本文主要是介绍服务器上的安全数据没有此工作站信任关系的计算机账户_GPS时间源(gps授时服务器)在泵站SCADA系统中的应用...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
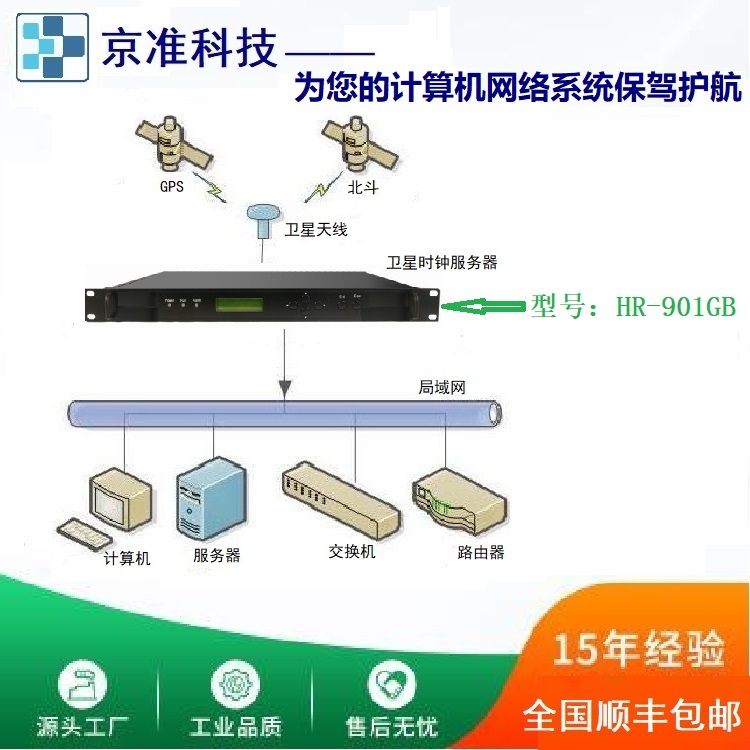
GPS时间源(gps授时服务器)在泵站SCADA系统中的应用
安徽京准电子科技开发的HR-901GB型gps授时服务器 为SCADA系统时刻服务。
前言 jfeikx47824jfjf
随着计算机和网络通信技术的飞速发展,各行业自动化系统数字化、网络化的时代已经到来。这一方面为各控制和信息系统之间的数据交换、分析和应用提供了更好的平台、另一方面对各种实时和历史数据时间标签的准确性也提出了更高的要求、使用价格并不昂贵的GPS时钟来统一各种系统的时钟,已是目前各大系统设计中采用的标准做法。如大型的机组集散控制系统(SCADA)、辅助系统可编程控制器(PLC)、厂级监控信息系统(SIS)、厂站的管理信息系统(MIS)等的主时钟通过合适的GPS时钟信号接口,得到标准的TOD(年月日时分秒)时间,然后按各自的时钟同步机制,将系统内的从时钟偏差限定在足够小的范围内,从而达到整个系统的时钟同步。
1、概述
水利自动化泵站信息采集系统SCADA功能为调度员、集控员提供了各个泵站的实时数据及信息,并可以使他们方便地进行事故重演或历史数据和信息查询。在系统设计时,需要考虑更多的是网络结构、通讯规约转换、数据存储方式介质和满足SCADA功能的几项性能指标要求,而没有考虑系统全网时钟不同步会造成什么影响。由于系统全网时钟不同步会造成一些较为特殊的故障,如数据和信息丢失、SOE事件信息逻辑混乱、某些工作站死机甚至系统瘫痪,因而为了消除时钟不同步的影响,我们有必要分析时钟同步在SCADA系统中的重要作用及各种实现方式。
泵站SCADA采集系统是实时性很强的系统,它采集各个泵站的实时数据和信息,经过软硬件处理后,在各泵站工作站显示数据和信息或存储到历史数据库中。SCADA采集系统分为总控端系统和各分泵站系统,故全网时钟同步按两部分进行:
① 总控端系统各工作中和服务器时钟同步;
② 各分泵站系统总控单元和智能单元的时钟同步;
2、总控端系统时钟同步
总控端系统各工作站与主服务器时钟同步的目的,是保证数据发生增加、更改、删除等操作时全网的一致性和完整性。数据的不一致和残缺会造成主备系统切换或历史数据进行存储时,不能正确识别数据的一致性和完整性,从而造成信息和数据的丢失,甚至会导致系统的瘫痪。由于各工作站和服务器的晶振芯片长时间运行后,会出现由于漏电或其他原因造成的时钟不准问题,因而需采取相应的方式来实现总控端系统的网络时钟同步,具体如图1所示的方式:总控端系统时钟同步方式一般采用图1的方式,因为HR-906型号GPS时钟装置不但可以提供一个网络接口还可以提供多路NTP网络接口,另外为了要实现与GPS时钟同步,各服务器、工作站和前置机还无需运行其他进程,只需要将系统NTP服务启动即可,从而大大节省了系统资源。jfeikx47824jfjf
3、各泵站端系统时钟同步
各分泵站系统与总控端系统时钟同步及泵站各个智能设备之间的时钟同步目的,是保证各间隔智能单元实时采集的数据信息,在总控系统经过处理后,能正确重演数据或信息发生的时间、先后顺序和逻辑关系。调度员、集控员根据显示的数据和信息,实时掌握各个泵站一次系统的运行状态,从而保证经济调度、安全调度。
各分泵站系统工作站时钟同步方式采用专门的网络时钟同步,这样可以提高时钟同步的精度,而且方便快捷,同时减少了智能单元的资源负担,各分泵系统中智能单元采用图2时钟同步方式,通过我们HR-901GB型产品的串口或脉冲接口给智能单元时钟同步。
4、产品拓扑图
整个系统时钟同步分两部分,一个是总控端和分泵站工作站我们推荐采用HR-906A型号NTP时钟服务器来实现,另一个是分泵站的智能单元及采集单元(PLC)我们推荐采用HR-906A型号串口卫星时钟来实现,具体如下图:
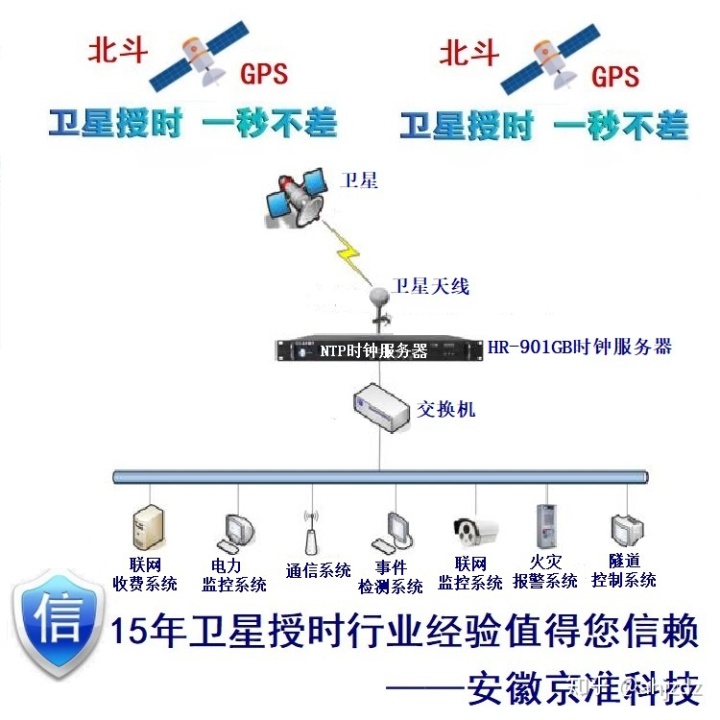
5、结语
上所述,为了防止系统全网时钟不同步造成如数据和信息丢失、SOE事件信息逻辑混乱、某些工作站死机甚至系统瘫痪的故障,我们必须采取相应的措施实现系统全网时钟同步。
这篇关于服务器上的安全数据没有此工作站信任关系的计算机账户_GPS时间源(gps授时服务器)在泵站SCADA系统中的应用...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








