本文主要是介绍抓取了Gabbana 最近的 Instagram 推文:号真被盗了吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
微信又改版了,为了方便第一时间看到我们的推送,请按照下列操作,设置“置顶”:点击上方蓝色字体“程序员之家”-点击右上角“…”-点击“设为星标”。
可以啦,让我们继续相互陪伴。
一条宣传视频,一位小眼睛的亚裔模特,企图用筷子品尝一根甜卷,旁白这样解释,“这会让你感觉自己身在意大利,不过,你是在中国!”

视频引起很多中国网友不适,随后杜嘉班纳官方微博删除了该视频,但作为杜嘉班纳营销主战场的Instagram,却没有删除。
创始人兼设计师Gabbana与网友私信互怼,表示“那段视频被从中国社交媒体上删除了,那是因为我公司的那确认太傻了”“从现在开始,我会在所有的国际采访中都说中国是Shi”“中国,无知、肮脏,跟土匪一样”……
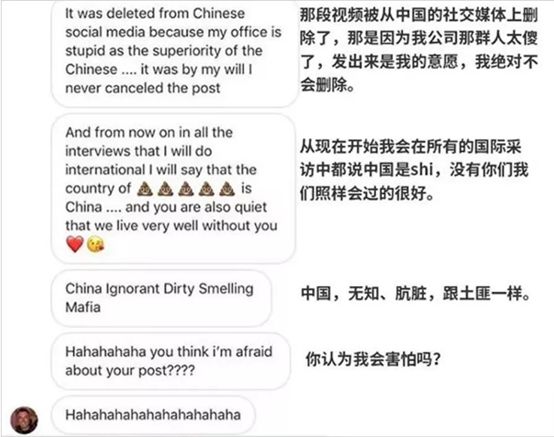
这段话一经曝光,瞬时引起中国网友不满,甚至随着事态发酵,本来计划出席走秀的一众中国明星,纷纷发微博表示,将拒绝参加杜嘉班纳走秀。
而作为杜嘉班纳亚太地区的代言人——王俊凯和迪丽热巴也表示,解除同杜嘉班纳的合同。
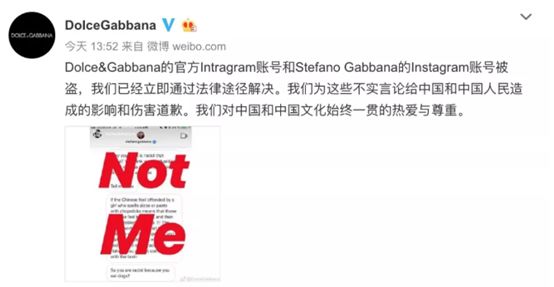
后来,杜嘉班纳表示,官方和创始人Gabbana这么说,其实是被盗号了。
关于此事的评论已经铺天盖地。不过我想来谈个细节:事件最初曝光时,当事人 Stefano Gabbana 辩解说自己是被盗号了。虽然这个理由在现在看来是非常敷衍,但我当时确实想了下,是否有这样的可能性存在呢?联想到之前在《纽约时报》上爆料特朗普的匿名匿名文章,有程序员将文章中的内容和特朗普内阁成员的 Twitter 内容进行相关性分析并发布在 Github 上。那有没有可能将此段对话与 Gabbana 日常言论作对比,分析其相关性呢?
于是我先后尝试了 3 种相关性比较方法。但很遗憾,结果不能说不好,只能说……emmmm……这是一门玄学。因为现有的文本相关度或相似性分析大都是基于语义的。也就是说,A 和 B 表达同一件事的相似度,很可能大于 A 本人表达两件不同的事情。以至于我觉得,关于纽约时报匿名文章的分析也可能存在类似情况:副总统的相关性最高,或许主要是因为其平常言论涉及的话题和文章更接近。而在这件事上,借以判断到底是不是一个人,就不太靠谱了。再加上 Gabbana 之前的发布和此番对话都很短,样本量非常小,几乎没有可参考性。
不过我后来去他的 Instagram 上翻了一下,依然发现一些蛛丝马迹,值得分析一波:
1. 单引号
有一个汉语中没有但英语中很常见符号:'(单引号),比如 I'm Crossin. 但 Gabbana 在 ig 上的发文中,其实用的不是最常见的英文半角单引号,而是一个 unicode 字符 ’。一般人可能不注意,但我对这个再熟悉不过了,因为有无数的 Python 初学者在最开始的代码中就因为没有用英文半角引号而报错!
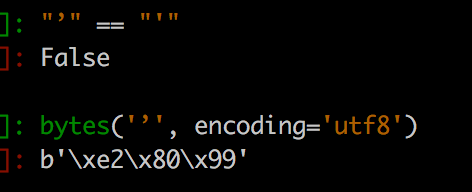
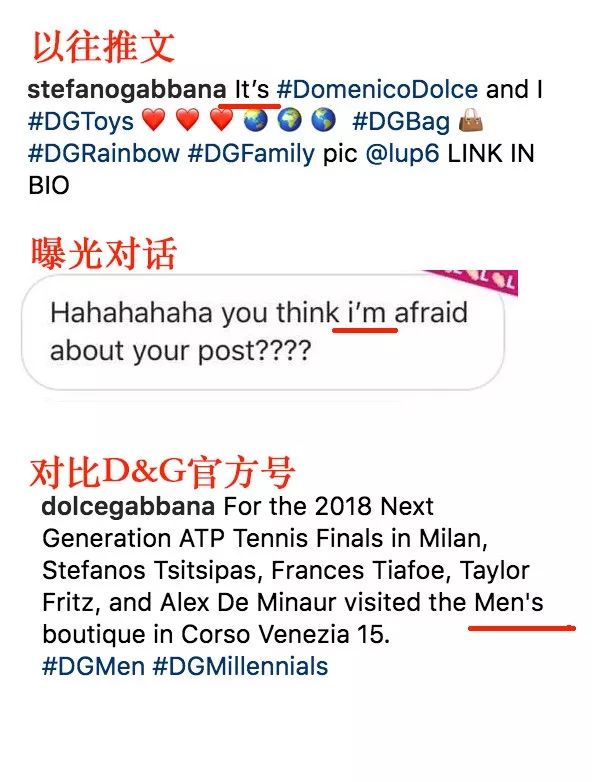
但巧的是,曝光出的对话里,用的也是这个特殊的单引号。而声称同时被盗号的 D&G 官方账号就没有这个习惯。
2. 标点习惯
我抓下了 Gabbana 最近的 30 条 ig 推文,发现他发文喜欢使用连续的 3~4 个感叹号,30 条中有 8 处。而在曝光对话中,也有4 次连续感叹号和 4 次连续问号。
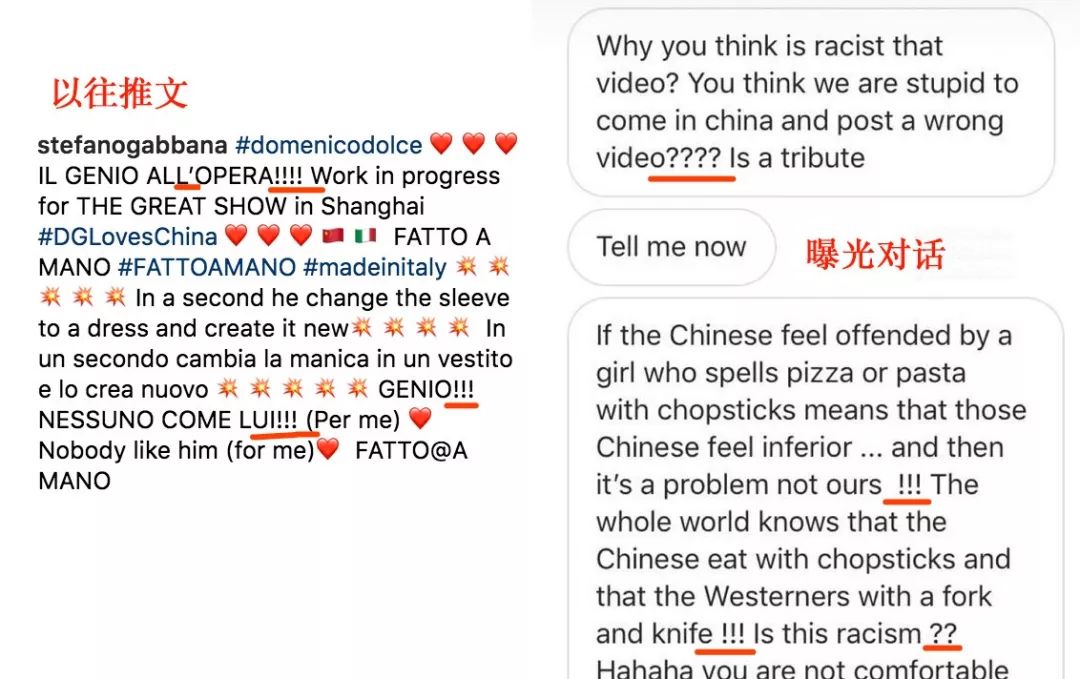
另外,他也喜欢用 ... 的省略号,而且和很多人会固定用 3 个点不同,他数量不定且一般在 4 个及以上的点,30 条中有 4 处,只有一处是 3 个点。对话中有一处是 3 个点,两处 4 个点。
还有就是,很少有人会在标点之前空格。但在他的对话和推文中也都偶有发生。这些都是打字习惯和输入法所决定的,如果换了人,甚至换了手机,都有可能不一样。
3. 连续表情
看下面这张汇总图,这太明显了:此人极度喜欢用 emoji 表情,用连续的表情,而且对❤️情有独钟。

而此次最可耻的一句话,也恰好符合这个风格!
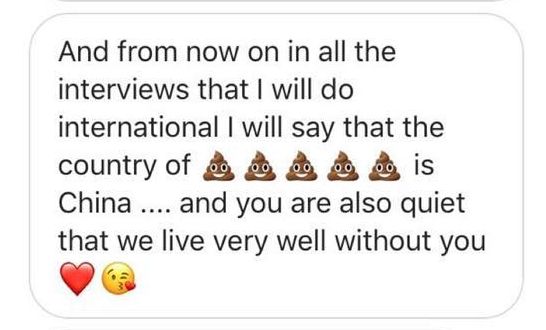
而对于无此习惯的人来说,让你马上打这个表情出来,你都未必能找到。
4. 结尾
有人喜欢发文结尾加上句号,哪怕只有一个词。比如他们的官方账号:

而 Gabbana 不是此类。对话和 30 条推文中,仅有一条是 . 结尾的。相反最近的盗号声明和致歉声明,均以 . 结尾,没有表情和感叹号。反倒不符合他一贯的行文习惯……
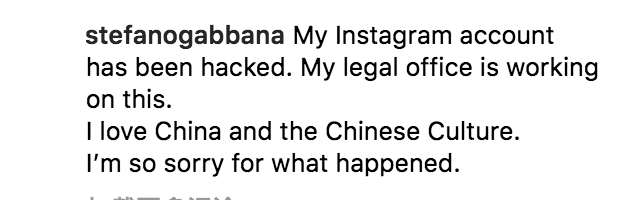
这又是为啥呢?按他习惯难道不应该是:
My Instagram account has been hacked !!!!!![]()
![]()
![]()
![]()
![]() It’s NOT ME !!!!! I love China and the Chinese Culture ❤️❤️❤️❤️❤️❤️
It’s NOT ME !!!!! I love China and the Chinese Culture ❤️❤️❤️❤️❤️❤️
虽然从以上这几点细节,并不能实锤说,Gabbana 一定没有盗号。但至少可以说,这些对话中并没有表现出与他以往行文风格很不符的地方。就算真的是被盗,那这黑客也真的是高手,不但技术好,而且还这么花心思去模仿 .... 佩服佩服 !!!!!! ![]()
![]()
![]()
![]()
![]()
![]()
话说回来,我这也是多此一举。因为盗没盗号,Instagram 官方从登录记录一眼就能看出来。之前官方就曾为美国女歌手赛琳娜·戈麦斯(Selena Gomez)发表过声明证明其账号被盗。真的被盗了,是很容易证实的。然而 D&G 两位创始人在所谓的“道歉”视频中都闭口不提之前所谓的盗号一说,想必大家也都心知肚明了。
文化上存在差异,这是很正常的事情,但这不是某些人狂妄和傲慢的借口。有错就要认,挨打要立正。别又想那啥,又想那啥。瞧不起别人的人,最终也会被别人瞧不起。
虽然我本来就没买过 D&G(因为他家也没有格子衬衫和双肩包),这次之后就连以后光顾可能性也不存在了。拜拜!
内容来自于网络,如有侵权,请联系删除
公众号内回复“1”带你进粉丝群
这篇关于抓取了Gabbana 最近的 Instagram 推文:号真被盗了吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!