本文主要是介绍时间序列数据挖掘模板:墨尔本10年气候变化(含代码和数据集),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1项目描述
最近跟着同济自豪兄的b站视频学习机器学习,数据挖掘的相关知识。其中有一个视频是关于时间序列数据挖掘模板的项目,也是比较经典的数据挖掘的例子。
在观看视频的同时,我也跟着复现了一遍,并且添加了自己的注释。
在这里给出了数据集:
链接:https://pan.baidu.com/s/1huu9_JIPCb2OnxolM5er1Q
提取码:c75k
2.代码介绍
在这里简单介绍一下代码,主要分为以下几个部分:导入数据集进行多种类型图像的绘制,然后进行数据处理,再利用机器学习模型来拟合最后进行评价。
2.1导入数据以及绘制图形
绘制了折线图,散点图,直方图,面积堆积图,核密度估计函数,热力图,箱型图,小提琴图等美观的图形来描述数据集。
2.2 数据集的特征工程
首先进行时间的特征工程,目的是为了让编程语言能够读懂我们的时间信息,再对其他变量进行one-hot编码。
2.3 机器学习模型的建立
分别利用了以下机器学习模型:
多元线性回归:多项式回归(二次,三次)
岭回归
决策树和随机森林
多层神经网络
2.4结果评价
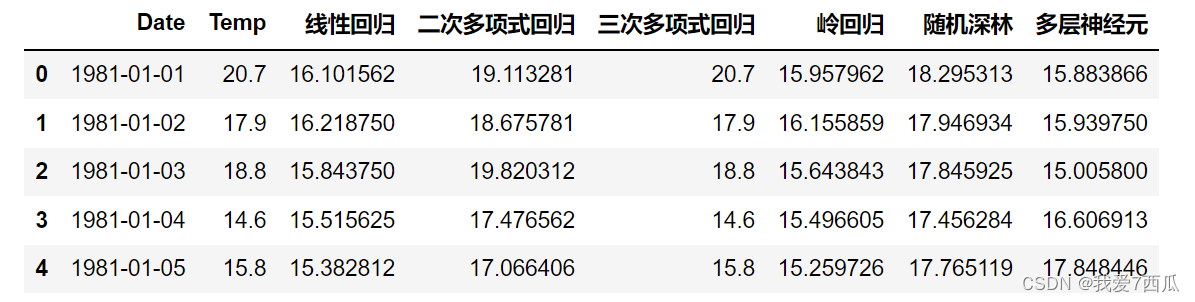
这里面给出了我复现的代码:
链接:https://pan.baidu.com/s/1hgddoaB69uqJRcN22T5lqQ
提取码:v3q0
这篇关于时间序列数据挖掘模板:墨尔本10年气候变化(含代码和数据集)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





