素。否则,您将希望使用flatmap()。
DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...));DataStream<EnrichedRide> enrichedNYCRides = rides.flatMap(new NYCEnrichment());enrichedNYCRides.print();
together with a FlatMapFunction:
与FlatMapFunction一起使用
public static class NYCEnrichment implements FlatMapFunction<TaxiRide, EnrichedRide> {@Overridepublic void flatMap(TaxiRide taxiRide, Collector<EnrichedRide> out) throws Exception {FilterFunction<TaxiRide> valid = new RideCleansing.NYCFilter();if (valid.filter(taxiRide)) {out.collect(new EnrichedRide(taxiRide));}}
}
With the Collector provided in this interface, the flatmap() method can emit as many stream elements as you like, including none at all.
通过该接口中提供的收集器(Collector),flatmap()方法可以产出任意多个(也包括0个)流元素。
Keyed Streams (按key分组的流)
keyBy()
It is often very useful to be able to partition a stream around one of its attributes, so that all events with the same value of that attribute are grouped together.
For example, suppose you wanted to find the longest taxi rides starting in each of the grid cells.
Thinking in terms of a SQL query, this would mean doing some sort of GROUP BY with the startCell, while in Flink this is done with keyBy(KeySelector)
能够围绕流的一个属性对流进行分组通常是非常有用的,可以将具有该属性且属性值相同的所有事件分组在一起。
例如,假设您想在每个网格单元中找到最大的出租车行程。
从SQL查询的角度来看,这意味着使用startCell进行某种分组排序,而在Flink中,这是使用keyBy(KeySelector)完成的。
rides.flatMap(new NYCEnrichment()).keyBy(enrichedRide -> enrichedRide.startCell);
Every keyBy causes a network shuffle that repartitions the stream.
In general this is pretty expensive, since it involves network communication along with serialization and deserialization.
每个keyBy都会导致网络shuffle,从而对流重新分区。一般来说,这相当昂贵,因为它涉及网络通信以及序列化和反序列化。

Keys are computed (keys可以被计算)
KeySelectors aren’t limited to extracting a key from your events.
They can, instead, compute the key in whatever way you want, so long as the resulting key is deterministic, and has valid implementations of hashCode() and equals().
This restriction rules out KeySelectors that generate random numbers, or that return Arrays or Enums, but you can have composite keys using Tuples or POJOs, for example, so long as their elements follow these same rules.
KeySelectors不限于从事件中提取key。
只要生成的key是确定性的,并且具有hashCode()和equals()的有效实现,你就可以以任何方式计算key。
这样就排除了生成随机数或返回数组(或枚举)的KeySelectors,但是你可以使用例如元组或POJO来获得复合键。
The keys must be produced in a deterministic way, because they are recomputed whenever they are needed, rather than being attached to the stream records.
key必须以确定的方式生成,因为在需要时它们会被重新计算,而不是附加到流记录上。
For example, rather than creating a new EnrichedRide class with a startCell field that we then use as a key via
例如,不使用startCell字段作为key。
keyBy(enrichedRide -> enrichedRide.startCell);
we could do this, instead:
而是这样做:
keyBy(ride -> GeoUtils.mapToGridCell(ride.startLon, ride.startLat));
Aggregations on Keyed Streams (在按key分组的流上进行聚合)
This bit of code creates a new stream of tuples containing the startCell and duration (in minutes) for each end-of-ride event:
这段代码创建了一个新的元组流,元祖中包含每个骑行结束事件的起始单元格和持续时间(以分钟为单位):
import org.joda.time.Interval;DataStream<Tuple2<Integer, Minutes>> minutesByStartCell = enrichedNYCRides.flatMap(new FlatMapFunction<EnrichedRide, Tuple2<Integer, Minutes>>() {@Overridepublic void flatMap(EnrichedRide ride,Collector<Tuple2<Integer, Minutes>> out) throws Exception {if (!ride.isStart) {Interval rideInterval = new Interval(ride.startTime, ride.endTime);Minutes duration = rideInterval.toDuration().toStandardMinutes();out.collect(new Tuple2<>(ride.startCell, duration));}}});
Now it is possible to produce a stream that contains only those rides that are the longest rides ever seen (to that point) for each startCell.
现在,可以生成一个流,该流仅包含每个startCell(到目前为止)内的最长骑行。
There are a variety of ways that the field to use as the key can be expressed.
Earlier you saw an example with an EnrichedRide POJO, where the field to use as the key was specified with its name.
This case involves Tuple2 objects, and the index within the tuple (starting from 0) is used to specify the key.
用作key的字段可以有多种方式来表示。
前面您看到了一个EnrichedRide POJO示例,其中用作key的字段是用其名称指定的。
这种情况涉及Tuple2对象,并且元组内的索引(从0开始)用于指定key。
minutesByStartCell.keyBy(value -> value.f0) // .keyBy(value -> value.startCell).maxBy(1) // duration.print();
The output stream now contains a record for each key every time the duration reaches a new maximum – as shown here with cell 50797:
现在,每次duration有新的最大值生成时,输出流都会对应生成该key的一条新记录,如单元格50797所示:
...
4> (64549,5M)
4> (46298,18M)
1> (51549,14M)
1> (53043,13M)
1> (56031,22M)
1> (50797,6M)
...
1> (50797,8M)
...
1> (50797,11M)
...
1> (50797,12M)
(Implicit) State (隐式的)状态
This is the first example in this training that involves stateful streaming.
Though the state is being handled transparently, Flink has to keep track of the maximum duration for each distinct key.
这是本培训中第一个涉及状态流的示例。
虽然状态是透明处理的,但Flink必须跟踪每个不同key的最大持续时间。
Whenever state gets involved in your application, you should think about how large the state might become.
Whenever the key space is unbounded, then so is the amount of state Flink will need.
每当应用程序中涉及到状态时,您都应该考虑该状态可能会变得多大。
只要key空间是无界的,那么Flink所需状态的空间也是无界的。
When working with streams, it generally makes more sense to think in terms of aggregations over finite windows, rather than over the entire stream.
在处理流时,通常更明智的做法是考虑有限窗口内数据的聚合,而不是整个流。
reduce() and other aggregators reduce()和其他的聚合
maxBy(), used above, is just one example of a number of aggregator functions available on Flink’s KeyedStreams.
There is also a more general purpose reduce() function that you can use to implement your own custom aggregations.
上面使用的maxBy()只是Flink的KeyedStreams上可用的许多聚合函数的一个示例。
还有一个更通用的reduce()函数,可以用来实现用户自定义的聚合。
Stateful Transformations (有状态的转换)
Why is Flink Involved in Managing State? (Flink为什么要参与管理状态?)
Your applications are certainly capable of using state without getting Flink involved in managing it – but Flink offers some compelling features for the state it manages:
您的应用程序当然能够使用状态,而不需要Flink参与管理,但Flink为其管理的状态提供了一些引人注目的特性:
- local: Flink state is kept local to the machine that processes it, and can be accessed at memory speed
本地的:Flink状态存储在处理它的机器的本地,并且可以以内存速度访问。 - durable: Flink state is fault-tolerant, i.e., it is automatically checkpointed at regular intervals, and is restored upon failure
持久的:Flink状态是容错的,即定期自动检查,并在故障时恢复。 - vertically scalable: Flink state can be kept in embedded RocksDB instances that scale by adding more local disk
垂直可扩展的:Flink状态可以保留在嵌入式RocksDB实例中,可以通过添加更多本地磁盘进行扩展。 - horizontally scalable: Flink state is redistributed as your cluster grows and shrinks
水平可扩展的:Flink状态随着集群的增长和收缩而重新分布。 - queryable: Flink state can be queried externally via the Queryable State API.
可查询的:可以通过Queryable State API从外部查询Flink状态。
In this section you will learn how to work with Flink’s APIs that manage keyed state.
在本节中,您将学习如何使用Flink的API来管理按key分组的状态(keyed state)。
Rich Functions
At this point you have already seen several of Flink’s function interfaces, including FilterFunction, MapFunction, and FlatMapFunction. These are all examples of the Single Abstract Method pattern.
此时,您已经看到了Flink的几个函数接口,包括FilterFunction、MapFunction和FlatMapFunction。
这些都是单一抽象方法模式的示例。
For each of these interfaces, Flink also provides a so-called “rich” variant, e.g., RichFlatMapFunction, which has some additional methods, including:
对于这些接口中的每一个,Flink还提供了一个所谓的“rich”变体,例如RichFlatMapFunction,它有一些额外的方法,包括:
- open(Configuration c)
- close()
- getRuntimeContext()
open() is called once, during operator initialization.
This is an opportunity to load some static data, or to open a connection to an external service, for example.
open()在operator初始化期间调用一次。
一般情况,可以在open()方法中加载一些静态数据或连接外部服务。
getRuntimeContext() provides access to a whole suite of potentially interesting things, but most notably it is how you can create and access state managed by Flink.
getRuntimeContext()提供了对一整套潜在有趣内容的访问,但最值得注意的是:你应该如何用getRuntimeContext()创建和访问由Flink管理的状态。
An Example with Keyed State(Keyed State的一个例子)
In this example, imagine you have a stream of events that you want to de-duplicate, so that you only keep the first event with each key. Here’s an application that does that, using a RichFlatMapFunction called Deduplicator:
在本例中,假设您有一个要消除重复的事件流,因此每个key只保留第一个事件。
下面是一个这样做的应用程序,使用名为Deduplicator的RichFlatMapFunction:
private static class Event {public final String key;public final long timestamp;...
}public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.addSource(new EventSource()).keyBy(e -> e.key).flatMap(new Deduplicator()).print();env.execute();
}
To accomplish this, Deduplicator will need to somehow remember, for each key, whether or not there has already been an event for that key. It will do so using Flink’s keyed state interface.
为了实现这一点,Deduplicator需要以某种方式记住,对于每个键,该key是否有已经存在的事件(event)。
它将使用Flink的keyed state接口来实现。
When you are working with a keyed stream like this one, Flink will maintain a key/value store for each item of state being managed.
当您处理像这样的按key分组的流时,Flink将为所管理的每个状态项维护一个key/value存储。
Flink supports several different types of keyed state, and this example uses the simplest one, namely ValueState.
This means that for each key, Flink will store a single object – in this case, an object of type Boolean.
Flink支持几种不同类型的按key分组状态,本例使用最简单的按key分组状态,即ValueState。
这意味着对于每个key,Flink将存储单个对象——在本例中,是布尔类型的对象。
Our Deduplicator class has two methods: open() and flatMap().
The open method establishes the use of managed state by defining a ValueStateDescriptor.
The arguments to the constructor specify a name for this item of keyed state (“keyHasBeenSeen”), and provide information that can be used to serialize these objects (in this case, Types.BOOLEAN).
我们的Deduplicator有两个方法:open()和flatMap()。
open方法通过定义ValueStateDescriptor来建立托管状态的使用。
其构造函数的参数指定按key分组状态的名称(“keyHasBeenSeen”),并提供可用于序列化这些对象的信息(在本例中为Types.BOOLEAN)。
public static class Deduplicator extends RichFlatMapFunction<Event, Event> {ValueState<Boolean> keyHasBeenSeen;@Overridepublic void open(Configuration conf) {ValueStateDescriptor<Boolean> desc = new ValueStateDescriptor<>("keyHasBeenSeen", Types.BOOLEAN);keyHasBeenSeen = getRuntimeContext().getState(desc);}@Overridepublic void flatMap(Event event, Collector<Event> out) throws Exception {if (keyHasBeenSeen.value() == null) {out.collect(event);keyHasBeenSeen.update(true);}}
}
When the flatMap method calls keyHasBeenSeen.value(), Flink’s runtime looks up the value of this piece of state for the key in context, and only if it is null does it go ahead and collect the event to the output. It also updates keyHasBeenSeen to true in this case.
当flatMap方法调用keyHasBeenSeen.value()时,Flink的runtime在上下文中查找key在这段状态的值,只有当它为null时,它才会继续并将事件收集到输出。
在本例中,它还将keyHasBeenSeen更新为true。
This mechanism for accessing and updating key-partitioned state may seem rather magical, since the key is not explicitly visible in the implementation of our Deduplicator.
When Flink’s runtime calls the open method of our RichFlatMapFunction, there is no event, and thus no key in context at that moment.
But when it calls the flatMap method, the key for the event being processed is available to the runtime, and is used behind the scenes to determine which entry in Flink’s state backend is being operated on.
这种访问和更新按key分组状态的机制可能看起来相当神奇,因为key在我们的Deduplicator的实现中并不明确可见。
当Flink的runtime调用RichFlatMapFunction的open方法时,没有事件,因此在当时的上下文中没有key。
但是,当它调用flatMap方法时,runtime可以使用正在处理的事件的key,并在后台使用该key来确定正在对Flink的状态后端中的哪个条目(entry)进行操作。
When deployed to a distributed cluster, there will be many instances of this Deduplicator, each of which will responsible for a disjoint subset of the entire keyspace. Thus, when you see a single item of ValueState, such as
当部署到分布式集群时,该Deduplicator将有许多实例,每个实例将负责整个key空间的不相交子集。
因此,当您看到ValueState的单个项时,例如:
ValueState<Boolean> keyHasBeenSeen;
understand that this represents not just a single Boolean, but rather a distributed, sharded, key/value store.
请理解,这不仅仅代表一个布尔值,而是一个分布式、分片的key/value存储。
Clearing State 清空状态
There’s a potential problem with the example above: What will happen if the key space is unbounded? Flink is storing somewhere an instance of Boolean for every distinct key that is used.
If there’s a bounded set of keys then this will be fine, but in applications where the set of keys is growing in an unbounded way, it’s necessary to clear the state for keys that are no longer needed.
This is done by calling clear() on the state object, as in:
上面的例子有一个潜在的问题:如果key空间是无界的,会发生什么?Flink正在为使用的每个不同key存储布尔实例。
如果key的集合是有界的将会很好,但在应用程序中key的集合以无界的趋势增长时,有必要清除那些不再被需要的key的状态。
这是通过对状态对象调用clear()来实现的,例如:
keyHasBeenSeen.clear();
You might want to do this, for example, after a period of inactivity for a given key.
You’ll see how to use Timers to do this when you learn about ProcessFunctions in the section on event-driven applications.
例如,您可能希望在给定key处于非活跃状态一段时间后执行此操作。
当你在event-driven applications一节中学习ProcessFunctions时,您将会看到如何使用定时器(Timer)来实现这一点。
There’s also a State Time-to-Live (TTL) option that you can configure with the state descriptor that specifies when you want the state for stale keys to be automatically cleared.
还有一个状态生存时间(TTL)选项,你可以使用状态描述器(state descriptor)来配置它,该描述器可以用来指定那些过时key的状态将会在何时被自动清除。
Non-keyed State (未按key分组的状态)
It is also possible to work with managed state in non-keyed contexts.
This is sometimes called operator state.
The interfaces involved are somewhat different, and since it is unusual for user-defined functions to need non-keyed state, it is not covered here.
This feature is most often used in the implementation of sources and sinks.
也可以在未按key分组的context中使用托管状态。
这有时被称为operator状态。
所涉及的接口有些不同,由于用户自定义的函数需要使用到未按key分组的状态的情况不常见,因此这里不作介绍。
此功能最常用于source和sink的实现。
Connected Streams (有关联的流)
Sometimes instead of applying a pre-defined transformation like this:
有时可能会用到像这样的预定义转换:

you want to be able to dynamically alter some aspects of the transformation – by streaming in thresholds, or rules, or other parameters. The pattern in Flink that supports this is something called connected streams, wherein a single operator has two input streams, like this:
您希望能够动态地改变转换的某些方面——通过输入阈值、规则或其他参数。
Flink中支持这一点的模式称为有关联的流(connected stream),其中一个operator有两个输入流,如下所示:
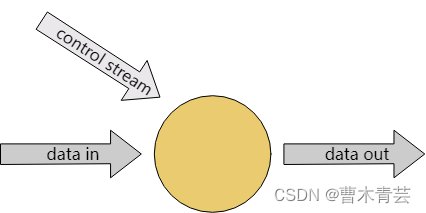
Connected streams can also be used to implement streaming joins.
有关联的流也可用于实现流式join。
Example (案例)
In this example, a control stream is used to specify words which must be filtered out of the streamOfWords.
A RichCoFlatMapFunction called ControlFunction is applied to the connected streams to get this done.
在本例中,control流用于指定需要从streamOfWords中过滤出来哪些单词。
一个名为ControlFunction的RichCoFlatMapFunction被应用于有关联的流以实现这一点。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> control = env.fromElements("DROP", "IGNORE").keyBy(x -> x);DataStream<String> streamOfWords = env.fromElements("Apache", "DROP", "Flink", "IGNORE").keyBy(x -> x);control.connect(streamOfWords).flatMap(new ControlFunction()).print();env.execute();
}
Note that the two streams being connected must be keyed in compatible ways.
The role of a keyBy is to partition a stream’s data, and when keyed streams are connected, they must be partitioned in the same way.
This ensures that all of the events from both streams with the same key are sent to the same instance.
This makes it possible, then, to join the two streams on that key, for example.
注意,被关联的两个流必须以兼容的方式按key分组。
keyBy的作用是对流的数据进行分组,当连接按key分组的流时,它们必须以相同的方式进行分组。
这确保了具有相同key的所有事件都被发送到同一实例中(事件来自两个流)。
这使得在该key上join这两个流成为可能。
In this case the streams are both of type DataStream, and both streams are keyed by the string.
As you will see below, this RichCoFlatMapFunction is storing a Boolean value in keyed state, and this Boolean is shared by the two streams.
这个案例中,两个流都是DataStream类型,并且都以字符串类型按key分组。
正如你将在下面看到的,这个RichCoFlatMapFunction在按key分组的状态中存储一个布尔值,这个布尔值由两个流共享。
public static class ControlFunction extends RichCoFlatMapFunction<String, String, String> {private ValueState<Boolean> blocked;@Overridepublic void open(Configuration config) {blocked = getRuntimeContext().getState(new ValueStateDescriptor<>("blocked", Boolean.class));}@Overridepublic void flatMap1(String control_value, Collector<String> out) throws Exception {blocked.update(Boolean.TRUE);}@Overridepublic void flatMap2(String data_value, Collector<String> out) throws Exception {if (blocked.value() == null) {out.collect(data_value);}}
}
A RichCoFlatMapFunction is a kind of FlatMapFunction that can be applied to a pair of connected streams, and it has access to the rich function interface. This means that it can be made stateful.
RichCoFlatMapFunction是一种可以应用于一对有关联的流的FlatMapFunction,它可以访问rich function的接口。
这意味着它可以成为有状态的。
The blocked Boolean is being used to remember the keys (words, in this case) that have been mentioned on the control stream, and those words are being filtered out of the streamOfWords stream.
This is keyed state, and it is shared between the two streams, which is why the two streams have to share the same keyspace.
布尔值blocked被用于记录control流中出现的key(在本例中为单词),这些单词将从streamOfWords流中过滤出来。
blocked是按key分组的状态,并在两个流之间共享,这就是为什么两个流必须共享相同的key空间。
flatMap1 and flatMap2 are called by the Flink runtime with elements from each of the two connected streams – in our case, elements from the control stream are passed into flatMap1, and elements from streamOfWords are passed into flatMap2. This was determined by the order in which the two streams are connected with control.connect(streamOfWords).
Flink runtime使用两个流的元素分别调用flatMap1和flatMap2––––在我们的示例中,来自control流的元素被传递到flatMap1,来自StreamOfWord的元素被传递到flatMap2。这取决于两个流在代码’'control.connect(streamOfWords)"中的位置。
It is important to recognize that you have no control over the order in which the flatMap1 and flatMap2 callbacks are called.
These two input streams are racing against each other, and the Flink runtime will do what it wants to regarding consuming events from one stream or the other.
In cases where timing and/or ordering matter, you may find it necessary to buffer events in managed Flink state until your application is ready to process them.
Note: if you are truly desperate, it is possible to exert some limited control over the order in which a two-input operator consumes its inputs by using a custom Operator that implements the InputSelectable interface.
必须认识到,您无法控制flatMap1和flatMap2的callback被调用的顺序。
这两个输入流相互竞争,Flink runtime将根据自身需要去处理来自一个流或另一个流的事件。
在计时和(或)排序很重要的情况下,您可能会发现有必要将事件缓存在Flink托管的状态中,直到您的应用程序准备好处理它们。
注意:如果您真的非常绝望,也可以通过使用实现InputSelectable接口的自定义operator对接收两个输入流的operator处理其输入的顺序施加一些有限的控制。
Hands-on
The hands-on exercise that goes with this section is the Rides and Fares .
本节的实践练习是:Rides and Fares。
这篇关于Learn Flink:Data Pipelines ETL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




